
TL;DR
- Go-to Stack: Use Pandas for data transformation, SQLAlchemy for database interaction, and an orchestrator like Prefect (for speed) or Apache Airflow (for enterprise scale).
- Architecture First: Choose ETL (Extract, Transform, Load) for compliance and control. Choose ELT (Extract, Load, Transform) for speed and analytical flexibility. This decision precedes all tooling choices.
- Production is Key: A pipeline isn't finished until it’s monitored, secure, and scalable. Use a secrets manager, track pipeline duration and data freshness, and plan for parallelization with tools like Dask.
- Hire for Production Experience: Prioritize engineers who have debugged and stabilized critical pipelines under pressure, not just those who can solve abstract coding problems.
Who this is for
- CTO / Head of Engineering: You need to decide on a data architecture, select a tech stack, and hire the right team to build and maintain data pipelines.
- Founder / Product Lead: You're scoping the budget and timeline for data-driven features and need to understand the trade-offs between different approaches.
- Data or MLOps Engineer: You are building and operating the pipelines and need a practical framework for making reliable, scalable choices.
Your 90-Second Python ETL Playbook
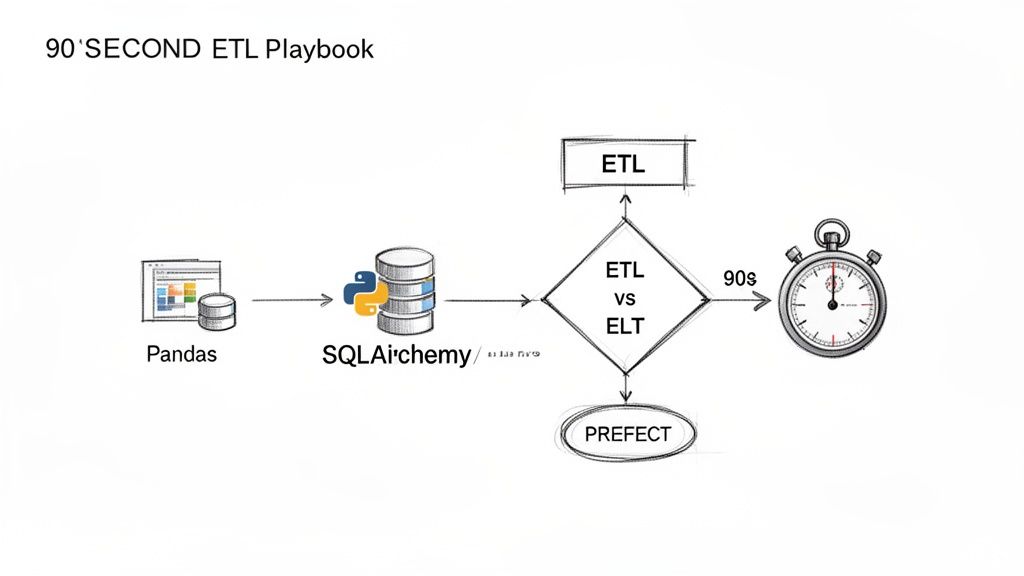
alt text: A flowchart titled "Your Python ETL Playbook in 90 Seconds" showing the steps: Extract (APIs, DBs), Transform (Pandas), Load (SQLAlchemy), and Orchestrate (Prefect), with a decision point for ETL vs. ELT.
Before you write a single line of code, your most critical decision is your architecture. This choice defines your costs, performance, and how quickly your team can move from raw data to insight. It all boils down to two patterns: ETL and ELT.
ETL (Extract, Transform, Load): The classic model. Data is pulled from a source, cleaned on a processing server using Python, and then loaded into your data warehouse. Use this for strict compliance needs (GDPR, HIPAA) or when you must enforce rigid data quality rules upfront. The business impact is lower risk but potentially slower time-to-insight.
ELT (Extract, Load, Transform): The modern, cloud-native approach. Raw data is loaded directly into a powerful cloud data warehouse. All transformation happens inside the warehouse using its compute power. This gives your team maximum flexibility to experiment with raw data. The business impact is faster time-to-value for analytics but requires strong governance to manage costs and quality.
Your choice should reflect your business reality. A fintech platform must validate transactions before they enter an analytical system, making ETL the right choice. An e-commerce company trying to spot new trends from raw clickstream data benefits more from ELT's flexibility.
Practical Examples & Architectures
Theory is cheap. Let's look at two common scenarios and how a Python ETL stack solves them.
Example 1: Customer 360 View for a SaaS Startup
A mid-stage SaaS company needs to combine user data from its production PostgreSQL database with subscription data from Stripe and support tickets from Zendesk to build a single customer view.
- Goal: Identify at-risk customers who have low product usage and recent support issues.
- Architecture: A scheduled ETL process is a perfect fit. The data is structured, and the business logic is well-defined.
- Extract: A Python script runs nightly. It uses
psycopg2to query the production database for usage metrics, the Stripe API for subscription status, and the Zendesk API for recent tickets. - Transform: Pandas is used to merge these three data sources on
customer_id. The script calculates an "at-risk" score based on business rules (e.g.,logins_last_30_days < 5andopen_tickets > 1). - Load: SQLAlchemy connects to a dedicated reporting database (e.g., another PostgreSQL instance or Amazon Redshift) and overwrites the
customer_health_scorestable with the fresh data. - Orchestration: The entire workflow is managed as a single task in Prefect Cloud, scheduled to run at 2 AM daily. It sends a Slack alert on failure.
- Goal: Create a reliable, point-in-time accurate database of market data for quantitative analysis.
- Architecture: ELT is a better fit here. The raw tick-level or daily-bar data is massive, and analysts need the flexibility to create different features (e.g., 7-day vs. 30-day moving averages).
- Implementation Snippet (Handling a Stock Split):
Business Impact: The customer success team gets a daily, actionable list of at-risk accounts, reducing churn by proactively engaging them. Time-to-value for this pipeline was under two weeks.
Example 2: Financial Data Ingestion for a Hedge Fund
A quantitative hedge fund needs to ingest and process historical and daily stock market data to backtest trading models. The data must be accurate and handle corporate actions like stock splits.
# A simplified example of a transformation function for a stock splitimport pandas as pddef adjust_for_split(historical_prices: pd.DataFrame, split_date: str, split_ratio: float):"""Adjusts historical prices for a stock split."""# Ensure date columns are in datetime formathistorical_prices['date'] = pd.to_datetime(historical_prices['date'])split_date = pd.to_datetime(split_date)# Select all prices before the split dateprices_to_adjust = historical_prices['date'] < split_date# Adjust OHLC (Open, High, Low, Close) and Volumeprice_columns = ['open', 'high', 'low', 'close']historical_prices.loc[prices_to_adjust, price_columns] /= split_ratiohistorical_prices.loc[prices_to_adjust, 'volume'] *= split_ratioprint(f"Adjusted {prices_to_adjust.sum()} rows for split on {split_date.date()}.")return historical_prices# This function would be part of a larger dbt model or Python script# running post-load in the data warehouse.Caption: A Python function using Pandas to retroactively adjust historical stock prices for a split, preventing incorrect analysis.
Business Impact: Forgetting this transformation could make a 2-for-1 split look like a 50% price crash, invalidating any backtest. A robust ELT pipeline, often using Python for extraction and a tool like dbt (Data Build Tool) for in-warehouse SQL transformations, ensures model accuracy and prevents costly trading errors. You can read a detailed breakdown of building a stock market ETL on AWS for more context.
Deep Dive: Trade-offs, Alternatives, and Pitfalls
Python's flexibility is its greatest strength, but it also means you have important decisions to make.
Why Python is the Go-To for Data Engineering
The core reason Python dominates is simple: its vast library ecosystem means a single versatile engineer can own the entire data lifecycle. This unifies your team, simplifies hiring, and accelerates development.
Instead of hiring separate specialists, you can build a team around a single skill set. A good Python engineer can pull data from an API, perform complex transformations with Pandas (used by 77% of data scientists), validate it with Great Expectations, and load it into Snowflake or BigQuery using SQLAlchemy. This dramatically reduces handoffs and operational complexity.
ETL vs. ELT: A Deeper Look
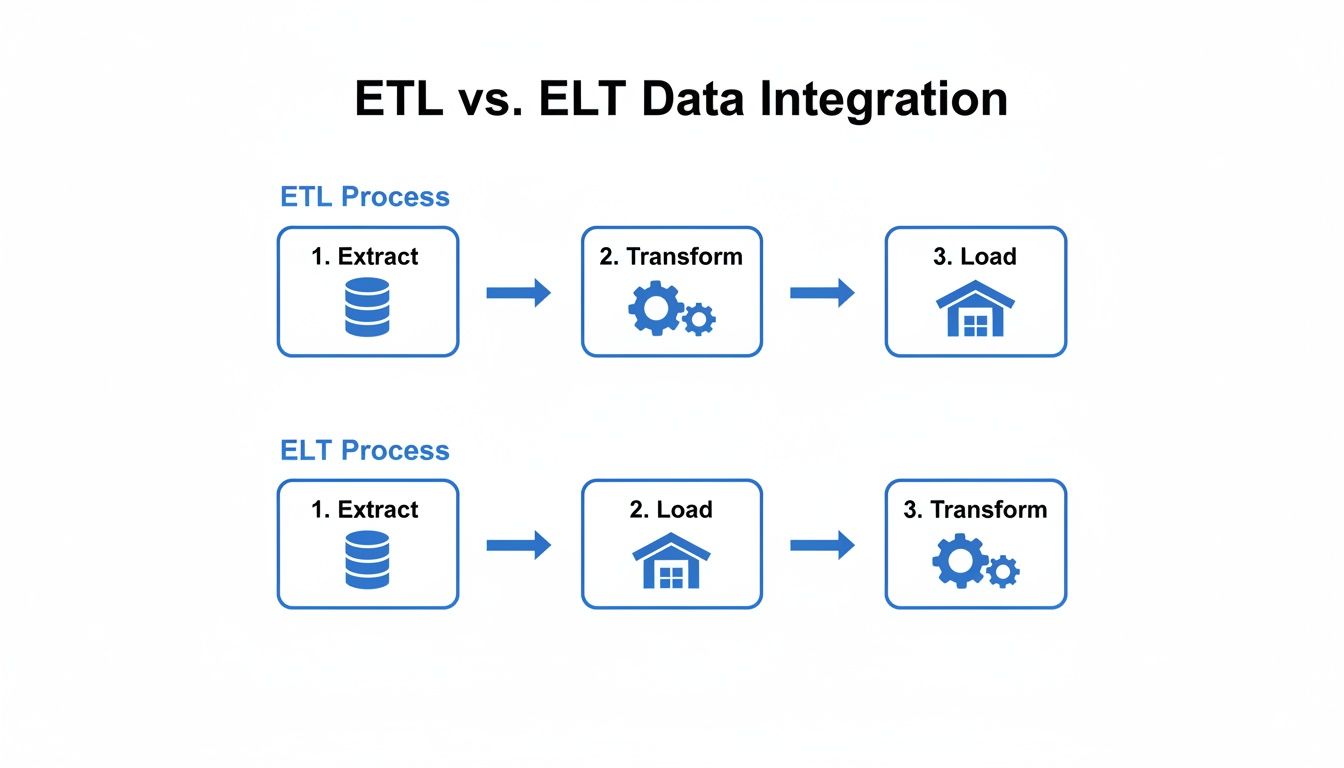
alt text: A diagram comparing ETL and ELT. The ETL side shows data moving from sources to a staging area for transformation before loading into a data warehouse. The ELT side shows data moving directly from sources into the warehouse, with transformation happening inside it.
Here’s a quick-reference table to help you weigh the trade-offs.
| Criterion | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
|---|---|---|
| Primary Goal | Data Integrity & Compliance | Speed & Analytical Flexibility |
| Best For | Regulated industries (finance, healthcare), structured reporting, complex pre-load business rules. | Exploratory analysis, data science, fast-moving business intelligence, large raw datasets. |
| Transformation Logic | Managed in Python code (e.g., Pandas) on separate compute resources. | Managed in SQL (often via dbt) directly within the data warehouse. |
| Flexibility | Lower. Analysts are limited to the pre-defined, transformed data models. | Higher. Analysts have access to raw data and can create their own views and models. |
| Risk | Slower time-to-insight; engineering bottleneck for new analytical requests. | "Data swamp" potential if not governed; higher warehouse compute costs. |
| Common Tooling | Python, Pandas, Airflow/Prefect, custom scripts. | Cloud warehouse (Snowflake/BigQuery), dbt, Fivetran/Stitch. |
Orchestration: Airflow vs. Prefect
As soon as your pipeline is more than one script, you need an orchestrator to schedule jobs, manage dependencies, and handle retries. The two main players in Python are Apache Airflow and Prefect.
- Airflow is the established veteran. It’s powerful and has a massive ecosystem, but its configuration-as-code approach can feel rigid.
- Prefect is built with a "Python-native" philosophy. You use decorators to turn any function into a managed workflow task, which feels more intuitive and flexible for dynamic pipelines.
Our Recommendation: For most new projects in 2026, start with Prefect. Its developer-friendly API and powerful UI will get you a robust, observable pipeline running much faster. Use Airflow if your organization already has a deep investment in it or you need an obscure integration only available in its vast operator library.
Production-Ready Python ETL Checklist
A pipeline that only "works on my machine" is a liability. Use this checklist to ensure your pipelines are reliable, secure, and scalable.
Monitoring & Alerting
- Track Pipeline Duration: Alert if a job takes >20% longer than its average.
- Track Data Freshness: Alert if a key table hasn't been updated in its expected interval (e.g., 24 hours).
- Track Failure Rate: Trigger an immediate PagerDuty/Slack alert on any job failure.
- Track Row Counts: Alert on significant deviations (e.g., +/- 30%) from expected record counts to catch upstream data issues early.
Security
- No Hardcoded Credentials: All API keys, DB passwords, and tokens are stored in a secrets manager like AWS Secrets Manager or HashiCorp Vault.
- Use Least-Privilege IAM Roles: The service account running the ETL job has only the permissions it needs (e.g.,
SELECTon source tables,INSERTon destination tables). - Rotate Credentials Regularly: Automate credential rotation every 90 days.
Scaling & Performance
- Parallelize Large Tasks: For datasets >1GB, use a library like Dask to parallelize Pandas operations across multiple CPU cores.
- Use Vectorized Operations: Avoid row-by-row loops in Pandas; use built-in vectorized functions for performance.
- Right-Size Infrastructure: Use cloud-native, memory-optimized instances for heavy transformation jobs and shut them down when finished to manage costs.
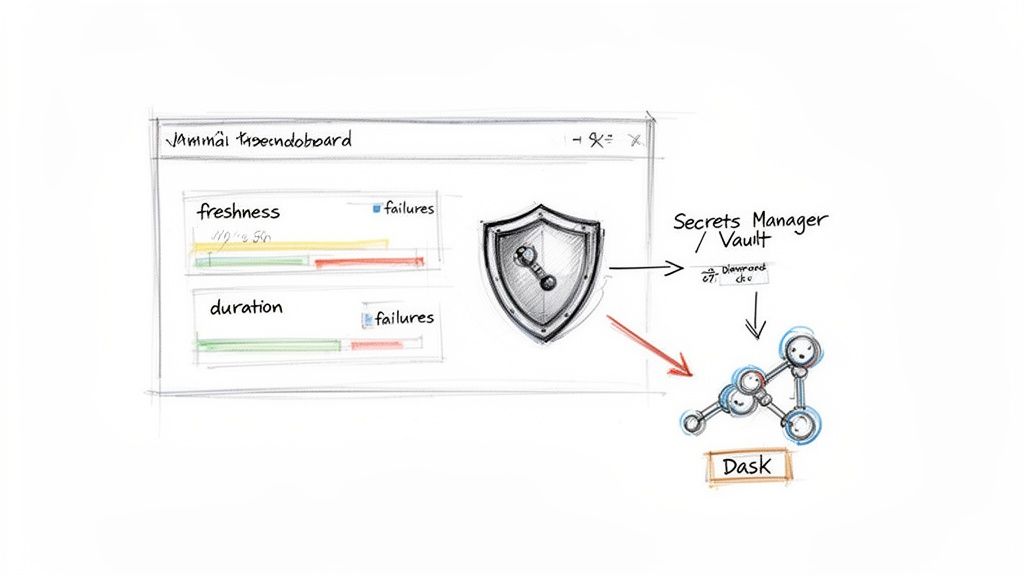
alt text: A diagram showing a scalable Python ETL architecture. It starts with a Dashboard, data flows through a Secrets Manager for security, and is processed by Dask for parallel computation before landing in a database.
What to Do Next
- Assess Your Architecture: Decide if ETL or ELT better fits your primary business need: control or speed?
- Pilot a Single Pipeline: Choose one high-impact business problem and build an end-to-end pipeline using the stack described (Pandas, SQLAlchemy, Prefect). Aim for a 2-week delivery.
- Book a Scoping Call: If you need to accelerate your data initiatives, ThirstySprout connects you with senior Python data engineers who have built and scaled production pipelines.
References and Further Reading
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.