
A familiar startup moment goes like this. It's 2 AM, PagerDuty is firing, Slack is noisy, and someone posts a screenshot that suggests customer data may have been exposed through a misconfigured service. Engineering wants to shut systems down. Product wants to know customer impact. The founder wants one answer to a simple question: what happened, and who is in charge?
That's where people usually ask, what is incident response. The useful answer isn't “a security best practice.” It's the operating system for bad days. If you don't have one, smart people improvise under pressure, decisions get delayed, evidence gets lost, and the business takes a larger hit than it had to.
What Happens When Things Go Wrong
A startup doesn't need a giant security team to handle incidents well. It needs a small set of decisions made in advance.
TL;DR
- Incident response is a structured way to detect, contain, eradicate, recover from, and learn from security incidents.
- The six-phase model works, but startups fail when they stop at the diagram and never assign ownership.
- For high-growth teams, the right goal isn't “build a full SOC.” It's create a repeatable response motion for the incidents you're most likely to face.
- AI and ML systems add new failure modes, especially leaked credentials, exposed training data, model endpoint abuse, and third-party platform dependencies.
- Measure your program with MTTD, MTTR, and MTTC, and review trends after every meaningful incident.
- If you handle customer data, regulated data, or vendor-managed infrastructure, pair technical response with legal and executive decision-making early. A practical guide for managing data incidents is useful when your response must go beyond engineering cleanup.
This is for CTOs, founders, heads of engineering, and platform leaders in startups that have outgrown “just fix it live” but haven't staffed a large security org. It's especially relevant if you run production AI systems, ship fast, rely on cloud vendors, and have a team where the same people own uptime, deployment, and incident handling.
What startup leaders usually get wrong
The common mistake isn't lack of effort. It's treating incidents as one-off technical problems.
Practical rule: If an incident can affect customers, contracts, or regulatory obligations, it's not only an engineering issue.
Another mistake is overbuilding. Startups often copy enterprise templates that look mature on paper but aren't usable at 2 AM. A thinner process that people will follow beats a heavyweight playbook nobody reads.
The 6-Phase Incident Response Framework
Incident response is a structured lifecycle for detecting, containing, and recovering from security incidents. Major frameworks break it into six phases: preparation, identification, containment, eradication, recovery, and lessons learned, turning ad hoc firefighting into a repeatable, measurable process, as described by Atlassian's incident response overview.
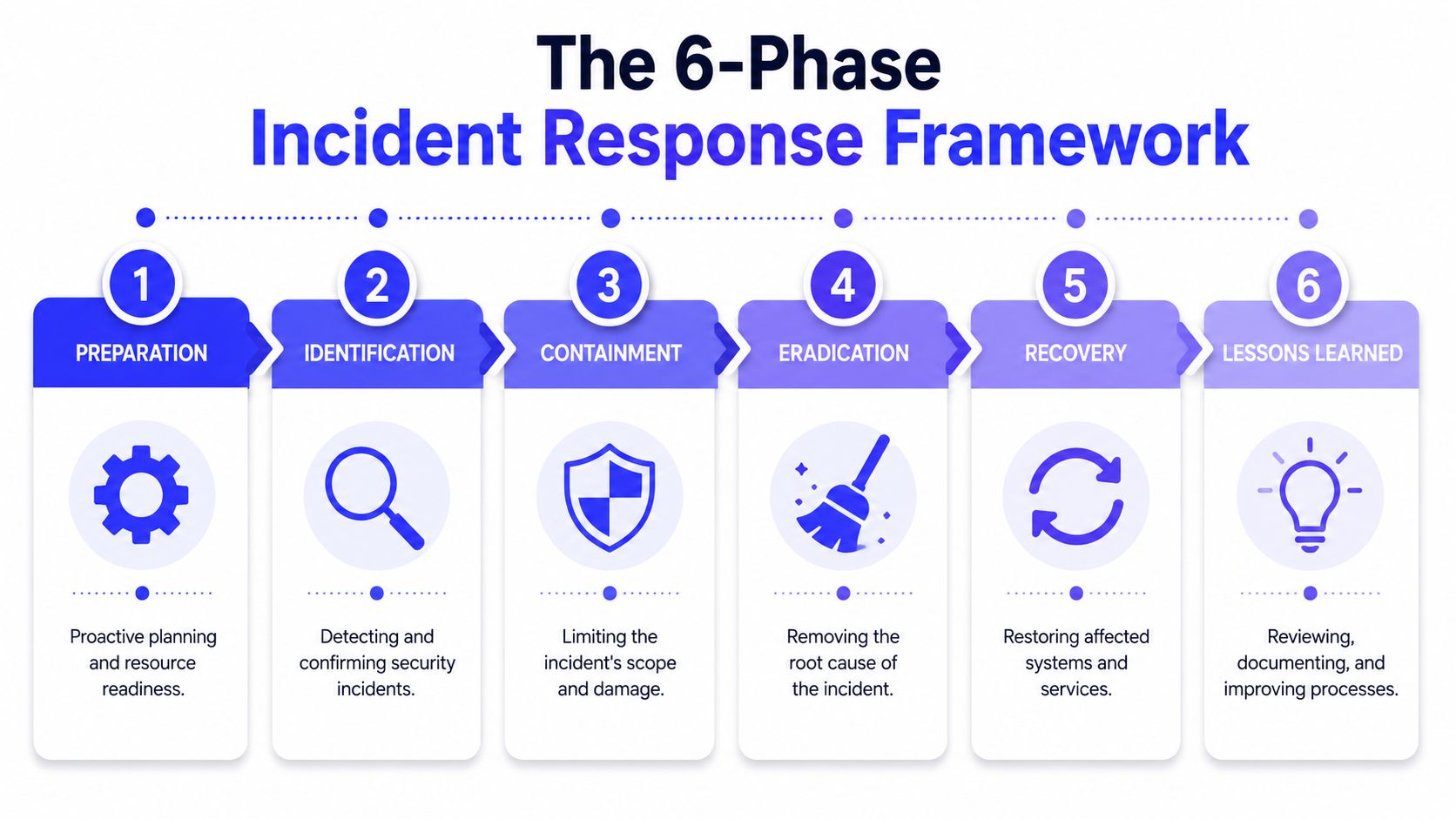
Preparation
Preparation is everything you do before you need it. For a startup, that means a current on-call schedule, clear severity levels, admin access that won't fail during an outage, asset inventory for critical systems, and one communication path for incident coordination.
A good preparation phase is boring. That's a compliment.
What works:
- One source of truth: Keep your incident playbooks in the same place engineers already use.
- Access pre-checks: Make sure responders can reach cloud consoles, identity tools, logs, and backups.
- Named decision owners: Pre-assign who can approve customer comms, system isolation, and vendor escalation.
What doesn't:
- Huge policy binders: They slow people down.
- Undefined severities: Teams argue about labels instead of impact.
- Tool sprawl: Five dashboards and no shared timeline is not readiness.
Identification
Identification is when you decide whether the signal is real, what's affected, and how urgent it is. At this stage, many teams lose time by debating symptoms instead of writing down evidence.
A simple pattern works well:
- Confirm the trigger
- State the suspected impact
- List affected systems
- Set a severity
- Start an incident record
If you need a parallel example of how teams structure issue flow outside security, this write-up on the bug life cycle is a useful comparison. The difference is that incident response compresses those decisions into minutes, not sprint ceremonies.
For breach-oriented situations, a concise reference like Steps for a data breach response can help teams remember the non-technical actions that often follow the initial technical triage.
A short explainer can help your team align on the flow before you formalize it further.
Containment, eradication, recovery, and lessons learned
Containment is about limiting blast radius. Eradication removes the cause. Recovery restores service safely. Lessons learned makes the next response better.
These phases sound neat in a framework, but in practice they overlap.
- Containment: Revoke tokens, isolate workloads, disable risky integrations, block automation jobs, or move traffic away from suspect systems.
- Eradication: Remove malicious code, close the exposed path, rotate secrets, patch the vulnerable component, or rebuild a compromised service.
- Recovery: Restore known-good systems, validate functionality, monitor closely, and communicate status.
- Lessons learned: Build a timeline, document gaps, update detections and playbooks, then assign follow-up work to real owners.
Fast containment often beats perfect diagnosis. If you know a production credential is exposed, rotate it first and investigate in parallel.
Incident Response in the Real World
Frameworks matter because they reduce chaos. They become real when you walk through specific failures your team could face.

Mini-case one leaked API keys for an AI service
A developer accidentally pushes an environment file to a repository mirror. The file includes credentials tied to an LLM gateway, vector database access, and a storage bucket used for retrieval-augmented generation assets.
The first alert may not even come from your security tooling. It might come from a code scanning bot, a teammate, or unusual spend and request volume. Identification starts with confirming whether the key is active, what permissions it has, and which systems trust it.
Containment is immediate and mechanical:
- Rotate exposed secrets
- Disable unused service accounts
- Review recent calls and logs
- Temporarily narrow access policies
- Pause high-risk workflows if abuse is possible
Eradication is where startups often cut corners. It's not enough to rotate one token and move on. You need to remove the reason the leak happened. That could mean changing how secrets are injected into CI, blocking commits with sensitive patterns, or separating model access keys from broader infrastructure credentials.
Recovery means more than “service is back.” For an AI product, validate that prompts, embeddings, file stores, and downstream jobs are behaving as expected. If the model pipeline depends on a third-party inference provider, confirm their logs and support process too.
If your AI stack includes multiple vendors, your incident timeline needs vendor checkpoints. Otherwise you'll spend hours assuming a problem is internal when it sits in someone else's control plane.
Mini-case two critical database outage during product launch
A more classic incident hits during a launch window. Write latency spikes, workers back up, and your application starts failing requests that depend on the primary database.
Preparation determines whether this becomes a short disruption or a long one. Teams that already know the business-critical paths can triage quickly. Teams that don't will waste time arguing whether the issue is “security” or “reliability.” At startup scale, those labels often matter less than restoring controlled service.
The workflow usually looks like this:
| Phase | What the team does |
|---|---|
| Preparation | On-call routing exists, dashboards are known, runbook is reachable |
| Identification | Confirm outage scope, affected services, and customer-facing impact |
| Containment | Shed non-critical load, disable failing batch jobs, limit write-heavy paths |
| Eradication | Fix the misconfiguration, bad deployment, or dependency issue causing failure |
| Recovery | Restore traffic in stages and validate application health |
| Lessons learned | Record timeline, gaps in alerting, and changes to runbooks |
This kind of incident also shows why a single command structure matters. One person runs the incident. Another handles stakeholder updates. Everyone else executes assigned tasks. Without that split, responders keep switching between technical work and status reporting, and both get worse.
What these examples have in common
The AI credential leak and the database outage look different, but they fail in the same places:
- No clear owner
- No prebuilt communication path
- No asset inventory
- No habit of documenting decisions during the event
That's why incident response shouldn't live only in the security wiki. It has to fit how your engineering org already works.
Who Owns the Incident Response Process
The most underexplained part of incident response is ownership. Incident response is the technical portion of broader incident management, which also requires executive, HR, and legal coordination, especially when breaches trigger customer notifications or regulatory reporting, as noted in IBM's explanation of incident response and incident management.
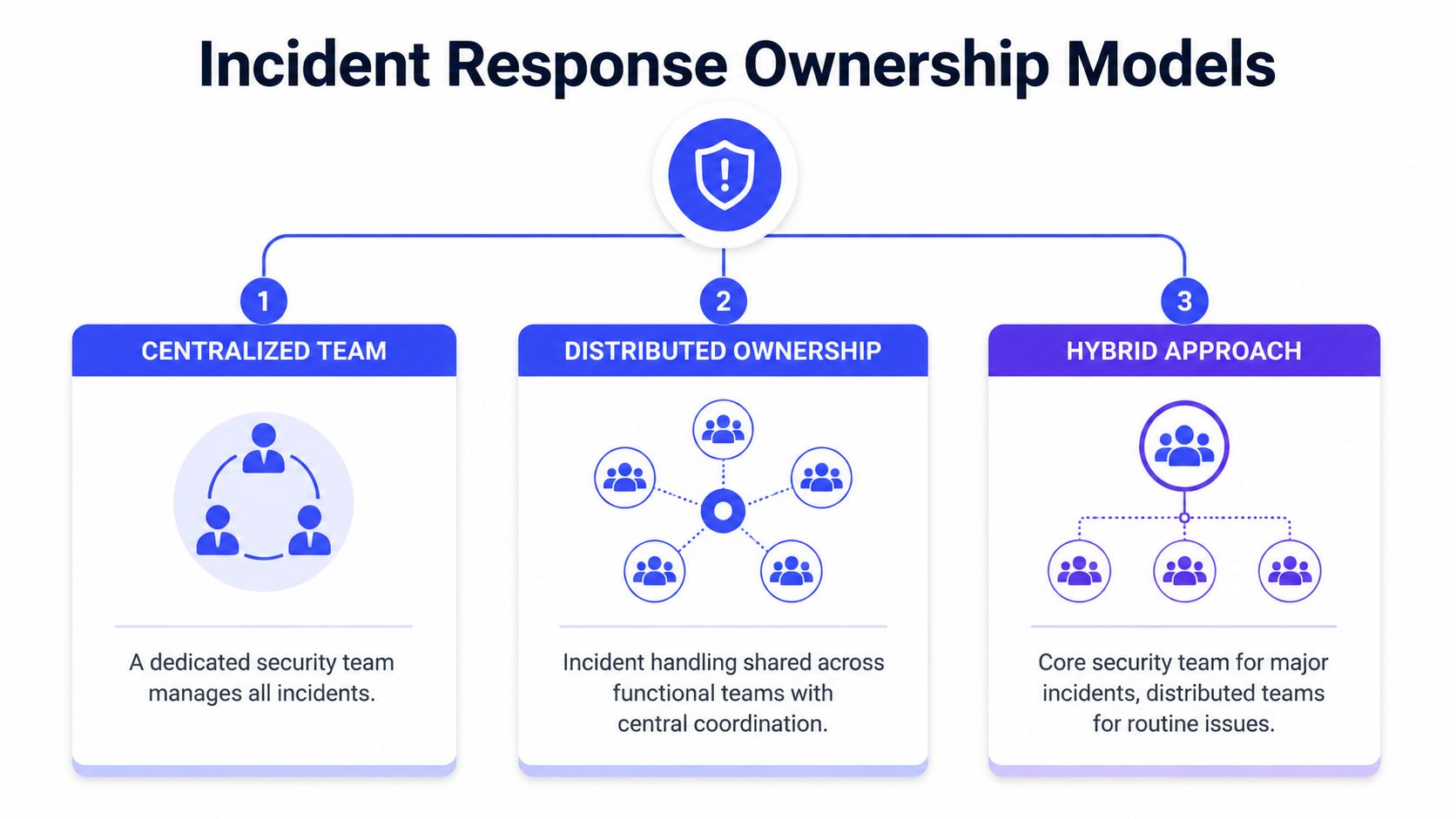
Model one SRE or platform-led ownership
This is common in early-stage companies. The SRE, DevOps, or platform team owns the mechanics of detection, triage, and response. It's often the fastest option because those engineers already know the systems and have production access.
This model fits when:
- Your incidents are mostly operational: outages, bad deploys, cloud misconfigurations, access issues
- The company is still small: one team can realistically hold the context
- You need speed over specialization: adding process friction would slow response
The downside is predictable. Security-specific evidence handling, legal coordination, and attack investigation often get weak treatment.
Model two dedicated security ownership
Once the company handles sensitive customer data, has stronger compliance obligations, or runs a larger estate, a dedicated security lead becomes valuable. That person doesn't need to handle every pager event personally, but they should own the framework, severity model, evidence standards, and post-incident follow-up.
This model fits when:
- You have recurring security incidents or near misses
- You rely on many vendors and cloud services
- The executive team expects structured security reporting
If you're considering this route, the hardest part usually isn't the playbook. It's hiring. Building the right team often starts with a realistic view of information security recruitment, because strong incident responders need both technical depth and calm judgment under pressure.
Model three fractional or hybrid ownership
A hybrid model works well for growth-stage startups. Core engineering owns first response. A fractional security leader, retained responder, or specialist advisor shapes the program, reviews major incidents, and helps with serious events.
This model fits when:
- You need maturity now but can't justify a full internal team
- Your risk profile is rising faster than headcount
- You run AI or data-heavy systems with niche failure modes
A practical split often looks like this:
| Responsibility | Best owner in a startup |
|---|---|
| Initial triage | On-call engineering or SRE |
| Technical lead during incident | System owner or incident commander |
| Legal and executive coordination | CTO, founder, or delegated business lead |
| Forensic depth and process design | Security lead or fractional expert |
| Post-incident follow-up | Engineering manager plus security owner |
Ownership should be explicit before the incident starts. “We'll figure it out live” is how authority gaps become business risk.
The key decision isn't whether to centralize everything. It's whether your current model can answer three questions fast: who leads, who approves business-impacting decisions, and who owns the follow-up work.
The Startup Incident Response Tool Stack
Startups don't need enterprise bloat. They need a narrow tool stack that supports detection, coordination, evidence collection, and recovery. The strongest setups are integrated enough to keep context in one place, but simple enough that responders can use them half-asleep.

Effective incident response relies on operational readiness, including continuous monitoring, regular testing, and leveraging automation. The field is moving from manual playbooks toward faster, tool-assisted response for detection, investigation, and recovery, as described by SANS.
The minimum viable stack
You can cover most startup needs with five categories.
- Monitoring and logs: Datadog, Elastic, Grafana, CloudWatch, or a similar stack. If you're comparing observability paths, this breakdown of Kibana vs Grafana is useful for deciding where logs and dashboards should live.
- Alerting and on-call: PagerDuty, Opsgenie, or native cloud alert routing.
- Communication: A dedicated Slack channel per incident, plus a standing incident channel for coordination norms.
- Tracking: Jira, Linear, or another ticketing system that can hold timeline, severity, owner, and action items.
- Identity and secrets: Okta, Google Workspace admin tools, AWS IAM, Vault, or your cloud-native equivalents.
How the tools map to the lifecycle
Different tools matter at different moments.
| Phase | Most useful tools |
|---|---|
| Preparation | Runbooks, on-call schedules, asset inventory, access management |
| Identification | Logs, alerts, SIEM-light searches, anomaly dashboards |
| Containment | Identity controls, secrets rotation, cloud console actions, endpoint controls |
| Eradication | Deployment pipeline, config management, patching, rebuild workflows |
| Recovery | Backups, rollout controls, health checks, status communication |
| Lessons learned | Ticket history, Slack transcript, timeline notes, task tracker |
What works best for startups is tight handoff, not maximal coverage. An alert should create a clear human action. A human action should create a record. That record should survive the incident and feed the postmortem.
What not to buy too early
Avoid tools that require a dedicated team to maintain before you've built the response habit. An advanced platform won't save a team that lacks ownership, runbooks, or clean escalation paths.
Measuring What Matters IR KPIs and Metrics
You can't improve incident response by saying “that felt better than last time.” Modern programs are judged by time-based metrics because they connect process quality to business disruption. Splunk's incident response metrics guidance highlights mean time to detect (MTTD), mean time to respond or resolve (MTTR), and mean time to contain (MTTC) as core measures, and explains that teams calculate them from incident history by averaging durations across incidents.
The three metrics that matter first
- MTTD tells you how long it takes to notice a real incident after it begins. If this is weak, your monitoring and escalation path need work.
- MTTC shows how quickly the team limits spread or impact once the incident is recognized. This reflects access, authority, and operational readiness.
- MTTR captures how long it takes to restore normal service or close the incident. It demonstrates engineering quality, rollback speed, and recovery discipline.
Those metrics matter because they're operational. They force the team to define timestamps, keep incident records, and review trendlines rather than relying on memory.
Good metrics don't make incidents look tidy. They make weak process visible early enough to fix it.
A simple KPI scorecard
Use one scorecard per quarter. Keep it lightweight enough that someone updates it.
| Metric | Description | Q1 Target | Q1 Actual | Q2 Target |
|---|---|---|---|---|
| MTTD | Average time from incident start to confirmed detection | [set internally] | [fill from incident history] | [set next target] |
| MTTC | Average time from confirmed detection to containment | [set internally] | [fill from incident history] | [set next target] |
| MTTR | Average time from confirmed detection to resolution or service recovery | [set internally] | [fill from incident history] | [set next target] |
| Incident volume | Total incidents recorded in the period | [set internally] | [fill from ticketing data] | [set next target] |
| False positives | Alerts escalated that did not become true incidents | [set internally] | [fill from review log] | [set next target] |
| Repeat incidents | Recurring incidents with the same root cause or playbook gap | [set internally] | [fill from postmortems] | [set next target] |
How to use the scorecard well
A few rules keep this useful:
- Track only incidents you review.
- Define your timestamps once. Don't change the meaning of “detected” quarter to quarter.
- Pair metrics with notes. If MTTR worsens because the team chose a safer recovery path, leadership should know that context.
- Watch repeats closely. A repeated incident usually means the lessons-learned phase failed, not just the original system.
For startups, the point isn't benchmarking against giant enterprises. It's proving whether your own response motion is improving, stable, or deteriorating.
How to Build Your IR Capability This Quarter
Don't start with a massive program. Start with one page, one owner, and one drill.
The lowest-friction plan that works
This quarter, do these three things:
Name an incident commander role
Pick the role, not just the person. Decide who leads live response when the primary owner is unavailable.Write one playbook for one likely incident
Good candidates are leaked credentials, suspicious account access, or a production database failure. Keep it short. Include triggers, first actions, decision owners, and communication steps.Run one tabletop exercise
Use a realistic scenario tied to your stack, especially if you operate AI systems or regulated data. If your product touches healthcare workflows, external validation such as affordable HIPAA compliance testing can complement your internal readiness work.
A basic readiness checklist should include:
- Critical asset inventory
- Current on-call rotation
- Access verification for responders
- Incident channel template
- Severity definitions
- Post-incident review template
Most startups don't need a perfect incident response program. They need one that exists, gets used, and gets better every quarter.
If you need to stand this up fast, ThirstySprout can help you Start a Pilot with senior security, SRE, and AI infrastructure talent who've handled production incidents in real environments. You can also See Sample Profiles if you're deciding whether to hire a dedicated responder, bring in a fractional security leader, or upskill your current engineering team with hands-on guidance.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.