
You need a data engineer who can build performant ML pipelines, not just solve abstract SQL riddles. Bad queries slow training jobs, inflate warehouse spend, and can poison feature sets with duplicates, leakage, or NULL bugs. That's why the best SQL query related interview questions don't sound like puzzle books. They sound like the work your team does on Monday morning.
Interview prep has caught up to that reality. Current guides repeatedly center joins, subqueries, NULL handling, aggregations, and window functions such as ROW_NUMBER, RANK, and running totals, while also pushing candidates to explain why a query works instead of only producing syntax, as noted in Data Interview's SQL interview guide. Coursera also describes a common SQL screen as a whiteboard interview where the candidate writes the query step by step and talks through the reasoning, which is a useful reminder that communication is part of the technical bar in Coursera's SQL interview overview.
If you're hiring for AI and data roles right now, stop rewarding clever one-liners. Reward production judgment. This guide gives you 10 production-focused SQL query interview questions that reveal whether someone can ship reliable data systems. If you want a broader view of how data work connects to modern AI workflows, this overview of how to use SQL and AI is a useful complement.
1. JOIN Operations
A candidate who can't reason clearly about joins will break feature pipelines. This is the first screen I trust because it exposes both query fundamentals and data thinking.
Ask something concrete: “We have a users table, a transactions table, and a risk_labels table. Build a training dataset for fraud modeling. Which join types would you use, and what failure modes would you watch for?” Don't let them answer with only definitions. Make them explain row preservation, duplicate amplification, and what happens when keys are missing.
What strong answers sound like
A solid candidate says INNER JOIN is appropriate when you only want records present in both sides. They use LEFT JOIN when preserving the base population matters, such as all users eligible for scoring, even if profile enrichment is missing. They also mention that FULL OUTER JOIN is useful for reconciliation work and that RIGHT JOIN is usually less common because teams can rewrite it as a LEFT JOIN for readability.
Mini-case: a churn model uses customers as the base table and joins support tickets and billing activity. If the engineer uses INNER JOIN everywhere, they may inadvertently drop customers with no tickets or no recent invoices. That changes the training population and can bias the model before it even starts training.
Practical rule: Every join should answer one question first. “Which table defines the population I must preserve?”
Follow-ups that separate real experience from textbook memory
- Ask about duplicates: “What happens if
transactionshas multiple rows per user?” Strong candidates discuss one-to-many explosion and pre-aggregation. - Ask about NULL keys: “Do NULLs join?” They should say no, not in standard equality joins, and explain the downstream impact.
- Ask about performance: “What would you inspect if this query got slow?” Good answers mention indexes, join order, and execution plans.
For teams hiring across database stacks, dialect context matters. Someone interviewing for Microsoft-heavy work should understand where T-SQL differs from generic examples. This comparison of Transact-SQL vs SQL is a practical reminder that syntax fluency and production fluency aren't identical.
2. Aggregation Functions and GROUP BY
A model review fails on Friday because revenue per customer looks too strong in training and too weak in production. The query passed code review. The issue was grain. Raw product events were joined to subscription charges, then grouped at the end. Every extra event row duplicated revenue, and the feature store inadvertently learned from bad math.
That is why aggregation questions matter. They test whether a candidate can turn messy event data into metrics the business can trust. For AI and data roles, that usually maps to feature engineering, cohort reporting, KPI definitions, anomaly monitoring, and label generation.
A useful prompt is: “Compute weekly active users, average sessions per active user, and total revenue by plan tier. How would you structure it, and what could go wrong?” Strong candidates start by defining the unit of analysis. One row per user per week is different from one row per session or one row per invoice, and that choice affects cost, correctness, and downstream model behavior.
The recurring failure mode is mixed grain. Candidates often aggregate too late, after they have already created duplication through joins or inconsistent filters. Production-ready candidates usually separate the problem into stages: clean the event set, establish the reporting grain, pre-aggregate where needed, then combine those outputs. That pattern reduces both query risk and warehouse spend.
Mini-case: a team is building engagement features for an LLM support assistant. The source table stores one row per interaction attempt. If the engineer averages interactions without checking retries, bot handoffs, delayed event delivery, or duplicate emissions, the feature captures logging behavior instead of customer behavior. The model may still train, but it learns noise. That shows up later as unstable thresholds, weak segment performance, and hard-to-explain drift.
Use follow-ups that test operational judgment, not just syntax recall:
COUNT(*)vsCOUNT(column): Candidates should explain how NULLs affect the result and when each count answers a different business question.GROUP BYand ordering: They should know grouped output is not ordered by default and say how they would make result ordering explicit.- Pre-aggregation strategy: Good answers mention summary tables, materialized views, or scheduled rollups when the same aggregation powers dashboards, features, and monitoring jobs.
- Metric definition control: Ask what filters belong before aggregation versus after. This exposes whether they can protect metric consistency across teams.
The rubric is straightforward. A weak answer focuses on getting a query to run. A strong answer protects metric definitions, states the grain early, calls out duplication risk, and explains how they would validate the output against known totals or a smaller sample. For AI and ML hiring, that difference matters. Bad aggregation logic does not just break a dashboard. It can distort labels, waste training spend, and push a model toward the wrong behavior.
3. Subqueries and Derived Tables
Subqueries are where many candidates reveal whether they can build logic incrementally or whether they only know isolated snippets. The question I like is simple: “Find customers whose spend is above their segment average, then return only their latest qualifying transaction.”
There are several valid solutions. That's useful. You're not scoring for one canonical answer. You're scoring for control over intermediate logic.
What to listen for
A strong candidate often starts with a derived table or a common table expression to compute segment averages, then joins that result back to transactions, then isolates the latest row with a window function or another filtering step. A weaker candidate stacks nested subqueries until neither of you can reason about the output.
Real-world scenario: in a recommendation system pipeline, you may need to identify products that overperform within category and then fetch the latest inventory state. If the candidate can't decompose the problem, they'll struggle in production where feature logic changes mid-sprint.
Don't over-reward compact SQL. In production, the query your team can debug at 2 a.m. is often the better query.
Good follow-up prompts
- Correlated subquery vs join: Ask when they'd rewrite one into the other.
- Readability trade-off: Ask whether they'd use a nested subquery in a shared analytics model.
- Execution concern: Ask how they'd verify whether the engine is repeatedly evaluating a correlated subquery.
The best answers stay pragmatic. They don't pretend every subquery is bad. They explain when it's fine, when it becomes unreadable, and when they'd break the logic into named steps.
4. Window Functions
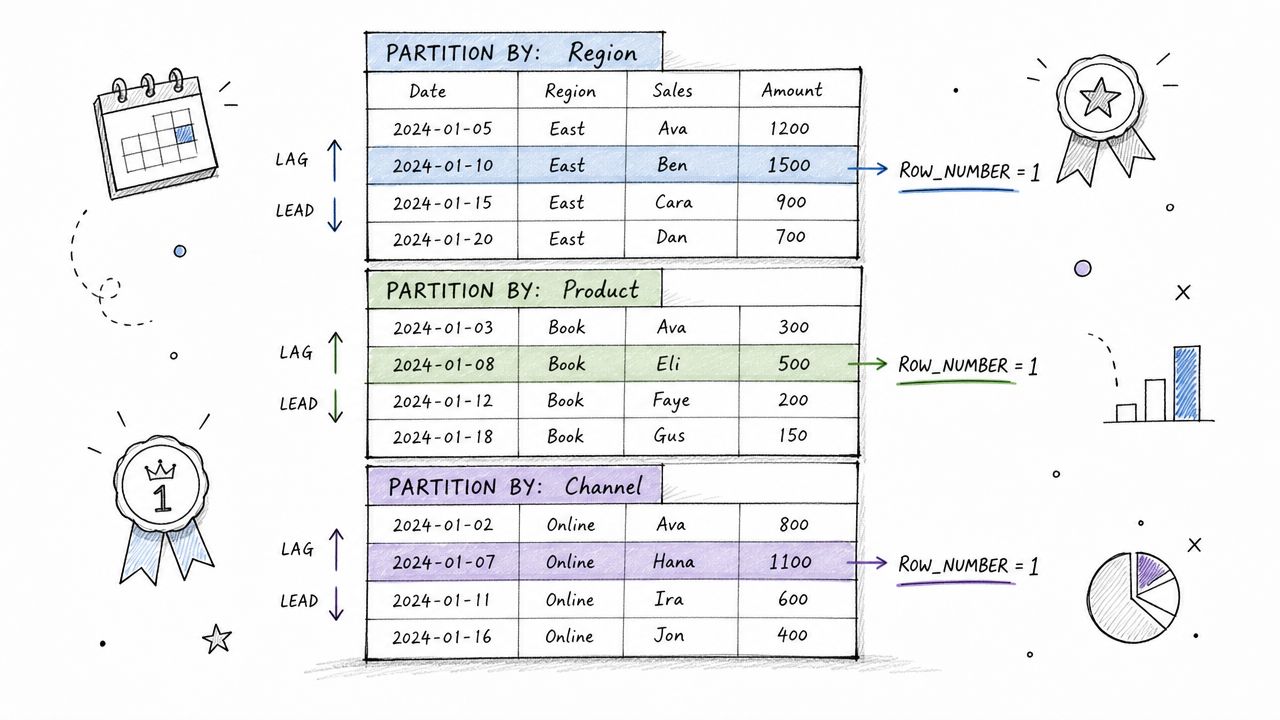
Window functions are one of the clearest markers of production-ready SQL. They're heavily emphasized in modern interview prep because they map directly to ranking, deduplication, rolling metrics, and sequential features used in real systems.
Ask a scenario instead of a definition: “For each user, return the most recent successful payment, their payment rank within account, and a rolling spend measure ordered by date.” If they immediately reach for GROUP BY, that's a warning sign.
Why this matters in AI work
Window functions are how teams build recency, frequency, sequence, and trend features without collapsing rows too early. They're also one of the most common places candidates introduce leakage. If someone computes a rolling metric without thinking carefully about frame boundaries and event time, they may accidentally use future information in training data.
Mini-case: for churn prediction, you want each customer's trailing behavior before a decision date. A candidate who uses a window but doesn't constrain ordering and frame logic may leak post-decision events into the feature.
What good sounds like:
ROW_NUMBER()for deduplication: Keep the latest record per entity.RANK()vsROW_NUMBER(): Explain ties clearly.LAG()andLEAD(): Use them for changes over time without self-joins.- Explicit ordering: They should insist on
ORDER BYinside the window.
“Show me the exact frame.” That's the sentence that catches a lot of false confidence.
5. Query Optimization and Execution Plans
A feature pipeline runs in minutes in staging, then burns hours and warehouse budget in production because one join multiplies rows and a date filter prevents partition pruning. That is the interview scenario to simulate. Query optimization questions show whether a candidate can protect cost, SLAs, and training data freshness under real workload pressure.
Ask: “Here's a slow training-data query. Walk me through how you'd diagnose it before rewriting anything.”
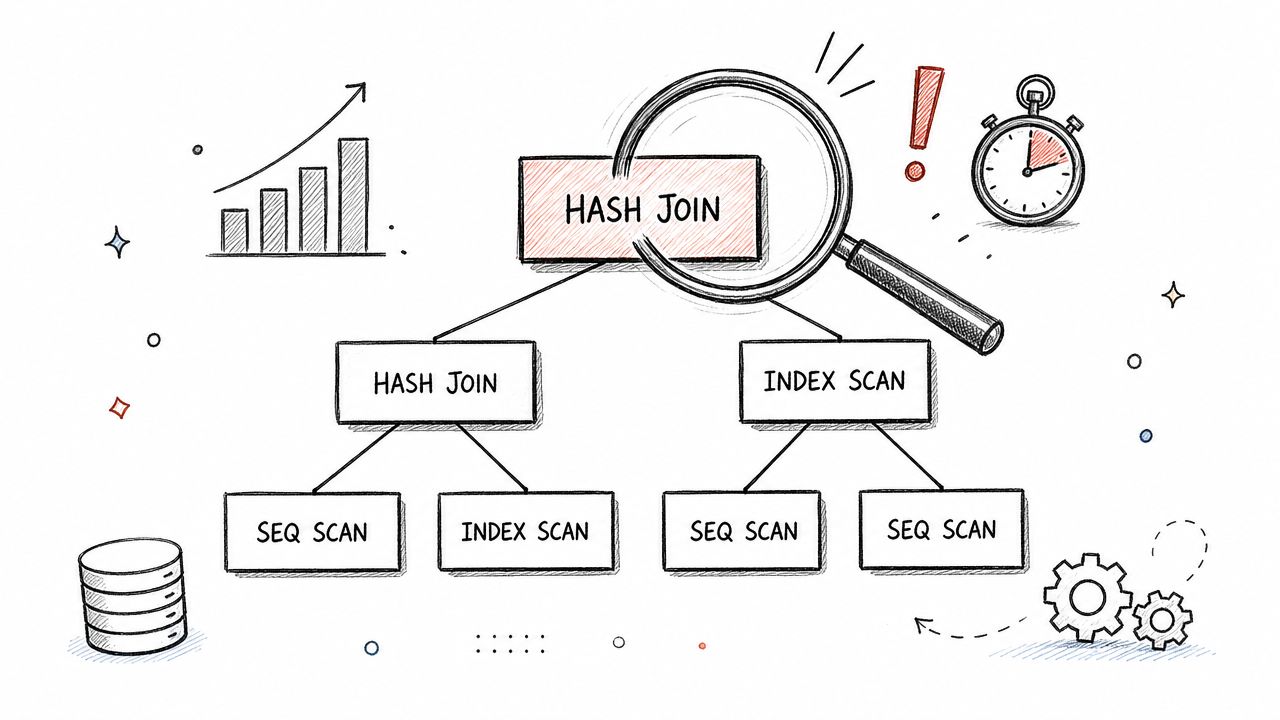
The best candidates start with the execution plan and the shape of the data. They want estimated versus actual row counts, join order, scan type, sort or hash spill risk, predicate selectivity, and the table grain on each side of every join. That matters in AI and ML work because a bad plan is rarely just a latency problem. It can delay feature generation, inflate compute spend, and hide logic errors that distort the final dataset.
A stronger interview exercise
Use a query that joins events, accounts, and model_labels. Add a function-wrapped date filter, a many-to-one join the candidate might wrongly assume is one-to-one, and an aggregation that happens after the largest join. Then ask two things: what is expensive here, and what could make the result wrong even if it finishes?
Strong answers usually cover these points:
- Plan first, syntax second: They inspect the execution plan before proposing a rewrite.
- Sargability: They call out filters like
DATE(created_at)that can block index or partition use. - Cardinality checks: They verify whether the join expands rows beyond the intended grain.
- Early reduction: They look for safe ways to filter or aggregate before large joins.
- Memory-heavy operators: They notice sorts and hash joins that can spill under larger production volumes.
- Actual business impact: They connect performance issues to missed training windows, higher warehouse cost, or stale features.
The follow-up is where seniority shows. Ask, “What would you change first, and how would you prove it helped?” A production-ready candidate talks about measuring before and after, validating row counts, checking whether the rewritten query preserves semantics, and avoiding premature tuning. I look for people who know that the fastest query is useless if it changes the population going into a model.
Engine awareness also matters. PostgreSQL, Oracle, and warehouse engines expose different planner behavior, indexing options, and execution details. A candidate does not need every vendor-specific trick memorized, but they should know that optimization is engine-dependent and say how they would adapt. This comparison of Oracle and PostgreSQL query behavior is the kind of distinction worth probing if the role spans multiple databases.
A simple rubric works well in interviews:
- Diagnoses before editing: Do they read the plan instead of guessing?
- Understands grain: Can they state the expected row count after each join?
- Protects correctness: Do they treat optimization as a data quality problem, not just a speed problem?
- Uses evidence: Do they propose
EXPLAIN, runtime metrics, and result validation?
Ask them to narrate the plan tree in plain English. That quickly reveals whether they can reason about production SQL under pressure.
6. DISTINCT and Deduplication Strategies
DISTINCT is one of the most overused bandages in SQL. It often hides a broken join, unclear grain, or poor upstream data contract. That's why this question is so effective.
Ask: “You noticed duplicate customer rows in a model-training extract. Would you use DISTINCT, GROUP BY, or ROW_NUMBER()? Why?” The right answer usually starts with, “First I'd find out why duplicates exist.”
The production mindset you want
A mature candidate distinguishes between duplicate rows and duplicate entities. Those are not the same problem. If a customer appears twice because of a join explosion, DISTINCT might suppress symptoms without fixing the logic. If a CRM sync created multiple records for the same natural key, a row-number approach with clear retention rules is often better.
Mini-case: in a lead scoring dataset, the same company can appear across several systems with different update times. The production-safe approach is often to partition by business key, order by trust rule or recency, and keep one row deliberately. That's audit-friendly. Blind DISTINCT isn't.
Use a short rubric in the interview:
- Root cause awareness: Do they ask why the duplicates exist?
- Retention logic: Can they define which row should survive?
- Bias awareness: Do they consider how deduplication changes the training population?
The strongest answers also mention validating downstream effects. Removing “duplicates” can erase legitimate repeat behavior if the true grain is transactional.
7. CASE Statements and Conditional Logic
CASE questions reveal whether the candidate can encode business logic safely. In AI pipelines, that matters because many model features are really just SQL business rules with good naming.
Ask something like: “Create a risk tier from transaction amount, refund history, and account age. How would you write it so another engineer can maintain it?” This surfaces both SQL fluency and judgment.
What strong candidates do differently
They keep conditions ordered and mutually understandable. They explain precedence. They call out edge cases such as overlapping rules, negative values, and missing fields. Better candidates also say when a lookup table would be cleaner than a giant in-query CASE.
Real-world example: a support triage model often needs derived labels like “urgent,” “standard,” or “self-serve.” You can encode that in CASE, but once policy changes every quarter, a reference table becomes easier to govern and review.
A practical scoring lens:
- Simple derivation: Good for feature bucketing and output labeling.
- Overgrown rule engine: Warning sign. Ask whether they'd move logic into a table.
- Testing mindset: Strong candidates mention checking boundary values and category coverage.
If the business rule has an owner outside engineering, put it somewhere that can be reviewed without reading a long SQL statement.
8. NULL Handling
NULL handling is where polished interviews turn into realistic ones. Candidates often know the syntax but forget the semantic traps.
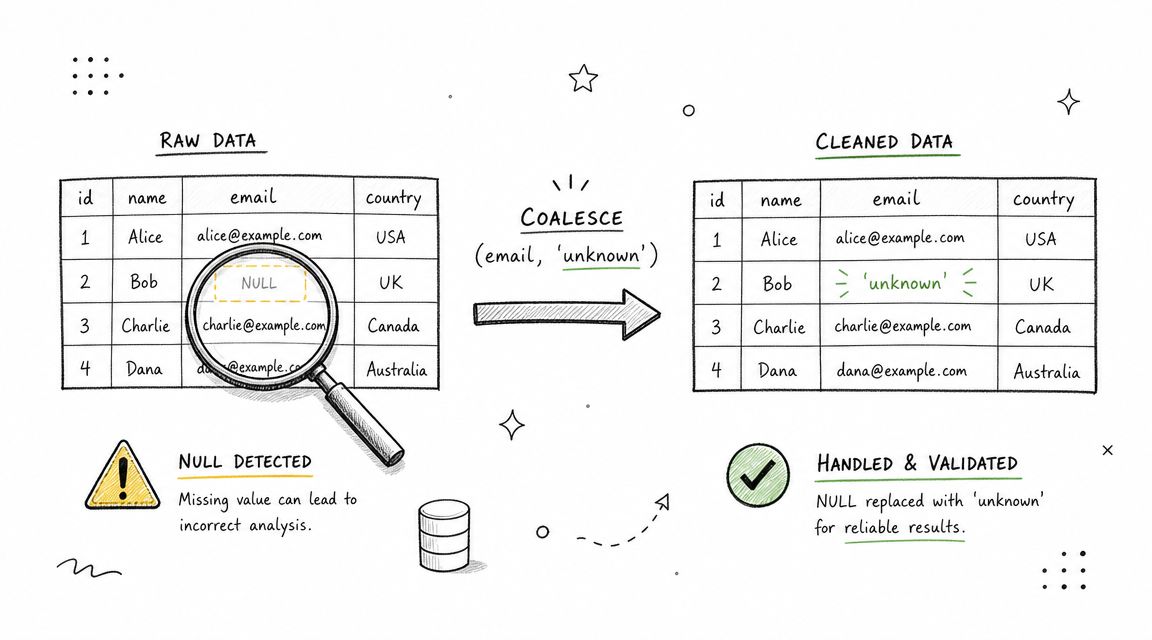
Ask this directly: “How would NULLs affect joins, filters, counts, and model features in this query?” Then give them a dataset where phone number, region, and signup source are missing for part of the population.
What this uncovers fast
Good candidates know to use IS NULL and IS NOT NULL, not = NULL. They know COUNT(column) skips NULLs while COUNT(*) counts rows. They also understand that a default fill like COALESCE(region, 'unknown') is a business choice, not only a syntax trick.
Mini-case: a recommendation model uses geography as a feature. If missing geography is implicitly mapped to a real region code or dropped through a join, model behavior changes in ways the team may not detect until after launch.
Ask follow-ups that connect SQL hygiene to AI quality:
- Feature semantics: Is “unknown” a valid category or a placeholder for bad ingestion?
- Join behavior: What happens when the join key is NULL?
- Aggregation bias: How does missingness affect averages and counts?
The candidate doesn't need a philosophical lecture. They need to show they treat missing data as part of data quality, not an afterthought.
9. Transactions and ACID Properties
Many SQL interviews skip transactions for analytics hires. That's a mistake if the role touches feature stores, ingestion, training snapshots, or production scoring data.
Ask this: “You're loading a model-ready dataset into a feature store while another process is updating source tables. How do transactions and isolation levels affect correctness?” This quickly reveals whether the person has worked near live systems.
Signals of production readiness
A strong candidate explains atomicity in practical terms. Either the batch lands consistently or it doesn't. They also discuss isolation as a trade-off, not a trivia answer. Higher isolation can protect correctness, but it may increase locking or contention depending on the workload and engine.
Mini-case: your team writes model metadata and feature values in separate steps. If one succeeds and the other fails outside a transaction boundary, reproducibility suffers. You can't reliably answer which feature set produced a given model artifact.
Useful follow-ups:
- Deadlocks: What causes them, and what retry strategy would you use?
- Snapshot consistency: How would you guarantee a point-in-time training extract?
- Transaction scope: Why should long transactions be avoided?
Coursera's guidance that candidates should restate the problem, inspect schema, identify needed columns, and build the query incrementally is also relevant here. The same structured thinking helps people reason about transactional correctness before they write code.
If your candidates will work in Oracle-heavy environments or adjacent enterprise systems, they should also be comfortable with core relational concepts in context. This overview of RDBMS in Oracle is a useful anchor for that discussion.
10. Common Table Expressions and WITH Clauses
A candidate who uses CTEs well usually writes SQL that another engineer can review, test, and modify without breaking the pipeline. In AI and data roles, that is not a style preference. It affects how quickly teams can validate feature logic, trace bad training data, and fix production issues under time pressure.
Ask a scenario-based question: “Build a cohort analysis query with separate steps for user eligibility, first activity date, and retention calculation. Would you use nested subqueries or CTEs, and why?” The answer should reveal more than syntax. Strong candidates explain where they would separate cleanup, business rules, and final metrics so each step can be checked against source data.
The Practical Impact of CTEs
Well-named CTEs turn a long query into an auditable sequence of transformations. That is useful in model development, where reviewers often need to answer specific questions fast: Which rows were filtered out, where leakage could enter, and whether a metric was computed before or after deduplication. If a candidate cannot structure that flow clearly, they often struggle with production debugging later.
There is also a trade-off worth probing. CTEs improve readability, but they do not guarantee a good execution plan. Some database engines inline them. Others may materialize them depending on the optimizer and query shape. A production-ready candidate knows that “cleaner SQL” and “faster SQL” are related but separate concerns.
Mini-case: a team building retention features for a churn model defines one CTE for raw event filtering, one for first active date, one for cohort assignment, and one for retention windows. That query is easier to validate than a single nested statement because each stage maps to a business definition the team can review with product or analytics stakeholders. It also reduces the chance of unknowingly carrying a bad filter into the final training set.
As noted earlier, current interview prep material reflects that advanced SQL questions now go well beyond basic SELECT, JOIN, and GROUP BY exercises. For hiring, the better signal is whether the candidate uses CTEs to make data logic inspectable.
What to score in the answer
- Naming quality: Do CTE names describe the dataset or rule being produced, not just
cte1ortemp_a? - Step boundaries: Can the candidate separate eligibility rules, transformations, and final metrics into stages that match the business logic?
- Validation approach: Do they describe how they would run each CTE independently, compare row counts, and spot unexpected drops or duplication?
- Optimization awareness: Do they know they still need to inspect the execution plan, especially for large feature-generation queries?
- Production judgment: Can they say when a CTE is the right abstraction, and when a temp table, persisted intermediate table, or materialized view would be better?
The strongest candidates treat CTEs as a tool for correctness and maintainability first, then verify performance with the actual engine behavior. That is the habit you want in someone who will own SQL feeding models, dashboards, or customer-facing decisions.
10-Point Comparison of SQL Query Interview Topics
| Feature | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes ⭐📊 | Ideal Use Cases 📊 | Key Advantages & Tips 💡 |
|---|---|---|---|---|---|
| JOIN Operations (INNER, LEFT, RIGHT, FULL OUTER) | 🔄 Medium, requires correct join logic and index design | ⚡ Moderate, can be heavy on memory/IO without indexes | ⭐ Produces combined, relational datasets; risk of leakage/duplication 📊 | 📊 Feature assembly from multiple tables (recommendation, fraud, sensor merges) | 💡 Essential for feature engineering; use EXPLAIN, index join cols, validate no leakage |
| Aggregation Functions and GROUP BY | 🔄 Low–Medium, straightforward but sensitive to cardinality | ⚡ Low–Moderate, cost rises with number of groups and distinct keys | ⭐ Fast statistical summaries and time-bucketed features 📊 | 📊 Daily/monthly metrics, time-series summaries, percentile-based features | 💡 Precompute common aggregates as materialized views; check NULL handling |
| Subqueries and Derived Tables (Nested Queries) | 🔄 Medium–High, nested and correlated forms add complexity | ⚡ Variable, correlated subqueries can be very expensive | ⭐ Enables complex stepwise transformations; potential performance hit 📊 | 📊 Isolated transforms, cohort extraction, threshold calculations | 💡 Prefer CTEs, avoid correlated subqueries, EXPLAIN to verify plans |
| Window Functions (PARTITION BY, OVER, ROW_NUMBER, RANK) | 🔄 Medium, requires understanding partition/order/frame specs | ⚡ Efficient relative to correlated subqueries but needs proper indexing | ⭐ Per-row advanced features (rolling averages, ranks) without collapsing rows 📊 | 📊 Time-series rolling features, ranking, lag/lead features, deduplication | 💡 Specify ORDER BY and frame bounds; combine windows to reduce scans |
| Query Optimization and Execution Plans (EXPLAIN/ANALYZE) | 🔄 High, interpreting plans and making changes needs expertise | ⚡ Low runtime overhead for analysis tools but high engineering time | ⭐ Identifies bottlenecks and reduces runtime and infrastructure cost 📊 | 📊 Scaling pipelines, diagnosing slow queries, index and schema tuning | 💡 Run EXPLAIN/ANALYZE, update stats, monitor plan changes over time |
| DISTINCT and Deduplication Strategies | 🔄 Low–Medium, simple to use but strategy selection matters | ⚡ Can be expensive (sorting); ROW_NUMBER often more efficient | ⭐ Clean, deduplicated datasets; risk of over-removal or bias 📊 | 📊 Removing duplicates, keeping latest per entity, cleaning ETL inputs | 💡 Understand duplicate source; prefer ROW_NUMBER for selective dedupe |
| CASE Statements and Conditional Logic | 🔄 Low–Medium, intuitive but complex nesting is hard to maintain | ⚡ Low, inline evaluation; many conditions may add CPU cost | ⭐ Derives categorical features and encodes business rules in SQL 📊 | 📊 Bucketing values, feature transformations, handling edge cases | 💡 Use lookup tables for complex mapping; test edge cases thoroughly |
| NULL Handling (ISNULL, COALESCE, IFNULL) | 🔄 Low, simple APIs but semantic pitfalls are common | ⚡ Low, functions are cheap; correctness impact > perf impact | ⭐ Prevents silent errors and ensures correct feature values 📊 | 📊 Imputation, validation of missing fields, safe aggregations | 💡 Use COALESCE/IS NULL explicitly; check aggregate behavior with NULLs |
| Transactions and ACID Properties | 🔄 Medium–High, requires design for isolation and recovery | ⚡ Can be heavy, locks and long transactions reduce concurrency | ⭐ Ensures atomic, consistent snapshots and reproducible datasets 📊 | 📊 Atomic feature-store updates, consistent training data loads, syncs | 💡 Keep transactions short, choose proper isolation, add retry logic |
| Common Table Expressions (CTEs) and WITH Clauses | 🔄 Low–Medium, improves readability; some optimizer caveats | ⚡ Low–Moderate, optimizer-dependent materialization and cost | ⭐ Modular, maintainable multi-step transformations and recursion 📊 | 📊 Multi-stage feature pipelines, readable transformations, hierarchical queries | 💡 Name CTEs descriptively, test each CTE, EXPLAIN to confirm efficient plans |
Your SQL Interview Scorecard and Next Steps
A candidate writes a query that passes the toy prompt, then joins two large tables at the wrong grain and inflates revenue by 18 percent. In an AI or data platform role, that mistake does not stay inside the interview. It turns into bad dashboards, mislabeled training data, wasted warehouse spend, and long debugging cycles after the model output looks "off."
That is why the scorecard should measure production judgment, not syntax recall.
I use six dimensions and score each one separately: problem framing, correctness, data quality judgment, performance reasoning, SQL dialect awareness, and communication. A candidate who is fast but careless with duplicates or NULL behavior is risky. A candidate who writes slower but checks grain, explains trade-offs, and knows how the engine will execute the query is usually the better hire for systems that feed models or customer-facing metrics.
A practical interview loop is simple:
- Start with one business-grounded query. Use joins, filters, and aggregation tied to a realistic metric.
- Add one failure-mode prompt. Ask what changes if late-arriving records, duplicate events, sparse dimensions, or NULL keys show up.
- Finish with one production follow-up. Ask how they would test the result, reduce compute cost, or make the logic safe to reuse in a pipeline.
This format exposes how a candidate handles ambiguity and pressure. It also shows whether they understand the connection between SQL choices and downstream impact. A careless DISTINCT, an unnecessary cross join, or a weak transaction boundary can affect cloud cost, feature correctness, and model reproducibility.
Use a rubric with clear signals:
- Strong hire: clarifies table grain early, states assumptions, checks edge cases, discusses execution trade-offs, and explains how to validate outputs.
- Borderline: gets to a working answer but misses failure modes, cannot explain plan quality, or treats dialect differences as irrelevant.
- Risky: writes plausible SQL without checking correctness, uses patterns mechanically, or cannot connect query design to data quality and business impact.
External prep guides can help candidates organize practice, and broad SQL interview coverage tends to cluster around the same core topics discussed earlier: joins, aggregations, subqueries, window functions, NULL handling, CTEs, and query tuning. The useful signal for interviewers is not that these topics appear often. It is that each one maps to a real production failure mode. Joins test grain discipline. Window functions test precision under ranking and time-series logic. Execution plans test whether the candidate can control cost before a scheduled job starts scanning far more data than intended.
For mixed analyst, analytics engineering, and data science hiring, this set of SQL and stats interview questions is a reasonable supplement. Keep it in a supporting role. The center of the process should stay on production readiness, because that is what protects model quality, reporting trust, and engineering time.
If you need outside help, ThirstySprout is one option for hiring data and ML engineers with production experience. The useful filter is not a bigger bank of interview questions. It is access to candidates who can explain why a query is correct, what it costs to run, and how it can fail once real data hits it.
If you're hiring for AI, data engineering, or ML platform work, ThirstySprout can help you meet vetted engineers who've shipped real systems and can handle SQL screens that test production readiness, not just syntax recall. Start a pilot or review sample profiles to tighten your hiring loop quickly.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.