
A candidate clears the interview, joins your team, and looks strong for two weeks. Then the nightly pipeline misses its SLA, an executor starts dying under skew, and the new hire can explain Spark syntax but not why the job failed or how to contain the blast radius. That is the hiring mistake this interview guide is built to prevent.
Spark interviews fail when they reward recall instead of judgment. Production Spark work is rarely about writing map, filter, or a clean demo join on balanced sample data. It is about choosing the right abstraction, reading a physical plan, spotting where memory pressure will hit first, and knowing which fixes are safe under time pressure. Hiring managers need questions that expose those habits.
That is why this article is structured as a hiring framework, not a generic list of spark interview questions. Each topic includes a model answer, an interviewer's scoring rubric, common red flags, and the business impact of getting the decision right or wrong. If you want a broader companion resource, this guide to Hadoop and Spark interview questions for data engineering hires is useful context, but the focus here stays on how candidates operate in real systems.
The strongest Spark candidates usually sound less polished than the textbook experts. They talk about bad partition choices, runaway shuffles, checkpoint trade-offs, schema drift, and the times they had to decide between shipping a contained workaround and redesigning a pipeline properly. That kind of answer gives you signal.
If you're hiring for data platform, ML infrastructure, analytics engineering, or a senior data engineering role with real production ownership, use these questions to separate operators from theorists. A role like this Web3 data engineering position is a good benchmark for the level of operational judgment senior candidates should handle without supervision.
1. Explain Spark Architecture and Distributed Computing Model
A batch job starts missing its SLA after a data volume jump. The team adds executors, but runtime barely improves. A candidate who understands Spark architecture will usually spot the underlying problem fast. The bottleneck is often in the execution plan, shuffle boundaries, driver behavior, or skewed tasks, not raw cluster size.
That is why this question matters in hiring. It tells you whether someone can explain how Spark runs work across a cluster, and whether they can connect that model to production failures, cost, and recovery behavior.
A model answer should cover the driver, cluster manager, executors, tasks, stages, and shuffles in one coherent explanation. The driver builds the logical plan, turns it into physical execution, schedules work, and tracks application state. The cluster manager assigns resources. Executors run tasks on worker nodes, store cached partitions, and report status back to the driver. Spark splits a job into stages at shuffle boundaries, then breaks stages into tasks that run against partitions.
Good candidates also explain the trade-offs instead of stopping at definitions. Spark performs well when work stays partition-local and avoids unnecessary data movement. It slows down when wide transformations trigger heavy shuffles, when partition sizes are uneven, or when the driver becomes a coordination bottleneck. Engineers who have operated Spark in production usually mention that adding memory or executors does not fix a bad DAG.
A practical answer separates driver failure from executor failure. If an executor dies, Spark can often rerun the lost tasks using lineage and available inputs. If the driver dies, the application usually stops unless the deployment mode and recovery setup were designed for that case. That distinction matters because junior candidates often focus on worker nodes and miss the fact that bad collect() usage, oversized broadcast objects, or too much metadata on the driver can kill an otherwise healthy job.
The strongest answers tie architecture to how they debug. They mention Spark UI, stage-level timing, shuffle read and write metrics, task skew, and executor logs. They know that one slow stage can dominate total runtime, and they can explain why. For broader screening context, this companion guide to Hadoop and Spark interview questions for data engineering hires is a useful pairing.
Practical rule: If a candidate cannot explain the boundary between driver responsibilities and executor responsibilities, they are not ready to own production Spark systems.
Interviewer rubric
- Strong hire: Explains driver, cluster manager, executors, stages, tasks, shuffles, retries, and lineage. Connects architecture to performance, failure handling, and debugging workflow.
- Borderline: Can name Spark components but struggles to explain how work is scheduled or why shuffles change performance.
- Weak: Describes Spark in generic parallel-processing terms and cannot explain what happens after code is submitted.
Red flags
- Treats the driver as a thin client instead of the control plane for the application.
- Talks about worker nodes in broad terms but never mentions stages, tasks, or shuffle boundaries.
- Assumes memory pressure is only an executor problem.
- Suggests scaling cluster size as the first fix for every slow job.
Business impact
This question predicts operational judgment. Engineers who understand Spark's execution model can explain why a pipeline regressed, choose the safest fix under incident pressure, and avoid wasting money on blind cluster expansion. Engineers who do not understand it usually debug by trial and error, which is expensive when your pipeline feeds revenue reporting, fraud detection, or customer-facing data products.
2. RDDs vs DataFrames vs Datasets When to Use Each

This question exposes whether someone still interviews like it's 2017. In modern Spark hiring, you want a candidate who defaults to DataFrames unless they have a clear reason not to.
A solid model answer is simple. RDDs give low-level control and are useful when you're dealing with custom logic or unstructured records that don't fit well into tabular APIs. DataFrames are usually the best production default because Spark can optimize them through Catalyst and the SQL engine. Datasets matter mostly in JVM-heavy codebases where typed APIs are worth the trade-off.
What good judgment sounds like
The best candidates don't turn this into a purity debate. They talk about maintainability, optimizer support, and team skill sets. If your pipeline is feature engineering for a fraud model, DataFrames usually win because they're easier to optimize, inspect, and hand off across teams.
RDDs still have a place. One example is raw text processing where the schema is unstable and you need custom parsing before data becomes tabular. Another is debugging edge-case transformations where explicit control matters more than optimizer help.
A practical answer should also mention lazy evaluation and inspection. Candidates who work in Spark will mention explain() and query plans instead of just saying "DataFrames are faster."
Interviewer rubric
- Strong hire: Defaults to DataFrames, justifies RDD use sparingly, understands optimizer implications.
- Borderline: Knows the definitions but gives no decision framework.
- Weak: Claims RDDs are always better because they provide "more control."
Mini case
Suppose you're ingesting application logs with inconsistent nested fields. A mature engineer may parse the raw payload in an RDD-style step or a custom preprocessing stage, then convert into a DataFrame for joins, aggregations, and downstream feature output. That's the answer I trust. It shows they care about both flexibility and production discipline.
The wrong answer is usually ideological. The right answer is workload-specific.
Red flags
- Treats Datasets as universally required.
- Doesn't know why schema awareness matters.
- Can't explain when optimizer visibility helps.
Business impact
This one matters because abstraction choices affect both speed and operating cost. Teams that force everything through low-level APIs usually end up with slower debugging, harder onboarding, and more brittle code review. Teams that blindly use high-level APIs without understanding edge cases can hide expensive execution plans until they explode in production.
3. Spark SQL Optimization and Query Plans and Catalyst Optimizer
A candidate gets handed a slow Spark SQL job in production. The query looks reasonable, the cluster is large, and the run still misses its SLA. The useful answer starts with the plan, not with more hardware.
Strong Spark engineers can explain how Spark turns a query into work. Catalyst builds a logical plan, applies optimization rules, and selects a physical plan. The point of the interview question is not whether someone can recite those stages from memory. It is whether they know how to write queries the optimizer can still improve, and how to verify what Spark chose with explain() and the Spark UI.
What matters in practice is optimizer visibility. Built-in expressions usually give Spark room to push filters down, prune columns, simplify expressions, and choose better join strategies. UDF-heavy code often blocks that visibility. So do unnecessary projections, late filters, and join logic that forces large shuffles before Spark has a chance to reduce the data.
Good candidates also connect the theory to production trade-offs. A clean SQL statement can still produce an expensive plan if the join order is poor, file statistics are stale, or one side of the join is small enough to broadcast but Spark cannot see that clearly. Adaptive Query Execution should come up here too, especially from candidates who have worked on Spark 3 in real systems. AQE can change join strategy at runtime, coalesce shuffle partitions, and handle some skew cases better than a static plan. That does not remove the need to inspect plans. It just means the final physical plan may improve after execution starts.
What a real answer sounds like
The answer I trust usually sounds something like this: inspect the parsed, optimized, and physical plan, check whether filter pushdown happened, confirm column pruning, look at the join type, and verify whether the shuffle volume matches expectations. If a candidate jumps straight to executor sizing, they are skipping the highest-value step.
I also listen for whether they understand that Spark SQL and DataFrame code usually share the same engine. People who know that tend to debug faster because they reason about plans, not just syntax.
Mini case
A pipeline joins a large events table to a small dimension table and suddenly gets slower after a schema change. A strong candidate says they would inspect the physical plan, confirm whether the small table is still being broadcast, check whether new columns prevented pruning, and see if a UDF or cast pushed filtering later in the plan. They may also ask whether table stats are current, because bad stats can lead Spark to choose the wrong join strategy.
A weak answer is still "add more nodes."
Interviewer rubric
- Strong hire: Explains logical versus physical plans clearly, uses
explain()as a default tool, understands why built-in functions are preferable to opaque UDFs, and can discuss AQE as a runtime improvement rather than a magic fix. - Borderline: Knows Catalyst exists and mentions pushdown or broadcast joins, but cannot connect those ideas to a debugging workflow.
- Weak: Treats SQL tuning as cluster tuning, cannot read a plan, or assumes a clean query string means an efficient execution plan.
Red flags
- Talks about Catalyst as a black box that "makes queries fast."
- Cannot explain the difference between a logical plan and a physical plan.
- Uses UDFs for transformations Spark can express with native functions.
- Never mentions
explain(), the Spark UI, or join strategy inspection. - Assumes AQE will fix poor query design automatically.
Business impact
This question screens for engineers who can control cost and predictability, not just write working code. Teams with strong SQL plan literacy catch bad joins before they hit nightly ETL, keep cloud spend from drifting upward, and recover faster when a schema or stats change shifts a stable workload onto a worse execution path. That is why this article treats each interview question as more than a prompt. The hiring value comes from the model answer, the rubric, the red flags, and the operational consequence of getting the hire wrong.
4. Handling Data Skew and Partitioning Strategies

A pipeline hits every SLA in staging, then misses by an hour in production after one large customer lands. The cluster size did not change. The code barely changed. One join key did. That is why this question works so well in interviews. It surfaces whether the candidate has dealt with real Spark failure modes or has only tuned happy-path jobs.
Data skew means work is distributed unevenly across partitions. In practice, a small number of partitions or keys absorb most of the data, so a few tasks run far longer than the rest. Spark looks busy, but much of the cluster is waiting on stragglers. Partitioning strategy is the related design choice. It decides how records are laid out before wide operations like joins, aggregations, and window functions.
Strong candidates talk about diagnosis before fixes. They check the Spark UI for long-tail task durations, spilled shuffle data, and stages where a handful of tasks dominate runtime. They inspect key frequency in the data itself because skew is often a data problem first and a Spark problem second. Then they choose a mitigation based on the shape of the workload, not on habit.
A practical answer usually includes several options and the cost of each:
- Repartition by the right key: Useful when the current partitioning is arbitrary or inherited from an earlier stage. It can improve parallelism, but it introduces a shuffle, so the candidate should explain why the extra movement is justified.
- Salt hot keys: Effective for joins or aggregations where a few keys are much heavier than the rest. It spreads those keys across multiple partitions, but it also adds code complexity and can make downstream logic harder to reason about.
- Broadcast the small side of a join: Good when one dataset is small enough to distribute to executors safely. It removes the large shuffle, but a candidate should mention executor memory pressure and the risk of forcing a broadcast that does not fit cleanly.
- Use custom partitioning or pre-aggregation: Often the right answer for recurring batch pipelines with predictable skew patterns. It takes more design work up front, but it can stabilize runtimes better than repeated ad hoc tuning.
- Let Adaptive Query Execution help, but not decide everything: AQE can split skewed partitions and improve some joins at runtime. Senior candidates should still treat it as a safety net, not as the primary plan.
Here is the kind of production case that separates strong answers from generic ones. An events table is joined to a user dimension on user_id. A small set of users generates an outsize share of events. Random repartitioning will not solve the underlying hotspot because the expensive join key still dominates. A better answer is to measure key skew, salt only the hot keys, broadcast the dimension if it is small enough, and confirm in the UI that the worst stragglers disappear after the change.
One sentence I listen for is simple: partitioning should follow the access pattern. If a candidate says that clearly and can defend it with an example, they usually understand Spark beyond syntax.
Model answer
Data skew happens when partitions are uneven, usually because a few keys are far more frequent than others. I would confirm it in two places: the Spark UI, where skew shows up as a small number of very slow tasks, and the data itself, where key counts reveal the hotspot. My fix depends on the operation. For a skewed join, I would consider broadcasting the small side first if it is safe in memory. If the skew is on a few hot keys, I would salt those keys rather than repartition everything blindly. If the partitioning is wrong for the workload, I would repartition on the join or aggregation key and accept the shuffle if it reduces repeated imbalance later in the job. I would also check whether AQE is enabled, because it can improve skew handling at runtime, but I would not rely on it to rescue poor partition design.
Interviewer rubric
- Strong hire: Diagnoses skew with both data inspection and Spark UI evidence, explains at least two mitigation options, and names the trade-offs in shuffle cost, memory use, and code complexity.
- Borderline: Knows terms like salting or repartitioning but cannot connect them to a specific failure pattern or workload shape.
- Weak: Frames skew as a cluster sizing problem, suggests adding executors first, or treats partition count tuning as a complete answer.
Red flags
- Recommends
repartition(1000)without explaining why that partitioning matches the join or aggregation pattern. - Never mentions hot keys, task skew, or uneven shuffle read and write behavior.
- Assumes broadcast joins are always better.
- Treats AQE as an automatic fix for any slow stage.
- Cannot explain why one slow task can hold an entire stage open.
Business impact
This question is about cost control and predictability. Teams that hire engineers who understand skew spend less time chasing “random” SLA misses that only appear on large customers, quarter-end loads, or uneven regional traffic. Teams that miss on this hire keep paying for oversized clusters while the underlying issue sits in partition design and join strategy. That is the broader value of this interview framework. The question matters, but the hiring signal comes from the model answer, the scoring rubric, the red flags, and the operational consequence of getting the call wrong.
5. Spark Streaming vs Structured Streaming and Real-time Data Processing
A payments stream can look healthy in Grafana even as it writes duplicate transactions for an hour. That is why this interview question matters. It tests whether the candidate understands real-time systems as production systems, not just as Spark APIs.
For senior hires, Structured Streaming should be the center of the answer. It uses the DataFrame and SQL engine, shares optimization behavior with batch workloads, and gives teams a consistent model for stateful processing, event time, and sink writes. DStreams still come up in legacy estates, but I would treat deep DStream-first answers as maintenance experience, not current design judgment.
The candidate should explain the execution model in plain language. Structured Streaming is usually micro-batch, even if the user experience feels continuous. Continuous processing exists, but very few teams choose it because the operational limits and sink constraints narrow where it fits. Good candidates know the difference and do not oversell "real time" as a single latency target. They ask what the business needs: sub-second alerts, five-second feature freshness, or minute-level aggregate updates.
That distinction changes the design.
Production awareness shows up in the failure modes they mention. Late data, out-of-order events, state growth, checkpoint recovery, replay behavior, and sink idempotency are the topics worth hearing. Fraud scoring, sessionization, recommendation features, and ops alerting all fail in different ways. A candidate who has run these systems will tie technical choices to those failure modes instead of reciting API methods.
A strong model answer usually sounds like this: use Structured Streaming with event-time windows when correctness depends on when the event happened, not when Spark received it. Add watermarking to bound state and define how long the system should wait for late records. Store checkpoints in durable storage so offsets and state can recover after executor or driver failure. Treat exactly-once claims carefully, because Spark can manage its side of the state and source progress, but the end-to-end result still depends on whether the sink can handle retries without duplicating writes.
That last point separates strong candidates from tutorial-level ones.
Exactly-once semantics are often misunderstood in interviews. Spark can provide exactly-once processing semantics for supported patterns, but the business result is only exactly once if the output system also behaves correctly under retry and replay. If the sink is a database table without idempotent keys, or a REST endpoint with side effects, "exactly once" becomes a dangerous phrase. I want candidates who say that clearly.
Two follow-up questions that expose real experience
- How would you handle late-arriving events in a sessionization pipeline?
- What would you checkpoint, and what failure would checkpointing not fix?
Strong candidates discuss watermark thresholds as a business decision, not a default setting. They should explain the trade-off directly. A longer watermark improves correctness for late events but increases state size, memory pressure, and recovery cost. A shorter watermark lowers resource use and latency risk, but it drops or misclassifies late records sooner.
On checkpointing, they should know what it protects and what it does not. Checkpoints help recover query progress, state, and source offsets. They do not fix bad sink design, corrupted upstream events, or non-idempotent side effects that already happened before the failure.
Interviewer rubric
- Strong hire: Explains why Structured Streaming is the default choice for new Spark streaming work, describes micro-batch versus continuous processing accurately, and connects watermarking, state management, checkpointing, and sink semantics to correctness and recovery.
- Borderline: Knows the API surface and can describe a demo pipeline, but gives vague answers on late data, state cleanup, replay, or duplicate writes.
- Weak: Focuses on Kafka ingestion and trigger intervals only, treats exactly-once as automatic, or cannot explain how event time differs from processing time.
Red flags
- Says Structured Streaming is always real time without clarifying latency expectations or execution mode.
- Treats checkpointing as a complete disaster recovery plan.
- Assumes Kafka offsets alone guarantee correct results.
- Never mentions watermarking, state retention, or sink idempotency.
- Confuses processing-time windows with event-time correctness.
Business impact
Streaming mistakes usually fail without warning. The job stays green while aggregates drift, customer notifications arrive twice, fraud rules miss late events, or online features go stale. Hiring someone who understands those trade-offs helps the team choose the right latency target, keep state under control, and avoid expensive incidents that look like "data quality issues" but are really design mistakes. That is the point of this interview framework. The question matters, but the stronger hiring signal comes from the model answer, the scoring rubric, the red flags, and the consequence of getting the decision wrong.
6. Spark Memory Management and Tuning
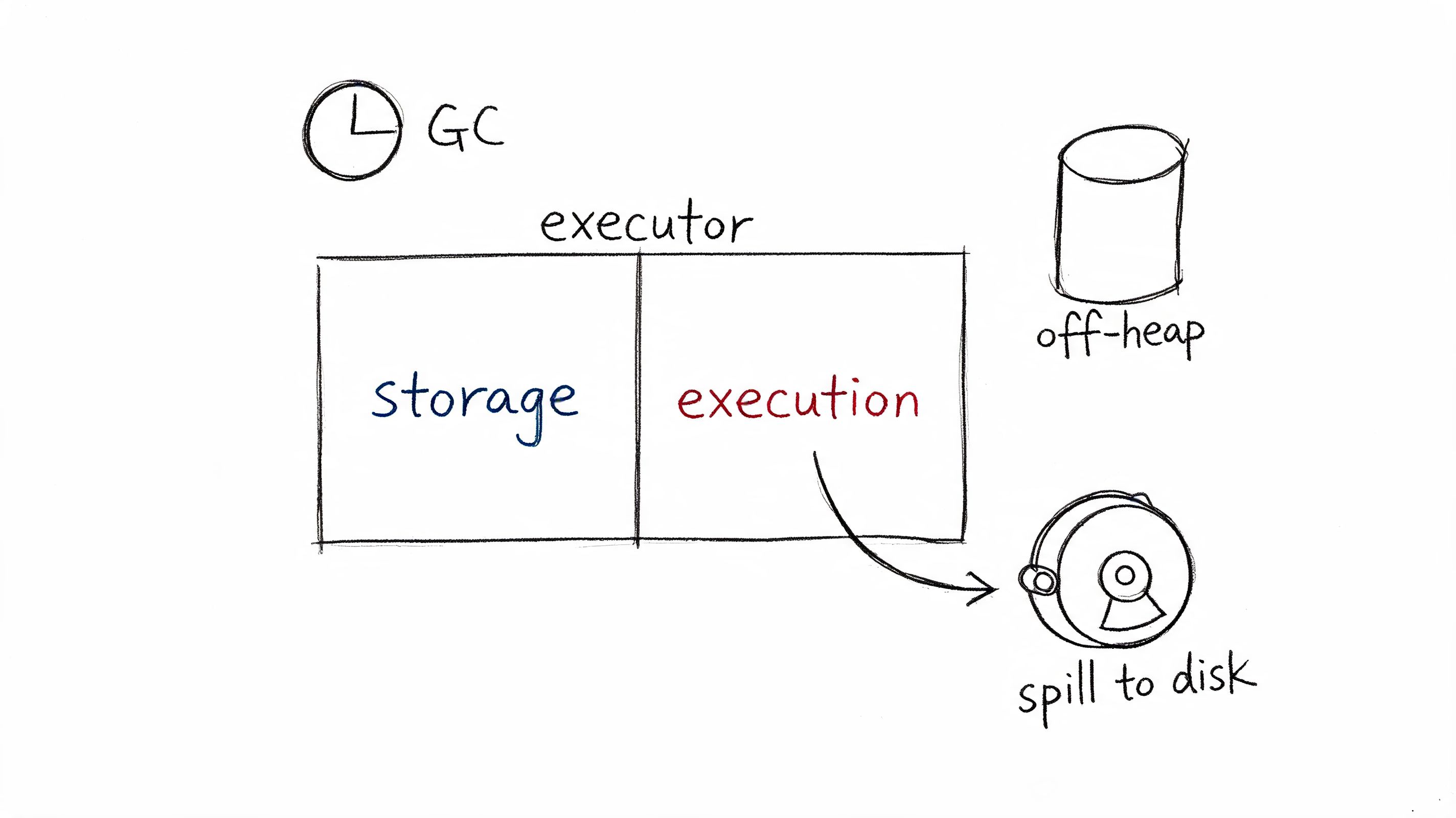
A Spark job runs fine in test, then falls over in production after the input doubles and a wide join hits shuffle. That is the interview scenario I care about here. Memory problems expose whether a candidate can diagnose real systems or only repeat config names.
The right answer starts with Spark's memory model and then ties it to symptoms. Candidates should explain the pressure between execution memory and storage memory, why spills happen, how off-heap memory can shift pressure, and why garbage collection gets ugly long before an executor dies. They should also separate executor failures from driver failures. A candidate who has been on call usually brings that up without prompting.
Good candidates do not treat --executor-memory as the main knob. They ask what the workload is doing. Shuffle-heavy joins, large aggregations, skewed partitions, cached DataFrames, Python UDFs, Arrow transfers, and oversized broadcasts fail in different ways. The tuning path changes with the failure mode.
What strong candidates say
A strong answer usually sounds like an investigation, not a recipe:
- Start with the Spark UI. Check spill metrics, task time, skewed partitions, storage usage, and executor loss patterns.
- Identify whether the pressure is on heap, off-heap, or driver memory.
- Ask whether cached data is competing with shuffle execution.
- Check partition sizing. Very large partitions create tasks that spill and stall.
- Look for anti-patterns such as
collect(),toPandas(), widegroupByKey, or broadcasting data that should not be broadcast. - Change one variable at a time, then confirm the effect in metrics.
That is what this hiring framework is meant to test. The question matters, but the stronger signal comes from how the candidate reasons, how you score the answer, which red flags show up, and what kind of production risk follows from a weak hire.
Model answer
If a join-heavy ETL pipeline is spilling heavily, I would first confirm whether the issue is partition sizing, skew, caching pressure, or a bad execution plan. Increasing executor memory might buy time, but it often hides the underlying problem and increases GC pauses.
Next, I would inspect storage use versus execution needs in the Spark UI. If cached tables are consuming memory needed for shuffle, I would unpersist aggressively or avoid caching altogether. If a small number of tasks are much slower and spill far more than the rest, I would suspect skew or oversized partitions and fix the data layout before I changed cluster size.
I would also check for driver-side mistakes. A job can look like an executor memory problem when the underlying issue is a large collect() or result serialization back to the driver.
Representative config:
spark.conf.set("spark.sql.adaptive.enabled", "true")spark.conf.set("spark.executor.cores", "5")spark.conf.set("spark.executor.memoryOverhead", "10%")AQE can help after shuffle boundaries, but it is not a substitute for sane partitioning or a better join strategy.
Interviewer scoring rubric
- Strong hire: Explains heap versus off-heap pressure, execution versus storage trade-offs, spill behavior, GC symptoms, and driver versus executor failure patterns. Connects tuning choices to workload shape and verifies changes with Spark UI metrics.
- Borderline: Knows several memory-related settings and can name spilling and caching issues, but struggles to connect symptoms to root cause or proposes tuning changes without a clear diagnostic path.
- Weak: Recommends adding RAM, increasing executors, or caching more data without examining skew, partition size, shuffle behavior, or driver actions.
Red flags
- Says caching is always a performance improvement.
- Talks only about executor memory and ignores the driver.
- Cannot explain why wide transformations and shuffles cause spill.
- Mentions broadcast joins without discussing broadcast size limits or executor overhead.
- Treats memory tuning as isolated from partitioning, skew, and query plan quality.
Business impact
Memory mistakes show up as both reliability problems and cloud spend. Jobs become flaky under normal growth, retries increase cluster load, and teams respond by overprovisioning instead of fixing the plan. In an interview loop, that distinction matters. You are not hiring someone to memorize Spark settings. You are hiring someone who can keep production pipelines stable as data volume, concurrency, and SLA pressure increase.
7. Spark and Machine Learning and MLlib vs Third-party Libraries
This question matters more now than many interview loops admit. Spark isn't just an ETL engine in modern AI stacks. It's often the bridge between raw data, feature pipelines, and model workflows.
A good answer starts with scope. MLlib works well for classical distributed machine learning and Spark-native feature pipelines. If the workload is deep learning, custom training loops, or model serving, teams usually combine Spark with tools outside MLlib.
What strong candidates say now
They should mention using Spark for large-scale feature engineering and batch inference, then handing off to libraries like PyTorch or scikit-learn when the modeling need goes beyond MLlib's strengths. The strongest candidates also understand that the production question isn't "Which library is best?" It's "Where should distributed data processing stop and specialized training begin?"
There's also a timely angle many interview kits still miss. A recent practitioner write-up notes that Spark interview content rarely covers integration with MLOps tools like MLflow and Kubeflow or Spark's role in LLM pipelines, even though those scenarios are increasingly relevant for senior AI roles. That same article says Spark 4.0, released in May 2025, introduced native Python 3.12 support and enhanced Pandas UDFs for vectorized ML workloads, according to this Spark scenario-based interview article.
That doesn't mean every Spark hire needs LLM experience. It does mean senior candidates should understand where Spark fits in end-to-end ML systems.
Practical hiring scenario
Ask this: "We have a large raw events pipeline, feature generation in Spark, and model training outside Spark. Where would you draw the system boundary?"
Good answers usually include:
- Spark for ingestion, cleaning, joins, and feature materialization.
- MLlib for simpler at-scale models when staying inside Spark is operationally cheaper.
- External training stacks for deep learning, advanced experimentation, or specialized serving.
The candidate you're hiring doesn't need to force everything into Spark. They need to know when not to.
Interviewer rubric
- Strong hire: Places Spark correctly within the ML stack and understands MLlib's practical limits.
- Borderline: Knows MLlib APIs but not the surrounding system design.
- Weak: Treats Spark as either the answer to everything or irrelevant to ML.
Business impact
This answer predicts architecture maturity. Engineers who misuse Spark for all ML workloads create slow experimentation and awkward serving paths. Engineers who ignore Spark's role in feature and batch inference pipelines create fragmented systems with poor handoffs.
8. Broadcast Variables, Accumulators, and Shared Variables
A candidate can recite definitions here and still make expensive mistakes in production. This question matters because shared variables sit right at the line between "Spark API familiarity" and "I know how distributed jobs behave under retries, serialization, and scheduler decisions."
The answer you want is simple and precise. Broadcast variables let executors reuse the same read-only reference data without shipping it with every task. Accumulators let tasks report counts or sums back to the driver, and they belong in observability, debugging, and coarse operational metrics.
The hiring signal comes from the trade-offs.
Strong candidates say broadcast helps when the reference data is small enough to distribute cheaply, reused across many tasks, and stable for the lifetime of the job. They also know the wrong broadcast can slow a job down. Large objects increase executor memory pressure, raise serialization cost, and can make task startup heavier than a regular join plan. In mature teams, engineers validate the physical plan instead of assuming broadcast is always faster.
They should also explain what Spark does not provide here. Shared mutable state across executors is not a normal Spark programming model. If someone talks about broadcast data as if workers can update it safely, they do not understand the execution model.
A practical interview prompt works well: you have an event-enrichment pipeline with a small country-code or product-category mapping used in every partition. Would you broadcast it or join it?
A strong answer says they would probably broadcast the mapping if it is static, reused heavily, and small enough to fit comfortably in executor memory. They should also mention the business cases where they would not. If the mapping changes often, needs lineage and audit controls, or behaves like a managed dimension table, a normal join is usually the safer design. That decision also intersects with big data security controls for shared storage and reference datasets, especially when teams distribute lookup data from object stores or maintain regulated enrichment tables.
Accumulators separate experienced Spark engineers from candidates who have only used toy examples. Good candidates know accumulator updates are tied to execution, not to a single clean pass through the code. Retries can replay updates. Speculative execution can distort counts. Lazy evaluation means nothing happens until an action runs. That is why accumulators work for telemetry, such as malformed-record counts, and fail badly as a source of truth for billing totals, fraud decisions, or workflow control.
Model answer
"Broadcast variables are for read-only reference data that many tasks need repeatedly. I use them for small, stable lookup datasets where broadcasting avoids repeated task-side shipping or an unnecessary shuffle-heavy join. I still check the query plan and memory impact, because a large broadcast can hurt executor performance.
Accumulators are for counters and metrics reported back to the driver. I use them for observability, such as tracking bad records, but not for business logic or final outputs because retries and re-execution can make the values unreliable."
Interviewer rubric
- Strong hire: Explains broadcast as a read-only optimization, names memory and serialization trade-offs, and clearly limits accumulators to metrics or diagnostics.
- Borderline: Knows the definitions but cannot explain failure modes, retries, or when a join is safer than a broadcast.
- Weak: Treats accumulators as reliable application state, or assumes broadcasting is always the fastest option.
Red flags
- Says broadcast variables can be updated across executors.
- Uses accumulators to drive branching logic or final result computation.
- Ignores retries, speculative execution, or lazy evaluation.
- Talks about broadcast joins without mentioning plan inspection or executor memory.
Business impact
This question predicts whether the engineer will create bugs your team can diagnose.
A bad hire may replace a manageable join with a broadcast object that bloats memory and destabilizes executors. They may also build monitoring or business logic on accumulator values that drift under retries. A strong hire uses shared variables sparingly, for the right reasons, and can explain the operational cost of getting that decision wrong.
9. Resilience, Fault Tolerance, and Checkpointing Strategies
Spark's fault tolerance story sounds elegant in interviews. In production, it's only elegant if the engineer knows where lineage recovery stops being practical.
A strong candidate should explain that Spark can recompute lost partitions through lineage, but long or expensive dependency chains can make that recovery painful. They should also distinguish caching from checkpointing. Cache is for reuse. Checkpointing is for cutting off expensive lineage and enabling more reliable recovery.
What to ask for in the answer
Ask them where they'd checkpoint and why. Good candidates usually say after expensive wide transformations, before especially costly downstream branches, or in streaming workloads where state must survive failures using durable storage.
They should also mention sink behavior. A job can recover internally and still duplicate external writes if the target system isn't idempotent. That's where resilience intersects with data governance and big data security controls, especially when checkpoint state and intermediate outputs live in shared object stores.
Mini case
Imagine a multi-stage ETL that ingests raw events, denormalizes them, computes user features, and writes outputs to a warehouse and a feature store. A mature answer says they may checkpoint after the most expensive shuffle stage, validate sink idempotency, and use durable storage for stream checkpoints if any stage is continuous.
The weak answer is "Spark is fault tolerant by default."
Fault tolerance isn't just about Spark rerunning tasks. It's about whether the whole data product stays correct after recovery.
Interviewer rubric
- Strong hire: Understands lineage, wide versus narrow transformations, checkpoint placement, and sink idempotency.
- Borderline: Knows lineage exists but can't design recovery boundaries.
- Weak: Thinks cache and checkpoint solve the same problem.
Red flags
- No distinction between recomputation cost and correctness risk.
- Local checkpointing for workloads that must survive cluster restart.
- No thought about downstream duplicate effects.
Business impact
A candidate who gets this wrong will build pipelines that technically restart but produce inconsistent business data. That's worse than a visible failure. It creates dashboards that look current and models that look fresh while the underlying outputs are wrong.
10. Spark Performance Profiling, Debugging, and Production Optimization
A pipeline passes staging, then falls over on the first month-end run. The cluster is larger, the config file is longer, and nobody can explain why one stage takes 40 minutes while the rest finish in seconds. That is the interview scenario that separates someone who has used Spark from someone you can trust with production ownership.
Good answers start with method, not folklore. The candidate should describe how they isolate where time and money are going, then connect symptoms to likely causes. Spark UI, event logs, physical plans, executor logs, storage metrics, and sink behavior all matter. The order matters too.
Spark gives engineers many ways to express the same job. In production, those choices show up as very different query plans, shuffle volumes, memory pressure, and recovery behavior. A hiring process should test whether the candidate can explain that trade-off clearly, score what they say against a rubric, and catch the red flags before they become on-call incidents.
Here's a useful video to pair with this interview area during team calibration:
What a strong answer sounds like
Ask the candidate how they would investigate a Spark job that regressed after a schema change or traffic spike. Strong candidates usually work through a sequence like this:
- Start with the Spark UI: Identify the slowest stages, failed tasks, skewed task durations, and shuffle-heavy boundaries.
- Check the execution plan: Confirm whether the engine chose the expected joins, filter pushdown, partition pruning, and code generation path.
- Correlate executor and cluster signals: GC pauses, spill to disk, container restarts, remote reads, and object store latency often explain symptoms the UI only hints at.
- Inspect code paths: Python UDFs, accidental collect calls, wide transformations, and unnecessary repartitions still cause a large share of avoidable regressions.
- Verify the sink side: A job can look slow in Spark when the actual bottleneck is a warehouse write path, transactional merge, or downstream API.
The weak answer jumps straight to executor memory and shuffle partition settings. That is how teams spend days tuning around the wrong bottleneck.
I also want candidates to say what they would measure before and after a change. Runtime alone is not enough. Production optimization means tracking cost per run, data freshness, failure rate, retry behavior, and whether a speedup makes the code harder to operate. That operating discipline overlaps with broader MLOps production practices for data and AI systems, especially when Spark jobs feed models, feature stores, and scheduled retraining pipelines.
Interviewer rubric
- Strong hire: Follows a clear profiling sequence, reads Spark UI and plans correctly, distinguishes compute bottlenecks from I/O bottlenecks, and explains the business trade-off behind each optimization.
- Borderline: Knows the main tools and common tuning knobs but struggles to prioritize the investigation or validate the result.
- Weak: Suggests generic config changes first, cannot read stage-level symptoms, or treats production debugging like local code debugging.
Red flags
- No mention of Spark UI, event logs, or explain plans.
- Confuses skew, spill, and GC as if they are the same problem.
- Assumes a larger cluster is the default fix.
- Optimizes for benchmark runtime without considering correctness, operability, or cloud cost.
- Cannot explain how they would prove that a change helped.
Business impact
This question predicts who will reduce incident time instead of extending it. A strong hire can turn a vague complaint such as "Spark is slow again" into a concrete diagnosis, a measured fix, and a safer production runbook. A weak hire burns budget with oversized clusters, masks real root causes, and leaves the team with jobs that only work under ideal conditions.
10-Point Spark Interview Comparison
| Item | 🔄 Implementation Complexity | ⚡ Resource Requirements | 📊 Expected Outcomes ⭐ | 💡 Ideal Use Cases | Key Advantages |
|---|---|---|---|---|---|
| Explain Spark Architecture and Distributed Computing Model | High, requires distributed systems and driver/executor knowledge | High, multi-node cluster, memory, network, cluster manager | Scalable, fault-tolerant large-data processing (⭐⭐⭐⭐) | Large-scale ETL, production ML pipelines, batch processing | Linear scalability, in-memory compute, cluster manager integration |
| RDDs vs DataFrames vs Datasets - When to Use Each | Moderate, API knowledge and conversion trade-offs | Varies, DataFrames more memory-efficient; RDDs heavier | Better performance & maintainability when chosen correctly (⭐⭐⭐) | DataFrames for most production; RDDs for unstructured; Datasets for Scala/Java type-safety | Catalyst optimization (DataFrames), flexibility (RDDs), type-safety (Datasets) |
| Spark SQL Optimization - Query Plans and Catalyst Optimizer | High, must read explain() plans and optimization rules | Medium, benefits from statistics and columnar formats (Parquet) | Significant query speedups and reduced I/O when tuned (⭐⭐⭐⭐) | ETL jobs, feature engineering, complex SQL queries | Automatic optimizations, predicate/column pruning, join reordering |
| Handling Data Skew and Partitioning Strategies | High, requires data analysis and custom strategies | Variable, salting/bucketing may increase shuffle/storage | More uniform task distribution and large speedups when fixed (⭐⭐⭐) | Joins on skewed keys, power-law distributions, large user/event joins | AQE, salting, bucketing, repartitioning to reduce skew |
| Spark Streaming vs Structured Streaming and Real-time Data Processing | Moderate, streaming semantics and state management | High, continuous resources, state stores, checkpoint storage | Near-real-time processing with fault tolerance (⭐⭐⭐) | Real-time features, fraud detection, monitoring, low-latency pipelines | Structured Streaming unifies batch/stream, watermarking, exactly-once |
| Spark Memory Management and Tuning | High, deep understanding of heap/off-heap and GC needed | High, careful executor/driver sizing, possible off-heap config | Improved stability and fewer OOMs; performance varies (⭐⭐⭐) | Large shuffles, ML training, heavy join/aggregation workloads | Unified memory, off-heap to reduce GC, spilling to prevent OOMs |
| Spark and Machine Learning - MLlib vs Third-party Libraries | Moderate, trade-offs between scalability and model features | Varies, MLlib scales on Spark; deep learning needs GPUs/external infra | Scalable traditional ML with MLlib; flexible advanced models with third-party (⭐⭐⭐) | Large-scale linear/tree models (MLlib); deep learning with PyTorch/TF | MLlib integrates with Spark & distributed tuning; external libs for advanced models |
| Broadcast Variables, Accumulators, and Shared Variables | Low–Moderate, simple APIs but requires serialization care | Low–Medium, broadcast memory limits (~2GB), accumulator overhead | Reduced network I/O and efficient aggregations (⭐⭐) | Large lookup tables, cluster-wide counters, metrics aggregation | Cuts network traffic, simple aggregation patterns, Spark UI visibility |
| Resilience, Fault Tolerance, and Checkpointing Strategies | Moderate, understanding lineage, checkpoints, speculation | Medium, reliable storage for checkpoints, extra I/O and storage | Reliable recovery from failures; extra storage/compute overhead (⭐⭐⭐) | Long-running jobs, streaming pipelines, critical ETL with SLAs | RDD lineage recovery, checkpointing, task retry and speculation |
| Spark Performance Profiling, Debugging, and Production Optimization | Moderate–High, interpreting metrics and profiling traces | Medium, event logs, monitoring stack (Prometheus, S3/HDFS) | Clear bottleneck identification and cost/perf improvements (⭐⭐⭐) | Slow ETL/ML jobs, production performance tuning, post-mortems | Spark UI & History Server, task/stage metrics, profiler integration |
Action Plan From Interview to Impact
Knowing the right spark interview questions is only half the job. The primary work is evaluating whether the answer reflects production judgment, not just familiarity with Spark terminology. If you want a stronger hiring loop, you need consistency in how interviewers score candidates and discipline in how you connect technical depth to business outcomes.
Start by changing what "good" looks like in the interview. A good answer isn't one that names every Spark subsystem. It's one that explains trade-offs, spots likely failure modes, and gives a reasonable production response. Candidates don't need to know every config from memory. They do need to show that they'd diagnose before tuning, optimize before scaling, and protect correctness before chasing speed.
Use these 10 questions as a structured panel, not a grab bag. Split them across architecture, data modeling, performance, streaming, and reliability. That lets you see whether the candidate is consistently strong or only polished in one comfort zone. The best Spark hires usually show the same pattern across multiple areas. They simplify where possible, they know where Spark hurts, and they talk about systems as things that have to stay running.
A practical way to score answers is to use four lenses in every round:
- Production realism: Did the candidate talk about incidents, skew, memory, retries, checkpointing, or observability?
- Decision quality: Did they explain when to choose one approach over another?
- Operational safety: Did they account for correctness, durability, and downstream impact?
- Communication: Could they explain a complex system in a way your team can work with?
That framework helps hiring managers avoid a common mistake. Many candidates sound senior because they've used Spark. Fewer are senior in the sense that matters. They can debug the ugly case, choose the simpler path, and protect business-critical pipelines without turning every issue into a cluster-size problem.
I'd also recommend running at least one scenario-based follow-up for every promising candidate. Ask them what they'd do if a nightly job suddenly doubled in runtime, if a stream started producing duplicates, or if a join began spilling after a schema change. Those prompts surface judgment much faster than another round of API definitions.
Two practical examples work especially well in final rounds. First, show a simplified Spark UI screenshot or describe one stage with clear stragglers and ask for a diagnosis path. Second, give a small architecture prompt: Kafka ingestion, Spark transformation, feature store output, and a model refresh dependency. Then ask what they'd monitor, checkpoint, and optimize first. These scenarios reveal whether the candidate thinks like an operator.
Hiring managers should also calibrate interviewers before running this loop. Make sure everyone agrees on what counts as a strong answer and what counts as a red flag. Without that, one interviewer rewards memorization while another rewards judgment, and your scorecards become noise.
Your next steps are straightforward.
- Download our Spark Interview Scorecard (PDF). Use a rubric-based template so every interviewer scores architecture, tuning, and reliability the same way.
- See vetted Spark experts. If your team needs help now, review sample profiles of senior Spark engineers who have shipped production pipelines and know how to operate them.
- Start a pilot project. If hiring risk is high, scope a short pilot with a senior engineer and evaluate how they handle design, debugging, and delivery in a real environment.
The point of this guide isn't to make interviews harder. It's to make them more honest. Spark is powerful, but it punishes shallow understanding fast. The right hire will help you ship reliable data products, keep ML systems fresh, and reduce the drag that bad pipelines put on the rest of the business.
If you're building AI, data, or MLOps capacity and need senior operators instead of resume-driven generalists, ThirstySprout can help you hire vetted Spark, ML, and platform engineers fast. Start a pilot or see sample profiles to find people who've already run production systems under real constraints.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.