
You have too many “must-win” AI projects, not enough senior people, and a budget that won't forgive indecision. One team wants to ship a customer-facing copilot. Another needs data pipelines fixed. Your MLOps work is half-built. Everyone says their project is critical.
That's usually where waste starts. Not because the team is weak, but because the company never made one hard allocation decision early enough.
Your AI Roadmap Is Stuck Now What
TL;DR
- Use one prioritization system. If your roadmap is stuck, start with RICE for projects, then force every initiative into a ranked list.
- Allocate people before you allocate tools. Headcount mistakes are harder to undo than software spend.
- Review allocation every quarter. Annual budgeting is too slow for AI teams dealing with changing product and infrastructure demands.
If you're a founder, CTO, or engineering lead planning the next few quarters, this is the core job. Not “support innovation” in the abstract. Your job is to decide which work gets people, which work gets delayed, and which work gets killed.
A good resource allocation strategy isn't finance theater. It's how you stop paying senior engineers to context-switch across six half-funded priorities. It's also how you decide whether the next dollar goes to an ML engineer, a data engineer, a contractor, or platform work that removes recurring toil.
The business stakes are bigger than most startup teams admit. Firms with disciplined, data-driven allocation reallocated 10–15% of capital annually and saw a median annual earnings growth rate roughly 2.4 percentage points higher than peers, which translated into nearly twice the cumulative earnings growth over a decade according to this summary of McKinsey Global Institute research. That matters because early-stage companies don't usually lose from lack of ideas. They lose from funding too many ideas at once.
What this usually looks like in practice
A typical Series A AI company has some version of this mess:
- Product pressure: Sales wants visible AI features now.
- Platform drag: Engineering knows the model and data stack won't scale cleanly.
- Hiring friction: The team can't fill every specialist gap with full-time hires.
- Budget confusion: Leaders approve projects without tying spend to one business outcome.
Practical rule: Every project should map to one primary business outcome. Revenue, retention, cost control, risk reduction, or delivery speed. If it maps to all five, it usually maps to none.
If your roadmap already feels crowded, don't add another planning ritual. Shrink the number of active bets, tie them to business outcomes, and make the trade-offs visible. If you need a parallel planning model for that exercise, this AI implementation roadmap is a useful companion.
Choose Your Allocation Framework
Different teams need different decision systems. The mistake is picking something too heavy, then abandoning it after one planning cycle.
Start with the problem you're actually trying to solve
Use RICE when product feature requests pile up. Use OKR-linked budgeting when leadership keeps approving work that doesn't move company goals. Use capacity planning when your bottleneck is delivery, not ideation.
That sounds simple because it is. The framework should remove debate, not create a new layer of it.
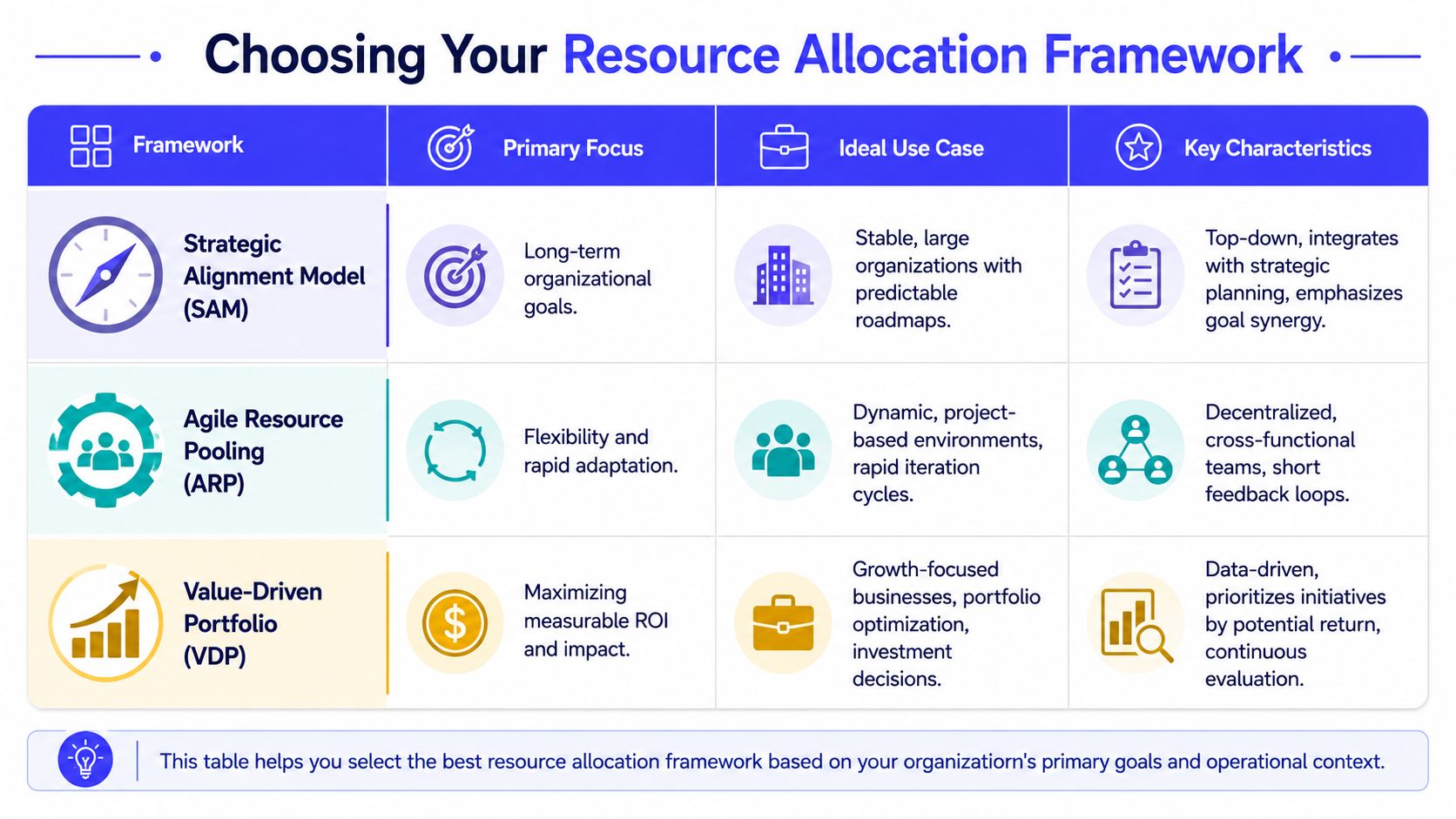
RICE works when the roadmap is feature-heavy
RICE stands for Reach, Impact, Confidence, Effort. It's useful when product, engineering, and go-to-market leaders are arguing over feature priority without a shared scoring method.
A lightweight RICE example:
| Initiative | Reach | Impact | Confidence | Effort | Decision |
|---|---|---|---|---|---|
| Support copilot for existing customers | High | High | Medium | Medium | Fund now |
| Internal model evaluation dashboard | Medium | Medium | High | Low | Fund if unblocker |
| Experimental voice agent | Unknown | Medium | Low | High | Delay |
RICE is good for product-facing choices. It is weaker for infrastructure work unless you explicitly score technical unblockers as business enablers.
OKR-linked budgeting works when priorities drift
This is better for companies where every team can justify spend, but few initiatives clearly support the quarter's goals.
A simple rule helps: no project gets budget or headcount unless it maps to a company or team objective and key result. That forces uncomfortable conversations early. For example:
- Objective: Improve onboarding conversion
- Approved AI work: Lead scoring, personalized onboarding prompts
- Rejected for now: Internal model playground with no direct tie to onboarding or delivery risk
If a project can't survive one sentence of business justification, it shouldn't survive a planning cycle.
This method is especially useful for Series A teams where founders need a clean line from spend to traction.
Capacity planning works when specialists are the constraint
If your biggest issue is that the same MLOps lead, staff data engineer, or backend engineer appears on every critical project, use capacity planning first.
You're not prioritizing ideas. You're managing finite specialist throughput.
A simple capacity planning board tracks:
- Role-based demand
- Available time after meetings, support, and admin
- Current allocation by initiative
- Risk flags for over-commitment
This is often the most honest framework for AI teams because delivery depends on scarce specialist roles, not just total engineer count.
A good first choice for each stage
- Seed: RICE, because the team is still deciding what deserves existence.
- Series A: OKR-linked budgeting, because growth pressure creates expensive distractions.
- Series B: Capacity planning plus portfolio review, because specialist bottlenecks start shaping execution more than raw idea volume.
The People Puzzle Headcount vs Contractors vs Infra
Most allocation mistakes aren't software mistakes. They're staffing mistakes.
AI leaders often assume the answer to roadmap pressure is “hire more ML engineers.” Usually it isn't. Data scientists and ML engineers typically spend 40–60% of their time on data preparation, pipeline debugging, and stakeholder communication rather than model experimentation, according to this industry analysis summary. If you ignore that hidden work, you'll keep hiring for the wrong bottleneck.
The decision matrix that actually helps
| Factor | Choose Full-Time Hire When... | Choose Contractor/Fractional When... | Choose Infra/Tooling When... |
|---|---|---|---|
| Duration of need | The work is persistent and core to the product | The need is urgent, specialized, or temporary | The same manual work repeats every sprint |
| Strategic importance | The capability is part of your moat | You need expert execution before building in-house depth | Automation removes recurring dependency on scarce people |
| Knowledge retention | Context must stay in-house | Transfer can happen through documentation and handoff | Process matters more than individual heroics |
| Hiring risk | You're confident the role definition is stable | You're still discovering the real job description | A tooling layer can postpone premature hiring |
| Speed | You can wait for the right long-term person | You need capability immediately | You need leverage across the whole team |
What usually works
Full-time hires make sense for areas that define the product or the company's core platform. If your model serving layer, ranking logic, or customer data workflows are central to differentiation, own that capability.
Contractors or fractional specialists fit when the work is sharp, urgent, and hard to hire for. Good examples include standing up a feature store, fixing CI/CD for models, cleaning up a brittle data ingestion path, or leading a short MLOps architecture transition. That's where IT staff augmentation for AI and engineering teams can make sense operationally.
Infrastructure spend is the right answer when human effort keeps getting wasted on repeatable work. If engineers manually patch pipelines every week, better tooling may create more value than another person.
Mini-case one
A startup has two ML engineers spending large chunks of their week on failed data jobs, ad hoc stakeholder requests, and notebook-to-production cleanup. The wrong move is hiring a third ML engineer. The better move is often a contract data engineer or MLOps specialist plus a tighter platform backlog.
Mini-case two
A fintech team wants a full-time prompt engineer because experiments feel slow. After review, the underlying issue is that no one owns evaluation, versioning, and release discipline. In that case, infra and process beat another feature-focused hire.
Operator's test: If the pain shows up as queueing, handoff failures, or repeated rework, don't default to headcount. Check whether the missing asset is actually workflow ownership or tooling.
One more practical note. If you use contractors in the UK, classification matters. Founders who haven't dealt with payroll and engagement structure should review IR35 and UK contractor tax 2026 before scaling contractor usage across engineering.
What Good Allocation Looks Like KPIs and Metrics
If your resource allocation strategy is healthy, you should see it in a small operating dashboard. Not in a deck. Not in a yearly budget file. In live delivery signals.

Track a few metrics that force action
In software and AI engineering organizations, utilization targets of 70–85% per role correlate with sustainable delivery performance and help avoid burnout-driven turnover, and teams that track planned versus actual effort see lower schedule variance, according to RocketLane's resource allocation guidance.
That gives you one reliable anchor. Don't try to squeeze every engineer to the ceiling. Teams need room for review, debugging, coordination, and unplanned work.
A practical dashboard should include:
- Utilization by role: Especially for scarce specialists like MLOps, platform, and data engineering
- Planned vs actual effort: Use this to catch estimation drift early
- Demand vs capacity by function: Shows whether your roadmap depends on roles you don't have enough of
- Allocation by business outcome: Reveals whether your team is overfunding internal projects with weak impact
How to read the numbers
If utilization is too low, you may have weak prioritization or poor staffing fit. If it's too high, deadlines start slipping because nobody has slack for quality, incident work, or integration tasks.
If planned versus actual effort keeps diverging, don't just blame estimation. Ask whether hidden work is consuming the team, whether dependencies were ignored, or whether the wrong roles were assigned.
Here's a simple review template:
| KPI | What it tells you | Common failure signal | Likely action |
|---|---|---|---|
| Utilization by role | Workload health | Specialists overloaded | Rebalance or reduce scope |
| Planned vs actual effort | Forecast quality | Persistent delivery slippage | Improve scoping and allocation |
| Demand vs capacity | Structural bottlenecks | Same role blocks multiple projects | Hire, contract, or defer work |
| Allocation by outcome | Strategic fit | Too much spend on low-impact work | Re-rank portfolio |
Healthy allocation doesn't look “busy.” It looks predictable.
What not to track
Avoid vanity metrics like total tickets closed or generic story-point output across mixed teams. Those numbers rarely tell you whether the company funded the right work. A lean dashboard with role-aware capacity and forecast discipline is far more useful.
Stage-Specific Allocation Templates for AI Startups
Most advice on resource allocation strategy stays abstract. Early-stage AI companies need working templates, even if they later adjust them.
Here's the rule I use. The split should change as the company moves from proving demand to supporting scale. Product pressure dominates early. Platform pressure catches up fast once customers depend on the system.
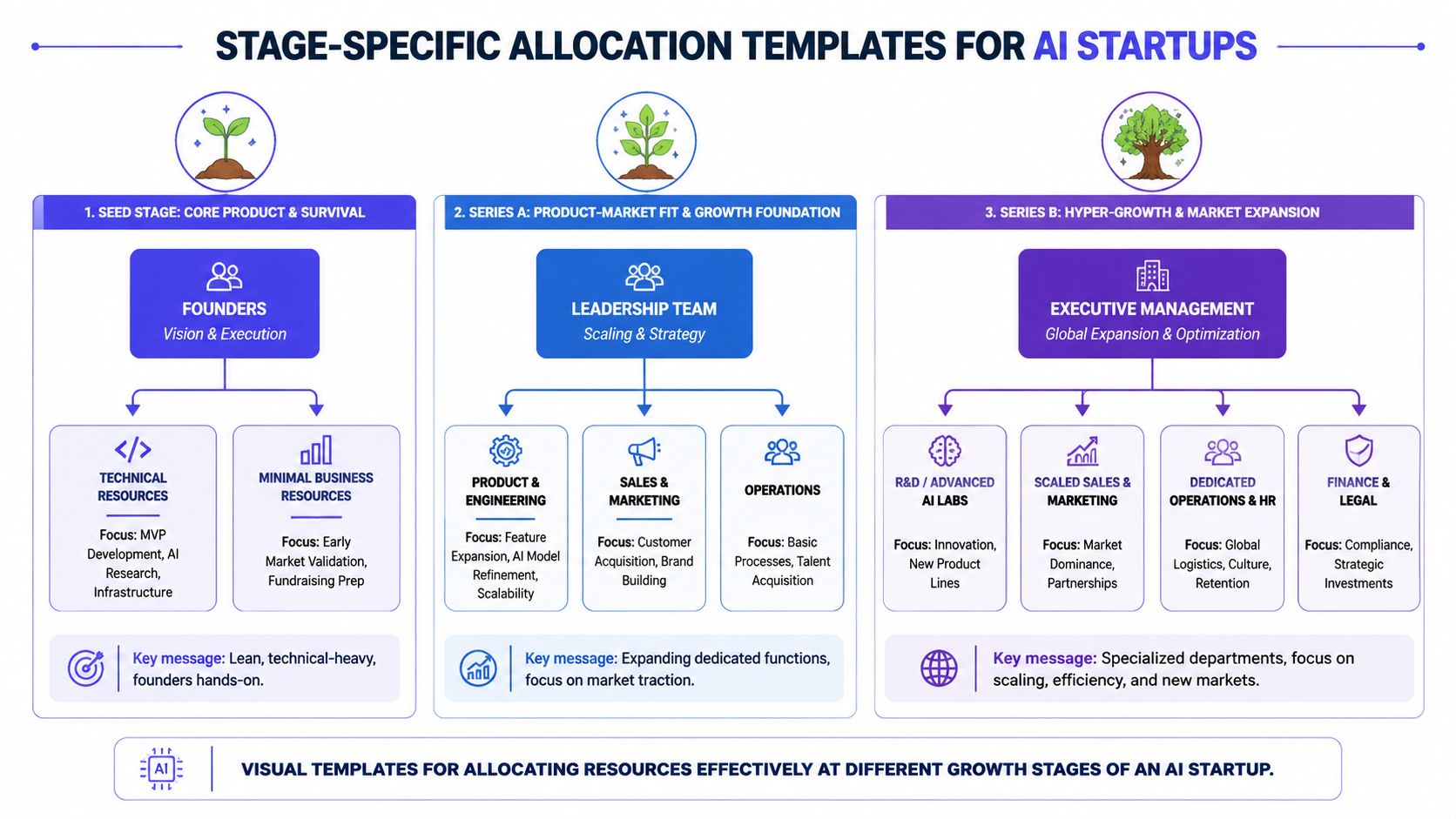
Seed stage
At Seed, you're buying learning. The company needs signal from users, not an elegant internal platform.
A practical template:
- Core product and feature delivery: Highest share of people and budget
- AI platform and MLOps: Minimal but intentional
- Research and experimentation: Narrow, tied to product questions
- Tech debt and maintenance: Controlled, not ignored
A Seed team usually makes one smart infrastructure investment, not five. Maybe it's evaluation workflows. Maybe it's reliable dataset versioning. Maybe it's a simple deployment path. The mistake is pretending you need a mature internal AI platform before you've earned product pull.
Series A stage
Series A is where teams get punished for underinvesting in operational discipline. Customers want reliability. Sales wants roadmap speed. Engineers start feeling the cost of every shortcut made at Seed.
The allocation pattern changes:
- Product is still the largest bucket
- Platform and MLOps move from “supporting” to “blocking or enabling”
- Research narrows further unless it directly supports product differentiation
- Maintenance and technical debt become a planned category, not background noise
A 2023 McKinsey survey found that 70% of organizations see MLOps and platform capabilities as important or critical to scaling AI, yet only about 35% have standardized MLOps practices, as summarized in this analysis. That gap shows up in startups as stalled releases, fragile model handoffs, and engineers babysitting systems instead of shipping product.
For teams feeling that tension, stronger AI project management practices usually matter as much as new hiring.
Here's a useful checkpoint for this stage.
If your team has multiple production models, recurring deployment friction, and unclear ownership of evaluation or monitoring, platform work is no longer optional overhead. It is product delivery work.
A short explainer on the shift helps make this visible to non-technical stakeholders:
Series B stage
By Series B, the company needs a portfolio mindset. The issue is no longer “can we ship AI?” It's “can we scale AI without drowning in maintenance and coordination cost?”
A practical template here looks different:
| Stage | Core Product | AI Platform and MLOps | Research | Tech Debt and Maintenance |
|---|---|---|---|---|
| Seed | Majority focus | Minimal foundation | Targeted experiments | Small planned share |
| Series A | Large focus | Meaningful increase | Tighter scope | Visible planned share |
| Series B | Balanced with platform | Major strategic function | Selective bets | Ongoing operational category |
At this point, contractors can still help, but they should fill targeted gaps. The company should own architecture, core platform direction, and role clarity internally.
Governance and Review Cadence to Stay on Track
A resource allocation strategy fails when it becomes a quarterly spreadsheet exercise with no operating rhythm behind it.
The companies that do this well build a repeatable review loop. A 2016 Harvard Business Review Analytic Services survey found that organizations with formal allocation processes directed 40% of capital and talent toward projects above the cost of capital, versus 15% at less mature firms, while also reducing project overload by roughly 20–30%, according to this summary of the research. That gap is what discipline looks like.
Use a quarterly review, not annual guesswork
For startups, annual planning is too blunt. AI priorities shift with customer feedback, model performance, hiring changes, and infrastructure reality.
A useful quarterly review agenda:
- Review the operating dashboard. Look at utilization, planned versus actual effort, and role bottlenecks.
- Check progress against company goals. If work consumed resources but didn't move a goal, challenge it.
- Re-rank the active portfolio. Run current projects and new requests through the same framework.
- Make explicit reallocation decisions. Move people, budget, or contractor support. Don't just “monitor.”
Keep the governance lightweight
You don't need a PMO. You need a cadence, a scorecard, and one owner who can force decisions.
A simple meeting format works:
- Founder or CTO: sets business priority
- Engineering lead: reports real capacity
- Product lead: argues expected impact
- Finance or operations lead: checks spend against plan
Teams don't get into trouble because they lack planning docs. They get into trouble because nobody revisits old commitments after reality changes.
What usually breaks the process
Three things show up repeatedly:
- Legacy commitments stay funded long after the business case weakens.
- Infrastructure work stays invisible until product delivery slows down.
- No one owns trade-off decisions across teams.
If you fix only one thing, fix cadence. A decent framework with regular review beats a complex framework nobody uses.
Your First 3 Steps to a Smarter Allocation Strategy
You don't need a reorg to get better this week. You need one audit, one prioritization exercise, and one decision meeting.
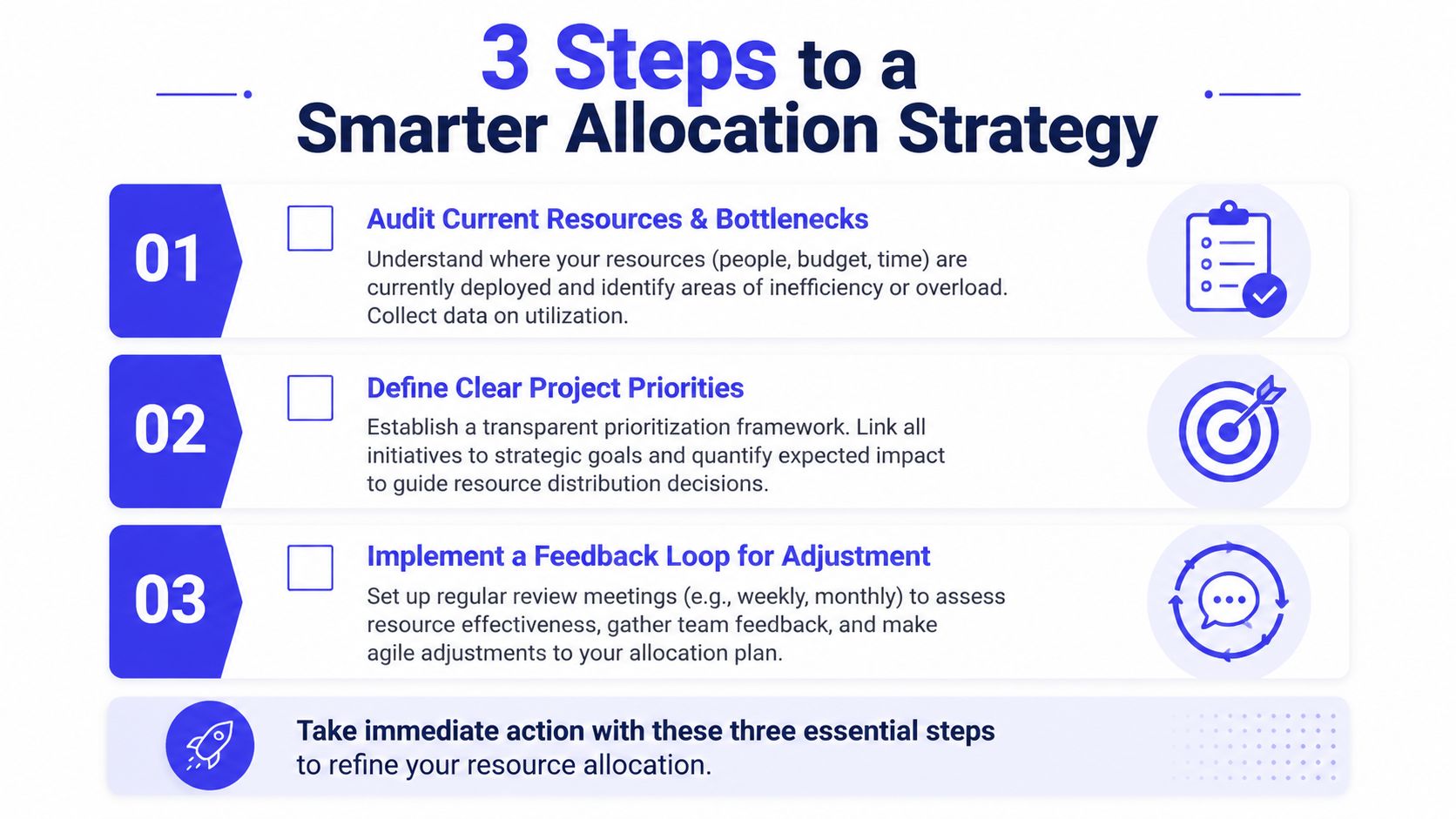
Step one
Audit one week of team time. Don't use estimates. Use calendars, sprint records, incident logs, and actual work notes. You're looking for hidden work, role bottlenecks, and repeat interruptions that aren't visible in roadmap planning.
Step two
Take one stalled or controversial initiative and score it against an alternative using your chosen framework. If you use RICE, force the current favorite to compete with a platform or delivery-enabling project. That comparison usually exposes whether the company is underfunding infrastructure or overfunding visible features.
Step three
Put a short allocation review on the calendar with the people who can move budget or headcount. Bring the time audit, the ranked project list, and one explicit recommendation. For example: pause one feature, add one contractor, or shift one engineer onto platform work for the quarter.
A simple weekly checklist helps:
- Audit current load: Find where expensive talent is doing low-impact work
- Rank active bets: Use one shared method, not politics
- Decide and document: Name what changes now, not “sometime later”
If you want to operationalize this quickly, create a lightweight template in Notion or a shared spreadsheet with four tabs: active initiatives, role capacity, hidden work log, and next-quarter decisions. That's enough to start.
If you need help turning this into an execution plan, ThirstySprout can help you scope the right mix of full-time, contract, or fractional AI talent for your roadmap. You can Start a Pilot, See Sample Profiles, or build a tighter hiring plan around the exact bottlenecks slowing delivery today.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.