
You’re probably making this choice under pressure. The product roadmap says “launch the AI feature.” Finance wants a clear infrastructure budget. Your team wants a stack they can operate without hiring a museum of specialists. And the worst outcome isn’t picking the slower database. It’s picking the one that slows your company down.
For most new AI and SaaS products, PostgreSQL is the default choice. It gives you strong performance, low lock-in, easier cloud portability, and a developer-friendly ecosystem. Oracle still earns its place when your system is mission-critical, your throughput demands are extreme, and your tolerance for operational surprises is close to zero.
The practical question in oracle vs postgresql isn’t which database is “better” in the abstract. It’s which one fits your workload, your hiring plan, and your margin structure.
A Quick Framework for Choosing Your Database
If you need a fast answer, start here. Achieving a solid first decision often involves scoring five areas: workload, cost tolerance, scaling model, team skills, and operational risk.

A side by side decision table
| Decision area | Oracle | PostgreSQL | Better fit when |
|---|---|---|---|
| Primary use case | Strong fit for enterprise-grade, mission-critical systems with heavy OLTP pressure | Strong fit for custom apps, SaaS platforms, AI products, and mixed workloads | Pick Oracle for the hardest uptime and throughput requirements. Pick PostgreSQL for most net-new product builds. |
| Cost model | Commercial per-core licensing drives higher total cost of ownership | Open-source license removes licensing fees and improves portability | PostgreSQL wins if budget discipline matters early. |
| Scaling pattern | RAC is built for active-active clustering and very high concurrency | Replication and ecosystem tools support scale, especially in cloud-native setups | Oracle fits extreme transactional scale. PostgreSQL fits flexible growth. |
| Team model | Best with experienced Oracle DBAs and formal ops discipline | Better for product engineers, platform teams, and DevOps-heavy orgs | PostgreSQL is usually easier to staff for startups. |
| AI and data engineering fit | Powerful built-in enterprise features, but more proprietary choices | Extensible ecosystem, easier integration into modern MLOps stacks | PostgreSQL is usually the better default for AI/SaaS iteration speed. |
One verified performance summary captures the trade-off well. PostgreSQL delivers 80–90% of Oracle’s enterprise-grade performance for most modern workloads at a fraction of the cost, while built-in logical replication since version 10 and native MVCC make it attractive for cloud-native systems and MLOps stacks, according to Newt Global’s comparison.
The five-question scorecard
Use these questions in your architecture review:
Is your core workload transactional or mixed?
If you’re building a core ledger, order pipeline, or another write-heavy system where predictable throughput matters more than flexibility, Oracle deserves a serious look. If your product mixes app traffic, analytics, feature storage, internal tooling, and AI metadata, PostgreSQL is usually the cleaner fit.Can you absorb premium database costs without distorting roadmap choices?
If database licensing changes how many engineers you can hire, that’s a strategy problem, not just an infrastructure line item.Do you need built-in clustering from the vendor, or are you comfortable composing your own stack?
Oracle gives you more out of the box. PostgreSQL often gives you more freedom, but your team has to assemble and operate parts of the platform.Who will run this system at 2 a.m.?
Oracle rewards specialized DBA depth. PostgreSQL aligns better with teams that already work in containers, infrastructure-as-code, managed cloud services, and standard observability tooling.What’s harder for your business to tolerate: high software cost or operational variance?
That is the trade.
Practical rule: If you’re a startup or scale-up building a new AI product, choose PostgreSQL unless you can name a specific Oracle capability you need on day one.
This is the same discipline you’d use in any major stack decision. If your broader product strategy still mixes custom engineering with platform buying, this guide on build vs buy software decisions is a useful companion.
Comparing Database Architecture and Core Features
The architectural gap between Oracle and PostgreSQL explains most of the downstream behavior that teams feel in production. Query behavior, failover strategy, tuning effort, memory pressure, and hiring needs all trace back to how each system is built.
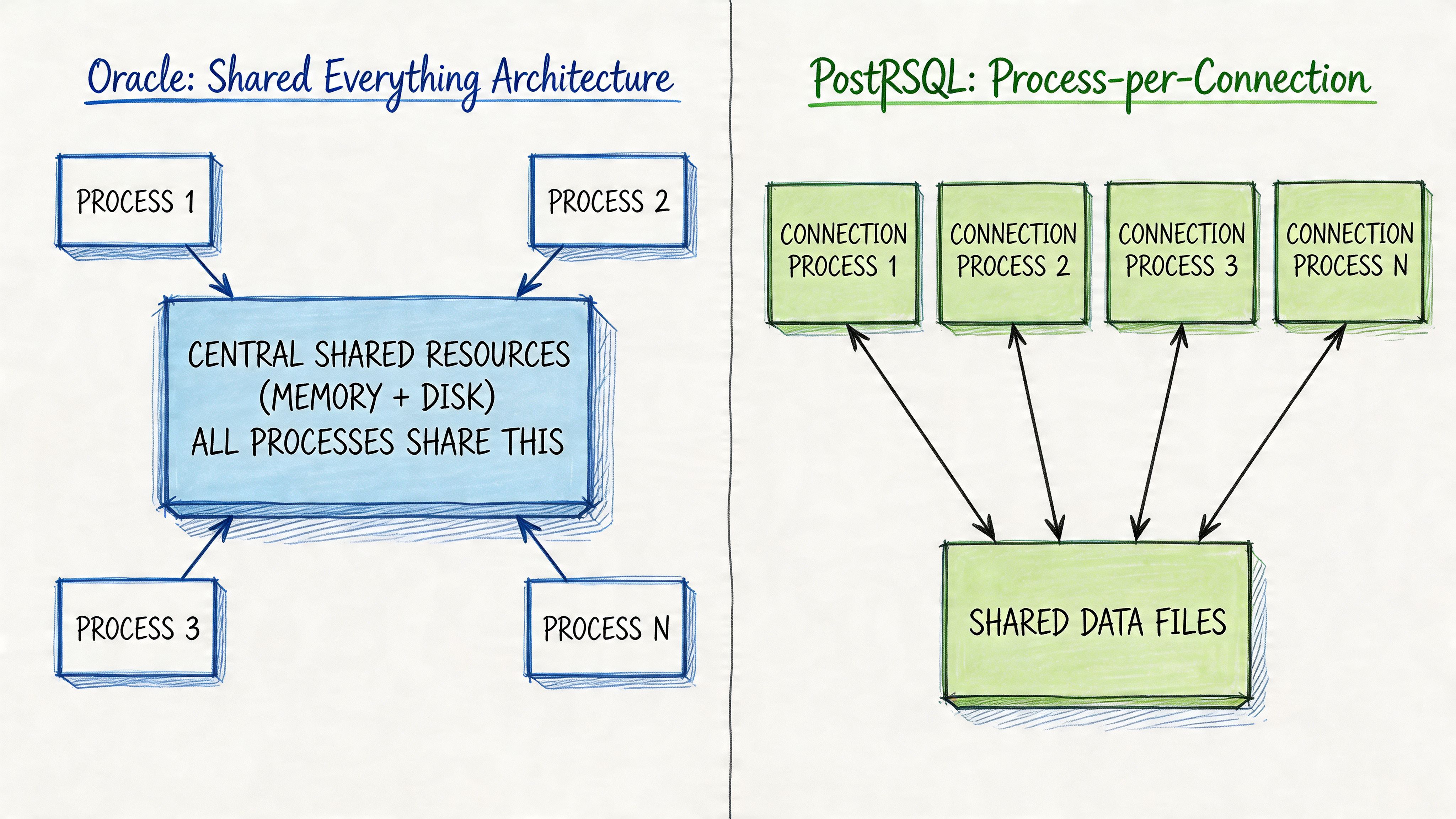
Oracle favors integrated enterprise control
Oracle uses a shared-everything architecture. In practical terms, that means shared memory structures, coordinated background processes, and a tightly integrated operational model. That design gives Oracle a reputation for predictable behavior under heavy enterprise load.
Oracle's built-in features are particularly important. Automatic Memory Management, Result Cache, In-Memory Column Store, and Resource Manager give operators more out-of-the-box tools for tuning and isolation. For large analytical workloads and high-volume online transaction processing, that can shorten the distance between “installed” and “production ready.”
The downside is operational weight. Oracle doesn’t just ask for good engineers. It often asks for specialized Oracle engineers. That changes hiring, incident response, and how quickly a startup can experiment.
PostgreSQL favors modularity and transparency
PostgreSQL uses a process-per-connection model with shared buffers and operating system caching. That sounds less elegant on paper than a giant integrated enterprise platform, but in modern product teams it often feels easier to reason about.
You can see what’s happening. You can tune it with familiar Linux and cloud-native habits. You can connect it to a broader ecosystem without immediately stepping into a proprietary workflow. PostgreSQL’s native Multi-Version Concurrency Control (MVCC) also helps reduce read-write blocking, which is useful in AI systems that continuously ingest, transform, and serve data.
What PostgreSQL gives you in flexibility, it sometimes asks you to repay in assembly work. Connection pooling may involve pgBouncer. Distributed scale may involve Citus. High-availability orchestration may involve Patroni. That’s not necessarily bad. It just means your architecture is more composed than purchased.
PostgreSQL usually feels like a platform your engineers can shape. Oracle usually feels like a platform your DBAs can govern.
How this affects AI and data workloads
Many oracle vs postgresql comparisons often stay too shallow. AI/SaaS teams rarely run a single neat workload. They run transactional APIs, event ingestion, feature generation, model metadata, background jobs, and operational analytics at the same time.
For those teams, PostgreSQL’s extensibility is a major advantage. Foreign Data Wrappers (FDW) make it easier to connect to external systems, including vector-oriented components in a broader AI stack. Extensions also make PostgreSQL friendlier to teams that want one operationally familiar database to support multiple adjacent jobs.
Oracle’s answer is different. It gives you more enterprise-grade capability inside the product itself. That can be valuable if your organization prefers vendor-backed features over ecosystem composition.
According to Bytebase’s Oracle vs Postgres analysis, Oracle’s built-in enterprise performance features provide out-of-the-box optimization, while PostgreSQL leans more on manual tuning, JIT compilation, and tools like pgBouncer or Citus. The same analysis also notes that PostgreSQL’s FDW can help AI startups integrate with vector stores, while Oracle’s RAC and flashback technology remain strong options for environments that need zero-downtime recovery expectations.
A practical architecture check
Before you choose, sketch your likely year-one stack.
- If you expect one primary transactional system with strict operational controls, Oracle’s integrated model may line up well.
- If you expect several evolving services around one core database, PostgreSQL usually fits the reality better.
- If your team is strongest in platform engineering, PostgreSQL is easier to operationalize with existing habits.
- If your team already includes Oracle DBA depth, Oracle becomes much more realistic.
A database isn’t just a storage engine. It’s a staffing decision, an incident model, and a product velocity choice.
Analyzing Performance, Scalability, and Availability
The cleanest way to think about performance is simple. Oracle tends to win when you push enterprise OLTP hard. PostgreSQL tends to hold up very well for modern product workloads, especially when you care about flexibility and cost as much as raw peak throughput.
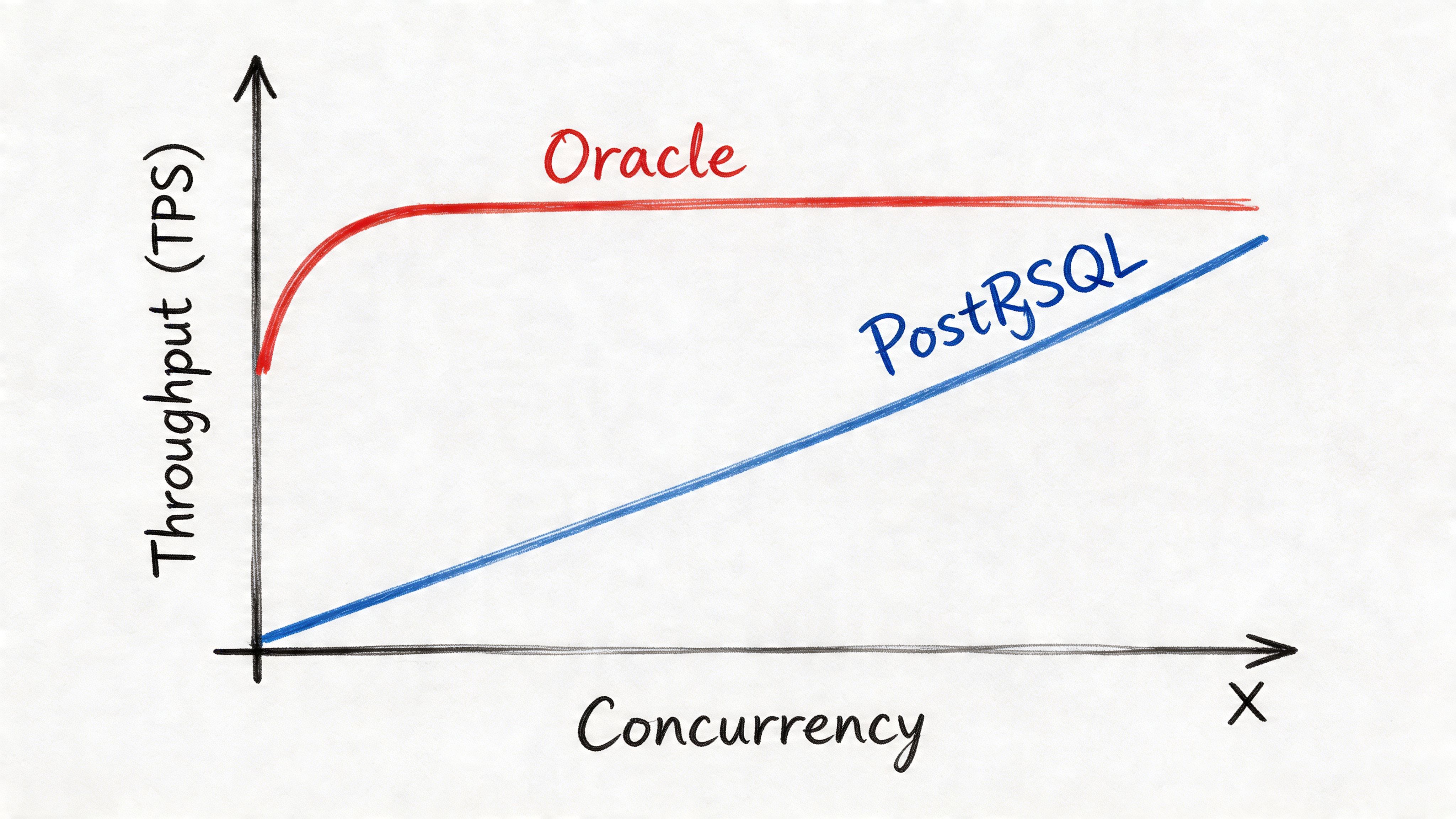
Where Oracle is clearly stronger
Oracle has a measurable edge in several benchmarked scenarios. In enterprise read benchmarks, Oracle reached 48,000 QPS on simple indexed SELECT queries versus 32,000 QPS for PostgreSQL, according to Fortified Data’s performance comparison. The same comparison reports that Oracle’s RAC can scale to up to 300K transactions per second at 25K concurrent users on enterprise hardware.
That matters if your AI/SaaS product has a true “every request is money” path. Think payment authorization, real-time policy enforcement, ad bidding, or a global order system where queueing and latency spikes create immediate business risk.
The same benchmark source also reports TPC-C OLTP response time of 5553ms for Oracle versus 10483ms for PostgreSQL on 100K records. That reinforces the same point. Oracle is engineered for low-latency, high-volume transaction handling.
Where PostgreSQL is often good enough, and sometimes the better operational choice
Most startups don’t need the database equivalent of a nuclear submarine. They need a system that performs well, scales reasonably, and doesn’t eat the budget or hiring plan.
PostgreSQL’s MVCC makes mixed read-write workloads easier to manage because readers don’t block writers in the same way teams often fear when traffic patterns get messy. That’s especially useful in AI pipelines where retraining jobs, feature refreshes, product analytics, and user traffic all hit the same platform over the course of a day.
A lot of AI products also aren’t bottlenecked by the database alone. They’re bottlenecked by orchestration, queues, embeddings, model latency, batch transforms, and infrastructure coordination. In those systems, PostgreSQL’s strong baseline and easier integration profile often matter more than squeezing out the last drop of benchmark throughput.
Operational advice: Don’t optimize for benchmark bragging rights if your actual bottleneck lives in the application tier, retrieval layer, or model serving path.
This is also why your container and orchestration model matters. Teams comparing self-managed PostgreSQL on containers to managed Oracle services, or the reverse, often mix database results with platform differences. If your stack is still maturing, this breakdown of Docker Compose vs Kubernetes helps frame the operational side of that choice.
Availability is where architecture meets process
Oracle’s availability story is strong because it combines mature clustering with enterprise recovery tooling. If your board, regulator, or customer contract treats downtime as a major business event, Oracle’s profile is hard to dismiss.
PostgreSQL can absolutely support highly available production systems. But in practice, you usually compose that outcome from replication, failover tooling, backups, and disciplined runbooks. It’s less “buy the platform” and more “build the operating model.”
A quick walkthrough helps:
What works in real AI/SaaS environments
For most product teams, the decision comes down to whether your growth path is predictable and extreme or messy and evolving.
| Situation | Better fit | Why |
|---|---|---|
| Core transaction system under sustained concurrency pressure | Oracle | RAC and stronger OLTP benchmark profile |
| AI product with mixed app, analytics, and pipeline traffic | PostgreSQL | MVCC, extensibility, lower friction in modern stacks |
| Enterprise environment with hard uptime expectations | Oracle | More mature integrated HA story |
| Fast-moving startup that changes architecture often | PostgreSQL | Lower lock-in, easier experimentation |
If you’re building a new AI/SaaS product, benchmark your own workload before committing. Public numbers are useful. Production fit is what pays the bills.
Understanding Costs, Licensing, and Managed Services
Often, many database decisions become clear. A team starts by debating architecture and ends by confronting the budget reality.
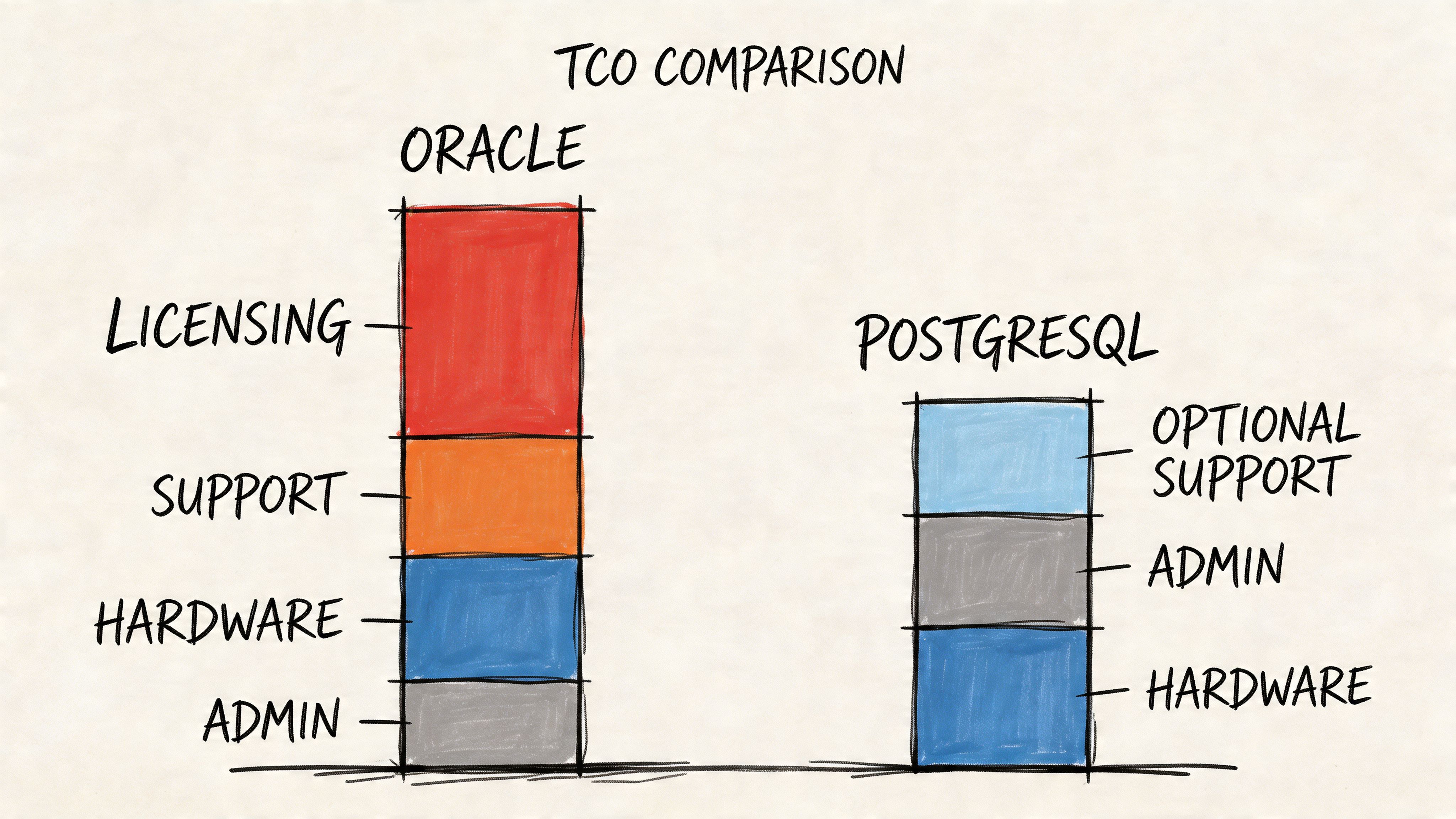
Oracle costs more than the license line suggests
Oracle Database remains the world’s most popular DBMS with a DB-Engines ranking score of 1244.08, and its reputation was built in part on enterprise features like RAC, according to Wonderment Apps’ Oracle vs PostgreSQL review. That position matters because it reflects deep enterprise adoption, not just nostalgia.
But Oracle’s commercial per-core licensing model changes the economics quickly. The visible cost is licensing. The hidden costs are usually bigger over time:
- Specialized staffing: You may need Oracle DBAs rather than generalist platform engineers.
- Support dependence: Enterprise support is part of the core operating model.
- Infrastructure assumptions: Oracle often shines most when the rest of the environment is designed around it.
- Migration drag: Once teams lean into proprietary features, leaving gets harder.
Those costs can be rational. In finance, insurance, and other high-stakes sectors, stability often matters more than software frugality.
PostgreSQL shifts spend from software to engineering choices
PostgreSQL removes license cost from the center of the discussion. That doesn’t mean it’s free in practice. It means you control where the spend goes.
Instead of paying for a premium database license, you’ll usually invest in some mix of:
- Managed service fees through a cloud provider
- Platform engineering time for replication, pooling, backup, and observability
- Third-party support if you want enterprise response guarantees
- Extensions and surrounding tools that make the platform easier to run at scale
That’s often a better trade for AI/SaaS companies because it preserves optionality. You can put more budget into engineers, data tooling, and product iteration rather than into a database contract.
The cheapest database isn’t always the lowest-TCO database. But the highest-priced database is often the one that forces the most second-order costs if your team and workload don’t truly need it.
Managed services change the conversation, but not the fundamentals
Cloud services soften some operational differences. Managed PostgreSQL can remove a lot of setup pain. Managed Oracle can reduce some of the heavy lifting that used to require a more hands-on DBA model.
Still, managed service convenience doesn’t erase the core trade-offs:
| Cost lens | Oracle | PostgreSQL |
|---|---|---|
| License exposure | High | None at the database license layer |
| Vendor lock-in | Higher | Lower |
| Specialist hiring pressure | Higher | Lower |
| Cloud portability | More constrained | Better |
| Best fit for most startups | Rare | Common |
If you’re a CTO at a growing SaaS company, this usually becomes a board-level resource allocation question. Do you want to fund premium database guarantees, or do you want to fund product and platform velocity? Most early and mid-stage teams should pick the second option unless the workload clearly forces the first.
Real-World Use Cases and Hiring The Right Talent
The easiest way to make this decision concrete is to look at how the choice changes with context.
Example one. Oracle for the system that can’t blink
A fintech company building a core ledger has a very different risk profile from a startup shipping an AI assistant. The ledger team cares about transactional correctness, formal recovery processes, auditability, and operational discipline under load. They don’t want to stitch together five tools and hope the on-call rotation keeps up.
In that environment, Oracle is often the cleaner answer. The company is buying maturity, vendor-backed operational patterns, and a database that was built with this class of problem in mind.
The hiring implication is immediate. You don’t just need backend engineers who can write SQL. You need people who understand Oracle internals, performance diagnostics, backup and recovery, and enterprise change control. That can be the right trade if the database is the heart of the business.
Interview questions for an Oracle-heavy role
- Concurrency diagnosis: “A write-heavy service shows latency spikes during peak settlement windows. How would you use Oracle performance views and execution analysis to isolate the bottleneck?”
- Recovery design: “How would you design a failover and recovery process for a transaction system where cutover risk matters more than hardware cost?”
- Operational governance: “Which Oracle features would you rely on first before introducing application-side workarounds?”
Example two. PostgreSQL for the team shipping AI features fast
Now take an AI startup building retrieval-augmented workflows, model metadata storage, usage analytics, and product APIs. The stack changes every quarter. New data flows show up unexpectedly. Product engineering and data engineering work closely, and the team values tools they can evolve without vendor friction.
That’s a classic PostgreSQL environment.
The database becomes part of a broader product system, not a crown-jewel platform that demands a separate priesthood. Engineers can use PostgreSQL for core application data, operational reporting, and adjacent AI workflow needs while keeping hiring simpler.
This is also where geography matters. If you want to build a strong remote database and platform team without forcing an Oracle-only talent search, broadening your recruiting pool helps. Teams looking to hire developers in Brazil often find strong backend, DevOps, and data engineering talent with PostgreSQL-heavy experience because the stack is common across startup and cloud-native environments.
Hire for the operating model you want, not the one your database forces on you by accident.
What the talent profile looks like
Here’s the practical difference in staffing.
| Role need | Oracle-leaning team | PostgreSQL-leaning team |
|---|---|---|
| Primary operator | Oracle DBA | Platform engineer, backend engineer, or PostgreSQL specialist |
| Daily focus | Tuning, governance, HA/DR, enterprise controls | Automation, scaling, schema design, pipeline reliability |
| Best org shape | Larger company with formal ops lanes | Product-led org with shared engineering ownership |
| Hiring risk | Smaller specialist pool | Broader market of capable operators |
Interview questions for a PostgreSQL-heavy role
- Connection management: “How would you prevent application-side connection spikes from destabilizing PostgreSQL?”
- Replication thinking: “When would you use streaming replication, logical replication, or a managed service abstraction?”
- AI workflow fit: “How would you structure PostgreSQL for application data plus pipeline metadata without turning it into an accidental data warehouse?”
The database choice and the hiring plan should be one conversation.
Your Oracle to PostgreSQL Migration Checklist
A migration from Oracle to PostgreSQL is rarely a pure lift-and-shift. It’s usually part schema conversion, part application refactor, part testing program, and part risk management exercise.
Teams that do this well treat migration as a product change, not a one-time infrastructure task. If you want a broader operating lens before kickoff, these data migration best practices are a useful companion.
Migration checklist
| Phase | Task | Key Consideration | Status |
|---|---|---|---|
| Assessment | Inventory schemas, data types, PL/SQL objects, jobs, and dependencies | Oracle-specific logic is often the main migration blocker | ☐ |
| Assessment | Identify performance-critical queries and batch jobs | Don’t assume semantic compatibility means equivalent runtime behavior | ☐ |
| Planning | Select conversion tooling such as Ora2Pg and define manual rewrite boundaries | Tooling helps, but stored procedures and edge-case SQL often need hand work | ☐ |
| Planning | Create a test strategy for correctness, latency, and cutover | Functional parity is not enough if your SLAs change | ☐ |
| Data migration | Choose initial load method and sync approach | Snapshot-only migrations are simpler. Ongoing sync reduces cutover risk but adds complexity | ☐ |
| Data migration | Rebuild indexes, constraints, and replication topology in PostgreSQL | Physical migration is only part of production readiness | ☐ |
| Validation | Run application regression, query benchmarks, and failover tests | Benchmark the real workload, not just synthetic SQL | ☐ |
| Validation | Plan cutover, rollback, and ownership after launch | Clear rollback criteria save projects | ☐ |
What teams usually underestimate
Three areas cause most of the pain.
First, stored logic. PL/SQL-heavy systems don’t migrate cleanly just because tables do. If business rules live deep in the database, you may need to redesign ownership between the application and PostgreSQL.
Second, performance assumptions. A query that is correct after conversion may still be wrong for production if execution plans behave differently. Benchmarking isn’t optional.
Third, operational equivalence. You are not done when data loads successfully. You’re done when monitoring, backup, recovery, connection management, and failover all work the way your team expects.
Migration rule: Treat cutover readiness as an operations milestone, not a database milestone.
A practical benchmark plan
Use a simple benchmark process before final approval:
- Choose the top workflows your business cares about. For example, user writes, dashboard reads, background jobs, and AI metadata lookups.
- Run the same application-level tests against Oracle and PostgreSQL.
- Compare latency consistency, not just peak speed.
- Test failure conditions, especially replica lag, reconnect behavior, and restore paths.
- Document tuning changes so your comparison is honest.
If your product relies on data movement and transformations, your migration test plan should also include pipeline validation. This guide to ETL with Python is useful if your team is rewriting extraction or transformation steps during the move.
Making Your Final Decision
Here’s the blunt answer.
For a new AI or SaaS product, PostgreSQL should usually be your default. It’s cost-effective, capable, extensible, and easier to align with modern engineering teams. Oracle is the better choice when your workload is enterprise-critical, your concurrency demands are severe, and your business can justify the extra cost and specialization.
Ask your team these questions before you commit:
- Is our hardest problem transaction throughput, or is it product velocity?
- Do we need vendor-backed enterprise features now, or are we paying early for a future we may never reach?
- Can our current team operate Oracle well, or would we be buying software and then scrambling to hire around it?
- Does lower lock-in matter to our roadmap?
- If we spent the difference on engineers instead, would the business move faster?
If the answers are mixed, run a benchmark with your own application traffic and choose based on operations, not brand recognition.
The best database decision is the one your team can run confidently while the company is still changing fast.
If you’re weighing oracle vs postgresql and need senior help to validate the architecture, benchmark the workload, or staff the team around it, ThirstySprout can help you Start a Pilot with vetted AI, data, and platform engineers. If you’re still comparing hiring options, See Sample Profiles and map the database choice to the talent you’ll need to operate it.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.