
TL;DR: What is Feature Engineering?
- What it is: Feature engineering is the process of transforming raw data into measurable features that a machine learning (ML) model can understand and learn from. It's about creating clear, predictive signals.
- Why it matters: Better features lead to more accurate models, faster time-to-value, lower cloud costs, and reduced project risk. It often has more impact on model performance than the choice of algorithm.
- How it works: The process involves four key steps: exploring data for patterns, creating new features (e.g., "debt-to-income ratio"), selecting the most impactful ones, and validating their effect on model performance.
- Recommended Action: Don't rely on AutoML alone. Empower your team with domain experts to create business-specific features. Use a feature store to manage and reuse feature logic across your organization, ensuring consistency and saving time.
Who This Guide Is For
- CTO / Head of Engineering: You need to decide on ML project architecture, budget for AI initiatives, and hire the right talent.
- Founder / Product Lead: You're scoping new AI features and need to understand the work required to get from raw data to business value.
- Talent Ops / Procurement: You're evaluating the skills and processes of potential AI/ML engineers and vendors.
This guide is for operators who need to make smart, practical decisions about AI projects in the next few weeks, not the next few months.
What Is Feature Engineering in Machine Learning?
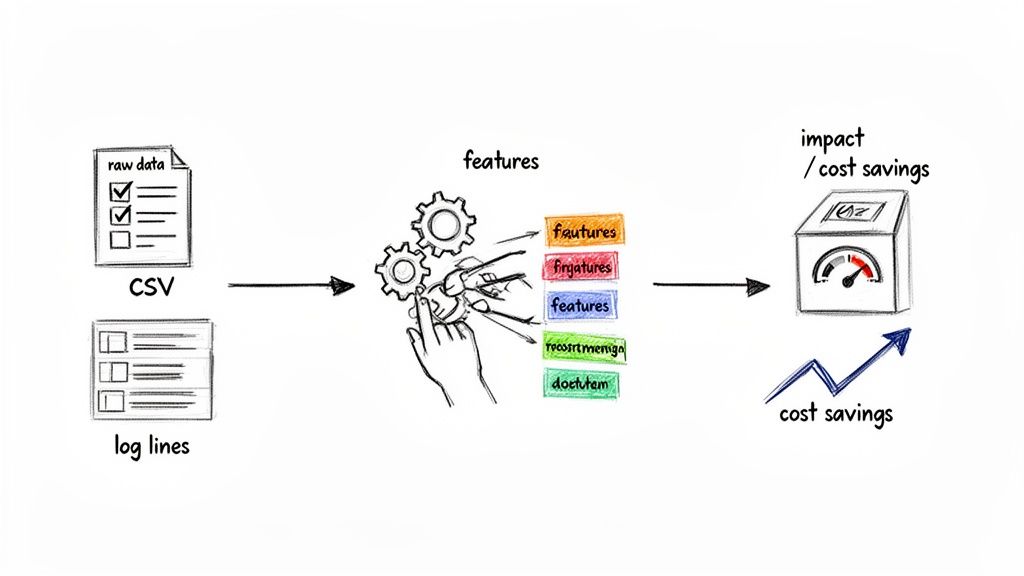
Alt text: Diagram showing raw data like 'user id' and 'timestamp' being transformed through feature engineering into meaningful features like 'time since last purchase', leading to business impact.
Feature engineering is the process of using domain knowledge to select and transform raw data into features that make machine learning models work better. If your data is the ingredients, feature engineering is the prep work a chef does—chopping, combining, and refining—to create a dish a model can digest.
A model is only as good as the data it’s given. If you feed it noisy, irrelevant data, you get poor results, no matter how powerful your algorithm is. Feature engineering ensures your model gets high-quality, informative inputs.
The Business Impact of Good Feature Engineering
For CTOs and product leads, feature engineering isn't just a technical task for the data science team; it's a strategic activity that directly impacts your budget and timeline.
- Faster Time-to-Value: High-quality features help models find patterns more quickly, cutting training time and moving your AI solution from proof-of-concept to production faster.
- Lower Project Risk: Well-designed features make model logic easier to understand. This simplifies debugging and validation, lowering the risk of deploying a faulty system.
- Reduced Cloud Costs: Smarter features often allow you to use simpler, less computationally intensive models, leading to significant savings on cloud infrastructure bills. For example, a well-engineered feature can reduce model training time on a GPU from 10 hours to 2, directly cutting costs.
- Higher Model Accuracy: Better features almost always result in better predictions, whether you're forecasting sales, spotting fraud, or identifying at-risk customers.
Ultimately, feature engineering is where your team’s business knowledge meets data science. It’s the art of manipulating data to reveal its predictive power, making it a cornerstone of any successful AI project.
Why Feature Engineering Is Your Model's Secret Weapon

Alt text: An illustration of a chef preparing dishes from raw ingredients, symbolizing feature engineering for better machine learning accuracy and lower cost.
Your ML algorithm is a world-class chef, but even the best chef can't create a masterpiece from unprepared, low-quality ingredients. Feature engineering is the meticulous process of cleaning, transforming, and combining your raw data into a format that highlights the exact patterns your algorithm needs to learn from.
Boost Accuracy, Reduce Model Complexity
Good feature engineering delivers an immediate jump in model accuracy. When you create features that clearly point to the outcome, you make the model's job much easier.
This also means you can often use simpler, less computationally hungry models. Instead of forcing a massive neural network to figure out the concept of "day of the week" from a raw timestamp, you can engineer a feature that spells it out. This improves performance and slashes cloud computing costs for training and deployment.
A simple model with well-engineered features will almost always outperform a complex model fed raw data. The goal is to put the "intelligence" into the data, not just rely on the algorithm to figure everything out.
Unlock Better Interpretability and Trust
In regulated fields like finance or healthcare, the why behind a prediction is often more important than the prediction itself. Feature engineering is your best friend for building explainable AI.
When you create features using domain knowledge, they are naturally easy for a human to understand.
- A "debt-to-income ratio" feature in a loan approval model makes immediate sense to a loan officer.
- A "days since last purchase" feature in a churn prediction model gives the marketing team a clear, actionable signal.
This transparency builds trust with stakeholders and simplifies regulatory compliance. Understanding the bigger picture of how Machine Learning for Businesses works makes it obvious why solid feature engineering is non-negotiable.
A 4-Step Framework for Transforming Data Into Value
At ThirstySprout, we use a four-step framework to structure feature engineering. This keeps technical teams and business stakeholders aligned on the path from raw data to a high-performing model.
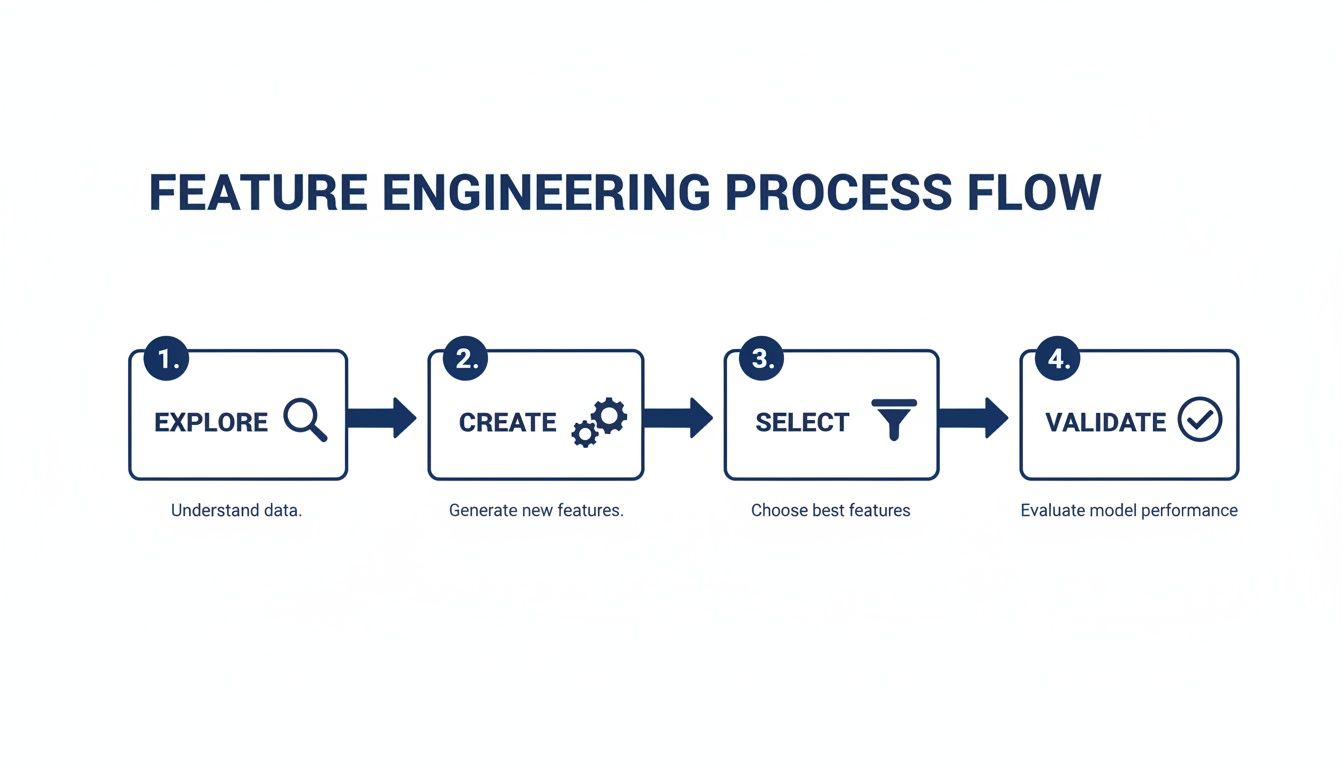
Alt text: Flowchart illustrating the four key steps of the feature engineering process: explore, create, select, validate, shown as a continuous cycle.
Step 1: Explore Data
Before you build, you must understand what you're working with. This step is a deep dive into your raw data to find patterns, spot anomalies, and form hypotheses. Your team analyzes distributions, checks for missing values, and creates visualizations. This is a critical time for product leads and business experts to share domain knowledge.
Step 2: Create Features
This is where the "engineering" begins. Armed with insights, your team crafts new features. This is the most creative part of the process and leans heavily on domain expertise.
Common examples include:
- Combining variables: Creating a "debt-to-income ratio" from separate debt and income fields.
- Extracting information: Pulling the day of the week from a timestamp to capture weekly patterns.
- Aggregating data: Calculating a user's "average purchase value over the last 90 days."
Step 3: Select Features
More isn't always better. After creating features, the next move is to methodically weed out the ones that don't add value. Too many irrelevant features can introduce noise and lead to overfitting, where a model performs well on training data but fails on new, real-world data. The team uses statistical tests to find the smallest set of features that still packs the most predictive punch.
Feature selection is the disciplined science that complements the creative art of feature creation. It's about trimming the fat to improve focus, reduce complexity, and cut computational costs.
Step 4: Validate and Iterate
Feature engineering is a loop, not a straight line. The final step is to test new features by training a model and measuring its performance on a separate validation dataset. The results tell you if your features moved the needle on the business metrics you care about. This iterative cycle of creating, selecting, and validating is what methodically pushes model performance higher.
Practical Examples of Feature Engineering
Theory is useful, but seeing feature engineering in action makes it click. Here are two common scenarios where smart feature creation has a direct business impact.
Example 1: Fintech Fraud Detection
Situation: A fintech startup needs to detect fraudulent credit card transactions in real time.
Raw Data: A simple log with user_id, timestamp, and transaction_amount.
This raw data is not enough. A single $2,000 transaction isn't inherently fraudulent. The signal is in how it compares to that user's normal behavior.
An ML engineer would transform the raw log into meaningful behavioral signals:
transaction_frequency_last_24h: How many purchases has this user made in the last 24 hours? A sudden burst is a red flag.amount_deviation_from_avg: How does this transaction amount compare to the user’s average? A large deviation is suspicious.is_unusual_time_of_day: Does this user typically shop at 3 AM? If not, a transaction at that time is worth a closer look.
Here’s a Python snippet showing how to create a simple frequency feature with pandas:
# Create a feature for transaction frequency in a rolling 24-hour window# Assumes 'df' is a pandas DataFrame with transaction datadf['timestamp'] = pd.to_datetime(df['timestamp'])df = df.sort_values(by=['user_id', 'timestamp'])# This calculates the number of transactions per user in a rolling 24h windowdf['tx_freq_24h'] = df.groupby('user_id')['timestamp'].rolling('24h').count().valuesBusiness Impact: The model now understands context. The result is a more accurate fraud detection system, reducing financial losses while minimizing false alarms that annoy legitimate customers.
Example 2: SaaS Churn Prediction
Situation: A B2B SaaS company wants to predict which customers are likely to cancel their subscriptions.
Raw Data: Login history, feature usage logs, and subscription plan details.
Knowing a customer is on the "Enterprise" plan is not enough. An Enterprise user who hasn't logged in for 30 days is a greater risk than a "Basic" user who uses the app daily. The key is to quantify engagement.
An experienced data scientist would build features that capture user interaction:
days_since_last_login: A simple but powerful recency feature.feature_adoption_ratio: The ratio of features a user has tried versus what's available in their plan. A low ratio suggests they aren't seeing value.admin_actions_last_30d: How many administrative actions (e.g., inviting a teammate) has the account admin performed recently? Low activity can signal poor team-wide adoption.
This approach is a core principle behind the growth of big data in retail.
Business Impact: The churn model can now flag at-risk accounts with high precision. This allows the customer success team to proactively intervene with training or support, directly protecting revenue.
Essential Techniques Your AI Team Should Master
As a leader, you don’t need to write Python, but you do need to understand the core techniques your team uses. This helps you scope projects, ask insightful questions, and appreciate the trade-offs your engineers are making.
Technique Decision Matrix
Use this matrix to map common data problems to the most effective techniques.
| Data Type | Problem | Recommended Technique | Key Consideration |
|---|---|---|---|
| Categorical | Text labels (e.g., "Basic", "Pro"). | One-Hot Encoding | Avoid on high-cardinality features (e.g., user IDs) to prevent creating too many columns. |
| Continuous | Numbers on different scales (e.g., Age vs. Income). | Scaling (Standardization) | Standardization is generally safer than normalization if your data has outliers. |
| Continuous | "Noisy" data where broad ranges matter more than exact values. | Binning (Discretization) | The number and width of bins can significantly impact performance; requires experimentation. |
| Temporal | Time-series data where past values influence the future. | Lag Features, Rolling Averages | Crucial for forecasting but requires careful handling of time windows to avoid data leakage. |
| High-Dimensional | Too many correlated numeric features are slowing down the model. | PCA (Principal Component Analysis) | Reduces feature count but makes the resulting components less interpretable. See our guide on understanding Principal Component Analysis for more. |
The impact of these methods is significant. A 2018 study found applying PCA to the Boston Housing dataset reduced training time by 70% while improving accuracy. Similarly, benchmarks show that temporal features like rolling averages can improve churn forecast accuracy by 18-22%. You can dig into some of the original research on these feature engineering findings.
The Feature Engineering Implementation Checklist
Use this checklist to ensure your ML projects are built on a solid, reproducible foundation. This is your pre-flight check before a model goes into production.
Phase 1: Scoping & Baseline
- [ ] Data Audit Completed: Profiled source data for completeness, types, and missing values.
- [ ] Domain Knowledge Acquired: Interviewed a subject-matter expert (SME) to understand business context.
- [ ] Business KPI Defined: Agreed on a specific, measurable goal (e.g., "reduce churn by 2%").
- [ ] Baseline Model Established: Trained a simple model on raw data to set a performance benchmark to beat.
Phase 2: Development & Validation
- [ ] Feature Hypotheses Logged: All ideas for new features are tracked with a clear rationale.
- [ ] Transformation Logic Version-Controlled: All transformation code is in Git. This is non-negotiable.
- [ ] Feature Definitions Documented: A central feature store or registry documents each feature's definition, source, and logic. See our guide to the best data pipeline tools for infrastructure options.
- [ ] Feature Importance Validated: Used SHAP or permutation importance to confirm new features improve performance on a validation set.
- [ ] Data Leakage Test Performed: Confirmed that no data from the future or test set has contaminated the training data.
Phase 3: Production & Monitoring
- [ ] Production Parity Ensured: The feature engineering logic in production is identical to the training logic.
- [ ] Feature Monitoring Established: Alerts are in place for data drift to detect when live feature distributions change.
- [ ] Latency & Cost Analyzed: Measured the time and cost to generate features in production.
This checklist helps you manage the entire lifecycle of machine learning model deployment.
What to Do Next
- Review your current ML projects: Are you spending at least 50% of your project time on data preparation and feature engineering? If not, you may be focusing too much on algorithms and not enough on the data itself.
- Schedule a meeting between your ML engineers and a business SME: Task them with creating three new, domain-specific features for your most important model. This simple exercise often unlocks significant performance gains.
- Audit your MLOps stack: Do you have a feature store or a clear process for documenting and reusing features? If not, make it a priority for your next infrastructure sprint.
Can AutoML Replace Manual Feature Engineering?
Not yet. Automated Machine Learning (AutoML) tools are powerful for optimizing standard transformations, but they lack deep domain expertise. An AutoML platform can’t invent a "debt-to-income ratio" because it doesn't understand what debt and income mean to your business.
The best results come from a partnership: your experts create high-potential features, and AutoML handles the brute-force work of testing and optimizing them.
How Do I Hire for Strong Feature Engineering Skills?
Look past a candidate's knowledge of algorithms. The best ML engineers connect technical choices to business impact. Ask them to walk you through a past project with these interview questions:
- "Describe a time when a feature you built significantly improved a model. What was your hypothesis for that feature?"
- "How did you measure the impact of your feature engineering, both on model metrics and the business KPI?"
- "Walk me through your process for validating features and ensuring they don't cause data leakage."
A great candidate will clearly explain their reasoning and demonstrate a focus on solving the core business problem.
Ready to build an AI team that masters feature engineering? At ThirstySprout, we connect you with vetted, senior AI experts who can transform your data into a competitive advantage.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.