
You're probably dealing with some version of the same problem most engineering leaders face now. The team looks busy, tickets move, standups sound fine, and yet releases still feel slower, riskier, or more chaotic than they should. Add remote collaboration and AI coding tools to the mix, and old management habits break fast.
That's why software development for managers has changed. The job isn't to supervise activity. It's to build a delivery system that can ship useful software predictably, recover quickly when things go wrong, and keep quality from eroding under speed pressure. That requires a different playbook than classic project management.
TL;DR
- Treat software delivery as a continuous loop, not a one-time project plan.
- Manage the system, not individual busyness. Focus on deployment frequency, lead time, change failure rate, and recovery time.
- Use small batches, automation, and clear quality gates to find bottlenecks before they turn into delays.
- Structure teams as cross-functional pods with explicit ownership, especially in remote and AI-assisted environments.
- In your first 90 days, audit the delivery flow, instrument the right metrics, and run one improvement experiment instead of launching a broad process overhaul.
If you run engineering, product delivery, or a remote software team, this is the practical version of software development for managers that holds up in production.
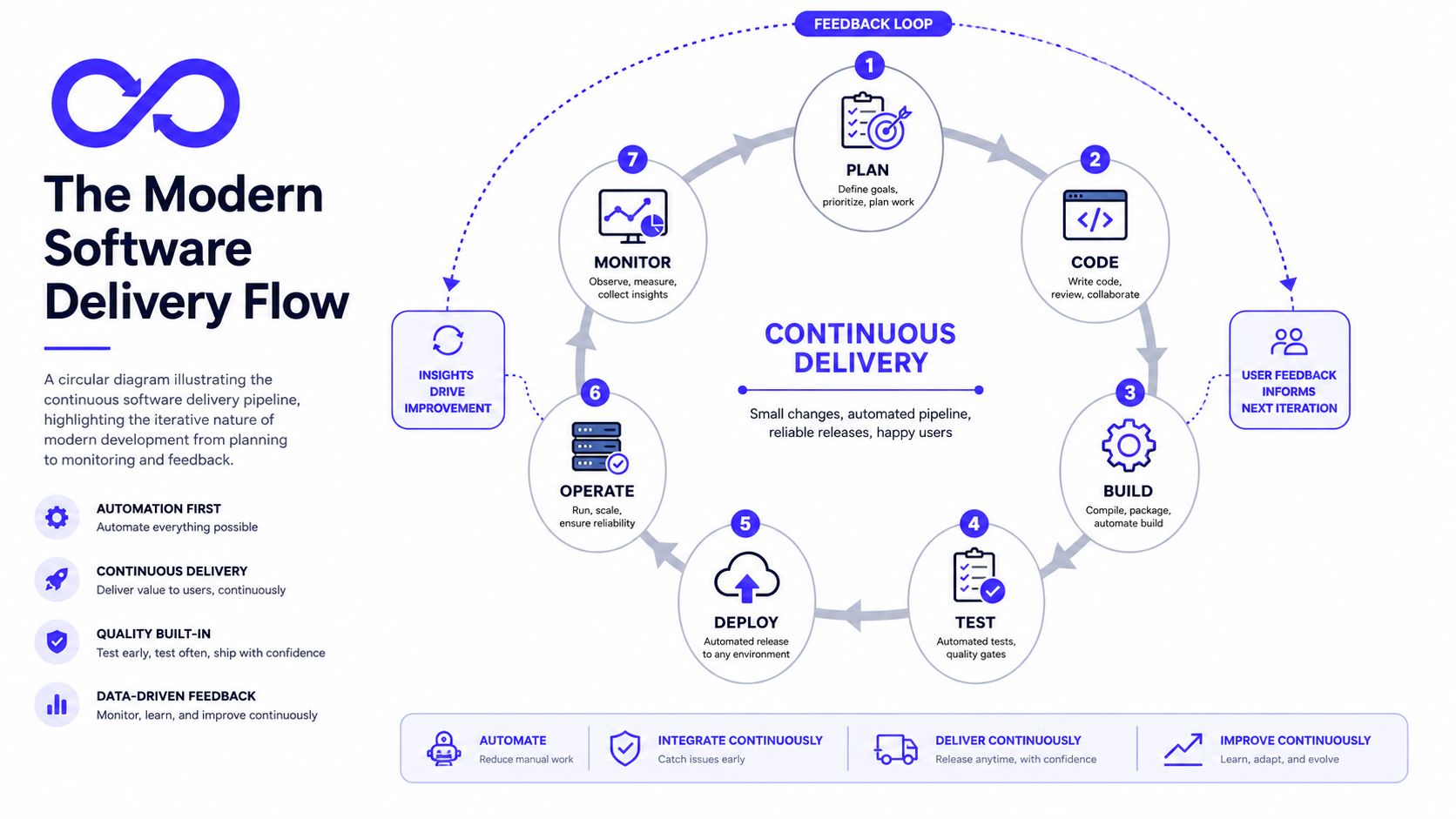
The Modern Software Lifecycle That Actually Ships
A lot of managers still inherit a mental model that looks like this: gather requirements, hand work to engineering, wait, test late, then release in a tense burst. That model breaks under modern product pressure.
A better model is a continuous delivery loop. Teams plan small pieces of work, code them, build and test automatically, deploy safely, operate the software in production, monitor what happened, and feed those lessons back into planning. That loop is what ships.
The business stakes are large. The global software market was valued at $823.92 billion in 2025 and is projected to reach about $2,248.33 billion by 2034, with enterprise software accounting for 61% of the market, according to software market projections and enterprise share data from Itransition. For managers, that means delivery discipline is a business capability, not a technical side issue.
Think in loops, not phases
Modern teams don't “finish development” and then start quality. Quality has to show up throughout the loop.
A healthy flow usually looks like this:
- Plan small, testable increments tied to a user or business outcome.
- Code in short-lived branches or similarly reviewable units.
- Build automatically so every change goes through the same path.
- Test with automation before humans spend time chasing regressions.
- Deploy in a repeatable way.
- Operate and monitor so production tells you what worked and what didn't.
Practical rule: If a change can't move through your standard path without heroics, the team doesn't have a process. It has a ritual.
If your release process depends on tribal knowledge, a single senior engineer, or a freeze window everyone fears, you don't need more status updates. You need a cleaner delivery path.
For teams working through cloud-native delivery and automation, Agile and DevOps practices for modern engineering teams become operational, not theoretical.
What each role contributes to shipping
Managers often get stuck because roles are described as specialties, not outcomes. That leads to handoffs instead of ownership.
Here's a simple way to frame core roles:
| Role | Primary contribution to the delivery loop | Business meaning |
|---|---|---|
| Frontend engineer | Builds user-facing behavior and client-side reliability | Faster learning from user behavior |
| Backend engineer | Implements business logic, APIs, and service behavior | Stable product operations and integrations |
| DevOps or platform engineer | Improves build, deploy, environment, and operational tooling | Lower release friction and better reliability |
| QA or test engineer | Strengthens test strategy and failure detection | Less rework and fewer escaped defects |
| MLOps engineer | Makes model deployment, monitoring, and repeatability production-ready | AI features behave reliably beyond demos |
A remote AI product team might ship an internal copilot feature this way: product defines a narrow workflow, frontend builds the review interface, backend exposes retrieval and orchestration endpoints, MLOps handles model deployment and monitoring, and platform engineering makes the release path repeatable. If one role is missing or overloaded, delivery slows at that exact point.
What doesn't work anymore
Managers get into trouble when they run software teams as coordination-heavy task factories.
Common failure patterns:
- Large batch planning that hides risk until late
- Manual testing bottlenecks that delay every release
- Role silos that reward local optimization over shipped outcomes
- Late production feedback that turns simple fixes into expensive incidents
The modern software lifecycle works when every role helps move work through a continuous system. That's the foundation of software development for managers who want predictable delivery instead of ceremonial process.
Measuring Engineering Outcomes Not Just Output
A team can produce a lot of visible activity and still deliver poorly. More commits don't mean faster learning. More tickets closed don't mean users got value. More pull requests don't mean the product became more reliable.
That's the trap. I call it output theater. It looks productive because dashboards are full of motion, but the system still struggles to ship.
Over 85% of organizations have a cloud strategy and 78% use DevOps, which changes what managers should measure. In cloud-based, automated environments, system outcomes like deployment frequency and lead time are the measures that matter most, as noted in Brainhub's summary of software management and DevOps trends.

The four metrics that don't lie
If you only track one category of delivery data, track these four system measures.
Deployment frequency
How often the team ships changes to production. This shows whether delivery is happening in small, repeatable batches or in risky, infrequent drops.Lead time for changes
How long it takes for a code change to reach production. This exposes waiting time, approval drag, test instability, and release friction.Change failure rate
How often a deployment causes a production issue, rollback, or meaningful defect. This is the fastest way to expose quality debt hiding behind “velocity.”Time to restore service
How quickly the team recovers after something breaks. This reveals operational readiness, monitoring quality, and ownership clarity.
Don't use these metrics to rank engineers. Use them to locate friction in the delivery system.
That distinction matters. Once managers turn system metrics into individual scorecards, teams start gaming the numbers.
Questions that reveal the truth
In a weekly delivery review, weak questions sound like this:
- Why did only a few tickets close?
- Who wrote the most code?
- Why aren't engineers moving faster?
Useful questions sound different:
- Where did work wait the longest?
- Which release step keeps failing?
- Are defects coming from review, testing, or rollout?
- What made recovery slower than it should've been?
Those questions follow the logic behind system-level engineering management guidance, especially the focus on flow over vanity metrics discussed in LinearB's perspective on measuring software teams without output theater.
A remote team example makes this concrete. Suppose your dashboards show high pull request volume, but lead time keeps stretching. The wrong conclusion is “engineers need more urgency.” The better conclusion is that work is piling up somewhere. Maybe reviews sit overnight across time zones. Maybe test suites are flaky. Maybe release approvals happen in a private Slack channel no one owns cleanly.
A simple scorecard for delivery reviews
Use a short scorecard in staff meetings or pod reviews:
| Signal | What to ask | What bad looks like |
|---|---|---|
| Flow | Is work moving in small batches? | Large PRs, long review times, delayed releases |
| Quality | Are changes failing in production? | Frequent hotfixes, repeated rollback anxiety |
| Recovery | Can the team restore service calmly? | Unclear ownership, slow incident triage |
| Learning | Do we know why delays happen? | Vague status, no root cause, repeated friction |
After the scorecard, pick one bottleneck. Not five. One.
Here's the common anti-pattern: a manager sees slow delivery and responds by adding more standups, more check-ins, and more dashboards. That increases reporting but rarely improves flow.
A better move is narrower. If code review is the bottleneck, reduce PR size and set review expectations. If test instability blocks deployment, fix the test environment before pushing for more output. If incidents take too long to resolve, tighten ownership and run incident writeups that produce operational changes.
This short video is useful if you want a plain-language explanation of outcome-oriented engineering measurement before you adapt it to your team rhythm.
What not to reward
Avoid using these as primary management metrics:
- Lines of code
- Commit count
- Hours online
- Tickets touched
- Pull requests opened
None of those tell you whether the team can ship safely, learn quickly, or support what it releases.
A busy engineering team can still be operationally weak. Shipping exposes the difference.
If you remember one thing from this section, make it this: software development for managers is about improving throughput and stability together. Speed without control creates incident churn. Control without speed creates backlog decay. The right metrics force you to manage both.
Frameworks for Critical Engineering Decisions
Managers earn trust when they turn fuzzy technical debates into clear business decisions. Two decisions come up constantly: when to pay down technical debt, and when to build custom software versus buying a platform.
Neither choice should be ideological.
A practical rubric for technical debt
Technical debt becomes dangerous when it slows delivery, raises defect risk, or creates operational fragility. High-performing teams use small-batch delivery because it shortens feedback loops and makes defects cheaper to fix. Tracking cycle time and defect rates helps managers see when deferred cleanup is now the bottleneck, as described in Axify's engineering management guidance on flow metrics and small-batch delivery.
Use this simple yes-or-no rubric in planning:
- Does it slow feature delivery by making changes harder than they should be?
- Does it increase production risk because behavior is hard to predict?
- Does it create repeated defects in the same area?
- Does it block automation such as testing, deployment, or environment setup?
- Does it depend on one person's memory instead of documented system behavior?
If you answer yes to several of those, it's no longer “nice to clean up later.” It's competing with product work already.
Operating principle: Don't label everything technical debt. Reserve the term for work that taxes future delivery.
A mini-case: a backend service has no reliable automated tests around billing logic. The team can still ship, but every pricing change triggers long manual checks and nervous late-night reviews. The mistake is to keep classifying that as “engineering hygiene.” It's a release constraint. In that case, a manager should prioritize test coverage and release safeguards before asking for more pricing experiments.
A build versus buy checklist
Build-versus-buy decisions go wrong when teams compare license cost to engineering salary and ignore the rest. The key question is whether the capability is strategic enough to own, and whether your team can support it without losing focus.
Use this checklist:
| Decision factor | Lean toward build | Lean toward buy |
|---|---|---|
| Strategic differentiation | The capability is core to product value | The capability is standard infrastructure |
| Workflow fit | You need custom behavior that tools can't support well | Existing tools fit most needs |
| Integration burden | Your architecture can support ownership cleanly | Vendor integration is simpler than internal maintenance |
| Control and governance | You need tighter control over behavior or data handling | Governance needs are satisfied by the vendor |
| Team focus | The team has capacity and long-term ownership appetite | Building it would distract from core product delivery |
A mini-case: a startup wants an internal admin workflow engine. Product argues for custom software because “our process is unique.” Engineering should test that claim hard. If the workflow mostly manages approvals, notifications, and role-based states, buying may be smarter. If that engine directly powers customer-facing differentiation, building may be justified.
If you're making those calls while fundraising or planning a product roadmap, it also helps to see how investors think about software categories and capital concentration. This directory of firms can help you find leading US software investors and understand where software buyers and backers are placing conviction.
For a deeper operating view, this build versus buy software decision guide is the right internal reference to standardize how your team documents these calls.
What works in practice
Good managers don't ask, “What's the technically pure answer?” They ask:
- What reduces future drag
- What protects core differentiation
- What can this team own
- What choice keeps delivery predictable
That framing keeps software development for managers grounded in business reality instead of architecture debates.
Designing and Hiring Your Modern Engineering Team
Org charts rarely explain delivery performance. Team design does.
If your structure creates too many dependencies, every feature turns into scheduling overhead. If ownership is vague, quality slips because everyone assumes someone else is covering the edge cases. In remote environments, those weaknesses get exposed faster.
The better pattern for most product teams is the cross-functional pod. A pod owns a customer problem or product surface end to end. It has enough skills inside the group to ship without waiting on a queue for every decision.
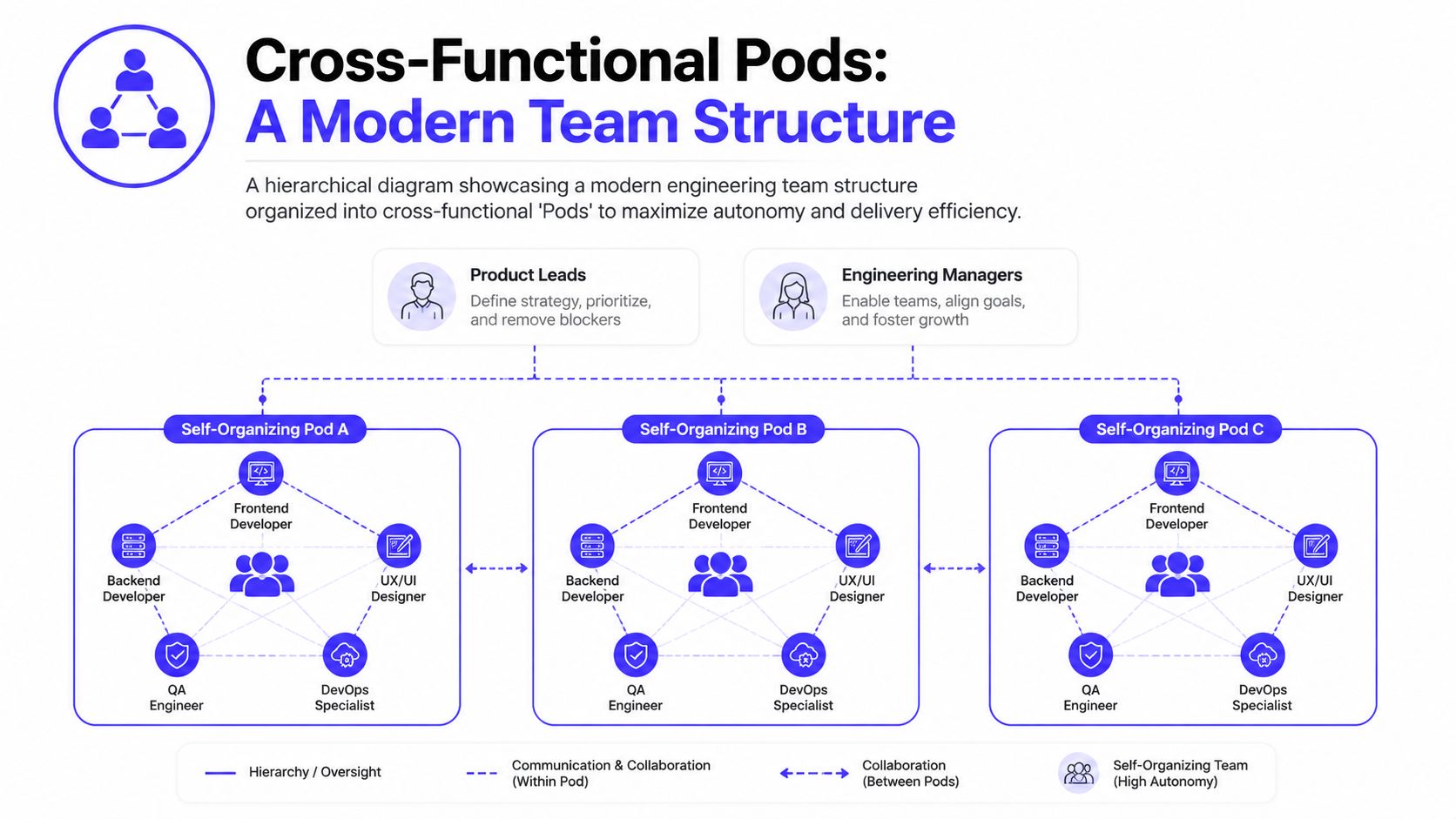
What a good pod actually owns
A pod should have a mission, not a vague area of interest.
For example, an AI-assisted support feature pod might own:
- the agent workflow in the product
- retrieval or orchestration logic
- quality review paths for unsafe or weak answers
- monitoring for production behavior
- release and rollback readiness
That pod might include a product-minded backend engineer, a frontend engineer, a platform or DevOps partner, and access to ML or MLOps support when model behavior is part of the feature. The key is not title purity. It's outcome ownership.
AI changes role design more than titles
The 2024 Stack Overflow Developer Survey found that 76% of developers were using or planned to use AI tools, according to this analysis of AI's impact on engineering management. Managers now need workflows that assume AI assistance is normal.
That changes hiring in a few important ways:
Junior speed can look misleading
AI can help someone produce more code quickly. It can't guarantee architecture judgment, failure analysis, or safe trade-offs.Senior review work becomes more important
The strongest engineers spend more time defining boundaries, reviewing generated changes, and guarding system integrity.Onboarding needs explicit quality rules
“Use AI if helpful” isn't enough. Teams need standards for testing, review, documentation, and when generated code needs deeper scrutiny.
In AI-assisted teams, the unit of management shifts upward. You're no longer just managing coders. You're managing prompts, review paths, quality gates, and system ownership.
A sample hiring scorecard for an AI product engineer
Use a scorecard that tests judgment, not just implementation speed.
| Capability | What good looks like | Interview prompt |
|---|---|---|
| System thinking | Breaks features into services, states, and failure paths | “How would you ship this feature so rollback is safe?” |
| AI workflow judgment | Knows when AI output is useful and when it needs strict review | “What kinds of generated code deserve extra scrutiny?” |
| Product sense | Connects engineering choices to user experience | “What would you instrument first after launch?” |
| Remote execution | Writes clearly, documents assumptions, works asynchronously | “Show how you'd hand off a design decision across time zones.” |
| Quality discipline | Uses tests and deployment safeguards as part of normal delivery | “What must be automated before this feature is widely released?” |
A practical interview question I like is simple: “Tell me about a feature that looked done in development but failed in production. What did you miss?” Strong candidates talk about monitoring gaps, hidden assumptions, rollout strategy, or weak test boundaries. Weak candidates just blame the bug.
If you're benchmarking external support options while building pods, this roundup of top Web3 and AI outsourcing companies is a useful market scan. It helps compare where specialist capacity might fit versus what should stay in-house.
For companies hiring remote AI talent, cross-functional team design for modern product delivery is the operating model to use before opening roles. And if you need a sourcing option, ThirstySprout is one way to find vetted remote AI and engineering talent for pod-based teams without redesigning your hiring loop from scratch.
What doesn't work
Three hiring mistakes show up repeatedly:
- Over-indexing on coding speed when the role needs architecture judgment
- Hiring narrow specialists into broad pods without clarifying ownership boundaries
- Ignoring writing and async communication in remote-first teams
Software development for managers now includes team design as a delivery lever. Structure decides how quickly problems get solved, how safely software ships, and whether AI makes the team better or just faster at creating rework.
Your First 90 Days A Manager's Action Plan
Most new managers try to prove value too early by changing too much. That usually backfires. You need enough understanding to act precisely.
A stronger first 90 days looks like this: map the delivery system, measure it, then improve one constraint at a time.

Engineering management guidance recommends CI/CD pipelines, automated testing, and workflow automation because they improve efficiency and reduce errors. A practical early step for any manager is to audit automation, since it directly affects reliable shipping and provides the data needed for flow metrics, as outlined in Jellyfish's engineering management best practices.
Days 1 to 30
Start by learning how work really moves.
Map the value stream
Follow one recent feature from planning to production. Note every queue, approval, manual step, and point where work waited.Run structured 1:1s
Ask each engineer the same set of questions: what slows delivery, what causes avoidable risk, and what part of the system they trust least.Audit release mechanics
Document how code gets merged, tested, approved, deployed, and monitored. Look for hidden dependencies on specific people.Review current incident patterns
Don't chase blame. Look for recurring categories like flaky tests, environment drift, unclear ownership, or weak rollback practice.
A simple 1:1 question set that works well:
- What part of delivery feels slower than it should?
- Where do we create rework?
- What breaks most often?
- What does the team avoid touching?
- If you could fix one process issue this quarter, what would it be?
Manager habit: Spend your first month collecting operational truth, not pitching process improvements.
Days 31 to 60
Once you know the path, instrument it.
Use this phase to put visible measures around the flow:
- Set up delivery dashboards for deployment frequency, lead time, change failure rate, and recovery time
- Add supporting flow signals such as cycle time and defect patterns where useful
- Identify the primary bottleneck instead of listing every problem
- Clarify ownership for services, environments, and incident response paths
A mini-case: a remote team believes deployment is the problem. After mapping the flow, they discover deployments are smooth. The delay is in pre-merge review because large pull requests span multiple time zones and no reviewer rotation exists. The right fix isn't release automation. It's smaller changes, reviewer assignment rules, and tighter review expectations.
Days 61 to 90
Now run one controlled improvement.
Pick a single operational change and treat it like a product experiment.
Good examples:
- Reduce PR size to speed reviews
- Stabilize one flaky test suite that blocks releases
- Introduce deployment automation for a manual release path
- Create a lightweight tech debt review tied to delivery friction
- Define AI usage guardrails for code review, tests, and documentation
Use a before-and-after review, but keep it qualitative if your data is still immature. What changed in waiting time, confidence, rollback clarity, and team stress? Those observations matter early.
A 90-day manager checklist
| Timeframe | Priority | Expected outcome |
|---|---|---|
| Days 1 to 30 | Learn the delivery path and trust boundaries | You understand where work actually stalls |
| Days 31 to 60 | Instrument the system and name the main constraint | The team can see delivery health clearly |
| Days 61 to 90 | Improve one bottleneck with a controlled change | You build credibility through targeted results |
What doesn't work in the first 90 days:
- rewriting the process before you understand it
- introducing too many metrics at once
- using dashboards to police people
- treating AI adoption as a tooling choice instead of a workflow change
- promising a full transformation before fixing one persistent constraint
Software development for managers gets easier when you stop trying to manage everything and start managing flow. The first 90 days should produce clarity, not theater.
If you're building a remote engineering or AI product team and need help turning this playbook into hiring plans, pod design, or delivery structure, ThirstySprout can help you scope the team, evaluate role gaps, and start a pilot with vetted engineers who've shipped production systems.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.