
You’re probably in one of two situations right now.
Either your team already runs core product data on Oracle and wants to add an AI feature without breaking the system that pays the bills. Or you’re choosing a database for a new product and trying to decide whether Oracle’s durability is worth the cost, operational load, and hiring implications compared with PostgreSQL or a cloud warehouse.
That’s where most database debates go wrong. People compare feature lists. CTOs need a decision rule. For AI products, the key question isn’t whether Oracle is powerful. It is. The question is whether rdbms in oracle is the right transactional foundation for the specific AI capability you’re building, and whether your team can operate it well.
TLDR What You Need to Know About RDBMS in Oracle
A CTO usually asks this question when an AI feature stops being a prototype and starts touching money, permissions, claims, or customer commitments. That is the point where Oracle becomes a serious option.
Oracle RDBMS is a strong fit for systems that cannot afford transactional mistakes. It has decades of maturity in high-concurrency OLTP environments, and that still matters when AI outputs need to write back into production workflows without corrupting state.
Oracle earns the overhead only in specific cases. Choose it when your AI feature depends on accurate account balances, policy decisions, entitlements, order state, or other records where rollback, auditability, and write consistency are part of the product requirement.
For many new AI products, Oracle is more database than the team needs. PostgreSQL is often easier to staff, cheaper to run, and faster to adapt during early experimentation. Snowflake often fits better for analytical pipelines, feature engineering, and model-adjacent workloads that do not sit on the transactional path.
Oracle is rarely the whole AI stack. In practice, teams use it as the system of record, then pair it with streaming, object storage, vector infrastructure, orchestration, and analytical platforms. Oracle can anchor the core transaction. It usually should not carry every AI workload by itself.
The real decision is economic and operational. Licensing, support posture, vendor dependence, specialist hiring, and operational discipline all affect the outcome as much as query performance. Oracle customers evaluating cost and support alternatives is a real pattern, as noted in this Rimini Street survey summary.
Practical default advice: use Oracle when the database sits inside the product’s risk-control layer. For greenfield AI builds where speed of iteration matters more than transactional rigor, start with a simpler cloud-native option unless the requirements clearly justify Oracle’s complexity.
Who This Guide Is For
This guide is for the CTO, head of engineering, platform lead, or founder who needs to make a database decision in the next few weeks, not after a quarter of architecture workshops.
You may be building a fintech workflow, a B2B SaaS control plane, a healthcare application, or an internal AI system that reads from operational data and writes outcomes back into a production workflow. The friction is familiar. Your product needs strong transactional guarantees, but your AI roadmap needs flexibility, fast experimentation, Python-heavy tooling, and room for event streams, embeddings, and non-tabular payloads.
Here’s the common tension:
- Your product team wants speed. PostgreSQL often feels simpler to adopt and easier to hire for.
- Your data team wants clean contracts. They don’t want model pipelines coupled directly to brittle app tables.
- Your operations team wants safety. They care more about rollback, recovery, locking behavior, and auditability than database fashion.
Oracle is usually a good answer for “how do we protect the core transaction?” It is often a poor answer for “how do we make AI experimentation easy?”
This guide is useful if you need to answer questions like these:
- Should Oracle be our system of record?
- Should AI features read directly from Oracle, or from replicated data products?
- Can we justify Oracle over PostgreSQL for a new build?
- What team skills do we need before we commit?
- Where does Snowflake or another analytical layer fit?
If you want a neutral feature checklist, this isn’t that. If you need a practical recommendation that balances reliability, cost, architecture, and team readiness, this is the right discussion.
A Quick Framework for Choosing Your Database
Don’t start with brand preference. Start with workload shape.
If the AI feature has to make or influence a live business decision using transactional data, the database choice should optimize for correctness first, then operating model, then developer convenience. If the feature is mostly analytical, retrieval-heavy, or experimentation-heavy, the answer usually shifts.
Database decision matrix for AI projects
| Criterion | Oracle RDBMS | PostgreSQL | Snowflake |
|---|---|---|---|
| Transactional system of record | Strong fit for mission-critical OLTP and strict consistency | Strong fit for many product workloads with simpler adoption | Not the primary choice for OLTP application state |
| Data consistency model | Strong, mature transactional model with statement-level read consistency | Strong relational consistency, common startup default | Best used for analytics and batch-oriented data work |
| Cost model | Licensing and support can be a major decision factor | Open-source model is usually easier to start with | Consumption and platform model fits analytics better than app transactions |
| Operational complexity | Highest of the three. Best with experienced DBAs and disciplined change control | Moderate. Broad operator familiarity | Lower for warehouse operations, but not a replacement for core app RDBMS duties |
| AI and Python ecosystem fit | Works, but often through surrounding integration layers | Usually easier for app engineers and ML engineers to work with directly | Strong in analytics workflows, feature preparation, and downstream reporting |
| Unstructured and hybrid AI data patterns | Possible, but architectural guidance is limited for modern AI/ML patterns | Often easier to pair with adjacent tools | Better for transformed, analytical, and collaborative data consumption |
| Hiring market and team familiarity | More specialized talent needs | Broadest generalist familiarity | Strong data platform familiarity, less suited to OLTP ownership |
| Best role in modern stack | Core transactional backbone | Default app database for many startups | Analytical and model-development data layer |
When Oracle is the right answer
Choose Oracle when all three are true:
- A wrong answer is worse than a slow answer. Think fraud controls, billing state, financial posting, entitlement checks, or regulated records.
- The AI feature depends on current transactional truth. Not just historical aggregates.
- You can support the operating model. Oracle isn’t a “set and forget” decision.
A practical pattern is to keep Oracle as the authoritative write system, then publish curated data to pipelines, model services, or analytical stores.
When Oracle is the wrong answer
Don’t lead with Oracle if you’re mostly building:
- A greenfield SaaS app where PostgreSQL is enough
- A reporting or experimentation layer better served by a warehouse
- An AI feature fed mostly by documents, event streams, or object storage
- A startup product with no Oracle skills in-house and no appetite for specialist hiring
Decision rule: If your main concern is model iteration speed, Oracle usually sits adjacent to the AI stack, not at the center of it.
For a more focused side-by-side on relational trade-offs, this comparison of Oracle vs PostgreSQL for engineering teams is worth reviewing before you lock in a roadmap.
Practical Examples An Oracle RDBMS in a Modern AI Stack
The most useful way to think about Oracle is not “database for AI.” It’s “trusted operational core that AI reads from and writes decisions around.”
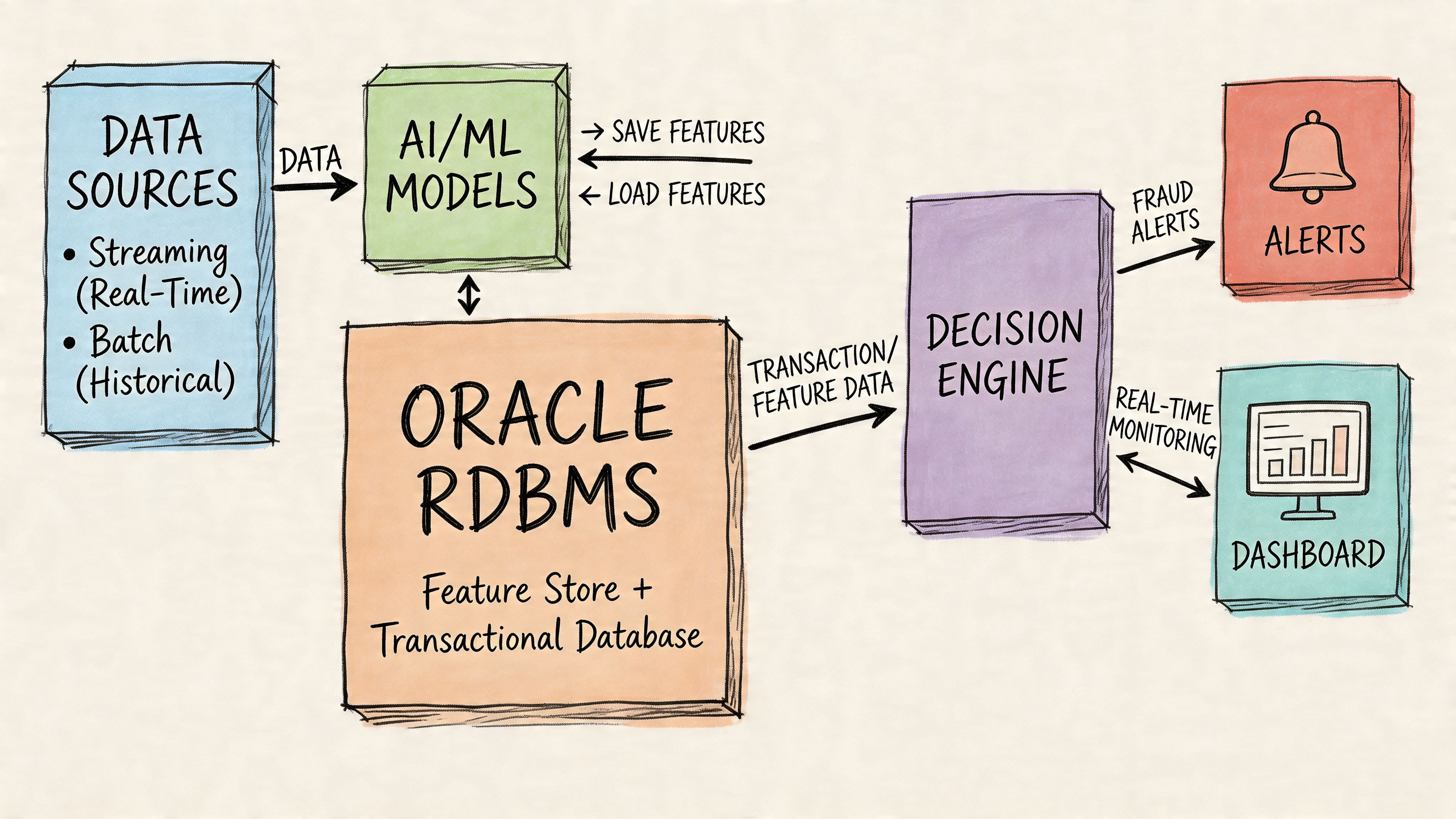
Example one real-time fraud scoring with Oracle as system of record
A payment platform stores customer accounts, transaction ledgers, merchant metadata, and risk flags in Oracle. That’s the right place for transaction truth because records must stay consistent while many users and services write concurrently.
A practical flow looks like this:
- Core write path: application writes transaction and account changes into Oracle
- Feature extraction path: a pipeline derives model features from approved operational tables
- Inference path: a Python service scores the transaction
- Decision path: the service writes a risk outcome or review requirement back into Oracle
- Alerting path: downstream systems notify analysts or block a workflow
This pattern works because Oracle owns the state transition. The model doesn’t get to invent truth. It informs a decision around a trusted record.
If your team needs help connecting Oracle to orchestration, APIs, or enterprise flows, resources on Oracle Cloud Integration Services can be useful for understanding how integration layers fit around the database without overloading the application tier.
Example two a simple feature store table inside Oracle
For some workloads, especially operational ML, a small feature store can live close to the transactional data.
CREATE TABLE customer_features (customer_id NUMBER PRIMARY KEY,risk_tier VARCHAR2(30),recent_chargeback_flag CHAR(1),account_status VARCHAR2(30),updated_at TIMESTAMP);CREATE TABLE transaction_events (transaction_id NUMBER PRIMARY KEY,customer_id NUMBER NOT NULL,amount_value NUMBER,merchant_category VARCHAR2(100),event_time TIMESTAMP);A scoring service might fetch the latest feature vector like this:
SELECTcf.customer_id,cf.risk_tier,cf.recent_chargeback_flag,cf.account_status,te.amount_value,te.merchant_category,te.event_timeFROM customer_features cfJOIN transaction_events teON cf.customer_id = te.customer_idWHERE te.transaction_id = :transaction_id;This isn’t a full-featured ML platform. It is a practical pattern for low-latency, transaction-adjacent scoring where feature freshness matters and the schema is controlled.
What usually works and what usually fails
What works:
- Stable, curated feature tables
- Clear ownership between app schema and ML schema
- Pipelines that publish into Oracle, not ad hoc notebook writes
- Operational monitoring around SQL behavior and query plans
What fails:
- Letting data scientists query production tables freely
- Mixing transactional schemas with constantly changing experimental features
- Treating Oracle as your document store, feature registry, and analytical warehouse at once
For teams designing the surrounding movement layer, this guide to data pipeline tools for modern platforms is a better place to evaluate replication, orchestration, and delivery options than trying to force every function into the database.
Understanding the Core Oracle RDBMS Architecture
A CTO usually feels Oracle’s complexity the first time an AI team asks a simple question and gets three different answers. Where does the data live? What controls performance? What do we restore after a failure? In Oracle, those are different layers. Once you separate them, the system becomes much easier to evaluate against PostgreSQL, Snowflake, or a managed cloud service.
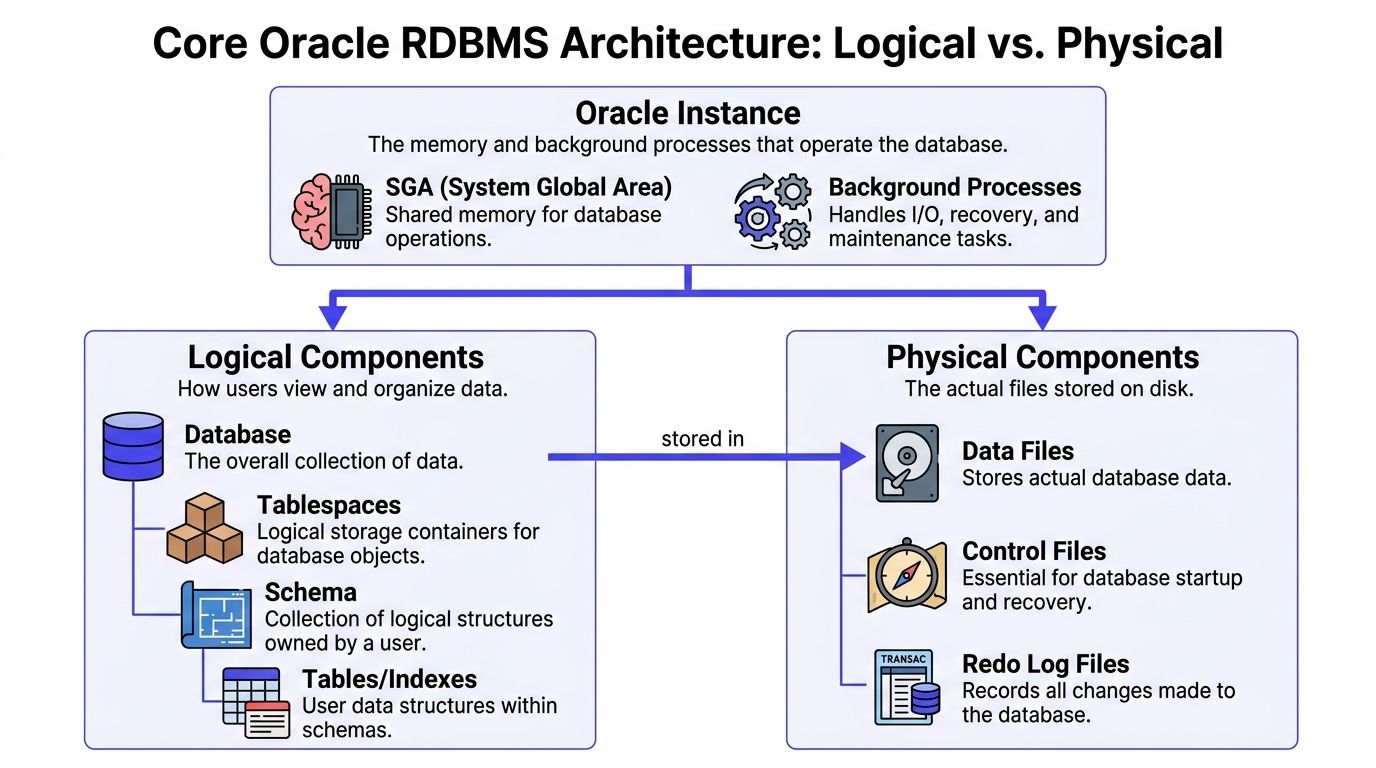
The instance is the running engine
The Oracle instance is the active runtime layer. It includes shared memory, such as the System Global Area, plus background processes responsible for I/O, recovery, scheduling, and cache management.
This is the part your operations team tunes when latency spikes or throughput drops. If sessions are waiting, memory is mis-sized, or recovery behavior is slow, the issue usually sits at the instance layer rather than in table design.
That distinction matters for AI workloads attached to transactional systems. A feature-serving query can be logically correct and still perform badly because the instance is under pressure from other application traffic.
Logical components define ownership and access
The logical architecture is what product, platform, and data teams work with every day:
- Database
- Tablespaces
- Schemas
- Tables and indexes
For AI projects, schemas are where architecture discipline starts. One schema can own product transactions. Another can own derived features for model scoring. A third can hold ingestion or staging objects. That separation reduces accidental joins, privilege sprawl, and deployment conflicts.
I usually advise teams to decide schema ownership before they write the first feature pipeline. Oracle handles strict separation well, but it punishes ambiguity. If application engineers, analysts, and ML engineers all write into the same object space, change control becomes slow and incident response becomes messy.
This also affects governance. Teams storing customer attributes, model inputs, or risk signals need clear controls around access, retention, and auditability. The practical concerns are covered well in this guide to data security controls for large-scale data platforms.
A short visual walkthrough helps if your team is new to Oracle internals:
Physical components determine durability and recovery
The physical architecture is the file layer Oracle writes to and recovers from:
| Physical component | Why it matters |
|---|---|
| Data files | Store persistent table and index data |
| Control files | Track database structure and support startup and recovery |
| Redo log files | Record committed changes for durability and recovery |
Oracle separates itself from lighter operational databases. If your AI feature depends on transaction integrity, recovery objectives, and predictable persistence under heavy write load, these physical components matter a lot. They also add operational overhead.
That overhead is real. Backup design, storage layout, archive log handling, patching discipline, and disaster recovery testing all need owners. Teams without internal depth should understand what an Oracle DBA administrator typically manages before they commit Oracle to a new product surface.
What this means in practice for AI teams
Oracle architecture is powerful because each layer solves a different problem. The instance governs runtime behavior. The logical model governs how teams organize and control data. The physical layer governs durability and recovery.
That structure is a strength when the AI feature sits close to systems of record and failure carries business risk.
It is also why Oracle can feel heavy compared with PostgreSQL or Snowflake. Cloud-native teams often prefer simpler operational models unless they need Oracle’s transactional discipline, recovery model, or long-established enterprise controls. If your team cannot assign clear ownership for each layer, Oracle will slow you down. If you can, it becomes a predictable platform rather than a confusing one.
Core Features Driving Mission Critical Adoption
A CTO usually feels the Oracle decision when an AI feature stops being a lab project and starts touching live business state. A support copilot writes back into a case system. A fraud model influences transaction holds. A next-best-action service reads customer status while orders are still processing. At that point, database features stop being abstract. They become risk controls, latency constraints, and operating cost.
Three Oracle capabilities explain why enterprises still keep mission-critical workloads there, even when newer platforms are easier to run.
Read consistency under concurrency
Oracle is strong at serving reads from a system that is also handling heavy write activity. Its statement-level read consistency, enforced through undo, means queries see a consistent view instead of partially completed changes, as noted earlier in Oracle documentation.
For AI teams, that matters when inference or feature lookups depend on current operational data. If a model reads account state, inventory position, claim status, or workflow progress while transactions are in flight, inconsistent reads can produce wrong recommendations and hard-to-reproduce incidents.
This is one of Oracle’s clearest advantages over simpler setups. It reduces a class of correctness problems that often appears only after traffic grows.
Indexing that improves one workload and taxes another
Oracle indexing gives teams a lot of control, and that control cuts both ways. B-tree indexes can make predictable OLTP queries fast. They can also slow write paths, increase maintenance work, and create plan instability when teams add indexes for every new experiment.
That trade-off matters for AI product work because feature-serving patterns are rarely static in the first few quarters. Data scientists and application engineers test new predicates, join paths, and retrieval logic. If those experiments drive permanent index changes in the core transactional schema, the production system starts carrying costs for workloads that may disappear next sprint.
Use a simple rule set:
- Stable lookup patterns on selective columns are good index candidates.
- Hot columns in write-heavy tables need more scrutiny.
- Queries that support revenue, risk, or service operations deserve deliberate tuning.
- Temporary exploratory access patterns usually belong in a replica, feature store, or analytical system, not in the primary OLTP design.
Oracle environments particularly reward discipline. PostgreSQL teams make many of the same decisions, but Oracle environments tend to surface the cost of bad indexing faster because the surrounding workloads are often larger, older, and less forgiving.
The optimizer is powerful, but it is not self-managing
Oracle’s optimizer is a major reason large enterprises trust the platform. It can produce very good execution plans across complex schemas, mixed workloads, and large volumes. But it still depends on current statistics, sane schema design, and predictable query behavior.
That has a direct implication for AI architecture. If the new feature introduces broad joins, dynamic SQL, or uncontrolled access paths from multiple services, Oracle will not save the team from weak design choices. It will expose them.
I usually advise CTOs to treat optimizer health as an operating model question, not just a tuning question. Who owns statistics quality? Who reviews schema changes? Who decides whether a model-serving query belongs on the primary database or on a downstream copy? Those decisions matter as much as the database engine.
Security and performance also meet here. Uncontrolled query patterns often create side-channel data access, duplicate extracts, and shadow pipelines. Teams that review query design alongside data security controls for large-scale data systems avoid a lot of avoidable rework.
The business case
These features explain why Oracle remains common in high-consequence systems:
- Read consistency protects application and model correctness during concurrent activity.
- Indexing control helps teams tune known access paths, but it raises the cost of bad design choices.
- Optimizer depth supports complex enterprise workloads, provided the team has operating discipline.
For an AI feature that acts on live transactional state, those are meaningful advantages. For a team optimizing for rapid experimentation, low admin overhead, and loose coupling, PostgreSQL, Snowflake, or another cloud-native option may be the better fit. Oracle earns its complexity when correctness, control, and operational predictability matter more than speed of iteration.
Checklist Oracle RDBMS Evaluation for AI Projects
Teams don’t need another opinion. They need a scoring tool they can use in a working session with engineering, data, platform, and finance.
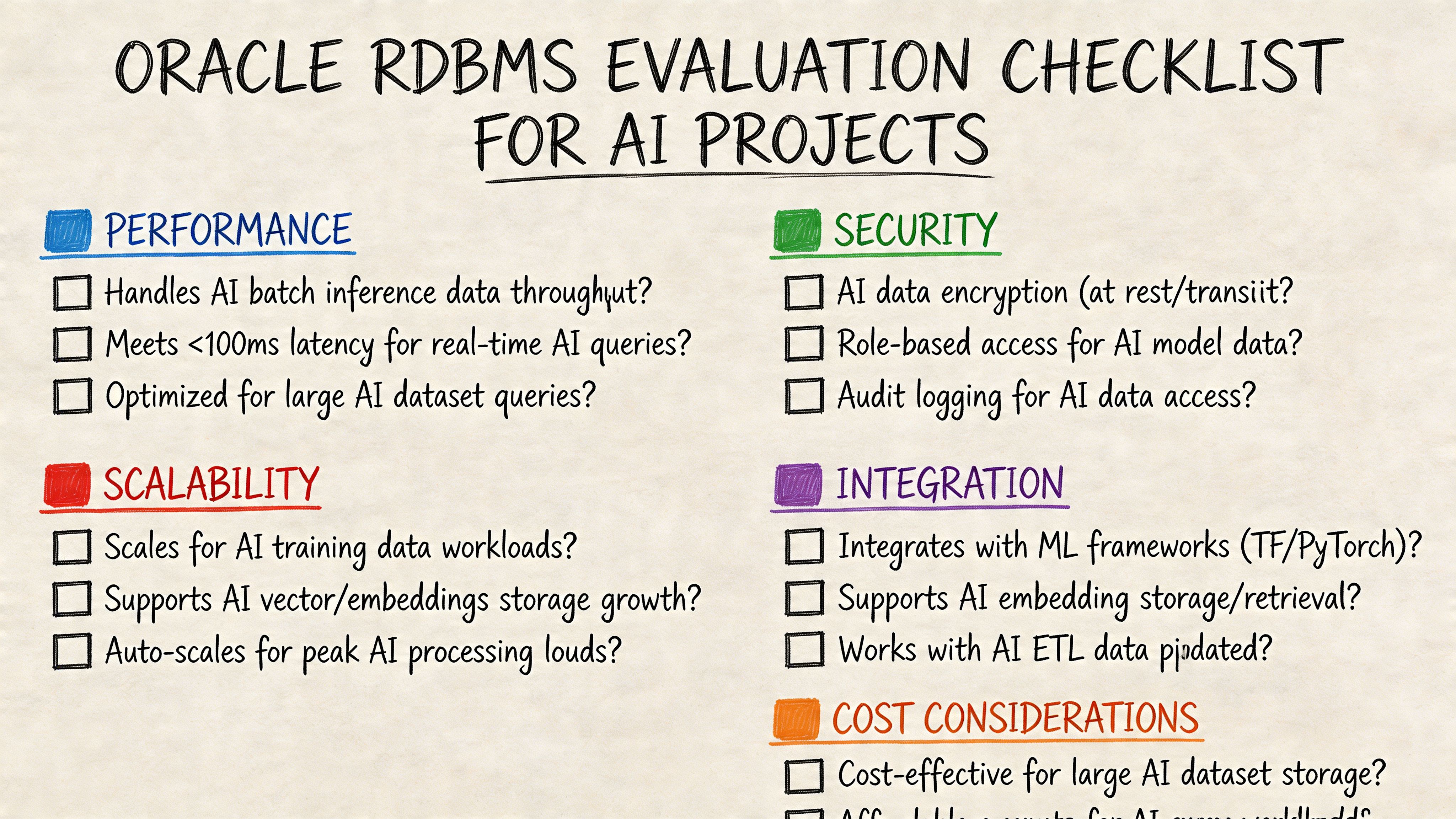
Oracle documentation makes clear that the platform can extend the relational model for complex data, but it offers minimal guidance for modern AI/ML pipeline architecture, as noted in Oracle’s Database 21c concepts documentation. That’s why a checklist helps. It forces explicit decisions instead of assumptions.
A practical evaluation checklist
Use these questions with your team:
Workload fit
- Is this a transactional feature? Does the AI output affect a live business workflow?
- Is Oracle the source of truth? If not, why must the feature run close to Oracle?
Architecture fit
- What data belongs in Oracle? Separate transactional entities, derived features, and analytical history.
- What stays outside? Define where documents, embeddings, event streams, and large artifacts live.
Team fit
- Who owns database performance?
- Who approves schema changes and index changes?
- Do we have Oracle operations capability, or will we need specialist support?
Cost and governance
- Have we compared Oracle against PostgreSQL for this exact workload?
- Have we identified the compliance, recovery, and audit requirements that justify Oracle’s complexity?
If your team can’t answer these questions crisply, don’t choose Oracle yet. Lack of clarity is usually a stronger risk signal than lack of features.
A useful internal artifact is a simple scorecard with red, yellow, and green status for each category. That makes the decision visible and defensible when finance or product leadership asks why the stack looks the way it does.
What To Do Next
Your CTO does not need another abstract database debate. Your CTO needs a decision that survives architecture review, finance scrutiny, and the first production incident.
Start by turning the discussion into a short decision session with engineering, data, product, and operations in the room. Score the AI feature against the checklist you just built. Focus on three questions. Does the feature need Oracle-grade transactional control at the point of inference or write-back? Is Oracle already the operational system you cannot move away from? Does the team have the skill and budget to run it well?
Then test the answer with a pilot. Keep the scope narrow enough that failure is cheap and success is meaningful.
- One production-adjacent data flow
- One model inference or rules decision
- One write-back into the system of record
- One review of latency, query plans, rollback behavior, and operational ownership
That pilot should answer a practical question. Is Oracle the right foundation for this AI feature, or just the database you already have?
For many teams, the best outcome is a split architecture. Oracle handles the transactional core. PostgreSQL, a vector store, object storage, or Snowflake handle the parts of the AI stack that change faster, scale differently, or cost less to operate. If the pilot shows that Oracle adds control you need, keep it in the path. If it adds process, licensing burden, and specialist dependency without improving the product, keep Oracle out of the critical AI loop.
The final decision should define Oracle’s role precisely. System of record, feature serving store, write-back target, or not used at all. Clarity here prevents the common failure mode where a team inherits Oracle complexity without getting Oracle’s actual advantages.
If you’re weighing Oracle against other database options for a new AI feature, ThirstySprout can help you scope the architecture, pressure-test the trade-offs, and bring in vetted data architects, MLOps engineers, and AI specialists fast. If you need to move from debate to a working pilot, start a pilot with ThirstySprout and get the right technical team in place without a long hiring cycle.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.