
TL;DR
- Modular Architecture: Break down large applications into independent microservices to speed up development and isolate failures. Hire Platform or MLOps engineers to manage the infrastructure.
- Event-Driven Architecture (EDA): Use asynchronous events for real-time data processing, crucial for fraud detection or live recommendations. Requires Data Engineers skilled in Kafka or AWS EventBridge.
- Feature Stores: Centralize ML features to eliminate training-serving skew and accelerate model development. Hire Data and ML Engineers with experience in data pipelines and governance.
- CI/CD for ML (MLOps): Automate model validation and deployment using GitOps principles to ensure reliable, auditable, and rapid updates. This is the core responsibility of an MLOps Engineer.
- Action: Audit your current architecture against the checklist below to identify the top 2-3 practices that will solve your most urgent scaling or hiring challenges.
Who this is for:
- CTOs & Heads of Engineering: Making architectural decisions that directly impact your ability to hire specialized AI/ML talent and scale operations.
- Founders & Product Leads: Scoping AI features and understanding the team composition required to build and maintain them.
- Staff Engineers & Architects: Designing resilient, scalable systems and need a practical framework for evaluating trade-offs.
The Framework: From Architecture to Action Plan
Choosing the right architecture is a hiring decision. A well-defined system lets you hire specialized, high-impact engineers for specific roles like MLOps or Data Engineering. A poorly defined one forces you to hunt for expensive, hard-to-find generalists who are expected to do everything.
Follow this simple, 3-step process:
- Assess Your Core Bottleneck: Is your biggest problem slow deployment cycles, inconsistent data, or real-time processing limitations? Match the problem to an architectural pattern in the list below.
- Define the Required Role: The chosen pattern dictates the skills you need. An event-driven system requires a Data Engineer with Kafka skills; a microservices-heavy environment needs a Platform Engineer who knows Kubernetes.
- Create a Pilot Project: De-risk the change by applying the new pattern to a single, high-value business problem. This builds team skills and proves business value before a full-scale migration.
This guide provides a practical, no-fluff roundup of 10 software architecture best practices that matter for AI, fintech, and SaaS companies. We cut through abstract theory to give you actionable implementation steps and the direct impact each practice has on your team structure.
1. Modular Architecture & Microservices
Modular architecture breaks a monolithic application into smaller, independent services. Each "microservice" handles a single business capability and can be developed, deployed, and scaled autonomously by a dedicated team. For AI platforms, this means separating components like feature engineering, model serving, and payment processing into distinct services.
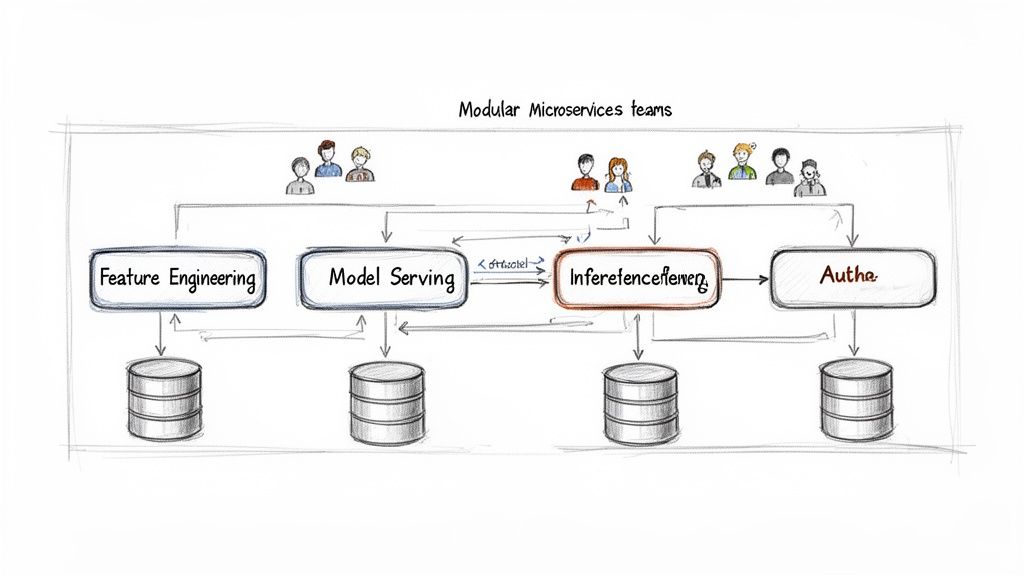
Alt text: Diagram illustrating modular microservices teams managing an AI/ML pipeline with feature engineering, model serving, inference, and authentication.
Why It Matters
This approach allows teams to work in parallel, accelerating development. For example, Netflix’s personalization algorithms and Stripe’s ML-powered fraud detection both use microservices to update critical business logic independently. This prevents a failure in one area, like a data ingestion pipeline, from bringing down the entire user-facing application.
Implementation Guidance
- Start Small: Avoid premature fragmentation. Begin by identifying 2–3 core business domains and building them as separate services.
- Define Clear Contracts: Use OpenAPI (for REST) or gRPC to establish strict, versioned API contracts between services.
- Containerize Everything: Package each service in a container (e.g., Docker) and manage it with an orchestrator like Kubernetes for consistency.
- Monitor Inter-Service Communication: Use observability tools to track latency, error rates, and dependencies. The move to distributed systems has major implications for developing in the cloud.
Hiring & Team Implications
To succeed, you need engineers skilled in distributed systems and containerization. Key roles include Platform Engineers or MLOps Engineers who build and maintain the infrastructure (service discovery, CI/CD pipelines).
2. Domain-Driven Design (DDD)
Domain-Driven Design (DDD) centers development around the core business domain. Instead of organizing code by technical layers like "database" or "UI," DDD structures the system into models that reflect deep business realities. This approach emphasizes creating a shared vocabulary, or "Ubiquitous Language," between technical teams and domain experts.
Why It Matters
DDD ensures the software accurately solves real-world business problems. For instance, Shopify's architecture is organized into distinct "bounded contexts" like inventory, fulfillment, and payments. This allows their teams to develop and scale each business capability independently, reducing complexity.
Implementation Guidance
- Conduct Domain Discovery: Run "event storming" workshops with product managers and engineers to map out business processes.
- Define Bounded Contexts: Identify the boundaries of different subdomains. A recommendation engine and a user authentication service are separate bounded contexts.
- Establish a Ubiquitous Language: Create a shared glossary of terms used consistently in conversations, documents, and the codebase.
- Model the Core Domain: Focus modeling efforts on the parts of the business that provide a competitive advantage.
Hiring & Team Implications
Implementing DDD requires engineers who are skilled communicators. Look for a Principal Engineer or Software Architect with experience facilitating domain modeling sessions. Align your team structure with your bounded contexts (Conway's Law) to create autonomous teams.
3. Event-Driven Architecture
Event-driven architecture (EDA) is a paradigm where system components communicate asynchronously by producing and consuming events. An event is a record of a state change, like a user completing a purchase. In this model, services emit events to a central broker without knowing which services will consume them, promoting decoupling and scalability.
Why It Matters
EDA is essential for AI/ML workflows that react to real-time data. For example, Instacart's real-time model serving is triggered by user events. This asynchronous pattern prevents bottlenecks, allowing ML training pipelines or feature computation jobs to be triggered efficiently as new data arrives.
Implementation Guidance
- Choose the Right Broker: Use Apache Kafka for high-throughput, persistent log streaming or AWS EventBridge for a managed, serverless bus.
- Establish Event Contracts: Document event structures using a schema registry with formats like Avro or Protobuf to enforce data consistency.
- Handle Failures Gracefully: Implement dead-letter queues (DLQs) to capture events that consumers fail to process.
- Monitor for Lag: Track the delay between when an event is produced and processed. High lag indicates a downstream service needs scaling.
Hiring & Team Implications
Success with EDA requires engineers who understand asynchronous systems. Look for Data Engineers and Backend Engineers with hands-on experience using Kafka, RabbitMQ, or cloud-native equivalents like SQS.
4. API-First Architecture
API-first architecture treats an application’s Application Programming Interfaces (APIs) as first-class citizens. The API is designed, documented, and reviewed before any backend code is written. This establishes a clear "contract" that frontend, mobile, and other backend teams can rely on, enabling parallel development.
Why It Matters
This practice decouples client-facing applications from backend services. Stripe’s success is built on a well-documented, developer-friendly API that became its core product. Similarly, OpenAI's API-first model for GPT-4 allows thousands of developers to build applications on their platform without needing to understand the complex backend.
Implementation Guidance
- Design Collaboratively: Involve frontend, backend, and data science teams in the API design process from the start.
- Use a Specification Language: Standardize API design with the OpenAPI Specification (OAS) to auto-generate documentation, client SDKs, and server stubs.
- Version Your APIs: Implement API versioning in the URL (e.g.,
/api/v2/predict) from day one to prevent breaking changes. - Implement an API Gateway: Use a tool like AWS API Gateway or Kong to manage authentication, rate limiting, and logging centrally.
Hiring & Team Implications
You need engineers who are skilled designers who think about the developer experience. Look for Backend Engineers and Solutions Architects with proven experience in RESTful API design and OpenAPI/Swagger.
5. Layered Architecture with Separation of Concerns
Layered architecture organizes code into distinct horizontal tiers, where each layer has a specific responsibility. This separation of concerns promotes maintainability by ensuring a change in one area, like the database, doesn't ripple through the entire application. For AI systems, this pattern extends to dedicated layers for feature engineering, model training, and model serving.
Alt text: Layered software architecture diagram showing Presentation, Business Logic, Data Access, ML stages, and Infrastructure.
Why It Matters
This structure enforces a clean, one-way dependency flow. In a fintech application, the business logic for calculating loan eligibility should be independent of the user interface and the database. This allows the UI to be replaced or the database migrated without rewriting core business rules.
Implementation Guidance
- Enforce One-Way Dependencies: A higher layer can call a lower layer, but never the other way around.
- Use Interfaces and Dependency Injection: Define clear contracts (interfaces) between layers to decouple them and simplify unit testing.
- Keep Business Logic Pure: Your core business rules should contain no framework-specific code, ensuring it's portable.
- Document Layer Responsibilities: Clearly define what each layer is responsible for to prevent "leaky abstractions."
Hiring & Team Implications
You need engineers who value discipline and clean code. Look for Backend Engineers and Software Architects with experience in Domain-Driven Design (DDD). On the ML side, ML Engineers should know how to separate data preparation, model training, and serving into distinct layers.
6. CQRS (Command Query Responsibility Segregation)
CQRS (Command Query Responsibility Segregation) separates the models used for updating data (commands) from those used for reading data (queries). Instead of a single model handling both, CQRS establishes two distinct paths. This is crucial for complex systems where read and write workloads have different performance needs.
Why It Matters
This segregation allows you to optimize each path independently. The write side can be designed for consistency, while the read side can be highly denormalized for fast access. LinkedIn's recommendation engine uses a command path to process user interactions and a separate query path to serve recommendations to millions of users, preventing slow writes from blocking fast reads.
Implementation Guidance
- Apply Strategically: Use CQRS only where read and write patterns diverge significantly, like a high-traffic analytics dashboard.
- Use Event Sourcing: CQRS is often paired with Event Sourcing. Commands generate events stored in an append-only log, which then asynchronously update read models.
- Separate Databases: Use a transactional database like PostgreSQL for the write model and a read-optimized store like Elasticsearch or Redis for query models.
- Monitor Synchronization Lag: Implement monitoring to track the delay between the write and read models to ensure it stays within acceptable limits.
Hiring & Team Implications
Implementing CQRS requires Senior Backend Engineers or Data Engineers who understand distributed systems, asynchronous processing, and eventual consistency. They must be comfortable working with message queues and designing different data models for distinct use cases.
7. CI/CD & GitOps for ML/AI Systems
Continuous Integration/Continuous Deployment (CI/CD) automates the testing and deployment of code changes. GitOps extends this by using a Git repository as the single source of truth for application and infrastructure state. For AI systems, this means automating the entire lifecycle, from data validation and model training to production deployment.
Why It Matters
In AI products, the model is as critical as the code. A manual deployment process is risky and slow. GitOps and CI/CD for ML (MLOps) allow teams to version-control code, data, configurations, and models. This provides an auditable, reproducible, and automated path to production, enabling rapid and reliable updates.
Implementation Guidance
- Treat Everything as Code: Version control your training scripts, model configurations, feature definitions, and infrastructure manifests in Git.
- Automate Model Validation: Your CI pipeline must test model performance (accuracy, precision), bias, and latency before any deployment.
- Use Feature Flags for Models: Decouple deployment from release. Deploy new models behind feature flags to allow for A/B testing or a gradual rollout.
- Leverage GitOps Tools: Use tools like Argo CD or Flux to automatically synchronize your production environment with the state defined in Git. For a deeper dive, explore these MLOps best practices.
Hiring & Team Implications
Success requires MLOps Engineers or Platform Engineers with experience in CI/CD tools (GitHub Actions, GitLab CI), infrastructure-as-code (Terraform), and container orchestration (Kubernetes). Data scientists and ML engineers must take ownership of the entire model lifecycle.
8. Data-Driven Architecture with Feature Stores
A feature store is a central repository that manages the entire lifecycle of Machine Learning (ML) features. It decouples the feature engineering pipeline from the model development pipeline, ensuring consistency between features used for training (offline) and serving predictions (online). This prevents the notorious training-serving skew that plagues many AI systems.
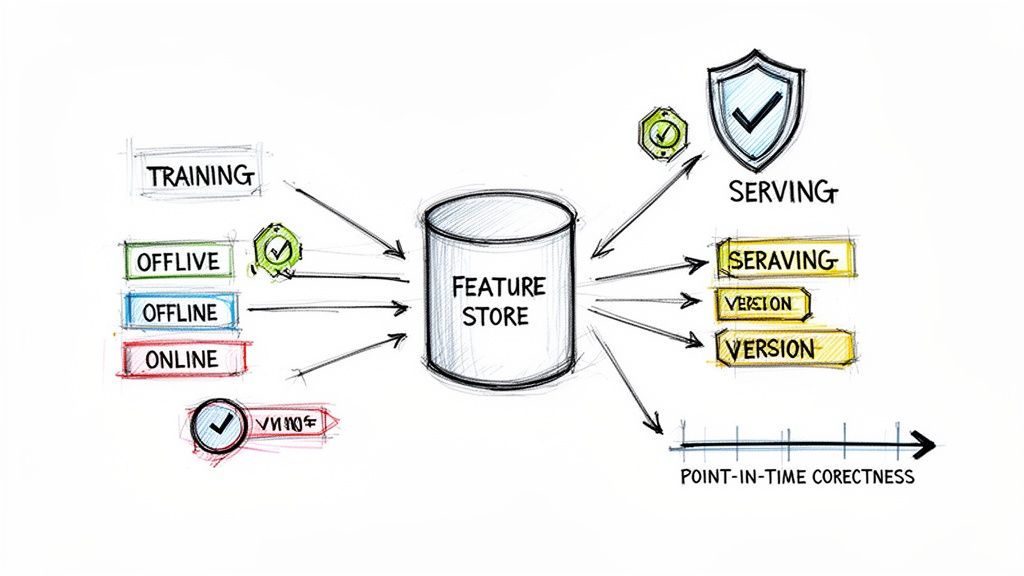
Alt text: Architectural diagram showing a feature store centralizing data for training, offline, online, and serving applications.
Why It Matters
This practice accelerates model development by allowing data scientists to discover and reuse features. For example, a fraud detection team can reuse customer transaction frequency features built by a marketing analytics team. This is a crucial component for effective AI solutions, as described in What Is a Feature Store and How Does It Power AI in Banking?
Implementation Guidance
- Start with an Offline Store: Begin by building a batch-based offline store for training data. Add a low-latency online store for real-time inference later.
- Define Feature Ownership: Assign clear ownership for each feature set and establish Service Level Agreements (SLAs) for freshness and availability.
- Version and Document Everything: Implement strict versioning for feature definitions to allow for rollbacks and maintain a feature catalog.
- Monitor Data Quality: Implement automated checks to monitor feature data for drift, freshness, and statistical anomalies.
Hiring & Team Implications
This requires specialized talent. Look for Data Engineers and ML Engineers with experience building large-scale data pipelines. A Platform Engineering team often owns the core feature store infrastructure (using tools like Feast or Tecton), while domain-specific teams contribute and consume features.
9. Observability & Monitoring for AI Systems
Observability goes beyond traditional monitoring of CPU and memory, extending to model-specific metrics like accuracy, fairness, and data drift. For AI systems, true observability means being able to answer complex questions about system behavior by instrumenting logs, metrics, and traces across the entire application and model lifecycle.
Why It Matters
In AI, "silent failures" are common. A model can serve predictions with perfect uptime but produce inaccurate results due to shifts in input data (data drift). Without dedicated AI observability, a fintech's fraud model could start incorrectly flagging legitimate transactions. Robust monitoring allows teams to detect performance degradation and debug errors.
Implementation Guidance
- Log Everything That Matters: Archive model inputs, predictions, and ground truth labels for debugging, retraining, and regulatory audits.
- Monitor Model and Data Health: Use tools like Evidently AI or WhyLabs to set up automated checks for data drift, concept drift, and model performance degradation.
- Establish Model SLOs: Define Service Level Objectives (SLOs) for your models, not just infrastructure. This includes targets for inference latency or accuracy.
- Implement Explainability: Integrate tools like SHAP to understand why a model made a specific prediction, which is critical for building trust.
Hiring & Team Implications
This requires a blend of MLOps and Data Science skills. Look for MLOps Engineers who can build monitoring pipelines using tools like Prometheus and the ELK Stack. You also need Data Scientists or ML Engineers who can interpret model performance metrics and diagnose drift.
10. Scalable Data Architecture & Data Pipelines
A scalable data architecture focuses on the robust ingestion, storage, processing, and serving of data. For AI companies, this includes everything from real-time data streaming and ETL/ELT pipelines to data warehousing. It is the foundation that ensures AI models receive high-quality, timely data for both training and inference.
Why It Matters
Without a scalable data architecture, data quality degrades and model performance suffers. Lyft's dynamic pricing and ETA models depend on a massive data platform that processes billions of events daily. A bottleneck could lead to stale, inaccurate predictions. A well-designed data infrastructure enables reliable feature computation and reproducible model training.
Implementation Guidance
- Start with Managed Services: Leverage platforms like Snowflake, Google BigQuery, or Databricks to handle infrastructure complexity initially.
- Orchestrate and Transform Reliably: Use tools like Airflow for pipeline orchestration and dbt for SQL-based transformations.
- Implement Data Quality Gates: Integrate data quality checks (e.g., using Great Expectations) at key pipeline stages to prevent bad data from corrupting downstream models.
- Optimize for Performance: Use partitioning and clustering in your data warehouse to speed up query performance. The complexity of these systems also has implications for how you secure big data.
Hiring & Team Implications
Building this infrastructure requires specialized talent. Key roles include Data Engineers, who are experts in building data pipelines using tools like Spark, Kafka, and Airflow. You'll also need Analytics Engineers who specialize in transforming and modeling data with dbt.
Practical Examples: Architecture in Action
Example 1: Real-Time Fraud Detection System (Event-Driven + Feature Store)
A fintech startup needs to build a system that detects fraudulent credit card transactions in under 100ms.
- Architecture: They choose an Event-Driven Architecture. Kafka ingests a stream of transaction events. A Flink job consumes these events in real time to compute features (e.g., transaction frequency in the last minute). These features are written to an online Feature Store (Redis). A separate model serving microservice reads features from the store and scores the transaction.
- Business Impact: The decoupled, real-time architecture allows the fraud model to be updated and deployed independently of the transaction processing system. It meets the strict latency SLA, reducing fraud losses without impacting user experience.
- Hiring Implication: This architecture requires a Senior Data Engineer with deep Kafka and Flink expertise and an ML Engineer skilled in low-latency model serving and feature stores.
Example 2: Architecture Scorecard for a New AI Project
A product team is scoping a new personalized recommendation feature. The engineering lead uses a simple scorecard to evaluate architectural trade-offs before committing to a design.
Deep Dive: Architecture Selection Checklist
Use this checklist to pressure-test your architectural decisions. A "no" to any of these questions is a red flag that requires further discussion with your team.
- Business Alignment: Does this architecture directly support a key business objective (e.g., reduce latency, increase developer velocity, lower operational risk)?
- Scalability Path: Does the design have a clear path to scale 10x from its initial load? Have you identified the primary scaling bottleneck?
- Hiring Feasibility: Can you realistically hire the talent required to build and maintain this architecture in your market and budget?
- Operational Cost: Have you estimated the 12-month total cost of ownership (TCO), including infrastructure, tooling, and engineering time?
- Developer Experience: Does this architecture make it easier for developers to test, deploy, and debug their code?
- Failure Modes: Have you identified the top three ways this system could fail and designed for resilience (e.g., retries, dead-letter queues, fallbacks)?
- Observability: Is there a clear plan for monitoring system health, model performance, and data quality?
- Data Governance: For data-heavy systems, is there a clear owner for data quality, lineage, and security?
What to Do Next
- Conduct an Architecture Audit: Use the checklist above to review your current system. Identify the top 1-2 practices that would solve your most pressing scalability, maintenance, or data-handling challenges.
- Define a Target-State Role: Based on your audit, create a precise job description for the one role that can close the biggest gap. For example, adopting a Feature Store creates a clear need for a "Senior Data Engineer (Real-time Pipelines)."
- Start a Pilot: Book a 20-minute call with us to scope a pilot project. We can connect you with a pre-vetted MLOps or Data Engineer from our network to de-risk the change and deliver measurable results in 2–4 weeks.
A well-defined architecture serves as a common language, aligning product, engineering, and data science teams on a shared vision. By investing in your architecture, you are investing in the caliber of team you can build.
Start a Pilot with a Vetted AI Engineer
See Sample Engineer Profiles
References
- To connect hiring principles to architectural decisions, explore this playbook for hiring software engineers.
- For a deeper dive into MLOps tooling, see our guide on MLOps best practices.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.