
TL;DR: What You Need to Know
- Security isn't an add-on. It must be designed into your big data architecture from day one. Trying to bolt on security after the fact is expensive, ineffective, and leads to breaches.
- Focus on four pillars: Your strategy must cover end-to-end encryption (at rest, in transit, in use), strict access control (IAM, RBAC/ABAC), secure MLOps pipelines (CI/CD scanning), and continuous, automated monitoring.
- A misconfigured cloud bucket is your biggest threat. Simple human error in cloud storage permissions is still the leading cause of massive data leaks. Automate configuration checks to prevent this.
- Actionable next steps: Start with a rapid risk assessment of your "crown jewel" data systems, enforce MFA everywhere, and hire or upskill a dedicated data security engineer with cloud IAM and Infrastructure-as-Code skills.
Who This Guide Is For
This guide is for technical leaders who are responsible for building or managing large-scale data and AI systems:
- CTO / Head of Engineering: You need a practical framework to manage risk without slowing down innovation.
- Founder / Product Lead: You're scoping the budget and team required to build secure, compliant AI features.
- Data / MLOps Lead: You are on the front lines, implementing the technical controls that keep data safe.
If you need to make sound architectural decisions and justify security investments to the board, this guide is for you.
Your 3-Step Framework for Big Data Security
Knowing the theory is great, but putting it into practice is what actually keeps your company's data safe. If you're wondering where to start, here's a straightforward, three-step plan to make tangible progress in the next 90 days.
Step 1: Run a Rapid Risk Assessment (1-2 Weeks)
You can't defend what you don't understand. Get a clear picture of your biggest vulnerabilities before a bad actor finds them.
- Map your data's journey: Trace where your most sensitive information lives, from collection to storage. Where is PII, financial records, or proprietary IP?
- Identify your "crown jewels": Pinpoint the 3-5 systems that would cause the most damage if compromised (e.g., the production Amazon S3 data lake, the core Snowflake data warehouse, the Kubernetes cluster serving your ML models).
- Threat model your top risks: Focus on the most likely and damaging scenarios. Model a misconfigured S3 bucket, stolen engineer credentials, or an unsecured API endpoint.
Step 2: Lock Down the Foundations (3-4 Weeks)
Once you know your risks, plug the most critical holes first. Prioritize controls that give you the most impact for the least effort.
- Enforce MFA everywhere. This is the single quickest and most impactful security win. Make multi-factor authentication mandatory for every user and service account. No exceptions.
- Shrink IAM roles: Go through your AWS, GCP, or Azure IAM roles. If a user or service doesn't absolutely need a permission, revoke it. The goal is least privilege.
- Automate vulnerability scanning: Integrate a dependency and container scanner into your main CI/CD pipeline. This creates an automated checkpoint that catches vulnerabilities before they reach production.
Step 3: Get the Right People in Place (Ongoing)
Tools and processes are only half the battle. You need skilled people to drive your security strategy and adapt to new threats.
- Decide to build or buy: You can upskill your current data engineers on security best practices. For complex environments, hiring a dedicated data security engineer is a game-changer.
- Hire for specific skills: A great data security engineer needs deep expertise in cloud IAM, Infrastructure-as-Code (e.g., Terraform, CloudFormation), and the security models of distributed systems like Apache Spark and Apache Kafka.
Practical Examples of Big Data Security in Action
Theory is one thing; real-world implementation is another. Here are two practical examples of how security controls are applied in common big data scenarios.
Example 1: Securing a Fintech's SOC 2 Audit on Snowflake
A Series B fintech company was preparing for its first SOC 2 audit and needed to secure its Snowflake data warehouse. Raw transaction data, analytics tables, and sensitive customer PII were mixed, creating a compliance nightmare.
Here’s the 3-step technical fix they implemented:
- Implemented Tag-Based Masking: They used Snowflake’s dynamic data masking to automatically hide sensitive columns (like Social Security Numbers) from analysts. Privileged service accounts could still see the raw data, but the default was secure.
- Created Segregated Roles: They replaced generic
admin/userroles with a granular system:PII_ACCESS_PROD,ANALYTICS_READ_ONLY, andETL_WRITE_RAW. This enforced the principle of least privilege. - Enabled Access History Logging: They activated Snowflake’s query logging to create an immutable audit trail. During the audit, they could prove exactly who accessed what data and when, satisfying a key SOC 2 control.
This didn't just pass the audit; it dramatically reduced the risk of an internal data breach.
Example 2: Sample Terraform for a Secure S3 Data Lake Bucket
This is the low-hanging fruit for attackers. A public S3 bucket can leak terabytes of data. This Terraform snippet shows a minimal set of controls to create a private, encrypted bucket.
# main.tf - Secure S3 Bucket Configurationresource "aws_s3_bucket" "secure_data_lake_bucket" {bucket = "thirsty-sprout-secure-datalake-prod"tags = {Name = "Secure Production Data Lake"Environment = "Production"ManagedBy = "Terraform"}}# Block all public access at the bucket levelresource "aws_s3_bucket_public_access_block" "block_public" {bucket = aws_s3_bucket.secure_data_lake_bucket.idblock_public_acls = trueblock_public_policy = trueignore_public_acls = truerestrict_public_buckets = true}# Enforce server-side encryption with AWS-managed keys (SSE-S3)resource "aws_s3_bucket_server_side_encryption_configuration" "enforce_encryption" {bucket = aws_s3_bucket.secure_data_lake_bucket.idrule {apply_server_side_encryption_by_default {sse_algorithm = "AES256"}}}# Bucket policy to enforce encryption on all object uploadsresource "aws_s3_bucket_policy" "enforce_tls_and_sse" {bucket = aws_s3_bucket.secure_data_lake_bucket.idpolicy = jsonencode({Version = "2012-10-17"Statement = [{Sid = "DenyIncorrectEncryptionHeader"Effect = "Deny"Principal = "*"Action = "s3:PutObject"Resource = "${aws_s3_bucket.secure_data_lake_bucket.arn}/*"Condition = {"StringNotEquals" = {"s3:x-amz-server-side-encryption" = "AES256"}}},{Sid = "DenyUnEncryptedObjectUploads"Effect = "Deny"Principal = "*"Action = "s3:PutObject"Resource = "${aws_s3_bucket.secure_data_lake_bucket.arn}/*"Condition = {"Null" = {"s3:x-amz-server-side-encryption" = "true"}}}]})}Commentary: This code enforces three critical controls: it blocks all public access, enables server-side encryption by default, and includes a bucket policy that actively denies any attempt to upload an unencrypted object. This is a foundational "Security as Code" practice.
Deep Dive: Key Challenges and Trade-offs
The scale and speed of big data create a massive attack surface. Traditional security tools can't keep up. Every node in your distributed system, every API call, and every step in a data pipeline is a potential entry point for an attacker.
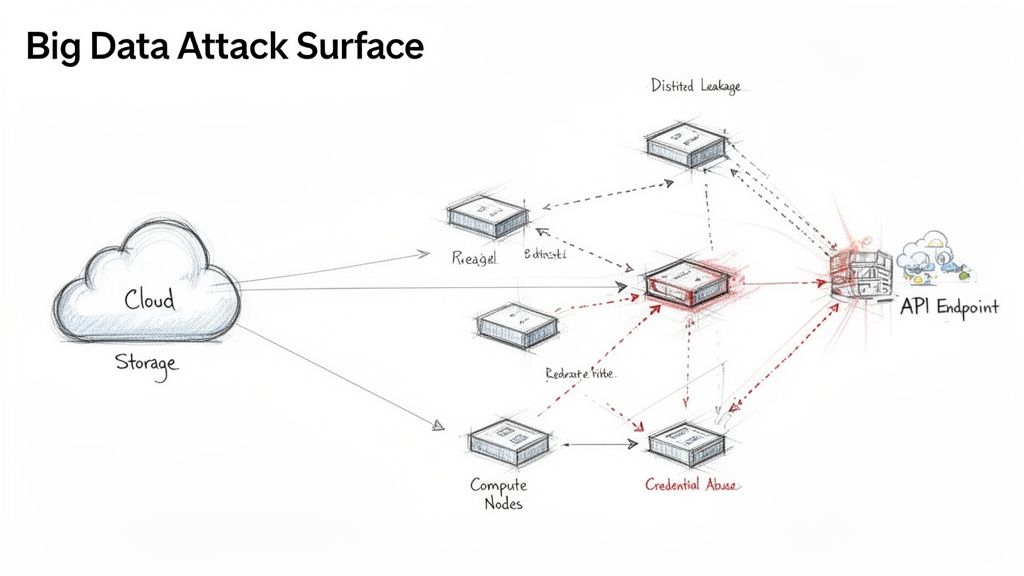
alt text: Diagram illustrating the Big Data Attack Surface, showing cloud storage, compute nodes, API endpoints, and various attack vectors like distilled leakage and credential abuse.
A single breach can lead to huge financial penalties, a damaged reputation, and loss of customer trust. In 2023, the Identity Theft Resource Center (ITRC) tracked 3,205 data compromises in the U.S., impacting over 353 million people—a 72% increase from 2022. You can read more cybersecurity statistics on Preveil's blog. Your data pipelines, processing terabytes of user data, are a prime target.
Primary Attack Vectors Your Team Must Address
Focus your energy on the threats that cause the most damage.
- Misconfigured Cloud Storage: A public S3 bucket or an improperly configured Azure Blob Storage container is the most common cause of massive data leaks.
- Insecure API Endpoints: APIs that ingest data or serve model predictions are prime targets. Without strict authentication, rate limiting, and input validation, they are open doors.
- Credential Abuse in Distributed Frameworks: In tools like Apache Spark and Hadoop, a compromised node's credentials can be used to move laterally across the entire cluster.
- Data Leakage from Analytics Platforms: Poorly configured BI tools or data science notebooks can become accidental backdoors, exposing sensitive customer records or proprietary algorithms.
- ML Model Integrity Attacks: Sophisticated attackers can poison your training data to skew model results or use inversion attacks to reverse-engineer sensitive training data from a model's outputs.
The global cybersecurity market is projected to exceed $520 billion annually by 2026, largely driven by the need to defend these complex data ecosystems. See the full cybersecurity market predictions and statistics for more detail.
Architecting Security into Your Big Data Foundation
You can't add security later. It must be baked into your architecture from the start. A security-first mindset treats data protection as a non-negotiable part of the design.
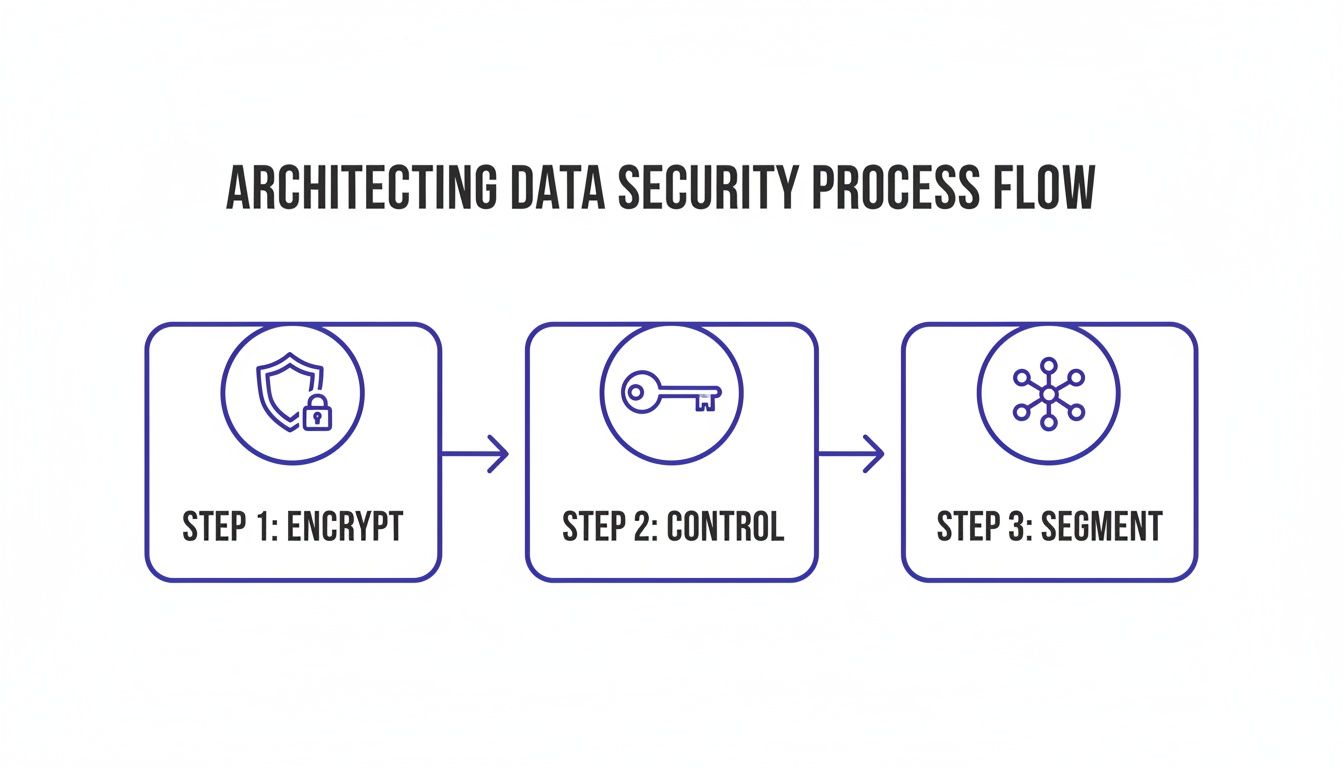
alt text: A diagram illustrates the architectural data security process flow with steps: encrypt, control, and segment.
A resilient big data architecture rests on three pillars:
Encrypt Everything, Everywhere: Protect data in all three states.
- Data at Rest: Use transparent data encryption (TDE) or server-side encryption (SSE) for data in storage like Amazon S3 or HDFS.
- Data in Transit: Enforce TLS/SSL for all data moving between services or across data pipelines.
- Data in Use: Use confidential computing technologies like AWS Nitro Enclaves to protect data while it is being processed in memory.
Isolate and Segment Your Network: Use Virtual Private Clouds (VPCs) to create separate network sandboxes for development, staging, and production. Inside each VPC, use subnets and security groups to create smaller, stricter zones to contain any potential breach.
Lock Down Your Keys: Use a centralized Key Management System (KMS) like AWS KMS or HashiCorp Vault to manage the entire lifecycle of your cryptographic keys securely and audibly.
- Role-Based Access Control (RBAC): You create roles like "DataAnalyst," attach permissions, and assign users to them. RBAC is simple and effective for teams with clear job functions.
- Attribute-Based Access Control (ABAC): Access is determined by policies that evaluate attributes in real-time (e.g., user department, data sensitivity tag, time of day). ABAC offers fine-grained control for complex environments.
- Scan Dependencies: Use tools like Snyk to scan dependencies for known vulnerabilities.
- Static Application Security Testing (SAST): Run SAST tools to find security flaws in your source code.
- Container Image Scanning: Use a scanner like Trivy to check your container images for vulnerabilities.
- Manage Secrets Securely: Use a secrets manager like AWS Secrets Manager to inject credentials at runtime. Never hardcode them.
- All cloud storage buckets (S3, GCS, etc.) have public access blocked by default.
- Server-side encryption is enabled and enforced on all data-at-rest.
- Multi-Factor Authentication (MFA) is mandatory for all users with access to data infrastructure.
- Network traffic between services is encrypted using TLS/SSL.
- A centralized secret management tool (e.g., Vault, AWS Secrets Manager) is used for all credentials.
- IAM roles follow the principle of least privilege; no wildcard (
*) permissions in production. - A clear RBAC model is defined and documented for user roles (e.g., Analyst, Data Scientist, MLOps Engineer).
- Sensitive data (PII, PHI) is tagged, and access is restricted using masking or column-level security.
- All access to production data warehouses and data lakes is logged for auditing.
- Automated dependency scanning is integrated into the CI/CD pipeline.
- Automated container image scanning is integrated into the CI/CD pipeline.
- Static Application Security Testing (SAST) is run on model training and inference code.
- Model serving APIs require strong authentication and authorization for every request.
- An automated alerting system is in place for suspicious activity (e.g., unusual data access patterns).
- A documented incident response plan exists and is reviewed quarterly.
- A process for handling "right to be forgotten" (GDPR) requests is defined and tested.
- Data retention and destruction policies are defined and automated where possible.
- Run a 1-week risk assessment. Use the checklist above to identify your top 3 security gaps. Focus on your "crown jewel" data systems first.
- Lock down the fundamentals. In the next 30 days, enforce MFA everywhere and conduct a full audit of your IAM roles to eliminate excessive permissions.
- Secure your talent pipeline. Your security is only as strong as the team implementing it. If you lack in-house expertise, don't wait for a breach to act.
- Preveil: 2023 Cybersecurity Statistics
- Cybersecurity Ventures: Official 2026 Cybersecurity Market Report
- ThirstySprout: Best Data Pipeline Tools
- ThirstySprout: MLOps Best Practices
- ThirstySprout: AI Governance Best Practices
As you build, remember that securing data migrations and transformations is critical for maintaining control.
Choosing Your Access Control Model: RBAC vs. ABAC
You need a scalable model for managing data access.
RBAC vs. ABAC: A Quick Comparison
A practical approach is to start with a clean RBAC model and evolve toward ABAC as your needs grow. Explore the best data pipeline tools to see how these models integrate with your infrastructure.
Weaving Security into the MLOps Lifecycle
Security must be a continuous, automated process within your MLOps pipeline.
Start with secure data ingestion. Validate that all incoming data matches your expected schema to prevent injection attacks. Use anonymization and pseudonymization techniques to mask or remove Personally Identifiable Information (PII). Tools like AWS Glue DataBrew can automate masking for structured data, while Named Entity Recognition (NER) models can redact PII from unstructured text.
Your CI/CD pipeline for models must include automated security gates:
Finally, lock down your model serving endpoints. Implement strong authentication (API keys, OAuth 2.0) and authorization (IAM roles). Validate all input data to prevent malicious payloads, and log all API requests to detect suspicious activity. For a deeper dive, review our guide on MLOps best practices.
Navigating Governance and Compliance
Good governance ensures your architecture meets legal and ethical standards like GDPR, CCPA/CPRA, and SOC 2. These regulations require you to design systems that can trace data lineage and perform targeted data deletion on demand.
Key Regulations and Their Impact on Big Data Architecture
Governance transforms security into a proactive discipline that supports business growth. Learn more in our guide to AI governance best practices. Good practices also extend to hardware, including compliant data destruction of retired servers.
Big Data Security Checklist
Use this checklist to audit your current security posture and plan your next steps.
Foundation (P0 - Must-Haves)
Access Control (P1 - High Priority)
MLOps & CI/CD (P1 - High Priority)
Monitoring & Governance (P2 - Important)
What to Do Next
Finding engineers with deep skills in cloud security, IaC, and distributed systems is tough. ThirstySprout connects you with vetted, senior AI and data security engineers who can implement these controls from day one.
Start a Pilot and see how quickly the right expertise can fortify your defenses.
References
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.