
Most advice on time to productivity assumes a straight line. New hire starts, learns the stack, ships tasks, hits benchmark. That model works well enough for sales, support, and many software roles.
It breaks for senior AI hiring.
A strong machine learning engineer can spend weeks on data profiling, model failure analysis, architecture reviews, and evaluation design before producing one visible feature. If you manage that ramp with generic onboarding rules, you'll misread progress, pressure the wrong behaviors, and sometimes lose the exact person you needed to keep.
TL;DR
- Time to productivity for AI teams isn't linear. Senior AI hires often go through an invisible ramp before their output becomes obvious.
- Use a multidimensional scorecard, not lines of code or ticket counts, to measure progress in remote AI teams.
- Set realistic benchmarks. Senior AI and ML roles commonly take 8 to 12 months to reach full productivity, and structured milestone plans can reduce that timeline by about 25% according to AIHR's time-to-productivity overview.
- Remote conditions change the ramp. Hiring for async communication, systems thinking, and documentation habits matters as much as hiring for model expertise.
- A 30-60-90 day onboarding plan is the fastest practical fix if your team wants better ramp time now.
Who this is for
- CTOs and Heads of Engineering building AI product teams
- Founders hiring their first senior ML or LLM engineer
- Heads of AI, MLOps, and Talent Ops trying to reduce slow ramp-up in remote teams
What Is Time to Productivity for AI Teams
At the simplest level, time to productivity is the duration between a hire's start date and the point where they perform independently against role-specific benchmarks. The standard formula is TTP = Date of Full Productivity − Start Date, as outlined in CGS Immersive's onboarding measurement guide.
That definition is fine. The usual interpretation isn't.
Teams often still treat productivity like a clean, linear slope. That's the mistake. For senior AI roles, productivity often follows a J-curve. Early work looks slow from the outside because the engineer is doing research, data inspection, architecture trade-off analysis, environment validation, and evaluation setup. Those activities don't create immediate output, but they determine whether the later system is stable or fragile.
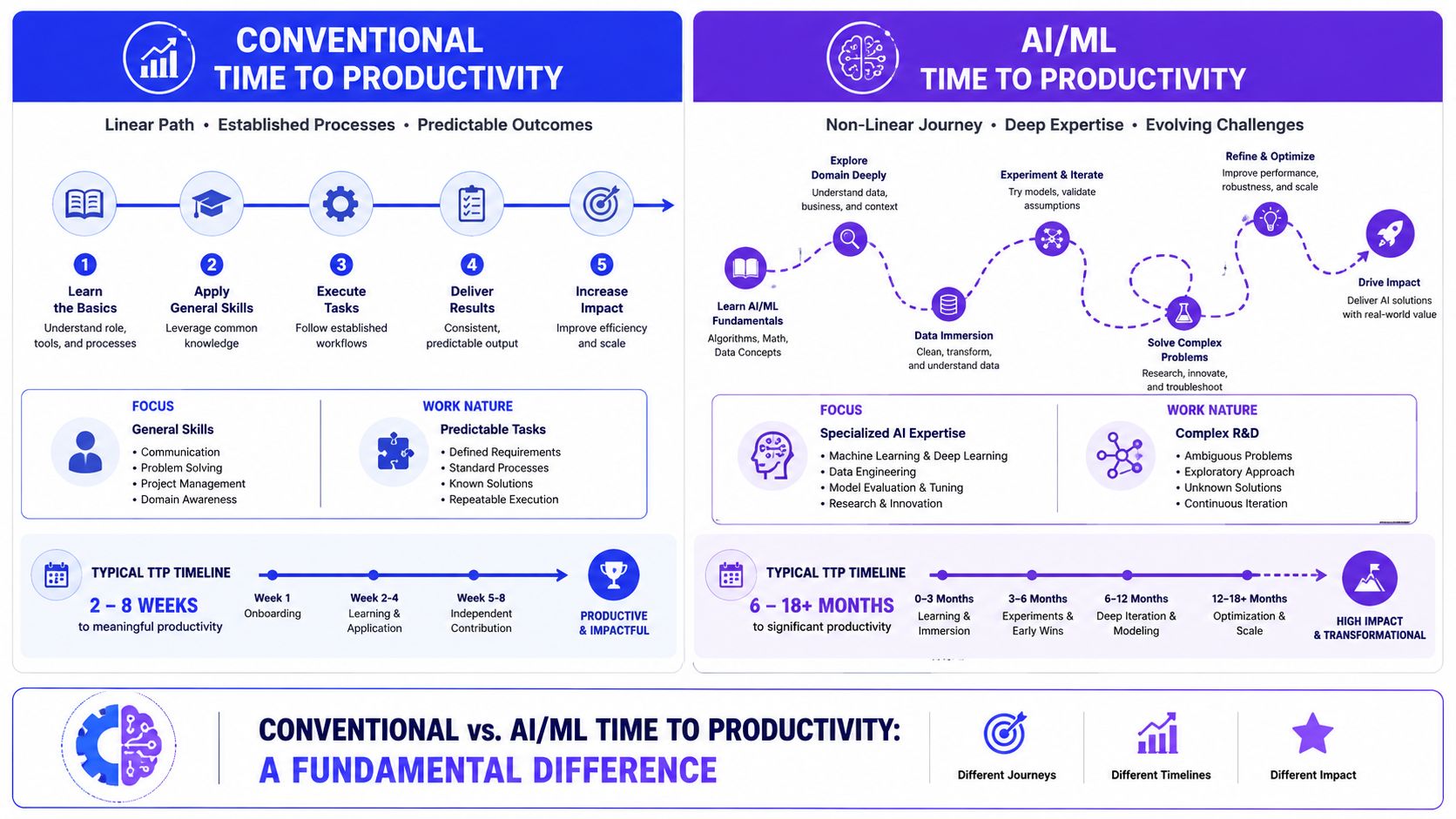
Conventional vs. AI/ML Time to Productivity: A Fundamental Difference
Why the linear model fails in AI
Senior ML engineers and LLM specialists often spend 60 to 90 days in what many leaders experience as an invisible ramp before producing a deployable unit, according to McKinsey's AI workforce discussion. If you expect visible output on a generic software timeline, you'll push the engineer toward activity that looks fast instead of work that compounds.
That usually shows up in four bad management moves:
- Premature task pressure: You ask for quick tickets instead of system understanding.
- Bad KPI selection: You reward visible motion, not independent judgment.
- False negative performance calls: You label strong hires as slow.
- Preventable churn: You lose people before they reach the part of the curve where they generate substantial value.
McKinsey's AI workforce discussion also notes that 70% of AI projects fail due to premature talent turnover, tied to misaligned expectations for senior roles. That's the business risk. Poor ramp management isn't just an HR issue. It changes product delivery, model quality, and hiring retention.
What “productive” should mean in practice
For AI teams, productivity doesn't mean “merged some PRs.” It means the engineer can make sound technical decisions without constant intervention, work within the constraints of your data and infrastructure, and improve a real system.
Practical rule: If a new AI hire is still dependent on a manager to frame problems, validate basic trade-offs, and unblock access every day, they aren't productive yet, even if they've shipped code.
That's why the best operators define productivity as independent, effective performance, not generic activity.
Measuring Productivity for Remote AI Engineers
Remote AI teams fail on measurement in a predictable way. They import software engineering metrics that are easy to count in distributed settings, then wonder why a senior ML hire looks busy for weeks without reducing real risk or improving a live system.
For senior AI work, productivity shows up first in judgment. A strong remote engineer learns which experiments are worth running, which model changes are unsafe, where the data is unreliable, and when to stop optimizing. Those signals matter more than raw ticket count because remote ramp-up is heavily research-driven and non-linear. Some weeks produce visible code. Other weeks produce a sharper evaluation plan, a cleaner dataset, or one decision that prevents a month of waste.
The scorecard I would use
I measure ramp across three dimensions: technical independence, production impact, and remote operating maturity.
That framing works better for senior AI hires because it separates activity from trust. The question is not whether the engineer finished onboarding tasks. The question is whether they can handle ambiguity, work safely inside your stack, and improve a production-relevant workflow without daily manager intervention.
Here's a practical scorecard you can adapt.
| Milestone (Days) | Objective | Key Result (Example) |
|---|---|---|
| 1-30 | Learn the system and remove access friction | Sets up local and cloud environment, reproduces one existing workflow, documents one confusing dependency |
| 31-60 | Contribute with guided independence | Owns a scoped model, data, or pipeline task and closes the loop from analysis to review |
| 61-90 | Operate with low supervision | Handles a meaningful task end-to-end, participates in incident response, proposes one measurable system improvement |
| Productivity milestone | Reach independent, effective performance | Handles routine incidents without escalation, contributes at expected team velocity, and works inside team workflows with consistent judgment |
The last row should be calibrated to your environment. In a mature ML platform team, that might mean debugging data drift, tracing a failed job, and proposing a fix without hand-holding. In an applied AI product team, it might mean improving retrieval quality or evaluation reliability while respecting latency and cost limits.
What to track in a remote setting
Remote measurement should answer one question: is this person requiring less management load each week?
Use a short weekly review and look for evidence in four areas:
- Decision quality: Are technical choices getting sharper, with clear reasoning about trade-offs?
- Unblocking behavior: Does the engineer surface blockers early, with options and a recommendation?
- System fluency: Can they explain failure modes, dependencies, evaluation gaps, and operational constraints?
- Async execution: Do written updates, design comments, and handoffs help the team move without a meeting?
Many teams misread senior AI performance. A remote engineer may spend several days reading old experiment notes, checking feature definitions, or validating an eval set before touching production code. That can be the highest-value work of the month. If your scorecard only rewards visible output, you will push people toward shallow wins and away from the system understanding that makes later work faster and safer.
For leaders managing distributed teams, the operating cadence still matters. Clear documentation, explicit ownership, and consistent manager check-ins from this guide to remote workforce management for distributed teams are especially useful for AI groups, where missing context slows judgment more than execution.
Remote AI engineers ramp faster when decisions, assumptions, and experiment history are written down. In research-heavy work, undocumented context is lost velocity.
What shortens ramp time in practice
The fastest remote AI onboarding programs combine three things: written system context, direct access to a senior technical guide, and early work on a bounded production problem.
A wiki alone is rarely enough. Senior hires need to see how your team evaluates model quality, how incidents are handled, where data is messy, and which trade-offs the business will accept. That is learned through recorded walkthroughs, design reviews, shadowing, and regular office hours with someone who knows why the current system looks the way it does.
The strongest signal that ramp is working is simple. The engineer starts bringing back decisions, not just questions.
Time to Productivity Benchmarks and Examples
Leaders usually underestimate this ramp. Senior AI hires rarely become fully effective on the same timeline as general software engineers, because they are not just learning a codebase. They are learning how your company defines model quality, which failure modes are tolerated, where the data is unreliable, and what has already been tried and rejected.
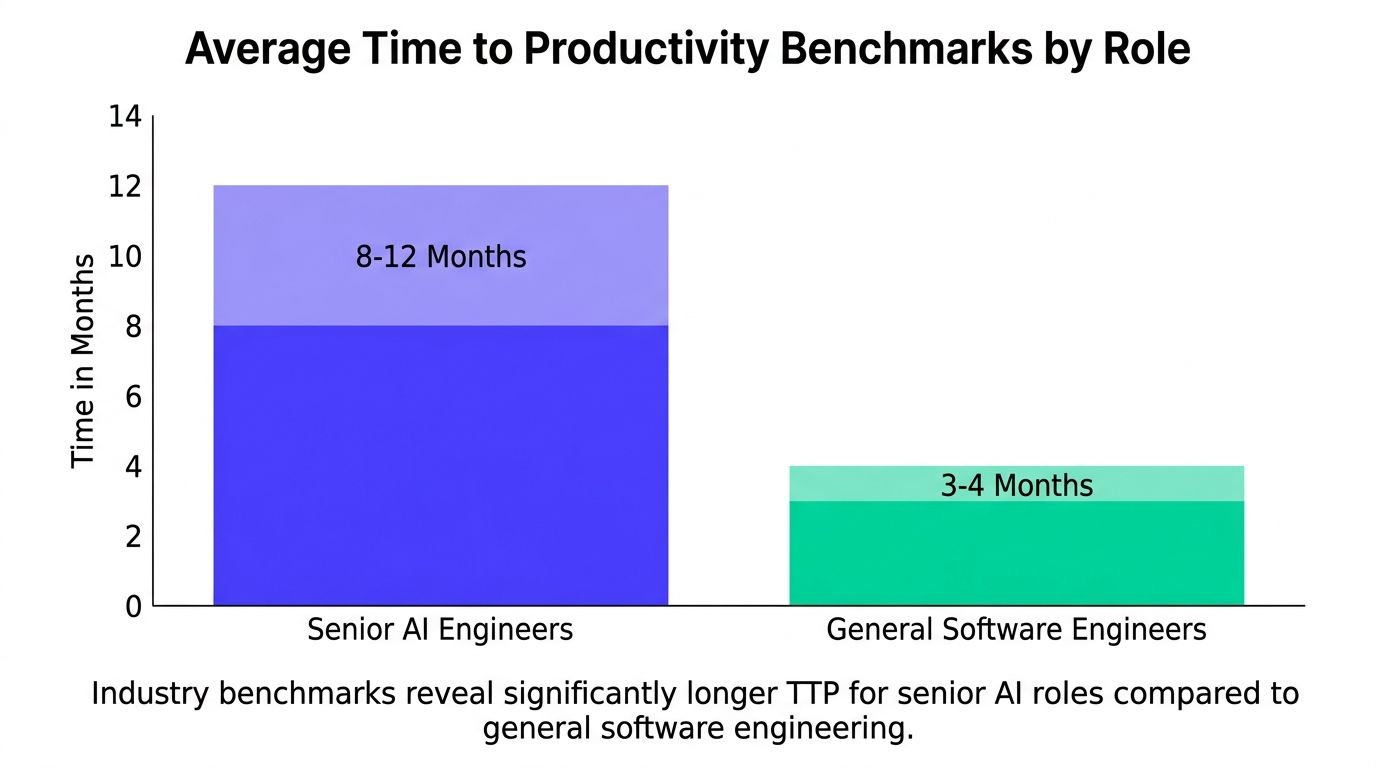
Industry benchmarks reveal significantly longer TTP for senior AI roles compared to general software engineering.
In remote teams, that gap gets wider when research context lives in Slack threads, private notebooks, and people's heads. A senior engineer can look productive early by closing tickets, while still lacking the judgment needed to change retrieval logic, retrain a ranking model, or adjust evaluation without creating downstream problems.
Example A and Example B
Two startups can hire the same senior ML engineer and get very different outcomes within 90 days.
Startup A runs standard software onboarding. The engineer receives a repo, a backlog, and scattered documentation. Offline metrics exist, but nobody can explain which one decides release readiness. Data access requires several approvals. Prior experiments are hard to trace. By month two, the engineer is still reconstructing why the current system behaves the way it does. Work gets done, but it is cautious, slower than it should be, and often duplicated.
Startup B treats AI ramp-up as a research transfer problem. The engineer gets architecture walkthroughs, recorded reviews of failed experiments, a clear map of data sources, and a safe environment to test changes against production-like evaluation rules. They still need time to build judgment, but they reach useful independence faster because the company removed avoidable delays.
That difference matters more in AI than in CRUD-heavy product engineering. Senior ML work is nonlinear. One week may produce a small code diff and a large decision. Another may invalidate a month of prior assumptions. Remote teams that handle this well usually borrow operating habits from the Madeira Remote playbook for teams, then adapt them for model development, experiment review, and written technical decision-making.
A practical benchmark helps here. By day 30, a strong senior AI hire should explain the current system, name the main quality and reliability constraints, and run bounded experiments with support. By day 60, they should own a scoped production problem and defend trade-offs in review. By day 90, they should be making sound decisions in their area without constant translation from long-tenured teammates. Full productivity often comes later, especially in companies with messy data, weak evaluation discipline, or multiple model stacks.
Teams with mature MLOps best practices for production ML systems usually shorten this curve. The reason is simple. New hires inherit reproducible workflows, visible experiment history, and clearer release gates instead of tribal knowledge.
Operator takeaway: Benchmark senior AI ramp against decision quality, system judgment, and production ownership. Ticket velocity alone will mislead you.
4 Strategies to Shorten Your AI Team's Ramp Time
Gallup's widely cited benchmark puts full productivity for a new employee at approximately 12 months, as noted in Gallup's workforce research. For expensive technical hires, waiting passively for that curve to take care of itself is a management failure.
The fastest teams shorten ramp time by removing uncertainty early and pairing new hires with meaningful, low-friction work.
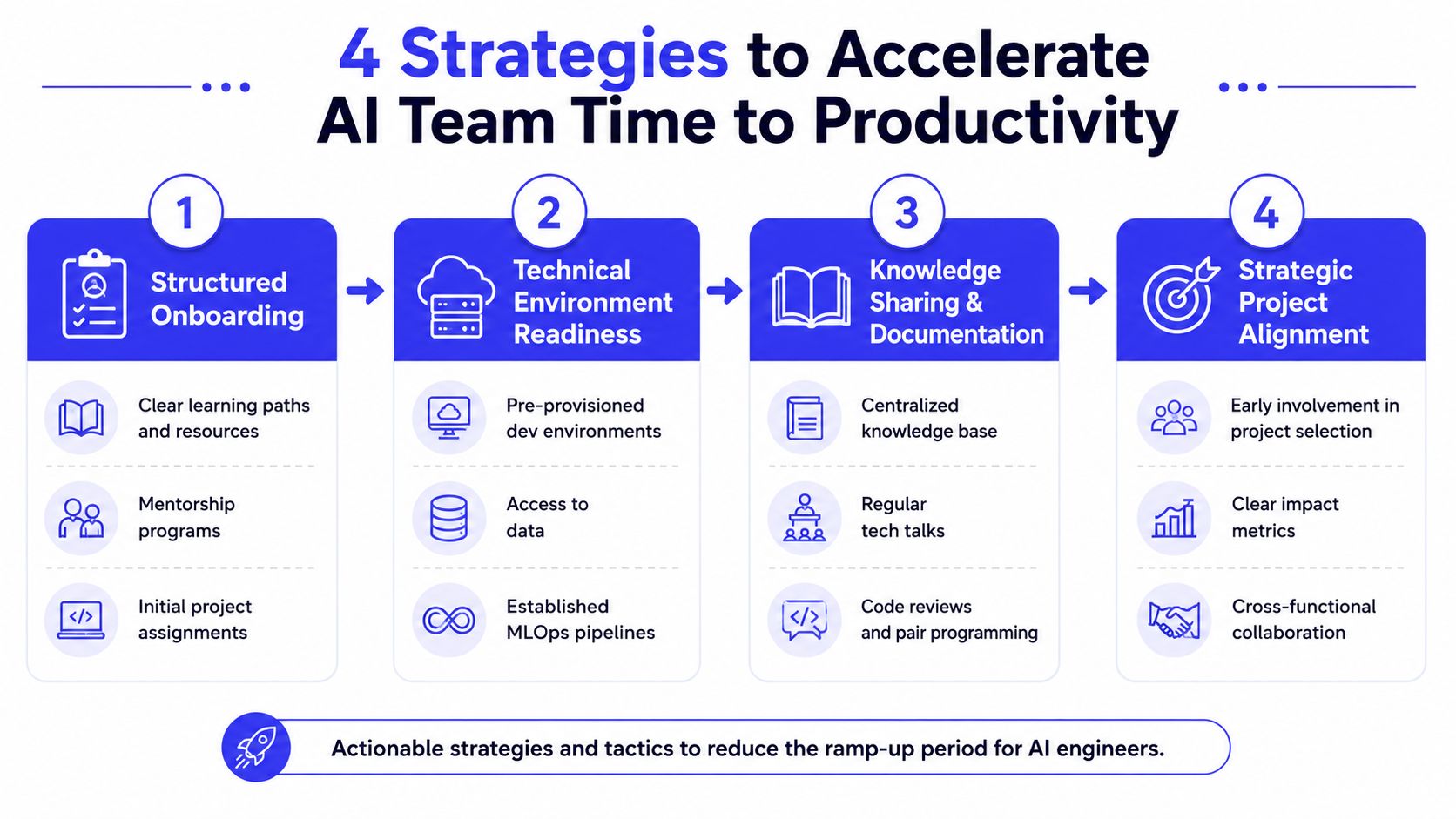
Actionable strategies and tactics to reduce the ramp-up period for AI engineers.
Build a real first two weeks
The first two weeks shouldn't feel like a scavenger hunt.
Use a written day-by-day plan that includes system access, architecture review, product context, data source mapping, and introductions to the people who own key services. New hires don't need every document. They need the right sequence.
Useful tactics:
- Front-load system context: Walk through the current pipeline, known bottlenecks, evaluation method, and open risks.
- Name decision owners: Make it clear who owns data, infra, product requirements, and deployment approvals.
- Schedule working sessions: Don't leave every transfer to self-serve reading.
Turn knowledge transfer into an operating system
Most AI teams have more hidden context than they admit. Failed experiments live in old notebooks. Architecture logic sits in Slack threads. Evaluation assumptions exist only in one staff engineer's head.
That's deadly for ramp time.
Create a single source of truth that includes:
- Past experiments: What was tried, what failed, and why it was dropped
- Model and data assumptions: Definitions, caveats, and quality concerns
- Architecture decisions: Why you chose a vector store, retrieval pattern, or orchestration approach
If you're rebuilding your remote management habits, the Madeira Remote playbook for teams is a useful companion read because it emphasizes written communication, meeting discipline, and clarity of ownership. Those aren't soft skills in AI teams. They're throughput tools.
Here's a lightweight doc structure that works well:
knowledge_base:system_overview:- current_architecture- service_owners- production_constraintsexperimentation_history:- successful_trials- failed_trials- open_questionsdata_assets:- source_tables- refresh_rules- quality_issuesoperations:- incident_runbooks- deployment_checklists- evaluation_recipesMake the technical environment boring
A new AI engineer should not spend their first month negotiating access, rebuilding environments, or guessing how to test safely.
Pre-provision what you can. Provide a sandbox that mirrors production closely enough to make early work realistic. Include sample datasets, evaluation harnesses, model configs, and a clear path to deployment review.
This video gives a useful high-level view of reducing onboarding friction in technical teams.
What fails here is partial setup. If the local environment behaves one way, staging another, and production a third, the hire spends energy on archaeology instead of engineering.
Give the first task a strategic shape
The first meaningful project should be real, but not existential.
Bad first tasks are either too small to reveal anything useful or too risky to let the person learn safely. Good first tasks have a visible outcome, narrow blast radius, and enough system surface area to teach the stack.
Two solid examples:
Evaluation improvement task
Ask the engineer to improve an existing model or retrieval evaluation workflow. They learn your data, metrics, and failure patterns quickly.Latency or reliability task
Assign one production-adjacent bottleneck, such as inference latency, retry behavior, or pipeline failure handling. That creates an early win without handing over the whole roadmap.
The best first project teaches the stack, exposes the constraints, and produces one outcome the team can trust.
How Hiring Decisions Influence Productivity Ramp
If you want shorter time to productivity, start before day one.
A lot of slow ramp-up is hired in. Teams select for model knowledge and ignore the traits that determine whether someone can become effective in a remote environment with imperfect context. That's expensive, especially because 90% of AI talent is now remote, and remote AI teams show 30 to 45% longer TTP due to context-switching latency in distributed MLOps, while a Harvard Business Review study found remote teams take 1.8x longer to reach production-ready AI models, as summarized in Harvard Business Review.
What to screen for before the offer
The fastest-ramping senior hires usually show the same patterns in interviews:
- Async clarity: They can explain complex work in writing and keep decisions moving without a live meeting.
- Ambiguity tolerance: They don't freeze when the task is under-defined.
- Systems thinking: They connect data quality, infra constraints, model behavior, and business trade-offs.
- Self-unblocking habits: They come with options, not just problems.
That's one reason hiring process design matters as much as onboarding design. If your funnel optimizes only for technical depth, you'll miss the candidate who can become useful faster in your environment. A good companion metric is how your process measures these signals early, not just how fast you close candidates. This breakdown of time-to-hire metrics for technical teams is useful if you're trying to tighten both hiring quality and hiring speed.
A better interview question
Use one behavioral question that forces the candidate to show how they work when context is incomplete:
“Tell me about a time you joined a project with weak documentation, unclear model behavior, and multiple stakeholders. How did you decide what to learn first, what to ignore, and when to escalate?”
A strong answer usually includes:
- A clear method for mapping the system
- Evidence of written communication
- A prioritization framework
- A concrete example of reducing uncertainty before writing a lot of code
A weak answer stays abstract or defaults to “I asked a lot of questions” without showing judgment.
The hiring trade-off leaders miss
Some candidates look brilliant in deep technical rounds but need heavy structure to perform. Others may look less flashy yet ramp quickly because they document well, operate asynchronously, and handle ambiguity smoothly.
For remote AI teams, the second profile often creates value sooner.
The 90-Day AI Engineer Onboarding Template
A good onboarding plan doesn't read like a checklist. It reads like a contract between the team and the hire about what progress looks like.
This template works best when each phase has one clear objective and a small set of key results. Keep the language specific. Tie each milestone to system understanding, independent execution, and measurable contribution.

A structured 90-day onboarding template for AI engineers, featuring phase-specific objectives and key results (OKRs).
Days 1 to 30
Objective: Learn the system and document it clearly.
Key results:
- Environment readiness: Access all required repositories, datasets, and tooling.
- Pipeline understanding: Map the core data and model flow from input to production output.
- Documentation contribution: Write or improve one onboarding doc based on actual friction encountered.
Days 31 to 60
Objective: Contribute to live work with guided ownership.
Key results:
- Scoped delivery: Complete one production-adjacent task such as evaluation cleanup, pipeline reliability work, or model analysis.
- Review participation: Join design or incident discussions and contribute useful technical judgment.
- Experiment discipline: Run one focused experiment with documented hypothesis, method, and outcome.
Days 61 to 90
Objective: Own a meaningful slice of the system.
Key results:
- Independent execution: Drive one task from definition through implementation and review.
- Operational fluency: Handle common issues in the stack with minimal escalation.
- Optimization mindset: Propose one improvement to reliability, latency, evaluation quality, or workflow efficiency.
A simple Notion, spreadsheet, or HRIS template is enough. What matters is weekly review. If a key result slips, don't just mark it red. Ask whether the issue is skill, missing context, or organizational friction. In AI teams, it's often the third.
Next Steps to Accelerate Your AI Team
Shortening time to productivity isn't about demanding faster output. It's about designing a ramp that matches the actual shape of senior AI work.
Start with three moves:
Audit your current onboarding flow
Compare your first 90 days against the template above. Look for access delays, missing architecture context, weak docs, and first tasks that don't build system fluency.Define productivity before the hire starts
Write down what independent performance means for each role. For a senior ML engineer, that may mean safe model iteration, reliable incident handling, or ownership of an evaluation workflow. Don't leave this vague.Hire for remote ramp ability, not just technical depth
Screen for async communication, ambiguity handling, and self-unblocking habits. Those traits shape ramp speed more than commonly recognized.
If you do only one thing this quarter, fix the first 30 days. That's where most preventable delay starts.
If you need senior AI engineers who can ramp quickly in remote environments, ThirstySprout can help. We connect companies with vetted AI, ML, data, and MLOps talent who've shipped production systems and know how to work across time zones, documentation gaps, and fast-moving product cycles. If you're hiring now, Start a Pilot, See Sample Profiles, or download your internal onboarding checklist and pressure-test your current process before the next hire starts.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.