
TL;DR
- Focus on Business Impact First: Start by identifying a specific, high-value business problem, not by chasing cool technology. A good goal is measurable, like "Reduce ticket resolution time by 25%."
- Follow a 6-Phase Plan: Structure your work in stages: Strategy, Data Readiness, Pilot, MLOps, Governance, and Value Realization. This de-risks the project and builds momentum.
- Run a Lean Pilot (8–12 Weeks): The goal is a Minimum Viable Model (MVM) that proves technical feasibility and business value. Use a small, dedicated team (e.g., one AI Engineer, one AI PM).
- Build for Scale with MLOps: After a successful pilot, implement MLOps fundamentals (version control, CI/CD for ML, model registry) to automate deployment and ensure reproducibility.
- Start with Contractors for Speed: For your first pilot, specialized contractors can help you launch in 2–4 weeks, validating your idea before you commit to long-term hires.
Who this is for
- CTO / Head of Engineering: You need a reliable framework to de-risk your first AI investment and build a scalable technical foundation.
- Founder / Product Lead: You need to scope a pilot, define success metrics, and align the AI initiative with clear business outcomes.
- Talent Ops / Procurement: You're evaluating whether to hire full-time AI engineers or engage specialized contractors to accelerate your roadmap.
The 6-Phase AI Implementation Framework
A successful AI implementation roadmap moves a project from a vague idea to a scalable, value-generating system. It prevents teams from getting lost in technical rabbit holes or building solutions that don’t solve a real business problem.
Our framework breaks the journey into six manageable phases. Each stage builds on the last, ensuring you have a solid foundation before committing more resources.
- Phase 1: Strategic Alignment: Pinpoint the business problem and define success in measurable KPIs.
- Phase 2: Data Readiness: Audit, clean, and prepare the data required for your pilot.
- Phase 3: Pilot Development: Build a Minimum Viable Model (MVM) to prove the concept is viable.
- Phase 4: MLOps and Scaling: Build the production-grade infrastructure for deployment and automation.
- Phase 5: Governance and Monitoring: Set up guardrails for performance, ethics, and compliance.
- Phase 6: Value Realization: Measure ROI, document learnings, and plan the next iteration.
This table maps out the key phases, offering a realistic view of timelines, objectives, and the critical outputs you should be aiming for at each stage. For a hand getting started, an AI business plan generator can help structure your initial strategy.
One of the first decisions you'll face is how to develop your pilot model: fine-tune an open-source model, use a third-party API, or build from scratch. This choice impacts your budget, timeline, and need for different types of what is AI automation.
Our Take: Your initial pilot only needs to answer one question: "Can we solve this business problem with AI in a way that is technically feasible and creates value?" It's an experiment, not the final product. Keep it lean.
Phase 1 & 2: Strategy and Data Readiness
The most common reason AI projects fail isn't the algorithm—it's the mission. Too many teams dive into development without answering a simple question: what problem are we actually solving?
Before assigning an engineer, you must define the "why." A strong goal is measurable. Instead of "making support faster," a better target is: "Reduce average ticket resolution time by 25% within three months by automating Level 1 inquiries." This clarity focuses the team and links the project to a business win.
Practical Example 1: Use Case Prioritization Scorecard
You need to find the sweet spot where business impact, technical feasibility, and data availability overlap. A scoring framework removes gut feel and forces objectivity.
This scorecard helps you compare ideas and get stakeholders aligned.
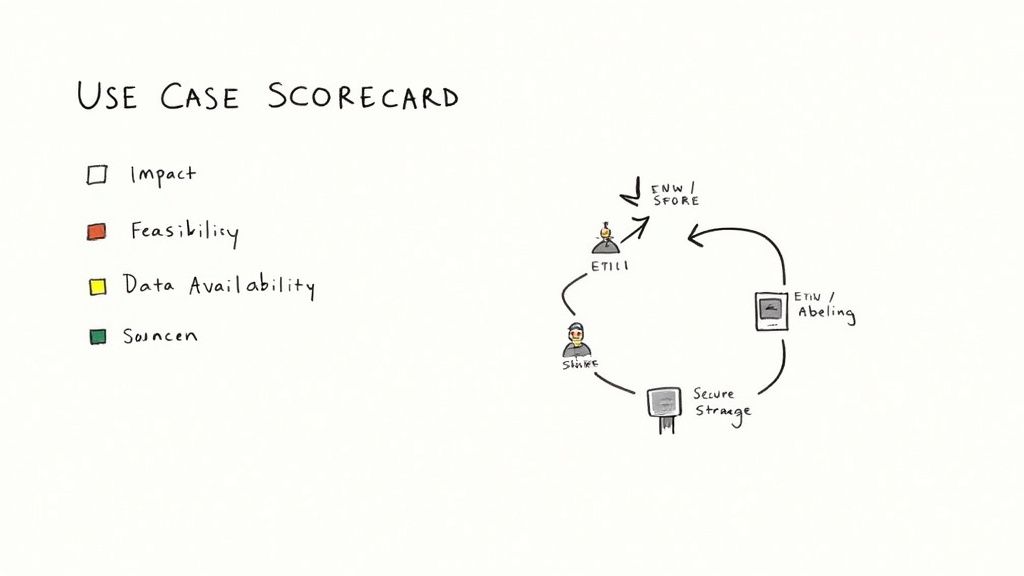
Here’s a template you can adapt:
Here, Use Case B has a higher potential impact. However, Use Case A wins because its data is ready and it's technically simpler. For a first project, it’s a much safer bet for a quick, tangible victory.
Getting Your Data House in Order
Once your use case is locked, the focus shifts to data. An AI model is only as good as the data it’s trained on. This phase is non-negotiable and often takes more time than model development. A practical data analysis strategy is essential.
Your data readiness checklist should cover four areas:
- Sourcing and Collection: Do you have the data? Is it accessible? Create a clear plan for consolidation.
- Cleaning and Preprocessing: Raw data is always messy. Handle missing values, fix errors, and standardize formats.
- Labeling and Annotation: For supervised learning, you need a consistent, accurate process for labeling your data.
- Pipeline and Governance: How will data get from source to model repeatably? Define data ownership and quality control.
From the Trenches: A SaaS Chatbot Pilot
A client wanted a chatbot to answer product questions. Their "data" was a messy folder of marketing PDFs. The project stalled immediately.We paused development and dedicated a four-week sprint to data readiness. A single engineer and a product manager teamed up to:
- Extract all text into structured JSON.
- Manually tag the top 500 support tickets to create a "golden set" of question-answer pairs.
- Set up a simple data pipeline to version the dataset.
This tedious work unlocked the project. With a clean dataset, they built a successful pilot in the next sprint, turning a failing initiative into a measurable win.
Phase 3: Executing A High-Impact AI Pilot
You have a use case and clean data. It’s time to build. The goal of a pilot is not to create a perfect system, but to answer two questions: can we build this, and will it create measurable value?
We frame pilots as intense 8–12 week sprints to produce a Minimum Viable Model (MVM). This forces ruthless prioritization and avoids "science projects" that drag on for months. A lean team—often just an AI Engineer and an AI Product Manager—can move fast and stay focused.
Your pilot should follow an agile process:
- Daily Stand-ups: Quick 15-minute syncs to review progress and unblock issues.
- Iteration Reviews: Demo the MVM's progress every two weeks, review metrics, and plan the next experiments.
- Model Performance Logs: Track model versions, datasets, and KPIs in a detailed log. This provides a clear audit trail of what worked and why.
Practical Example 2: B2B SaaS Knowledge Base Search
A Series B SaaS company wanted to build an intelligent search for its 50,000-document knowledge base to reduce support ticket escalations.
The Pilot Plan (First 4 Weeks):
- Weeks 1-2: The AI Engineer set up a basic Retrieval-Augmented Generation (RAG) pipeline, parsing documents into 512-token chunks and generating embeddings. The AI PM curated a test set of 100 common user questions.
- Weeks 3-4: They tested the initial RAG model, tracking two key metrics: precision@5 (relevance of top 5 results) and inference latency. Early results were poor; latency was too high, and retrieved chunks lacked context.
Iteration and Outcome:
The team implemented a hybrid retrieval strategy, combining keyword-based search (BM25) with semantic search. This simple change boosted precision@5 by 30%. The pilot was greenlit for further development, having proven its potential in weeks.
Practical Example 3: Fintech Fraud Detection Model
A fintech startup needed to spot fraudulent transactions in real-time. The objective was to reduce chargebacks by 15% without a high false positive rate.
The Pilot Plan (First 4 Weeks):
- Weeks 1-2: The team built a simple logistic regression model using a historical dataset of labeled transactions to establish a baseline.
- Weeks 3-4: They deployed the model in "shadow mode," making predictions on live transactions without blocking them. They monitored precision, recall, and the false positive rate.
Iteration and Outcome:
The first model caught fraud (high recall) but flagged too many legitimate transactions. The false positive rate was unacceptable. By analyzing the errors, they discovered that time-of-day was a weak signal. In the next sprint, they used a Gradient Boosting Machine and engineered new features, like recent transaction frequency. This iterative refinement struck a better balance, and the pilot successfully beat the initial goal.
Phase 4: Building Your MLOps Infrastructure For Scale
A successful pilot proves an idea. Now you must turn that idea into a production-grade asset. This is where you shift from experimentation to engineering.
Machine Learning Operations (MLOps) provides the automation and management needed to run models reliably at scale. Without a solid MLOps foundation, you're signing up for manual deployments, unpredictable performance, and a system that can’t grow.
Core Components Of An MLOps Stack
To move from proof-of-concept to a live product, you need an automated pipeline.
- Version Control for Everything: Version your code (
git), datasets (with tools like DVC), and models. The goal is to make every model 100% reproducible. - CI/CD for Machine Learning: Your Continuous Integration/Continuous Deployment pipelines must automatically trigger data validation, model retraining, and performance evaluation before deployment.
- Model Registry: A central repository for trained models. It stores artifacts, version histories, and performance metrics, acting as a single source of truth for what's approved for production.
- Feature Store: A shared library for the data inputs (features) that feed your models. It ensures consistency between training and production environments, preventing common errors.
Implementing these core components can slash deployment time from weeks to hours. For a deeper look, check out our guide to MLOps best practices.
Choosing The Right Architecture
Your architecture depends on your team's size, expertise, and control requirements.
- Startups: Prioritize speed and simplicity. A fully managed cloud platform like AWS SageMaker, Google Vertex AI, or Azure Machine Learning is usually the right choice.
- Scale-ups: May need more control to optimize cost or performance. A Kubernetes-based setup using tools like Kubeflow offers more power but requires deeper infrastructure expertise.
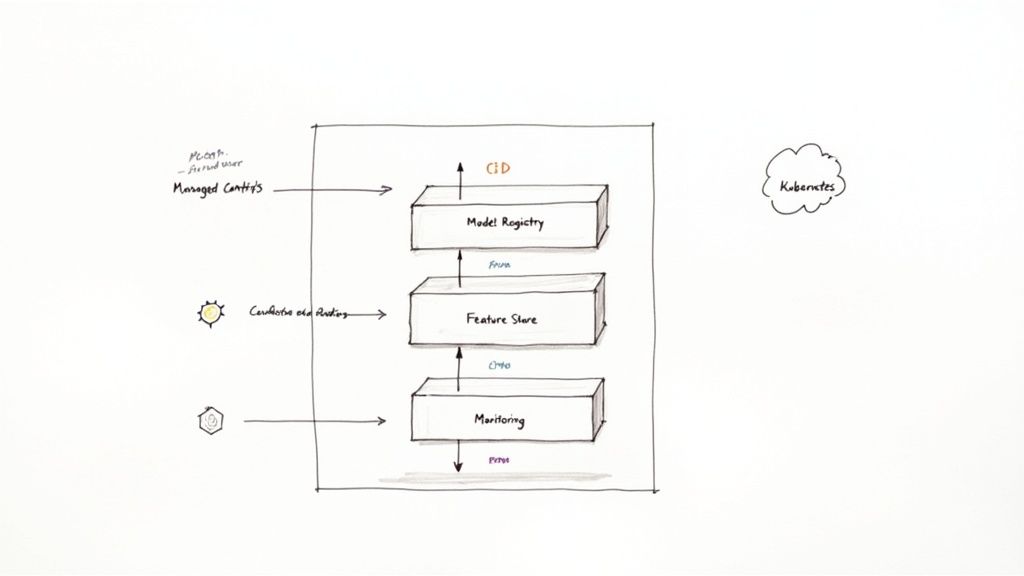
This diagram shows how data flows from a feature store, through a model registry, and into a monitored production environment.
Phase 5: AI Governance And Continuous Monitoring
Once your model is live, the work is just beginning. You must ensure it operates safely, ethically, and effectively. Governance and monitoring are the guardrails that prevent a successful pilot from becoming a production liability.
Launching a model without a monitoring plan is like flying blind. You have no idea when you're drifting off course.
A Lightweight Governance Framework
For a startup, "governance" doesn't have to be bureaucratic. The goal is to define responsibility and success.
- Roles and Responsibilities: Document who owns the model in production, who gets alerts when performance dips, and who is responsible for fixes.
- Ethical and Risk Review: Before deployment, conduct a common-sense check for unintended consequences to protect your users and brand.
- Compliance Documentation: Maintain a document outlining the model’s purpose, data usage, and known limitations.
Monitoring For Model Drift
Models are not static. Over time, the real-world data your model sees will differ from its training data. This is called model drift, and it silently degrades performance. Without monitoring, a model with 95% accuracy at launch can drop to 70% within six months.
Your monitoring should track two signals:
- Data Drift: Are the statistical properties of incoming data changing? A sudden shift in averages, variance, or distributions is a major red flag.
- Concept Drift: Is the relationship between inputs and the correct output changing? For example, in a shifting economy, predictors of customer churn may become irrelevant.
A Practical Monitoring Setup
You can build a powerful monitoring dashboard with open-source tools like Prometheus for metrics collection and Grafana for visualization.
For the fraud detection model example:
- Instrument the Model: Configure the prediction service to export key metrics like latency, confidence scores, and input feature counts.
- Set up Prometheus: Scrape and store these metrics in a time-series database.
- Build a Grafana Dashboard: Visualize precision and recall over time, the distribution of transaction amounts (to spot data drift), and P95 latency.
- Configure Alerts: Set up alerts in Grafana. If the false positive rate spikes by 10% over an hour, the on-call engineer gets a Slack message immediately.
According to the Stanford HAI AI Index Report 2025, legislative mentions of AI have increased significantly. Building compliance and ethical reviews into your process from day one is smart business.
Phase 6: Budget, Talent, and Timelines
A great strategy needs resources. Executing your AI implementation roadmap requires a clear understanding of costs, people, and timelines.
A typical first-year AI pilot budget breaks down into three areas:
- Talent (50-60%): Salaries or contract rates for AI engineers and data scientists. This is your biggest cost.
- Infrastructure (20-30%): Cloud compute (GPU instances) and data storage.
- Tooling (10-20%): Licenses for data labeling, MLOps, and monitoring platforms.
Mapping Timelines From Pilot to Production
Getting from concept to a scaled system is a marathon. A realistic timeline for 2025 breaks down like this:
- Phase 1: Readiness & Strategy (3–8 weeks)
- Phase 2: Pilot Development & Testing (8–16 weeks)
- Phase 3: Initial Scaling & Integration (8–12 weeks)
Plan for a 6 to 18-month journey from idea to widespread impact. Data on AI adoption timelines is available from sources like Statista.com.
From the Field: A common mistake is underestimating the integration and scaling effort. A 12-week pilot is a great start, but hooking that model into other departments' workflows and building robust monitoring can easily take another six months. Budget your time and money accordingly.
Decision Checklist: Full-Time Hires vs. Contractors
For many companies, using contractors for the initial pilot is the smartest move. It lets you test ideas with top talent without the long-term overhead. Once the pilot proves its value, you can build a full-time team with a clear understanding of the roles you need to hire AI engineers.
What to do next
- Scope Your First Pilot: Use the Use Case Scorecard to identify a high-impact, low-risk project you can tackle in the next quarter.
- Assess Your Data Readiness: Schedule a 1-hour workshop with your engineering and product leads to audit the data needed for your top-priority use case.
- Book a Scoping Call: Talk to an expert about your AI goals. A 20-minute call can help you define the scope for a pilot that delivers results in weeks, not months.
Ready to build your AI team? ThirstySprout connects you with the world's top remote AI and ML engineers, vetted for your specific needs. Start a pilot in weeks, not months. Get started with ThirstySprout.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.