
TL;DR
- Version Everything: Use Git for code, DVC for data, and a model registry (like MLflow) for models. This is non-negotiable for reproducibility and rollbacks.
- Automate CI/CD: Build pipelines that automatically test, validate, and deploy models. Start with Continuous Integration (CI) to gate commits, then add Continuous Deployment (CD).
- Monitor Models & Data: Deploying isn't the finish line. Track model performance (accuracy, F1) and data drift (PSI, KS tests) in production. Set up alerts for degradation.
- Use a Feature Store: To prevent training-serving skew—the #1 cause of silent model failure—use a feature store (like Feast or Tecton) to serve consistent features for training and real-time inference.
Who this is for
- CTO / Head of Engineering: You need to build a reliable, scalable AI platform without derailing your engineering roadmap. You're deciding on architecture and hiring the right talent.
- ML Platform Lead / MLOps Engineer: You're responsible for building the infrastructure that lets data scientists ship models safely and quickly.
- Founder / Product Lead: You're scoping an AI feature and need to understand the operational costs, risks, and timeline to move from a prototype to a production system.
This guide provides the framework and practical examples to implement MLOps practices that directly impact your time-to-value, operational costs, and model reliability.
1. Version Control for Code, Data, and Models
In traditional software, versioning code with Git is non-negotiable. MLOps extends this to every component. You must version your source code, datasets, and model artifacts together.
This holistic approach guarantees reproducibility—the ability to recreate any experiment or production model perfectly.
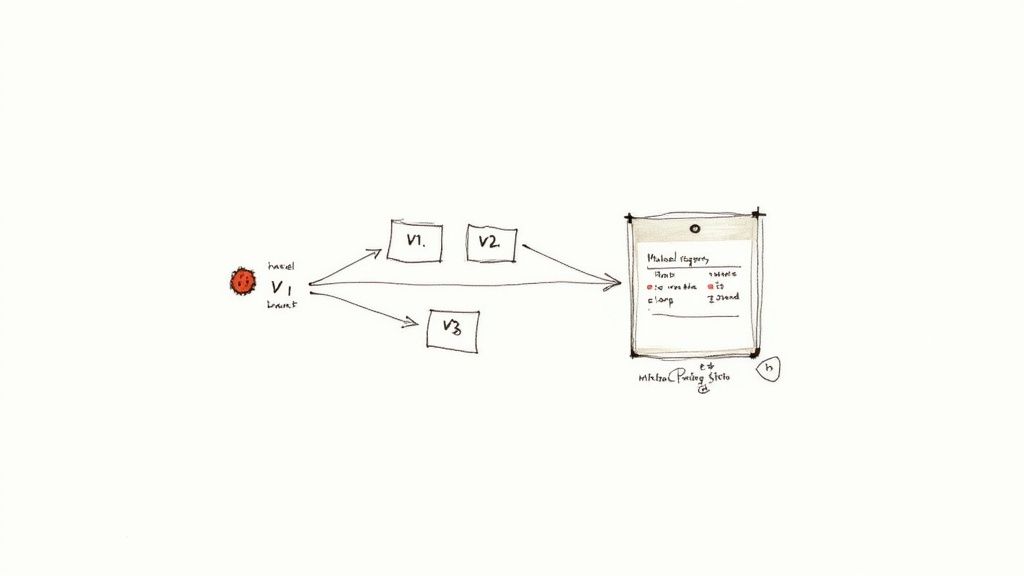 Alt text: A diagram illustrating version control for MLOps, showing code, data, and model versions (V1, V2, V3) feeding into a central model registry for tracking and rollback.
Alt text: A diagram illustrating version control for MLOps, showing code, data, and model versions (V1, V2, V3) feeding into a central model registry for tracking and rollback.
Without this, you cannot explain why a model’s performance changed, trace a bug to its root cause, or roll back to a working version. Treating data and models as versioned artifacts transforms them from opaque blobs into transparent, auditable assets.
Business Impact: Reduces risk, accelerates debugging, and enables secure, parallel experimentation.
Practical Example: Reproducible Fraud Model
A fintech company needs to retrain its fraud detection model. An MLOps engineer checks out a Git branch, updates the training data (tracked with DVC), and retrains the model.
The final model artifact is pushed to an MLflow registry. Its entry is tagged with:
- Code:
git commit hash: 8a3d... - Data:
dvc hash: f4e2... (customer_txns_2024_Q3.csv) - Model:
mlflow run ID: b1c9...
Six months later, an auditor asks to see the exact setup that produced this model. The team can reproduce it in minutes.
Actionable Implementation Checklist
- Code Versioning: Use Git for all training and application code. Enforce a branching strategy like GitFlow.
- Data Versioning: Use Data Version Control (DVC) with Git. DVC tracks pointers to data in cloud storage (S3, GCS) without checking large files into your repo.
- Model & Configuration Versioning: Use a model registry (MLflow, Weights & Biases) to version trained models. Link each version back to the specific Git commit and DVC hash used to create it.
2. Automated Testing and Validation
Rigorous automated testing separates a fragile experiment from a robust system. MLOps best practices mandate a test strategy that validates code, data, and model performance at every stage.
Systematic validation is embedded in CI/CD pipelines to catch issues early and prevent bad models from reaching production. This transforms testing from a manual checklist into an automated gatekeeper.
Business Impact: Builds trust in your AI systems and ensures every deployment is a measurable improvement, not a step backward.
Practical Example: Model Promotion Gate
A B2C app team wants to deploy a new recommendation model. Their CI/CD pipeline in GitHub Actions includes a mandatory "Model Validation" step. This step automatically:
- Loads the new model and the current production model.
- Runs both against a "golden dataset" of 500 key user scenarios.
- Fails the pipeline if the new model's precision@10 is not at least 3% better than the production model or if its average latency exceeds 40ms.
This automated gate prevents deploying a "smarter" but slower model that would harm user experience.
Actionable Implementation Checklist
- Code & Logic Testing: Use
pytestfor unit tests on data preprocessing functions and feature engineering. - Data Validation: Use Great Expectations to define contracts on your data schemas and distributions. Fail the pipeline if incoming data doesn't meet expectations.
- Model Validation: Automate tests for performance against a held-out test set, regression tests against the current production version, and fairness checks across user segments.
- Threshold-Based Gating: Codify promotion criteria in your CI/CD pipeline. Only promote a model if its accuracy is >2% higher than the current one and latency is <50ms.
3. Continuous Integration and Continuous Deployment (CI/CD)
Continuous Integration (CI) and Continuous Deployment (CD) automate the machine learning lifecycle. In MLOps, these pipelines automatically build, test, validate, and deploy entire model packages.
Without CI/CD, teams are stuck in manual, error-prone handoffs. Automation transforms the process into a reliable, repeatable workflow. This enables organizations like Netflix and Amazon to deploy hundreds of model updates daily. To implement robust deployment pipelines, explore strategies on how to build and operationalize production AI agents.
Business Impact: Achieves velocity and reliability, significantly reducing the risk of deploying faulty models and improving team productivity.
Practical Example: CI/CD for an LLM Prompt Chain
An AI team is building a customer support chatbot using an LLM. The "model" is actually a chain of prompts and tools.
- The CI pipeline (using Jenkins or GitHub Actions) runs unit tests on the prompt templating logic.
- It runs "evals" against a testbed of 50 common customer queries.
- It checks for regressions in response quality and hallucination rates.
- If CI passes, the new prompt configuration is packaged into a Docker container.
- The container is deployed to a staging environment for live testing.
- After manual approval, it's rolled out to production using a canary release.
- Separate CI and CD: Start with CI to automate testing. Once stable, add CD to automate deployments to staging and production.
- Use Containerization: Standardize training and inference environments using Docker to eliminate "it works on my machine" issues.
- Implement Canary Deployments: Route a small percentage of traffic (e.g., 5%) to the new model to safely validate its performance before a full rollout.
- Automate Model Validation: Your CI pipeline must include automated checks for performance, fairness, and bias. Block deployment if the model fails these checks. Learn more about the power of AI automation in streamlining these workflows.
- Define a Data Schema: Use a tool like Great Expectations or TensorFlow Data Validation (TFDV) to define a schema specifying data types, required columns, and value ranges. Integrate this as a mandatory CI/CD step.
- Automate Statistical Profiling: At the start of each training run, generate statistical profiles of the new data (mean, median, null counts). Compare this against a "golden" profile from a trusted dataset to detect significant data drift.
- Implement Data Quality Dashboards: Centralize data quality metrics in a monitoring dashboard (e.g., Grafana). This provides a single source of truth for data scientists and engineers to track data health over time.
- Define KPIs Pre-Deployment: Establish clear business Key Performance Indicators (KPIs). For a recommendation engine, this could be click-through rate. For a fraud model, it's the false positive rate.
- Monitor Model and System Metrics: Implement dashboards to track model-specific metrics (AUC, F1-score) and system health (CPU/GPU usage, latency).
- Set Up Automated Alerting: Use Prometheus or CloudWatch to notify the team when metrics breach thresholds, enabling a rapid response to performance drops or data drift.
- Detect Data and Concept Drift: Use statistical methods like the Kolmogorov-Smirnov (KS) test or Population Stability Index (PSI) to monitor input data distributions. Tools like Evidently AI or Fiddler can automate this.
- Choose a Tool and Standardize: Select an IaC tool like Terraform (cloud-agnostic) or a cloud-specific option (AWS CDK, Azure Bicep). Mandate its use for all infrastructure.
- Version Control Everything: Store all your IaC configuration files in a Git repository for a clear audit trail.
- Modularize Configurations: Break down infrastructure into reusable modules (e.g., a module for a Kubernetes cluster or a secure S3 bucket).
- Implement a CI/CD Pipeline for Infrastructure: Use a CI/CD tool to automate infrastructure changes. A typical GitOps pipeline should
lint,validate,plan(preview), and thenapplychanges. - Adopt an Experiment Tracking Platform: Integrate a tool like MLflow or Weights & Biases (W&B) into your training scripts. Use their APIs to automatically log hyperparameters and evaluation metrics.
- Log Everything: Capture the entire context of a run: Git commit hash, DVC hash for the dataset, and a snapshot of the environment (e.g.,
requirements.txt). - Structure Experiment Naming: Use a clear naming convention for experiments (e.g.,
bert-hyperparameter-tuning) to make comparison straightforward. This discipline is a key trait when you hire machine learning engineers. - Standardize on Docker: Create a
Dockerfilefor each ML service (e.g., training job, inference API). - Create Minimal Images: Start with slim base images (like
python:3.9-slim-buster) to reduce container size, speed up deployments, and minimize security risks. - Implement Health Checks: Add a
/healthzendpoint to your model's API. Kubernetes uses this to know if a container is alive and ready to serve traffic. - Use an Orchestrator: Deploy containers using a managed Kubernetes service (GKE, EKS, AKS) to handle scheduling, scaling, and networking.
- Define Feature Pipelines: Create version-controlled pipelines that transform raw data into features, writing to both an offline store (Snowflake) for training and an online store (Redis) for inference.
- Establish a Feature Registry: Use a tool like Feast (open-source) or Tecton to document and discover features.
- Implement Serving APIs: Build low-latency APIs for models to retrieve feature vectors from the online store for real-time predictions.
- Monitor Feature Quality: Track feature freshness, distribution, and null rates to detect data issues before they impact models.
- Standardize with Templates: Create and enforce templates. Use Model Cards for every production model and Architecture Decision Records (ADRs) for significant system changes.
- Automate Where Possible: Integrate documentation generation into your CI/CD pipelines. For example, automatically update a model card with fresh performance metrics after each retraining run.
- Keep Docs Close to Code: Store documentation (e.g.,
README.md) in the same repository as the code it describes so it can be version-controlled and reviewed. - Schedule Regular Reviews: Just like code reviews, schedule quarterly documentation reviews to ensure runbooks and diagrams are still accurate. Clarifying roles in agile software development can help assign ownership.
- Run a "Pre-Mortem" on Your Next Project: Before building, ask your team: "If this project fails six months after deployment, what would be the most likely reason?" The answers (e.g., "data drift," "slow manual deployment") will reveal your most urgent MLOps gaps.
- Implement One Foundational Practice: Choose one item from Stage 1 of the framework above. The highest-impact starting point for most teams is implementing rigorous version control for code, data, and models.
- Scope an MLOps Pilot: The best way to build momentum is with a focused win. Pick one model and build a simple CI/CD pipeline for it that automates testing and deployment to a staging environment.
- Start a Pilot: Get a senior MLOps engineer on your team in under two weeks.
- See Sample Profiles: Review candidates with proven experience at top tech companies.
Actionable Implementation Checklist
4. Data Quality and Validation
A model is only as good as its data. The principle of "garbage in, garbage out" is amplified in MLOps. Systematic data validation shifts quality control from a reactive problem to a proactive, automated part of the pipeline.
This involves automated checks at critical stages: data ingestion, pre-training, and inference. These checks validate schema, detect statistical drift, and ensure values are in expected ranges.
Business Impact: Prevents corrupted data from ever reaching a production model, saving hours of debugging and protecting revenue from faulty predictions.
Actionable Implementation Checklist
5. Model Monitoring and Observability
Deploying a model is the beginning, not the end. Without oversight, model performance will degrade in production due to concept drift—changes in the statistical properties of live data.
Alt text: Hand-drawn sketch showing a fluctuating red line graph and a data gauge with a bar chart, representing model performance monitoring.
Model monitoring establishes a feedback loop to track performance, detect drift, and ensure the model continues to deliver value. It transforms the model from a black box into a transparent, observable system.
Business Impact: Prevents business losses from silent model failures and maintains user trust. It is the foundation of responsible and reliable AI.
Actionable Implementation Checklist
6. Infrastructure as Code (IaC)
Manually configuring cloud infrastructure is a recipe for disaster. Infrastructure as Code (IaC) is the practice of managing your tech stack through code using tools like Terraform or AWS CloudFormation.
IaC is a pillar of MLOps because it makes your infrastructure versionable, testable, and reproducible. It eliminates "environment drift," where staging and production slowly diverge, leading to impossible-to-debug deployment failures.
Business Impact: Guarantees consistency across environments, drastically reducing deployment risk and accelerating experimentation.
Actionable Implementation Checklist
7. Reproducibility and Experiment Tracking
ML development is inherently experimental. Without a systematic way to track experiments, this process becomes chaotic, and knowledge is lost.
Experiment tracking involves logging every detail of a model training run: the code version, data version, hyperparameters, and resulting metrics. This ensures any result can be perfectly replicated. It transforms machine learning from an art into a science.
Business Impact: Accelerates development by making it easy to compare runs and debug failures. It's essential for collaboration and regulatory compliance.
Actionable Implementation Checklist
8. Containerization and Orchestration
A model that only works on a data scientist's laptop is a liability. Containerization with Docker packages a model and all its dependencies into a single, standardized unit.
Orchestration platforms like Kubernetes then manage these containers at scale. This combination is foundational for portability and scalability. It decouples the ML application from the infrastructure, allowing for faster deployments and more efficient resource use.
Business Impact: Creates reproducible and isolated environments, eliminating "it worked on my machine" problems and enabling high-availability production systems.
Actionable Implementation Checklist
9. Feature Management and Feature Stores
A feature store is a centralized repository for storing, retrieving, and managing ML features. It acts as the single source of truth for feature data across the entire model lifecycle.
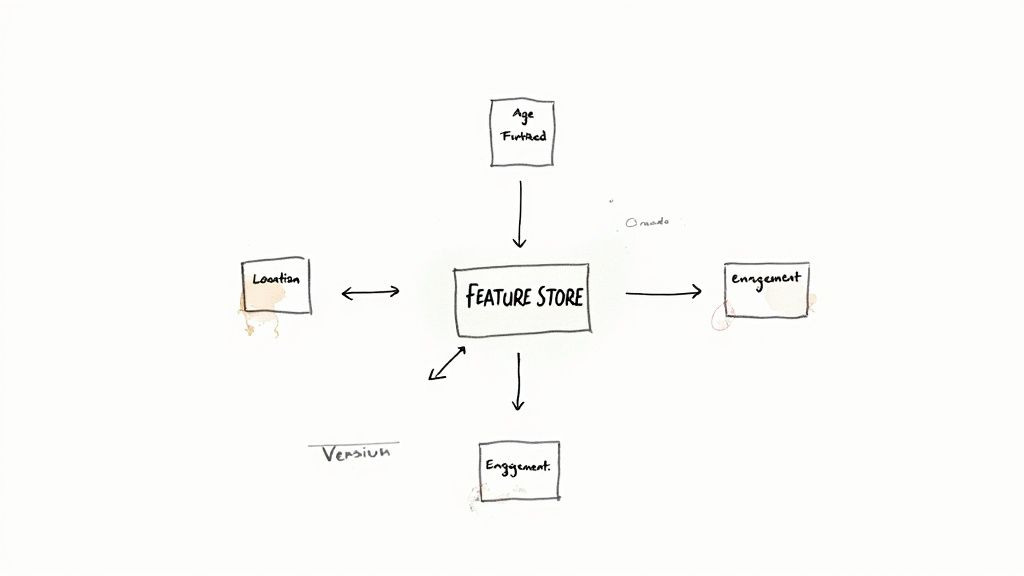 Alt text: A hand-drawn diagram illustrates a 'Feature Store' connected to 'Location,' 'Age Furthered,' and 'Engagement.'
Alt text: A hand-drawn diagram illustrates a 'Feature Store' connected to 'Location,' 'Age Furthered,' and 'Engagement.'
It directly solves training-serving skew, which occurs when features used for training differ from features used in production. A feature store ensures consistency by calculating features once and serving them to both environments.
Business Impact: Eliminates the most common cause of silent model failure, accelerates development by promoting feature reuse, and improves model reliability.
Actionable Implementation Checklist
10. Documentation and Knowledge Management
Comprehensive documentation of ML systems is not an afterthought; it's a strategic practice for managing complexity and ensuring maintainability. This includes model cards, data dictionaries, and operational runbooks.
Without strong documentation, your ML system becomes a black box that only its creators understand. This introduces significant business risk. Effective knowledge management ensures your ML practice is resilient, auditable, and scalable.
Business Impact: Reduces operational risk, accelerates onboarding for new team members, and makes proving regulatory compliance straightforward.
Actionable Implementation Checklist
Framework: Prioritizing Your MLOps Roadmap
Not all practices deliver the same value at every stage. Use this simple framework to prioritize.
What to Do Next: Your 30-Day MLOps Plan
The path to MLOps maturity is incremental. Avoid trying to boil the ocean.
The True Value of Mature MLOps
Ultimately, implementing these MLOps best practices is about managing risk and accelerating time-to-value. It’s about building the organizational muscle to not only deploy AI but to trust it, maintain it, and improve it at the speed your business demands. For further insights, you might find this list of Top 10 MLOps Best Practices for Engineering Leaders in 2025 useful for planning your team's long-term strategy.
The investment you make in a solid MLOps foundation today will enable your team to innovate faster, reduce operational fires, and deliver the intelligent products that will define your market.
Building a world-class MLOps team is the critical next step. ThirstySprout connects you with the top 2% of pre-vetted, remote MLOps and AI engineers who have hands-on experience implementing these exact best practices.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.