
TL;DR: Vetting a Top Data Engineer
- Go Beyond Theory: Don't just ask "What is HDFS?" Instead, ask "How does HDFS achieve fault tolerance, and what are the operational risks?" Assess their understanding of trade-offs, not just definitions.
- Focus on Optimization: A key differentiator is optimization skill. Ask, "Walk me through how you'd debug a slow Spark job." Look for a systematic approach: Spark UI analysis, identifying skew/shuffle, applying targeted fixes like partitioning or broadcasting, and measuring impact.
- Test Architectural Judgement: Use scenario-based questions. "When would you choose Hadoop MapReduce over Spark in 2025?" The answer reveals their grasp of cost, latency, and workload fit, which is crucial for business impact.
- Insist on Practical Examples: The best candidates connect concepts to reality. For partitions, they should mention aiming for ~128MB per partition. For Catalyst, they should name
Predicate PushdownorBroadcast Hash Joinas specific optimizations. - Recommended Action: Use the questions below to build a tiered interview kit. For senior roles, combine them into a live-coding task where candidates must optimize a deliberately inefficient Spark job.
Who This Article Is For
- CTOs, VPs of Engineering, and Staff Engineers: You need to hire a data or ML engineer who can architect and maintain scalable, cost-effective data pipelines, not just run basic scripts. You must be able to tell the difference in an interview.
- Hiring Managers and Tech Leads: You are responsible for designing the technical interview loop for data roles and need a reliable set of questions to separate great candidates from good ones.
- Founders and Product Leads: You are scoping a new data-intensive feature and need to understand the core competencies required to build and operate it, ensuring you hire the right talent for the job.
This guide provides a framework to move beyond rote memorization and assess a candidate's practical ability to build, debug, and optimize real-world data systems using Hadoop and Spark.
While this list focuses on technical evaluation, a strong interview process is equally critical. For broader insights, this guide on remote job interview questions from RemoteWeek covers essential techniques for assessing candidates in any distributed environment.
1. Explain HDFS Architecture and How NameNode and DataNode Work Together
This question is a cornerstone of any Hadoop and Spark interview. A strong answer shows you understand how distributed storage provides fault tolerance and scalability, which is critical for any large-scale data role. It separates candidates who know the what from those who know the how and why.
Hadoop Distributed File System (HDFS) uses a primary-secondary architecture.
- The NameNode is the primary. It manages the file system's metadata: the directory tree, file permissions, and the mapping of files to data blocks. It does not store the actual data.
- The DataNodes are the secondaries. They store the data blocks on their local disks and handle read/write requests from clients, as directed by the NameNode.
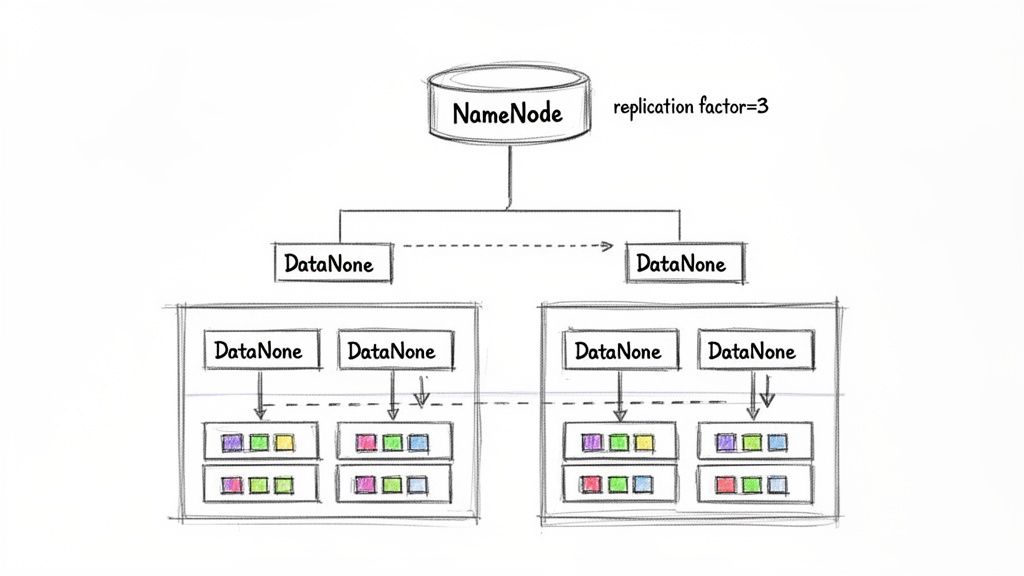
alt text: Diagram showing Hadoop Distributed File System (HDFS) architecture with NameNode, DataNodes, and data replication.
How They Work Together: An Example
- Write Operation: A client wanting to write a log file first contacts the NameNode. The NameNode checks permissions and returns a list of DataNodes for the file's blocks (e.g., DataNode 1, 3, and 5 for the first block). The client then writes data directly to those DataNodes.
- Read Operation: To read the log file, the client asks the NameNode for the block locations. The NameNode provides the addresses of the DataNodes holding those blocks. The client reads the data in parallel directly from the DataNodes.
- Fault Tolerance: DataNodes constantly send "heartbeats" to the NameNode. If a DataNode fails and misses its heartbeats, the NameNode identifies which blocks are now under-replicated and instructs other DataNodes to create new replicas, ensuring data durability.
Practical Application: A Production Checklist
- Implement NameNode High Availability (HA): A single NameNode is a single point of failure. Use an Active/Standby NameNode configuration with Apache ZooKeeper for automatic failover. This is non-negotiable for production systems.
- Tune the Replication Factor: The default is 3. For critical data like financial transactions, you might increase it to 4. For temporary staging data, reducing it to 2 can save significant storage costs.
- Configure Rack Awareness: In a multi-rack deployment, this ensures HDFS places block replicas across different physical racks. This protects against a rack-level failure (e.g., power or network switch) taking out all copies of your data.
2. What is MapReduce and How Does the Shuffle and Sort Phase Work?
This question tests a candidate's understanding of the original distributed batch processing model. Since the shuffle phase is a common performance bottleneck, explaining it correctly shows practical knowledge for pipeline optimization.
MapReduce is a programming model for processing large datasets in parallel across a cluster. It has two main functions:
- Map function: Processes key-value pairs to generate intermediate key-value pairs.
- Reduce function: Aggregates all intermediate values associated with the same intermediate key.
The most critical—and expensive—part is the Shuffle and Sort phase, which moves data from mappers to reducers. This phase is almost entirely network and disk I/O.
How It Works: An Example
Imagine a word count job.
- Map Output: A map task processes a block of text and outputs pairs like
(the, 1),(spark, 1). This output is written to a local buffer. When full, it's partitioned by key (e.g., using a hash function) and spilled to the local disk. - Shuffle: The reduce tasks then pull their assigned partitions from each mapper node over the network. Reducer #1 might be responsible for all keys starting with A-M, so it pulls those partitions from every mapper.
- Sort (Merge): As a reducer receives these sorted map outputs, it merges them to maintain the sort order. This guarantees that all values for a single key (e.g., all the
1s for the keyspark) arrive together to be processed by the reduce function.
Practical Application: A Performance Tuning Checklist
- Use a Combiner: For associative operations like sums or counts, a Combiner acts as a mini-reducer on the map side. It pre-aggregates data before the shuffle, drastically reducing network traffic and improving job performance.
- Tune Reducer Count: The number of reducers determines parallelism. Too few creates a bottleneck; too many creates excessive small files and scheduling overhead. A good rule of thumb is to aim for each reducer to process around 1 GB of data.
- Enable Intermediate Data Compression: Compressing map outputs with a fast codec like Snappy or LZ4 reduces the data transferred during the shuffle. This trades CPU cycles for a significant drop in network and disk I/O, often speeding up jobs.
3. Explain RDD, DataFrame, and Dataset in Spark—When to Use Each
This question tests a candidate's knowledge of Spark’s core data abstractions. Articulating the differences reveals their understanding of Spark's evolution, performance optimization, and ability to choose the right tool for the job.
- Resilient Distributed Dataset (RDD): The original low-level API. It offers flexibility and control but lacks the schema information and performance optimizations of newer APIs. It treats data as a collection of Java/Python objects.
- DataFrame: Introduced in Spark 1.3. A distributed collection of data organized into named columns, like a table in a database. It enables massive performance gains via the Catalyst optimizer and Spark SQL.
- Dataset: Added in Spark 1.6. It combines the type-safety of RDDs (you work with domain objects like
case class User) with the performance optimizations of DataFrames. It is primarily used in Scala and Java.
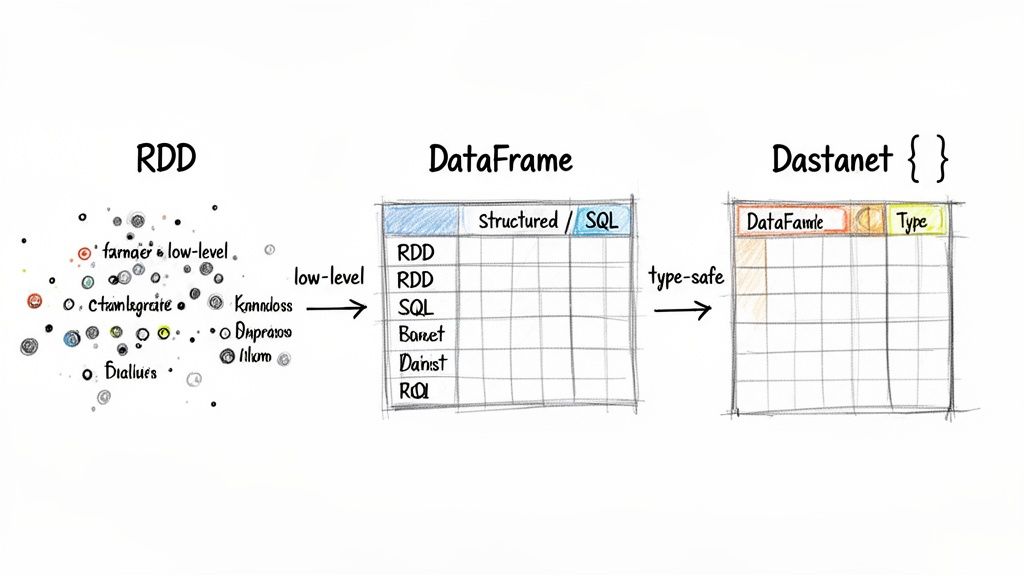
alt text: Flowchart illustrating the progression from low-level RDDs to DataFrames and type-safe Dastanet for data processing.
When to Use Each: A Decision Framework
- Example: Parsing a proprietary binary format where you need to manipulate individual byte arrays.
- Example: Analyzing e-commerce transactions with SQL queries for fast, aggregated reporting.
- Example: A complex ML feature engineering pipeline where a
NullPointerExceptioncould corrupt a multi-hour job. The Dataset API catches these errors at compile time. - Analysis: Catalyst first resolves table and column names against its catalog, creating a logical plan.
- Logical Optimization: It applies rules to the plan. A key rule is Predicate Pushdown. It moves the
filter("state = 'CA'")operation as close to the data source as possible. If thecustomerstable is stored in Parquet, Spark will read only the data for California customers, drastically reducing I/O. - Physical Planning: Catalyst generates several physical plans and uses a cost model to choose the best one. For the join, it might choose a Broadcast Hash Join if the
customerstable is small enough to fit in memory, avoiding a costly and slow shuffle of the largeorderstable. - Code Generation: Finally, Catalyst uses whole-stage code generation to collapse the entire query into a single, optimized Java bytecode function. This minimizes virtual function calls and improves CPU and memory efficiency.
- Analyze the Physical Plan: Before deploying a job, run
df.explain(true)to inspect the optimized plan. Check if predicate pushdown and the correct join strategy are being used. - Guide the Optimizer: If you know a table is small, provide a hint:
df_large.join(broadcast(df_small), "join_key"). This forces a broadcast join, which Catalyst might otherwise not choose. - Filter Early, Select Late: Structure your code to apply filters (
where,filter) as early as possible andselectstatements as late as possible. This gives Catalyst the best chance to prune data. - Logical Plan (DAG) Creation: When you call an action, Spark's driver inspects the chain of transformations (e.g.,
map,filter,join) that created the final DataFrame. This chain forms the DAG. - DAGScheduler Splits DAG into Stages: The DAGScheduler takes this logical graph and splits it into stages. A new stage is created at every "wide" transformation boundary (e.g.,
groupByKey,reduceByKey,join), which requires shuffling data across the cluster network. - TaskScheduler Launches Tasks: The DAGScheduler submits these stages to the TaskScheduler. The TaskScheduler launches the individual tasks on the cluster's executor nodes. It is also responsible for retrying failed tasks.
- Visualize the DAG in the Spark UI: This is the single best tool for finding bottlenecks. An unexpectedly high number of stages points to too many shuffles. A single, long-running stage might indicate data skew.
- Minimize Shuffles: Each shuffle introduces expensive network and disk I/O. For example, use
reduceByKeyinstead ofgroupByKeyfollowed by a map.reduceByKeyperforms a partial aggregation on the map side, reducing the data sent over the network. - Cache Intermediate DataFrames: If your DAG re-uses a DataFrame multiple times (common in iterative ML algorithms), use
.cache()or.persist(). This tells Spark to keep it in memory, avoiding re-computation from scratch in subsequent stages. - Hash Partitioning (Default): Spark applies a hash function to a key to assign it to a partition (
partition = key.hashCode() % numPartitions). It works well for evenly distributed keys but causes severe skew if one key dominates. - Range Partitioning: This sorts data by key and divides it into roughly equal ranges, assigning each range to a partition. It is highly effective for time-series data or ordered keys, as it allows Spark to skip reading partitions that fall outside a query's date range.
- Custom Partitioning: For complex business logic, you can define your own partitioning scheme. For example, ensuring data for a specific country is always processed in a particular data center for GDPR compliance.
- Partition Before Joins: When joining two large DataFrames, always
repartitionboth on the join key before the join. This co-locates the data, allowing the join to happen without a massive shuffle. - Optimize Partition Size: Aim for partitions to be around 128 MB. Too many small partitions create scheduling overhead; too few large partitions reduce parallelism and can cause OutOfMemory errors. Use
repartition()orcoalesce()to adjust the partition count. - Use Salting for Skewed Keys: If a few keys cause skew (e.g., a "guest_user" ID), add a random prefix ("salt") to the key before partitioning. This spreads the data for that single key across multiple partitions, balancing the workload. You then join on both the original key and the salt.
- RDD Lineage: When you apply transformations like
map()orfilter(), Spark builds a Directed Acyclic Graph (DAG) of these operations. This DAG is the RDD's lineage. - Lazy Evaluation & Re-computation: The job only runs when an action (like
count()) is called. If a worker fails, the driver consults the DAG and re-schedules the computation for the lost partition on another available worker. - Checkpointing: For very long lineage graphs, re-computation is slow. You can use
checkpoint()to save a DataFrame to a reliable file system (like HDFS or S3). This truncates the lineage graph. If a failure happens after a checkpoint, Spark recovers from the saved data instead of re-computing from the original source. - Checkpoint Strategically: Use
checkpoint()after computationally expensive transformations, like large joins or complex aggregations. In a 20-stage ETL pipeline, checkpointing every 5-7 stages can dramatically reduce recovery time after a failure. - Enable Speculative Execution: Set
spark.speculation=truefor jobs running on clusters with uneven hardware. Spark will launch redundant copies of slow-running tasks ("stragglers") and take the result of the first one to finish, preventing one slow node from delaying the entire job. - Monitor Task Failures: A task failure rate above 5% in the Spark UI often points to systemic issues like out-of-memory errors, bad data, or network problems that require investigation.
- A broadcast variable is a read-only variable cached on each machine rather than being shipped with each task. It's used to efficiently distribute a large object (e.g., a lookup table) for tasks to use.
- An accumulator is a write-only variable that tasks can "add" to. It's used for aggregating results back to the driver, like implementing counters or sums.
- Example: In a sales analytics job, broadcast a
product_metadatatable to enrich a multi-billion-rowtransactionstable. - Example: Create an accumulator to count the number of log entries that fail a parsing step. This provides visibility without disrupting the main data flow.
- Hadoop MapReduce is a disk-based, batch-processing engine. It writes intermediate results to HDFS after each stage. This makes it highly resilient and cost-effective for petabyte-scale datasets but results in high latency.
- Apache Spark is an in-memory processing engine. It builds a DAG of transformations that it can execute without writing intermediate data to disk. This makes Spark up to 100x faster for iterative algorithms (like machine learning) and interactive analytics.
- Example: A financial institution running an end-of-year regulatory report on a decade's worth of immutable transaction logs.
- Example: An e-commerce platform using Spark to train recommendation models, which requires repeatedly passing over the same dataset. The in-memory caching provides a massive performance boost.
- Go to the Stages tab to find the longest-running stage.
- Look for signs of high Shuffle Read/Write, which indicates a bottleneck.
- Check for task-level skew: are a few tasks taking much longer or processing much more data than others?
- Hypothesis 1 (Shuffle): A large
joinorgroupByoperation is causing a massive data shuffle. - Hypothesis 2 (Skew): A few keys (e.g.,
user_id = 'NULL') are dominating a partition, creating straggler tasks. - Hypothesis 3 (I/O Bound): The job is spending most of its time reading data, not computing. Maybe predicate pushdown isn't working.
- For Shuffle: If joining a large table with a small one, use a
broadcast()hint. If aggregating, ensure you are not usinggroupByKey. - For Skew: Apply "salting" to the skewed keys to distribute the data more evenly.
- For I/O: Check your data format (Parquet/ORC is best) and ensure filters are applied early in your code.
- Measure and Iterate: Rerun the job and compare the Spark UI metrics. Did the stage duration decrease? Did shuffle data size go down? If the problem persists, return to the UI to gather more evidence and refine your hypothesis.
Build a Tiered Question Bank:
- Junior Roles: Focus on core concepts. Can they explain the purpose of the shuffle phase? Can they describe the difference between HDFS and local storage?
- Mid-Level Roles: Test practical application. Ask them to walk through optimizing a slow Spark job, focusing on their use of the Spark UI.
- Senior/Staff Roles: Probe architectural thinking. Present a business problem (e.g., "design a near-real-time user analytics dashboard") and have them defend their choice of tools and architecture (e.g., Spark Streaming vs. Flink, partitioning strategy).
Design a Practical Take-Home Task:
- Task Example: Provide a 5-10 GB sample of skewed log data and an inefficient Spark script. Ask the candidate to identify the bottleneck, fix the code, and write a brief explanation of their changes.
- Evaluation Rubric: Assess their code correctness, performance improvement (did execution time decrease?), and the clarity of their explanation. Did they correctly identify the need for salting or a broadcast join?
Widen Your Talent Search: Exceptional data engineers are in high demand. To find candidates with niche expertise in distributed systems, look beyond traditional job boards and explore where to find top remote jobs talent globally.
4. How Does Spark Optimize Query Execution with Catalyst Optimizer?
This question separates candidates who use Spark from those who understand it. Knowing Catalyst shows they can write efficient code and diagnose performance bottlenecks, a critical skill for any senior data role.
The Catalyst optimizer is Spark SQL's query optimization engine. It transforms DataFrame/Dataset operations into a highly efficient physical execution plan through four main phases: Analysis, Logical Optimization, Physical Planning, and Code Generation.
How It Works: A Practical Example
Imagine you run this code: orders.join(customers, "id").filter("state = 'CA'")
Practical Application: A Debugging Checklist
5. What is DAG and How Does Spark's DAG Scheduler Work?
This question assesses a candidate's grasp of Spark's execution model. Understanding the DAG is key to optimizing job performance and comprehending Spark's fault tolerance mechanism.
A Directed Acyclic Graph (DAG) is Spark's logical execution plan. Spark builds this graph from your code's transformations on RDDs or DataFrames. It's "directed" because data flows one way, and "acyclic" because it has no loops, ensuring a finite execution. An action (like count() or save()) triggers the execution of this graph.
alt text: DAGScheduler diagram illustrates data transformations, shuffle boundary, join, and groupBy operations in a distributed processing pipeline.
How It Works: From Code to Execution
Practical Application: A Performance Checklist
6. Explain Spark Partitioning Strategies and Their Impact on Performance
This question separates candidates who can run Spark jobs from those who can optimize them. The answer shows whether they understand how to control parallelism to minimize data shuffling and improve job performance—a core competency for any senior data engineer.
A partition is a logical chunk of a dataset that can be processed in parallel on an executor. The way data is distributed into partitions directly impacts performance. Poor partitioning causes data skew (some tasks get much more work than others) and excessive shuffling during joins and aggregations.
alt text: Diagram showing Spark partitioning strategies, with data flowing from a source into different partitions based on hash, range, and custom logic.
Partitioning Strategies and When to Use Them
Practical Application: A Partitioning Checklist
7. How Does Spark Handle Fault Tolerance and Recovery?
This question tests a candidate's grasp of distributed system reliability. A strong answer shows they can architect jobs that survive node failures and avoid costly re-computations, which is non-negotiable for production pipelines.
Spark's fault tolerance is based on its core abstraction, the Resilient Distributed Dataset (RDD). Spark tracks the lineage (the series of transformations) used to create each RDD. If a partition of an RDD is lost because a worker node fails, Spark can replay the transformations from its lineage on the base data to recompute just that lost partition.
How It Works in Practice
Practical Application: A Resiliency Checklist
8. What is a Broadcast Variable and an Accumulator? When to Use Each?
This question probes understanding of performance optimization beyond basic transformations. The answer reveals whether a candidate can optimize for network I/O and memory usage, a key differentiator for senior engineers.
In Spark, shared variables allow tasks running on different executors to use common data.
alt text: Diagram showing Spark broadcast variable and accumulator. The driver sends a broadcast variable to all executors. Executors perform work and send accumulator updates back to the driver.
When to Use Each: A Decision Framework
9. Compare Hadoop and Spark: When to Use Each Framework?
This is a classic architectural question that evaluates a candidate's ability to make sound technology choices that impact cost, performance, and team capabilities. A strong answer goes beyond "Spark is faster" and discusses the specific trade-offs.
The core difference is their processing model.
alt text: Diagram comparing Hadoop MapReduce's disk-based processing with Spark's in-memory processing.
Decision Framework: Hadoop vs. Spark
10. How Would You Optimize a Slow Spark Job? Walkthrough Your Approach
This is a critical, practical question for any mid-level or senior role. The answer reveals a candidate's debugging methodology, familiarity with the Spark UI, and intuition for spotting performance bottlenecks.
Optimizing a slow Spark job is a systematic investigation, not guesswork. The goal is to gather evidence, form a hypothesis, apply a targeted fix, and measure the result.
A Step-by-Step Optimization Framework
What To Do Next
You now have a robust set of Hadoop Spark interview questions designed to identify top-tier data engineers. The key is to move beyond definitions and test a candidate's ability to apply these concepts to solve real business problems related to cost, speed, and reliability.
A 3-Step Framework for Vetting Data Engineers
By implementing this structured approach, you create a system that reliably identifies engineers who can build and maintain scalable, high-performance data platforms.
Ready to hire an expert who can ace these questions and build your next data platform? ThirstySprout specializes in vetting and matching elite, remote data and AI engineers from our exclusive network. We handle the sourcing and technical screening so you can start a pilot in weeks, not months.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.