
TL;DR: 3 Key Takeaways
- Python is the lowest-risk bet for AI in 2026. Its massive talent pool (22M+ developers) and unmatched library ecosystem (PyTorch, LangChain) deliver the fastest time-to-market for AI features.
- Modern Python architecture isn't about pure Python speed. It's about using Python to orchestrate high-performance libraries written in C++, CUDA, and Rust. The key is separating I/O-bound tasks (handled with
asyncio) from CPU-bound tasks (handled withmultiprocessingor Rust offloads). - Your action plan is simple: Identify a high-impact, low-friction project (like a RAG-based support bot), define the specific skills needed (e.g., LangChain orchestration, Polars for data processing), and launch a 2-week pilot to prove value and de-risk the investment.
Who This Guide is For
This guide is for technical leaders who need to make strategic decisions about their AI roadmap in the next 6–12 months.
- CTOs / Heads of Engineering: Deciding on architecture and hiring plans for AI initiatives.
- Founders / Product Leads: Scoping roles, timelines, and budgets for new AI-powered features.
- Talent Ops / Procurement: Understanding the skills needed to hire elite AI engineers and evaluate project risk.
If you need to move from planning to a pilot project within weeks, not months, this is for you.
Quick Framework: When to Use Python for AI
Use this decision framework to confirm if Python is the right strategic choice for your AI project. For 95% of business-facing AI applications, the answer will be yes.
Is your primary goal speed-to-market?
- Yes: Python's ecosystem and talent pool offer the fastest path from concept to production. Proceed.
- No (e.g., building a new physics engine from scratch): You may need a systems language like C++ or Rust as your primary tool.
Does your project rely on existing AI/ML libraries?
- Yes (e.g., using transformers, vector search, data pipelines): The best libraries (PyTorch, LangChain, TensorFlow) are Python-first. Proceed.
- No (you are building entirely new, low-level algorithms): This is rare. You may need another language, but will likely still use Python wrappers for usability.
Is your workload I/O-bound or CPU-bound?
- I/O-bound (waiting on APIs, databases): Python's
asynciois excellent for this. Proceed. - CPU-bound (heavy calculations): The Python ecosystem solves this by using high-performance backends (C++, Rust). You orchestrate with Python. Proceed.
- I/O-bound (waiting on APIs, databases): Python's
- API Layer: FastAPI is the ideal choice. Its
asyncsupport is perfect for I/O-bound tasks like calling an LLM API and waiting for a response. - Orchestration: LangChain acts as the central logic controller. It retrieves relevant document chunks, constructs the prompt for a model like GPT-4, and manages conversation history.
- Vector Search: For a knowledge base under 100k documents, an in-memory library like FAISS is fast and cost-effective. For larger scale, you would swap this for a managed service like Pinecone or Weaviate.
- Deployment: The application is packaged into a Docker container for portable deployment on Kubernetes or a serverless platform.
- Data Ingestion & Validation: An Apache Airflow Directed Acyclic Graph (DAG)—a scheduled Python script—pulls new transactions from a database.
- Data Transformation: The script uses a high-performance library like Polars (which is built in Rust for speed) to clean the data and engineer new features. Great Expectations runs data quality checks.
- Model Training & Tracking: A new model is trained using PyTorch. All parameters, metrics (accuracy, F1 score), and the model artifact are logged with MLflow for a complete audit trail.
- Deployment: If the new model outperforms the old one, a Python script triggers a CI/CD pipeline to deploy the new model container to production.
- I/O-Bound: The code spends most of its time waiting for a network or disk. This is common in web services and data ingestion pipelines.
- CPU-Bound: The code is actively performing computations, such as data manipulation or mathematical calculations.
- Real-World Example: An API gateway must fetch data from three separate internal services to build a user profile.
- Actionable Solution: Use
asyncio.gather()with a library likeaiohttp. This makes all three requests concurrently. The total wait time is reduced from the sum of all three requests to the duration of only the longest one, directly improving user-perceived latency. - Real-World Example: Preprocessing a dataset of 100,000 images by resizing and augmenting each one.
- Actionable Solution: Create a
multiprocessing.Pooland map your processing function across the list of images. The pool distributes the work across all available CPU cores, providing a near-linear speedup. This approach is fundamental to continuous performance testing. - Real-World Example: A core financial modeling function performing millions of calculations is slowing down an entire risk analysis pipeline.
- Actionable Solution: Isolate that single function and rewrite it in Rust, creating Python bindings with
PyO3. The Python application calls this compiled Rust function, getting the best of both worlds: Python's developer velocity and Rust's raw execution speed. - Identify a Business Problem: Find one process in your business bottlenecked by manual work that an AI-powered Python service could automate (e.g., document summarization, internal Q&A, data classification).
- Define the Skills Needed: Based on that problem, list the specific Python libraries and architectural skills required. Do you need someone with deep experience in LangChain for orchestration? MLflow and Kubernetes for MLOps? Or Polars for high-performance data work?
- Launch a Low-Risk Pilot: Scope a 2-week pilot with a vetted engineer to build a functional prototype. This proves the concept and provides clear data for a go/no-go decision on a larger investment.
- Languages & Libraries: Rust, Mojo, Airflow, MLflow.
- Python vs. Ruby for web and API development
- A guide to Python coding AI from basics to advanced apps
- Find remote Python jobs
If you answered "Yes" or the "Proceed" path to these questions, Python is your lowest-risk, highest-leverage choice.

Practical Examples: Two Production Python Architectures
Let's move from theory to practice. Here are two common, real-world architectures that show how to use Python to build and deploy production AI systems. These are battle-tested blueprints you can use to de-risk projects and estimate budgets.
The key business advantage is using a single language across the entire workflow. This reduces friction and handoff costs between data scientists, ML engineers, and MLOps, directly shortening time-to-value.
Example 1: RAG System for Customer Support
A common project is a Retrieval-Augmented Generation (RAG) system to answer questions using your company's private documents. This avoids the high cost of retraining a large language model (LLM).
Here’s a practical, Python-powered stack for a support bot handling <100k documents:
Business Impact: The goal is to reduce support ticket volume and improve customer satisfaction (CSAT) scores. Technically, you measure
precision@k(did we retrieve the right documents?) and end-to-end latency. This stack allows a small team to build a production-ready RAG system in 2–4 weeks. To go deeper, see our guide on software architecture best practices.
Example 2: MLOps Pipeline for a Forecasting Model
Consider a fintech company needing to update a fraud detection model daily. A robust MLOps pipeline is non-negotiable, and Python scripts are the engine.
A typical automated workflow:
This entire process, automated with Python, ensures the reliability and auditability required for mission-critical ML systems.
Deep Dive: Trade-offs and Pitfalls
Python isn't perfect. Its primary limitation, the Global Interpreter Lock (GIL), prevents multiple threads from executing Python code simultaneously. This can bottleneck CPU-bound tasks.
However, abandoning Python is the wrong move. The skill is in engineering around the bottleneck. Premature optimization is the most common and expensive mistake teams make.
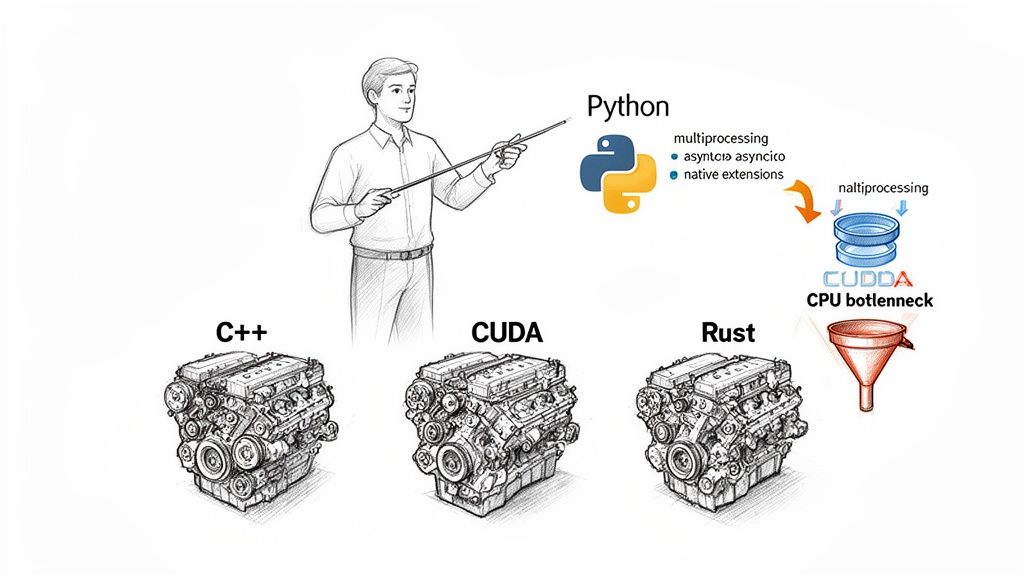
A Decision Framework For Performance
Your performance strategy must match the bottleneck. First, diagnose if your application is I/O-bound or CPU-bound.
Using a multiprocessing fix for an I/O-bound problem adds unnecessary complexity and won't solve the real issue.
Practical Strategies and Examples
1. For I/O-Bound Workloads, Use asyncio
When your application is waiting on many network calls (e.g., microservices, external APIs), asyncio lets a single thread handle thousands of concurrent operations efficiently.
2. For CPU-Bound Workloads, Use multiprocessing
When a large computational job can be divided into independent chunks, the multiprocessing module bypasses the GIL by launching separate processes.
3. For Extreme CPU Bottlenecks, Offload to Rust
For the 1% of functions where performance is absolutely critical, rewrite that specific hot spot in a systems language like Rust. The speed of data libraries like Polars demonstrates this approach.
Checklist: Scoping Your Next Python AI Project
Use this checklist to move from idea to a scoped pilot project.
What to do next: Your 3-Step Action Plan
Thinking about Python's future is useful, but acting on it creates value. Here are three steps you can take this week.
References & Further Reading
Ready to build your team with the right Python expertise? ThirstySprout helps you hire vetted, senior AI and MLOps engineers who can build and scale production systems. Start a Pilot.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.