
A model-serving issue once looked like a normal app bug until we traced it back to a schema change in an upstream data job. The ticket bounced between backend, data, and ML engineers for hours because nobody agreed on what state it was in or who owned the next move.
That’s what a weak bug life cycle does to a fast-growing AI team. It doesn’t just slow fixes. It creates ambiguity, hides risk, and burns senior engineering time on coordination instead of resolution.
TLDR
A bug life cycle is the operating model that keeps defects from turning into coordination work. For an AI team, that includes product bugs, backend failures, data contract breaks, inference incidents, and model drift. If the issue affects reliability, user trust, or delivery predictability, it belongs in the same system with a defined owner and a defined next state.
The state names matter less than the handoffs. Keep the workflow simple enough that people use it, usually a small set of core states with explicit exception paths for reopened, deferred, and rejected issues. The goal is to remove ambiguity about who acts next, what evidence is required, and when a bug is completely done.
Tools help, but process design matters more. Jira, Linear, Bugzilla, and incident tooling can all support a good bug life cycle if severity, priority, report quality, and triage rules are clear. Without that discipline, teams get the worst of both worlds: more tickets and less clarity.
AI teams need one adjustment that generic guides usually miss. Some bugs do not come from code changes. They come from stale data, degraded model performance, failed pipelines, or feature store mismatches. Treating those as operational bugs, not separate edge cases, keeps ownership clear across product engineering, data, ML, and MLOps.
This also changes hiring and team structure. If nobody on the team can triage cross-functional defects, the queue stalls. If QA owns intake but cannot validate ML behavior, bugs bounce. Strong bug life cycle design usually leads to clearer staffing decisions, better on-call boundaries, and faster recovery when production issues hit.
Start with a process your team can enforce this quarter. Define statuses, ownership by state, severity rules, exit criteria, and a standing triage cadence. Then inspect reopen rates, aging bugs, and handoff delays to see where velocity is leaking.
Who This Guide Is For
This is for CTOs, Heads of Engineering, founders, and engineering managers who are trying to scale quality without strangling delivery.
It’s especially relevant if your team is shipping AI-powered products and you’ve already felt one of these failure modes: engineers arguing about whether something is a bug or a data issue, repeated reopenings after “fixes,” customer-facing defects that linger because nobody owns triage, or sprint plans that keep getting wrecked by surprise production issues.
A small team can survive with informal coordination for a while. One staff engineer remembers everything, one PM keeps the queue in their head, and everyone pings each other in Slack. That stops working when you add multiple squads, remote contributors, a real release cadence, and ML systems with dependencies outside the app codebase.
A bug life cycle is less about tracking defects and more about making responsibility visible.
If you need a process that protects shipping velocity while improving reliability, this is the operating model to put in place.
The Bug Life Cycle Framework Explained
A bug life cycle is an operating system for ownership. In a fast-growing AI team, it decides whether a customer issue gets diagnosed in hours or drifts between engineering, data, and product until the next incident review.
The mechanics are simple. The discipline is not. Teams usually use a small set of states between first report and final closure, but the value does not come from the labels alone. It comes from clear entry criteria, explicit handoffs, and the right owner at each stage.
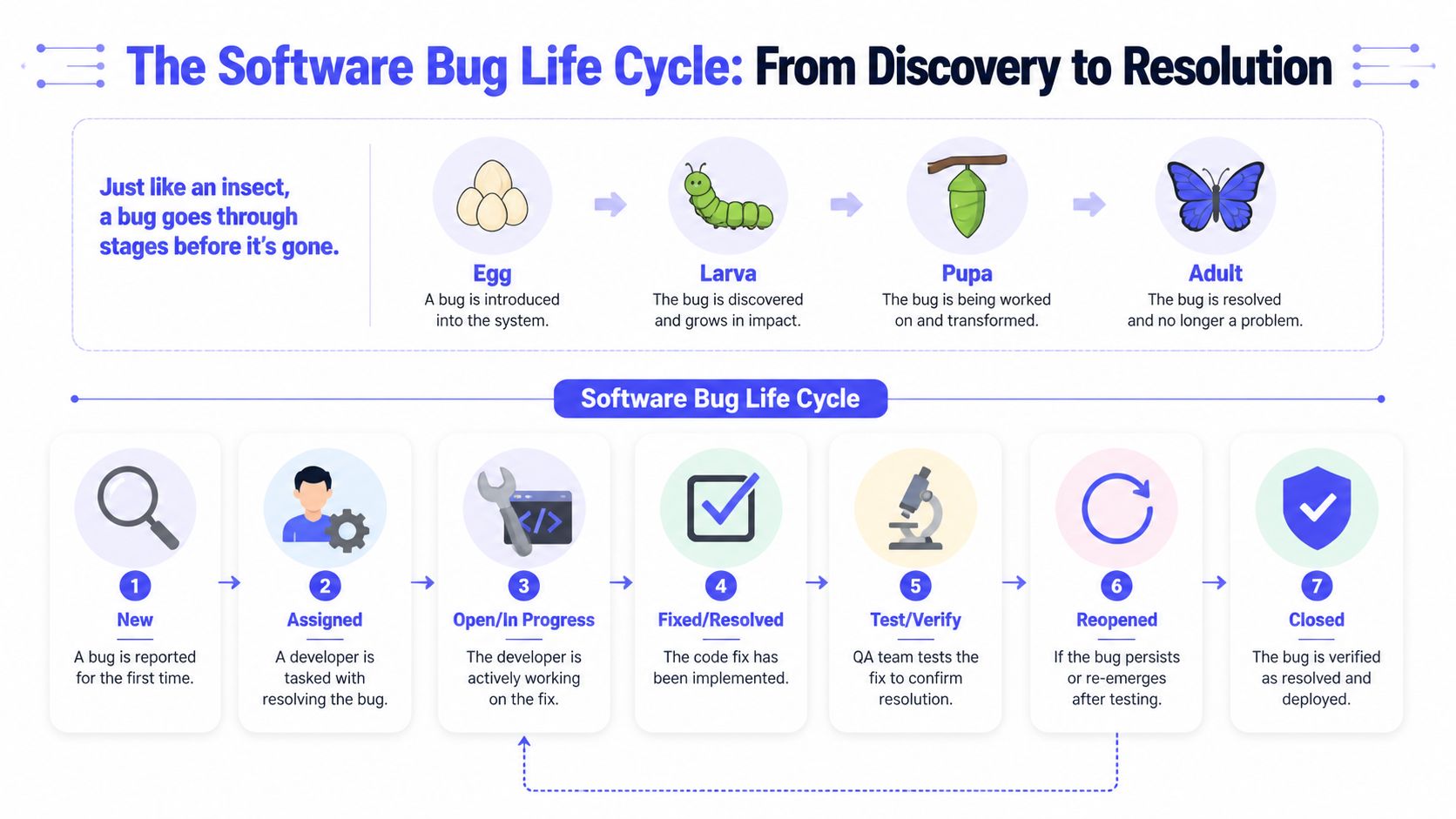
New and Assigned
New is the intake state. A bug enters here when someone reports a defect for the first time, whether it came from QA, support, an engineer, or production monitoring. In AI products, that report has to capture more than UI behavior. Include prompt or input samples, model version, feature flag state, tenant or cohort, environment, and any traces or logs that narrow the failure.
Bad intake creates slow triage. Good intake cuts cycle time.
Use a practical standard for every new ticket:
- Describe the failure precisely: observed behavior, expected behavior, and how often it happens
- Capture the execution context: browser, device, app version, API version, model version, data source, and environment
- Attach evidence: screenshots, logs, trace IDs, payloads, failing prompts, or sample records
- State the business impact: customer-facing risk, revenue exposure, compliance concern, SLA impact, or release blocker
Assigned starts when triage confirms the issue is real enough to own. That owner should match the likely failure domain, not just the team that got paged first. A retrieval failure in an AI assistant may belong to platform or MLOps. A hallucination spike after a model swap may need application engineering, evaluation, and ML working together. Getting this right protects delivery because the ticket lands with the people who can move it.
In Progress and Fixed
In Progress means investigation has started and someone is accountable for root cause analysis. The work here is diagnostic before it is corrective. The engineer, or paired team, reproduces the issue and identifies whether the fault sits in product code, infrastructure, data pipelines, prompt logic, model behavior, evaluation thresholds, or release configuration.
AI teams need a wider definition of bug. A bug is not only broken code. It can also be model drift, a stale embedding index, a bad labeling job, a broken feature store assumption, or an alert threshold that hid a quality drop. If your workflow cannot represent those failures cleanly, MLOps problems stay invisible until customers report them.
Fixed should mean the change is implemented and ready for independent validation. It should never mean the developer stopped seeing the problem on their machine.
For AI systems, a real fix often includes several actions:
- code change or rollback
- prompt or routing update
- data contract correction
- model redeploy or version pin
- reindex, backfill, or cache invalidation
- new monitor, test case, or safeguard to catch recurrence
Teams that want tighter handoffs usually improve this stage and the one after it. This guide to quality assurance for software testing is useful if you are formalizing what “ready for validation” should mean across engineering and QA.
Pending Retest, Verified, and Closed
Pending Retest is the control point between implementation and proof. Development signals that the fix is ready. QA, the original reporter, or a designated reviewer validates it against acceptance criteria and checks for regressions in the affected path.
Verified means the team confirmed the fix works in the target environment and under the conditions that originally triggered the issue. In AI products, that often includes retesting with known failing prompts, checking tenant-specific behavior, and confirming monitoring has stabilized after the change.
Closed is an administrative state with operational meaning. The issue is resolved, evidence is attached, and no follow-up action is required. If a ticket reaches Closed without proof, the process trains the team to confuse activity with resolution.
Reopened, Deferred, and Rejected
These states keep the workflow honest because they record decisions teams often make informally.
| Status | When to use it | What it prevents |
|---|---|---|
| Reopened | The issue still exists, recurs in production, or the validation missed part of the failure | Premature closure and repeat incidents |
| Deferred | The bug is valid, but the team intentionally schedules it for later because other work has higher business priority | Hidden backlog risk and random reprioritization |
| Rejected | The report is not a defect, duplicates another ticket, or matches intended behavior | Wasted engineering and QA effort |
A useful test is simple. If an engineer, QA lead, and product manager would each explain a state change differently, the workflow is too loose. Tight definitions improve speed because they reduce argument, shorten triage, and make ownership visible across application, platform, and ML teams.
Real-World Bug Life Cycle Examples
The easiest way to see whether your process is working is to follow real tickets, not theoretical ones.
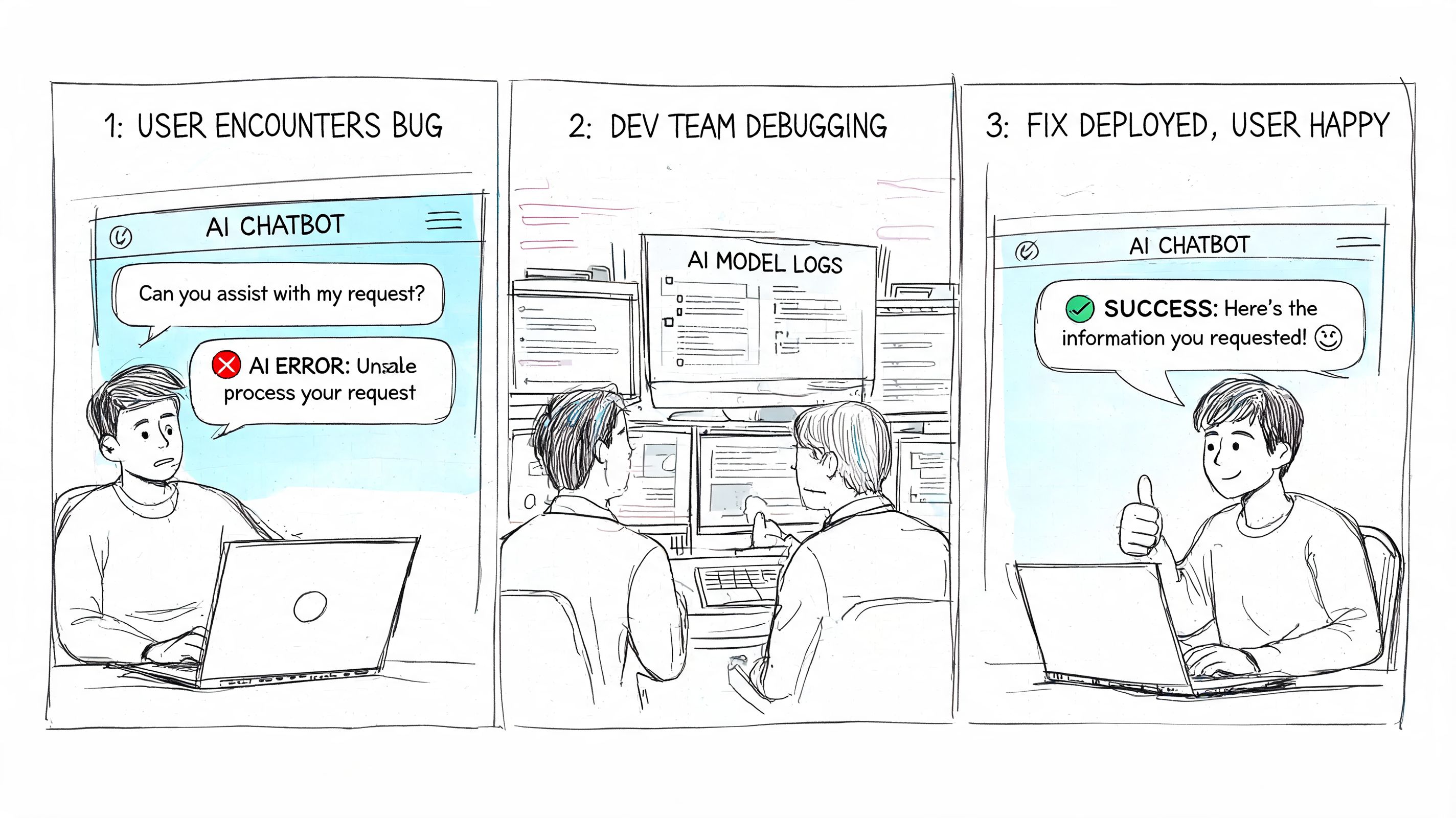
Example one with a production AI incident
A customer support copilot starts returning empty answers for a subset of enterprise tenants after a deployment. Support raises it. The bug enters New with tenant IDs, timestamps, failing prompts, and response logs.
During triage, the engineering lead marks it as severe because it affects a core workflow and customer-facing output. It moves immediately to Assigned, then In Progress with an application engineer and an MLOps engineer paired on the issue.
What happened?
The application layer was fine. The retrieval step was failing because a metadata field changed in the indexing pipeline. The fix required three actions:
- revert the schema change,
- reindex affected content,
- add a contract test between the ingestion job and retrieval service.
The developer marks the ticket Fixed only after the patch and reindex complete in the staging environment. QA retests known failing prompts, validates tenant-specific behavior, and confirms monitoring is green. The bug moves to Verified, then Closed after deployment review.
The lesson isn’t that the team moved quickly. It’s that the lifecycle forced clarity. One ticket held the timeline, owner, root cause, remediation, and validation evidence.
Example two with a low-priority UI defect
A tester notices that a settings page button wraps awkwardly on smaller laptop screens. The feature still works. No data is lost. No customers are blocked.
That bug still enters New, but triage handles it differently. Product and engineering agree it’s valid but low urgency. The ticket gets Assigned for review, then moved to Deferred because the current sprint is focused on release blockers and reliability work.
Later, when the team picks up design polish items, the bug returns to active work. A frontend engineer fixes the layout, QA verifies it across the supported screen sizes, and the ticket closes without drama.
Many teams fail. They either ignore low-severity bugs until users complain repeatedly, or they overreact and flood the sprint with cosmetic work. A mature bug life cycle gives you a middle ground. You can acknowledge the bug, preserve the context, and defer it intentionally.
What these two examples show
The same workflow handled both issues, but the operating posture changed.
- Critical AI bug: Fast triage, direct ownership, cross-functional resolution.
- Minor UI issue: Documented, deprioritized, and revisited on purpose.
- Shared benefit: Everyone could see status, rationale, and next action without chasing updates in chat.
A good bug process should be strict about states and flexible about urgency.
Deep Dive Into Triage Metrics and MLOps
A bug queue starts to fail long before customers notice. It happens in the first ten minutes of triage, when nobody can answer four basic questions with confidence: Is this real? How bad is it? Who owns it? What happens if we wait?
On fast-growing AI teams, weak triage creates two expensive patterns. Engineers get pulled off roadmap work for issues that only look urgent, and genuinely dangerous failures sit in the queue because they do not fit a clean product bug label. That second category is common in ML systems. Drift, stale features, broken evaluation jobs, and alert failures often cause more business damage than a visible UI defect.
Severity and priority need separate owners
Severity is a technical judgment. Priority is a business decision.
If one person sets both in isolation, the process gets distorted. I have seen infra-heavy teams mark every model-serving issue as Sev 1 because the failure mode looks scary, while product leaders push customer-facing paper cuts to the top because revenue is on the line. Both views matter. They should not be collapsed into one field.
A simple operating model works better:
- Engineering or incident lead sets severity based on system impact, blast radius, reversibility, and safety risk.
- Product or engineering management sets priority based on customer exposure, contractual commitments, launch timing, and revenue risk.
- Triage lead resolves conflicts fast so tickets do not sit in Assigned waiting for consensus.
Use a matrix that forces the conversation:
| Severity | Priority | Typical example | Team response |
|---|---|---|---|
| High severity, high priority | Core system failure with immediate business impact | Model serving down for paying customers | Stop planned work, assign an incident owner, and track recovery in real time |
| High severity, lower priority | Serious defect with limited exposure | Internal admin workflow corrupts a non-critical export | Fix quickly, but protect release work if customer impact is contained |
| Low severity, high priority | Limited technical impact with high business visibility | Formatting issue on a launch page or investor demo flow | Route to the responsible team immediately because visibility is high |
| Low severity, low priority | Small defect with no meaningful business risk | Layout issue in a settings subpage | Record it, rank it, and defer deliberately |
Critical should be a behavior-changing label. It should trigger an owner, a response time, and an escalation path.
Metrics that show whether triage is working
Raw bug counts rarely help leadership decisions. A rising count may mean quality is worse, or it may mean detection got better. The useful metrics show whether the system routes work cleanly and closes the loop.
Key Bug Life Cycle Metrics for Engineering Leaders
| Metric | What It Measures | Good Signal | Bad Signal |
|---|---|---|---|
| Mean time to recovery | How quickly the team restores service or resolves impactful defects | Owners are clear and handoffs are fast | Bugs wait on triage, environment access, or unclear rollback paths |
| Reopen rate | How often fixed bugs come back | Root cause was addressed and validation was real | Fixes only treated the symptom or testing missed edge cases |
| Bug aging | How long tickets stay unresolved | The queue reflects current priorities | Old defects pile up with no owner or decision |
| Defect escape pattern | Which bugs reach production | Test coverage matches real failure modes | The same classes of issues keep getting through |
| State transition friction | Where bugs stall in the workflow | Tickets move predictably between teams | Work sits in Assigned, Pending Retest, or Deferred without clear criteria |
Review these metrics next to delivery and reliability metrics, not in a separate quality report nobody acts on. DataLunix's DORA metrics guide is useful because it frames recovery, change failure rate, and deployment performance as one operating system. That is the standard to aim for. A healthy bug life cycle protects throughput by reducing chaos.
One more metric matters for AI teams: false urgency. If half of your P1s get downgraded after triage, the team is paying an interruption tax. Track that. It exposes weak intake standards, unclear severity definitions, or missing observability.
In MLOps, many bugs do not start with code
Traditional workflows assume a defect enters the system after a release. ML systems break that assumption.
A model can regress because the input distribution changed. A feature store job can produce undetected stale values. An evaluation dataset can drift away from production reality. None of that requires a bad deploy, but the customer still experiences a bug.
Treat these as first-class bug categories:
- Data pipeline defects: Missing fields, schema drift, bad joins, stale features, late batch jobs
- Model serving failures: Inference errors, timeout spikes, broken canary rollout, version mismatch
- Model behavior defects: Accuracy degradation past your internal threshold, unsafe output patterns, biased classifications, retrieval failures
- Observability defects: Drift detector misfires, missing alerts, dashboard gaps, broken incident routing
This is partly a tooling decision and mostly an ownership decision. Once these issues use the same lifecycle as application defects, they become visible in the same queue, reviewed in the same triage, and held to the same closure standard. That changes staffing conversations too. You can see whether backend engineers are carrying hidden ML operations work, whether platform engineers are becoming the default sink for every unclear issue, and whether your team needs stronger QA, SRE, or MLOps coverage.
Teams building AI products should standardize these workflows early. A shared bug process, paired with strong monitoring and release controls, is one of the most practical MLOps best practices for production AI teams because it turns operational surprises into manageable work with an owner, an SLA, and evidence of resolution.
Hiring and Team Structure Implications
The quality of your bug life cycle is a hiring signal. Not because candidates ask for your Jira workflow, but because mature engineers can tell quickly whether your team knows how to manage operational risk.
Weak teams hire “fast coders” and hope process emerges later. Strong teams hire people who can diagnose, document, collaborate, and close the loop.
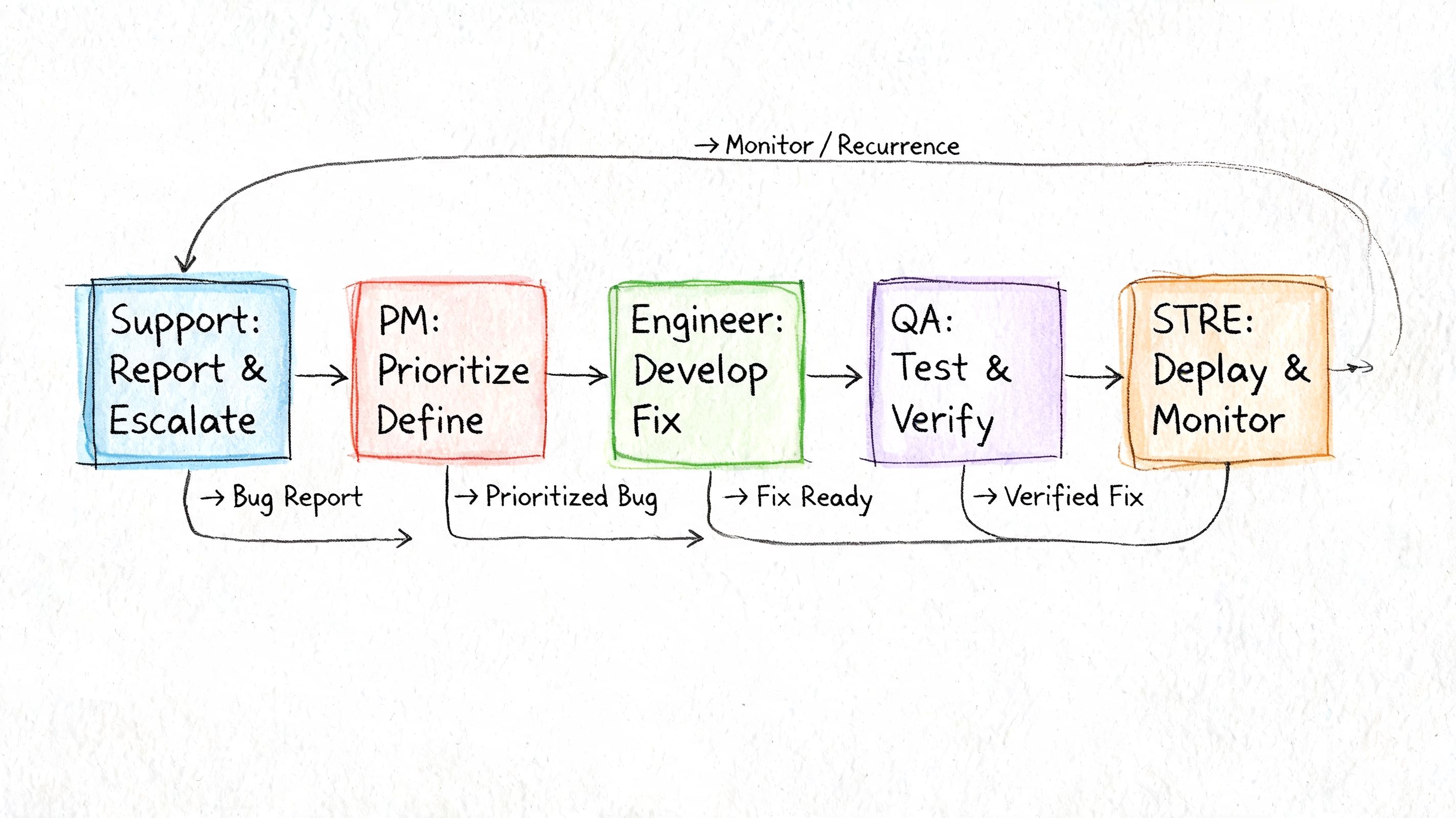
Who should own each stage
A bug life cycle breaks down when ownership is fuzzy. You don’t need a huge QA department, but you do need explicit responsibilities.
- QA or the reporting engineer should own report quality in New. If the bug is poorly logged, everyone downstream pays for it.
- Engineering lead or triage lead should own Assigned. Someone has to decide validity, impact, and routing.
- Developer or paired implementation owner should own In Progress and Fixed. That includes root cause analysis, not just patching symptoms.
- QA, SDET, or designated reviewer should own Pending Retest and Verified. Independent validation matters.
- Product and engineering leadership should jointly own Deferred decisions because deferral is a business choice, not just a technical one.
- MLOps or platform engineers should be in the loop when bugs involve serving, monitoring, data contracts, retraining, or model health.
This is one reason AI teams often need different staffing earlier than traditional SaaS teams. If production quality depends on model behavior, data freshness, and deployment discipline, then dedicated MLOps capability stops being optional.
What to screen for when hiring
Ask questions that reveal how a candidate behaves inside a real defect process.
A few interview prompts that work well:
- Tell me about a bug you thought was one thing but turned out to be something else. How did you narrow it down?
- Describe a time you disagreed with a bug’s priority. What did you do?
- How do you decide whether a fix is ready for QA versus still risky?
- What belongs in a high-quality bug report for a production issue?
- Have you dealt with a model or data problem that looked like an application defect at first?
- What do reopened bugs usually tell you about a team?
Good candidates answer with process awareness. They talk about reproduction steps, logs, impact, rollbacks, validation, communication, and trade-offs. Weak candidates talk only about “fixing the code.”
If your engineers treat bugs as interruptions instead of part of product delivery, the team will never scale quality cleanly.
Your Bug Life Cycle Implementation Checklist
A bug process fails in implementation, not in theory.
I have seen fast-growing AI teams agree on status names in a meeting, then lose a week because incidents still live in Slack, model issues sit in a separate notebook, and nobody knows whether "fixed" means code merged, deployed, or verified in production. The checklist below keeps the process tight enough to run, but mature enough to cover application defects, data issues, and model behavior.
Phase one. Set the workflow and tools
Choose one system of record for all defects. Jira, Linear, GitHub Issues, and Azure DevOps all work if the team uses one consistently. If product bugs live in one place, infra incidents in another, and model drift alerts in a third, triage slows down and ownership gets blurry.
Start with a small state model:
- New
- Assigned
- In Progress
- Fixed
- Pending Retest
- Verified
- Closed
- optional Reopened, Deferred, Rejected
Keep the meaning of each state explicit. In AI teams, that matters more than the label itself. A drift issue marked Fixed might mean the threshold changed, the data pipeline was corrected, or the model was retrained. The team needs one written definition for each case.
Set transition rules early. For example:
- New to Assigned requires an owner
- Fixed to Pending Retest requires a linked PR, runbook, model version, or config change
- Pending Retest to Verified requires QA, reviewer, or monitoring evidence
- Deferred requires a reason and a review date
That level of discipline protects velocity. It cuts the time lost in handoffs and prevents the quiet backlog growth that usually shows up a quarter later.
Phase two. Standardize what a good bug report looks like
Use a template that a busy engineer will indeed fill out. If reporting takes ten minutes, people skip fields or file vague tickets. If the template is too thin, triage turns into detective work.
Include:
- Summary of the defect
- Steps to reproduce
- Expected behavior
- Actual behavior
- Environment or model version
- Severity
- Priority
- Evidence
- Affected component, service, dataset, or pipeline
- Business impact
That last field matters. A broken export button and a ranking model drifting for one customer segment may both look like "bugs," but they need different urgency, different owners, and different communication paths.
If your team already runs automated checks, connect defect handling to automating regression testing for repeatable verification. Retest gets faster when engineers and QA can validate the fix against a stable suite instead of rebuilding the same checks by hand.
Phase three. Roll it out with operating rules
Do not launch the process across every team at once. Start with one product area or one squad that handles a meaningful mix of app, platform, and ML work. Clean up the workflow there, then expand.
Run triage on a fixed cadence. High-volume teams usually need daily review. Lower-volume teams can review a few times a week if ownership is still clear and serious issues bypass the queue through incident response.
Set a few hard rules:
- every new bug is reviewed within the agreed window
- every assigned bug has one directly accountable owner
- every deferred bug has a reason, target review date, and business sign-off where needed
- every reopened bug triggers a short root-cause review
- every ML or data issue is tagged so the team can separate code defects from model and pipeline failures
Those rules also expose staffing gaps. If bugs keep waiting for retest, QA capacity is thin. If model issues keep bouncing between backend and data teams, you likely need clearer MLOps ownership, not another status.
A simple rollout scorecard keeps the team honest:
| Area | Minimum standard |
|---|---|
| Status model | One shared workflow across product, platform, and ML defects |
| Ownership | Named triage lead and one implementation owner per bug |
| Reporting quality | Standard template used consistently |
| Verification | Independent QA, reviewer, or monitoring confirmation before closure |
| Review cadence | Bugs reviewed on a predictable schedule |
| ML coverage | Drift, data quality, and serving issues enter the process with clear tags |
Phase four. Measure stalls and tighten the process
Resist the urge to add more statuses once the workflow is live. First, watch where work stops moving.
Common failure patterns are easy to spot:
- bugs pile up in Pending Retest because nobody owns verification
- too many tickets go to Deferred without a business review date
- model or data incidents never enter the tracker, so the team cannot see repeat patterns
- reopened bugs cluster around one service, one engineer handoff, or one release path
Treat those as operating signals. If the same class of issue keeps coming back, the answer may be a better test harness, stronger release checks, a dedicated SDET, or an MLOps hire who owns model health end to end.
A good checklist does more than organize tickets. It shows whether your team structure matches the product you are shipping.
What To Do Next
A bug process proves its value the first time a release goes sideways and the team can answer three questions fast. What broke. Who owns it. How do we know the fix worked. If those answers still depend on Slack threads, memory, or whoever was online at the time, the process is not ready for a growing AI team.
Start with your last few high-cost bugs. Look at the ones that delayed a release, triggered customer escalations, or exposed model behavior that should have been caught earlier. Trace each ticket from report to closure and mark where it slowed down, changed hands too often, or closed without clear verification. That review will show whether the root issue is workflow design, role clarity, or missing capability on the team.
Then make the ownership model explicit.
One person should run triage. One person should own implementation. One person should verify the fix, whether that is QA, an engineer outside the change, or an MLOps owner checking production signals. AI teams also need a clear rule for model drift, data quality failures, and serving regressions. Some belong in the standard bug queue. Some start as incidents and only enter the backlog after containment.
Team structure matters here. If application bugs, infra defects, and ML failures keep bouncing between specialists, cycle time will stay high no matter how clean the status model looks. That pattern usually points to hiring decisions. You may need stronger QA coverage, an SDET who can build release checks around model-backed features, or an MLOps engineer who owns model health from deployment through monitoring.
As noted earlier, the lifecycle and triage ideas in this guide build on established bug management practices. The difference is operational scope. In AI products, the bug life cycle has to cover code defects and system behavior that changes after deployment.
If you want to tighten execution this week, do these three things:
- Review recent costly bugs: Confirm that state changes, ownership, and verification were clear at every step.
- Standardize one workflow: Use one status model across product, platform, data, and ML work, with incident rules called out separately.
- Fix the capability gap: Add QA, SDET, or MLOps support where bugs repeatedly stall or reopen.
If you need senior engineers who’ve run production AI systems with strong QA and MLOps discipline, ThirstySprout can help you build the team. You can Start a Pilot or See Sample Profiles to find vetted AI, ML, data, and MLOps talent that can improve reliability without slowing delivery.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.