
Your team probably didn't pick the wrong language. You hit the wrong operating model.
A lot of engineering leaders reach this point the same way. A few Python scripts started as a fast win. Then those scripts became nightly jobs, then customer-facing dashboards, then features feeding machine learning models. Suddenly Pandas jobs run out of memory, retries become routine, and one senior engineer is the only person who understands the pipeline well enough to fix it.
That's where spark and python becomes a leadership decision, not just a tooling choice. The key question isn't whether Spark is powerful. It is. The question is whether your data volume, latency requirements, and team maturity justify the cost of introducing a distributed system.
Why Your Python Scripts Are Breaking and What to Do Next
If you're a CTO, Head of Engineering, or Staff Engineer at a Series A to D company, you usually don't need Spark at the first sign of pain. You need a clean decision framework.
TL;DR
- Stay with native Python if your datasets fit comfortably in memory, your jobs are easy to rerun, and your team moves fastest with Pandas.
- Move to PySpark when failures come from scale, not code quality. That usually shows up as memory pressure, long aggregations, unreliable batch windows, or shared pipelines used across analytics and machine learning.
- Don't adopt Spark just to look “enterprise.” If your team lacks distributed systems experience, Spark can slow delivery before it helps.
- Treat PySpark as a platform choice when ETL, feature engineering, and large-scale analysis need the same execution engine.
- Run a pilot first. Pick one painful workflow, instrument it, and compare build effort, runtime stability, and operational burden.
A practical decision matrix
| Situation | Native Python | Dask | PySpark |
|---|---|---|---|
| Data fits on one machine | Best fit | Possible, often unnecessary | Usually overkill |
| Fast notebook exploration | Best fit | Good if you already use Dask | Good, but slower to set up |
| Team already strong in Pandas | Best fit | Easier transition | Requires more platform discipline |
| Repeated failures from memory or long-running joins | Weak fit | Sometimes enough | Strong fit |
| Shared ETL and ML pipeline needs | Limited | Mixed | Strong fit |
| Need governed, production-grade distributed processing | Weak fit | Depends on setup | Strong fit |
What usually breaks first
The first issue is rarely syntax. It's operating constraints.
A single-node Python workflow breaks when one of these happens:
- Memory stops being predictable. Jobs work in development samples and fail in production.
- Nightly jobs miss downstream deadlines. The business feels this before engineering documents it.
- The pipeline grows beyond one owner. Local conventions stop scaling when multiple teams touch the same code.
- Machine learning depends on the same raw data. Now ETL quality becomes model quality.
Practical rule: If your main problem is messy code, Spark won't save you. If your main problem is that one machine can't reliably process the workload, Spark deserves a serious look.
The quickest leadership call
Ask three questions.
- Is the bottleneck volume, concurrency, or both?
- Do you need one system for analytics engineering and ML data prep?
- Can your team operate a distributed platform without turning every job into a debugging exercise?
If the answers are yes, yes, and mostly yes, PySpark is probably justified. If the third answer is no, the technology may be right but the timing is wrong.
How Spark and Python Work Together Under the Hood
Spark and Python work well together because each handles a different part of the problem. Python gives your team a familiar language and library ecosystem. Spark gives that Python code a distributed execution engine.

Think manager and crew, not one giant script
The easiest mental model is a construction site.
The driver acts like the site manager. It plans the work, tracks dependencies, and decides what needs to run. The executors are the crew spread across machines. They do the heavy lifting on partitions of data.
Your Python code usually describes the job, not every low-level step of execution. Spark turns that intent into a plan and distributes the work.
Why that matters to a CTO
This model changes three things that matter at the leadership level:
- Scale. Work is split across machines instead of stressing one box.
- Fault tolerance. If part of the job fails, Spark can often recompute only what's needed.
- Operational consistency. The same engine can support ETL, analytics, and parts of ML preparation.
That's why Spark often survives as companies mature. It's not just faster in the right workloads. It also creates a more stable backbone for data processing.
The hidden trade-off
Spark uses lazy evaluation. That means transformations are planned first and executed only when an action requires results. This is powerful because Spark can optimize the plan before running it.
It also confuses teams new to distributed systems. A job that looks simple in code can trigger expensive shuffles, large scans, or poor partitioning decisions at runtime. Leadership should expect a ramp-up period while engineers learn to reason about execution, not just syntax.
Teams that succeed with PySpark usually standardize on DataFrame operations early and limit custom Python logic to places where it clearly adds value.
If your analysts and engineers already work across SQL and Python, it's worth seeing how Querio empowers data teams with a more unified workflow. The bigger point is that Spark adoption works better when your tooling reduces handoffs instead of creating more of them.
When to Choose PySpark vs Pandas or Dask
A CTO usually asks this question after a familiar failure pattern. The team started with Pandas because it was fast to ship, then added larger files, more joins, and stricter delivery windows. Now the scripts work only when the data volume cooperates, and every new use case raises the cost of keeping the same approach alive.

The right choice depends less on ideology and more on operating model. Ask three questions first: Does the data fit comfortably on one machine? Does the team need a shared production pipeline instead of analyst-owned scripts? Do you already have the engineering discipline to run scheduled, tested, observable data jobs?
Choose Pandas for speed, local control, and early-stage uncertainty
Pandas is still the best tool for many teams because time-to-market matters more than distributed scale in the first phase.
Use Pandas when:
- The data fits in memory with margin
- An analyst or data scientist needs quick exploration
- The workflow is still changing every week
- The business case is not stable enough to justify cluster overhead
- You want the fastest path from question to answer
This is often the correct startup decision. If your product team is still refining metrics, retention views, or onboarding best practices for product teams, a local Python workflow keeps iteration tight. For smaller pipelines, a straightforward guide to building ETL workflows with Python is often more useful than introducing Spark too early.
Pandas becomes expensive when engineers start designing around its limits. That usually shows up as chunking logic, fragile multiprocessing, oversized instances, and jobs that only one person knows how to restart.
Choose Dask when the team wants more scale without a platform reset
Dask fits a narrower decision window. It works well for teams that already write idiomatic Python, need more parallelism than a single machine can offer, and do not yet need the operational model of Spark.
That makes Dask a reasonable choice when:
- The team is strong in Python but light on Spark experience
- Workloads are mostly Python-native data science tasks
- You need parallel compute soon, but not a full data platform
- The organization is not ready to invest in Spark operations and tuning
The trade-off is long-term standardization. Dask can extend familiar code. It does not automatically solve the leadership problem of creating one durable execution layer for batch processing, feature pipelines, and shared data engineering workflows. If that is the target architecture, Dask often becomes a transition tool rather than an endpoint.
Choose PySpark when scale, reliability, and team coordination are recurring needs
PySpark makes sense when data volume is only part of the problem. The larger issue is that multiple teams now depend on the same pipelines, the same joins, and the same delivery windows.
Microsoft's Fabric guidance on Python visualizations with Spark shows the practical advantage. Spark DataFrames can read large Parquet datasets with schema handling built in and support analysis from Python tools on top of distributed processing (Microsoft Fabric tutorial and summary).
Commit to PySpark when you need:
- Repeated large joins, aggregations, or window functions
- A shared processing layer across analytics engineering and ML
- Production jobs with retries, scheduling, lineage, and observability
- A system that can absorb growth without repeated rewrites
- A team that can debug distributed execution, not just Python syntax
This is also where leadership often underestimates the people side. PySpark succeeds when the team can work in SQL, Python, and data platform operations at the same time. If your engineers are excellent notebook users but have limited experience with partitioning, storage formats, job orchestration, and CI/CD for data pipelines, Spark adoption will be slower and more expensive than the initial architecture slide suggests.
A practical scorecard for leadership
| Decision factor | Pandas | Dask | PySpark |
|---|---|---|---|
| Fastest path to first result | Strongest | Good | Weakest |
| Lowest setup and infrastructure cost | Strongest | Good | Weakest |
| Best for analyst-led experimentation | Strongest | Good | Mixed |
| Best for growing Python workloads without major retraining | Mixed | Strongest | Good |
| Best for shared production data pipelines | Weakest | Mixed | Strongest |
| Best fit for mature MLOps and governed data operations | Weakest | Mixed | Strongest |
A simple rule helps. Choose Pandas if the business is still searching for repeatable data products. Choose Dask if you need more headroom but want to stay close to existing Python habits. Choose PySpark if the company already knows these pipelines will become operational infrastructure and is prepared to staff accordingly.
Example 1 Building a Scalable SaaS ETL Pipeline
A common PySpark adoption story starts with product analytics.
A SaaS company collects clickstream events, feature usage logs, and account activity records. At first, a Python job reads raw files, cleans them, and pushes daily summaries into the warehouse. Then the event volume grows, more teams depend on the metrics, and the nightly job becomes fragile.
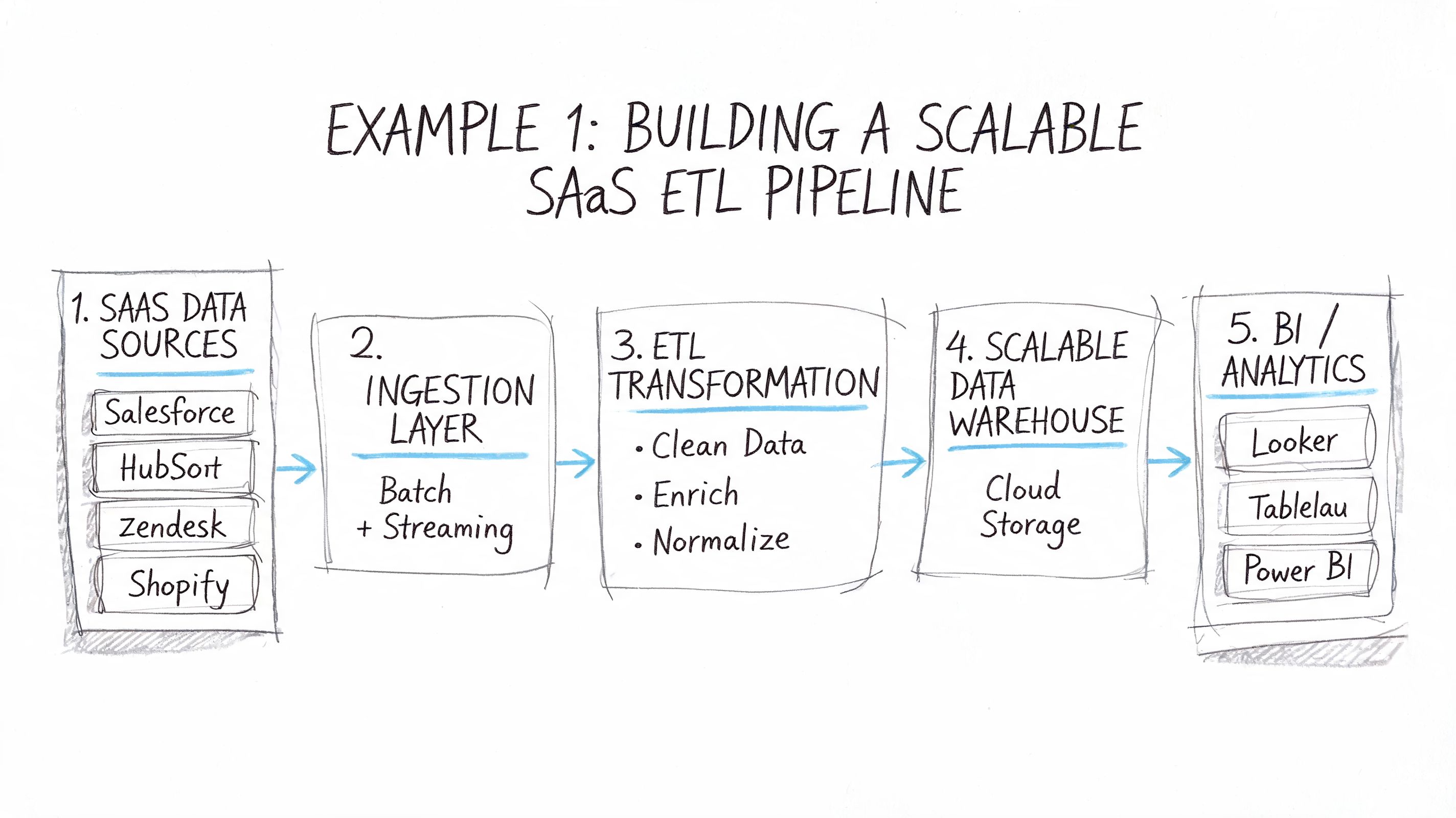
The business problem
The pipeline isn't failing because Python is bad. It's failing because the workflow now needs distributed I/O, repeatable schema handling, and stable timestamp processing.
That last point matters more than teams expect. An Areto Databricks MLOps walkthrough notes that defining a precise schema with StructType can avoid schema inference overhead that increases runtime by 2 to 5 times, and that converting timestamps with from_unixtime enables temporal feature engineering in scalable ETL.
A representative PySpark pattern
from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType, StructField, StringType, LongTypefrom pyspark.sql import functions as Fspark = SparkSession.builder.appName("saas-etl").getOrCreate()schema = StructType([StructField("user_id", StringType(), True),StructField("account_id", StringType(), True),StructField("event_name", StringType(), True),StructField("timestamp", LongType(), True)])events = (spark.read.schema(schema).json("s3://company-raw/events/"))clean = (events.withColumn("event_time", F.to_timestamp(F.from_unixtime("timestamp"))).withColumn("event_date", F.to_date("event_time")).filter(F.col("user_id").isNotNull()))daily_usage = (clean.groupBy("account_id", "event_date").agg(F.count("*").alias("event_count"),F.countDistinct("user_id").alias("active_users")))daily_usage.write.mode("overwrite").parquet("s3://company-curated/daily_usage/")This isn't fancy. That's the point.
What works and what doesn't
What works:
- Explicit schemas
- Simple DataFrame transformations
- Aggregation close to raw storage
- A clear bronze to curated flow
What doesn't:
- Heavy Python UDF use too early
- Letting every team define event semantics differently
- Treating Spark as a place to dump ungoverned logic
A clean ETL design beats a clever one. Spark rewards disciplined transformations and punishes ad hoc pipelines.
If your product team is building activation dashboards from this same event stream, good onboarding design matters too. This piece on onboarding best practices for product teams is useful because the metrics you model in ETL often map directly to product adoption questions.
For teams still shaping their extraction and transformation layer, this guide on ETL with Python is a useful companion before you commit to a distributed stack.
Example 2 Distributed Feature Engineering for Production ML
The second place teams outgrow native Python is feature engineering.
A recommendation or churn model often starts in a notebook with sampled data. That's fine for experimentation. The problem shows up when the model has to train on the full behavior history and the same feature logic must run consistently for training and inference.
A realistic production pattern
Say you're building a subscription churn model. You want user-level features like:
- session frequency
- days since last activity
- support ticket counts
- product area usage patterns
- plan and region encodings
On a single machine, this becomes painful fast when historical data is large and joins multiply. Teams end up sampling too aggressively, precomputing features manually, or maintaining separate code paths for research and production.
PySpark is often the cleaner answer because it lets you compute those features where the data already lives, then standardize them for downstream model use.
from pyspark.sql import functions as Ffrom pyspark.ml.feature import StringIndexer, VectorAssemblerfrom pyspark.ml import Pipelineuser_features = (spark.table("silver.user_events").groupBy("user_id").agg(F.count("*").alias("event_count"),F.max("event_time").alias("last_event_time"),F.countDistinct("product_area").alias("product_area_count")).withColumn("days_since_last_event", F.datediff(F.current_date(), F.to_date("last_event_time"))))users = spark.table("silver.users")training_base = user_features.join(users, on="user_id", how="inner")indexer = StringIndexer(inputCol="plan_tier", outputCol="plan_tier_index")assembler = VectorAssembler(inputCols=["event_count", "product_area_count", "days_since_last_event", "plan_tier_index"],outputCol="features")pipeline = Pipeline(stages=[indexer, assembler])feature_model = pipeline.fit(training_base)features_df = feature_model.transform(training_base).select("user_id", "features")Where Spark earns its keep
The leadership takeaway is simple. Spark is excellent for feature computation and data preparation, but it isn't automatically the best runtime for online inference. Strong teams separate those concerns.
The trade-off most teams miss
Spark makes batch feature engineering scalable. It doesn't make feature definitions magically consistent.
You still need:
- Versioned feature logic
- A training-serving contract
- Ownership between data engineering, ML engineering, and platform
- A plan for drift checks and retraining
If your team is still formalizing that layer, this explainer on what feature engineering means in machine learning helps align product and engineering expectations before you scale the pipeline.
Spark is the right tool when feature generation is the bottleneck. It's the wrong tool if your real problem is weak ML process discipline.
The Spark and Python Team You Need to Hire
A common failure pattern looks like this. The company approves PySpark because nightly jobs are slipping, one strong Python engineer gets asked to “make it scale,” and three months later the team has a cluster bill, unstable pipelines, and no one who can explain why one join takes 6 minutes and another takes 90.
Technology choice becomes an operating model choice fast. Spark increases throughput, but it also raises the bar for data modeling, job debugging, orchestration, and production ownership. If leadership treats PySpark as just “Python on bigger machines,” hiring will lag behind the system you are building.

The roles that matter most
For many organizations, two hires determine whether Spark becomes a durable platform or an expensive workaround.
Data Engineer
Owns ingestion patterns, transformation design, partitioning, file formats, Spark SQL quality, and pipeline reliability. This person should be able to read an execution plan, spot unnecessary shuffles, and make storage decisions that reduce both runtime and cloud spend.
MLOps Engineer
Owns feature pipelines, training data contracts, artifact packaging, orchestration, model release process, and production integration. In a Spark plus Python stack, this role matters most when ML is part of the roadmap, because distributed data preparation without release discipline usually creates more rework than value.
The hiring market reinforces that pressure. As noted earlier, Python remains central to analytics and ML hiring, which means strong Spark plus Python candidates are expensive and selective. Plan for that before you commit to a platform that depends on them.
What leadership should screen for
Do not hire only for API familiarity. Hire for operational judgment.
| Skill area | Data Engineer | MLOps Engineer |
|---|---|---|
| Spark DataFrame API | Must have | Must have |
| Spark SQL and joins | Must have | Strong working knowledge |
| Partitioning and file layout | Must have | Useful |
| Orchestration and CI/CD | Useful | Must have |
| Feature pipelines | Useful | Must have |
| Model packaging and serving | Nice to have | Must have |
| Debugging slow Spark jobs | Must have | Must have |
That table is the minimum, not the target state.
If the team is early, one senior data engineer with real Spark production experience can cover a lot of ground. If the company expects shared feature pipelines, scheduled retraining, approval flows, and monitored deployments, add MLOps capability early. Waiting usually shifts the burden onto data engineers who can build pipelines but should not own model release and serving contracts by default.
Interview questions that expose real experience
Good candidates answer with trade-offs, failure modes, and decisions they made under pressure.
- Ask for a bottleneck story. “Tell me about a slow Spark job you fixed. What was the root cause, and what changed after the fix?”
- Probe tool selection. “When would you keep a workflow in Pandas instead of moving it to Spark?”
- Check execution thinking. “How do you identify a transformation that will trigger an expensive shuffle?”
- Test production maturity. “How do you keep feature logic aligned between training and inference?”
- Ask about cost control. “What did you do to reduce cluster waste without hurting delivery time?”
A weak candidate stays at the API level. A strong one talks about skew, partition counts, file sizes, schema drift, retry behavior, and the business consequence of getting those wrong.
For a more targeted screening process, this bank of Spark interview questions for production data roles helps separate résumé familiarity from operational competence.
If your local market is tight, expand the search deliberately. Teams that need Python strength plus data platform experience often review options like Hire LATAM developers to access engineers who can contribute faster without building a full team in one geography.
The team design mistake to avoid
Do not assume a group of good Python developers will naturally become a good Spark team.
PySpark succeeds when the team can handle distributed systems behavior, data contracts, observability, and release discipline. If those muscles are weak, start smaller. Keep heavy workflows in native Python where possible, hire one senior Spark practitioner first, and prove that the organization can support the platform before staffing around it.
That is the leadership test. Spark hiring is less about headcount and more about whether your team can operate a distributed data system without slowing the business down.
Your Action Plan for Adopting PySpark
A successful adoption usually fits into three moves.
Start with one painful workflow
Don't migrate everything. Pick the pipeline that already hurts. That could be a nightly ETL job, a large aggregation feeding dashboards, or feature generation for a model the business already trusts.
Document current runtime, failure points, retry patterns, and downstream impact. You don't need a perfect benchmark. You need a clear before-and-after decision record.
Run a short pilot with strict boundaries
Use PySpark on one workflow end to end. Keep the scope tight.
Pilot goals should include:
- Data correctness
- Operational stability
- Maintainability by more than one engineer
- Clear cost visibility
One caution matters here. A Damavis article on Arrow UDF optimization notes potential 2 to 5 times slowdowns on large datasets without explicit batch sizing. In practice, that means you shouldn't judge PySpark based on a pilot full of avoidable UDF mistakes.
Check team readiness before full rollout
Ask whether your team can support:
- Distributed job debugging
- Data modeling discipline
- Production orchestration and monitoring
- A clear split between ETL, feature engineering, and inference concerns
If those foundations are weak, fix them first. Spark amplifies good engineering habits. It also amplifies weak ones.
A sensible 90-day path is simple. Audit one bottleneck, pilot one PySpark workflow, then decide whether to standardize on Spark for the workloads where it's clearly better.
If you're weighing that decision now, ThirstySprout can help you start a pilot with vetted Spark, data engineering, and MLOps talent who've shipped production systems before. If you're still shaping the team, you can also see sample profiles and compare the skills you need before making a full-time hire.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.