
Your team has a prototype in a notebook, a founder who wants results fast, and a backlog full of ideas that all sound “AI-ready.” That's usually where the trouble starts. The first major AI initiative in a startup rarely fails because the team lacks ambition. It fails because scope is fuzzy, data is weaker than expected, ownership is split, and nobody agrees on what “working” means.
That's why AI project management has to be more disciplined than normal feature delivery. You're not just shipping code. You're managing uncertainty across product, data, engineering, operations, and compliance at the same time.
The AI Project Management Flywheel
TL;DR
- Treat AI work as a flywheel, not a linear project plan. Strategy, data, modeling, deployment, and feedback all affect each other.
- Automate admin work, not judgment. Gartner projects that by 2030, 80% of today's project management work will be eliminated by AI, especially routine work like data collection and reporting, according to Planview's summary of Gartner's projection.
- Start with one narrow business problem. Broad “let's add AI” programs waste time.
- Build the team around constraints. Early-stage startups usually need a lean strike team, not a full org chart.
- Data quality decides the ceiling. Most AI plans look good until labeling, schema gaps, or access issues show up.
- Use MLOps early. If the model can't be tested, versioned, deployed, and monitored, it's still an experiment.
- Report in business language. Stakeholders need risk, progress, and decision points, not model jargon.
A founder usually feels the pressure from two sides. Customers expect smarter features, and investors expect a credible AI roadmap. Meanwhile, the internal team is trying to answer basic questions: should you build or buy, hire or contract, start with a copilot or prediction system, ship a pilot or wait for more data?
That's why I prefer a flywheel model. Linear plans assume each phase ends cleanly before the next begins. AI work doesn't behave that way. Data problems change scope. Early model results change priorities. Production feedback changes labeling rules. If your process doesn't expect that loop, you'll call normal iteration a project failure.
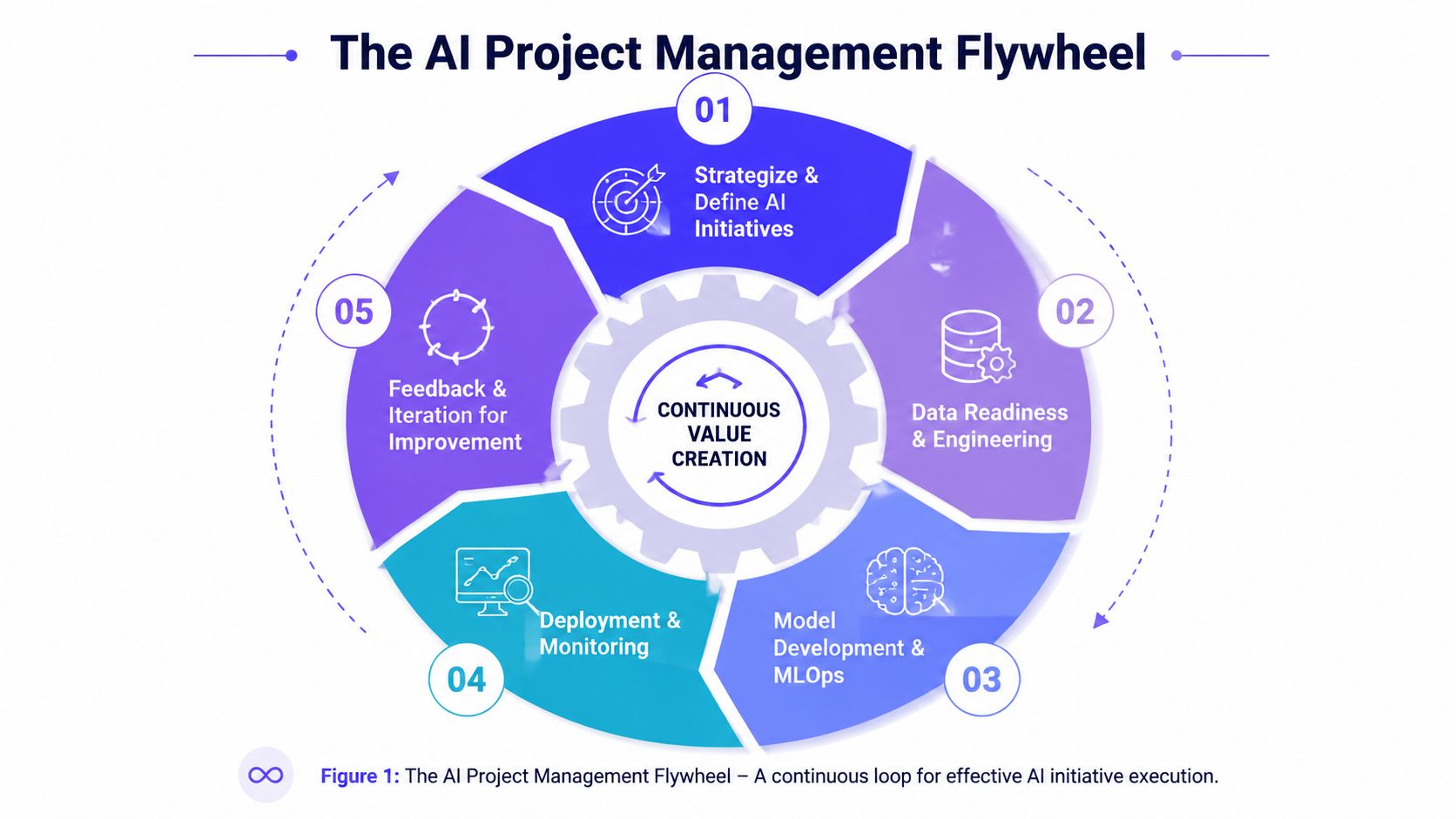
Practical rule: If your AI plan assumes fixed requirements and one clean handoff from product to engineering, the plan is wrong before sprint one starts.
The seven phases that keep the flywheel moving
I use a seven-phase operating model for startup AI project management:
- Frame the business problem
- Define success and guardrails
- Assign owners and staffing
- Audit data readiness
- Run model development with experiment discipline
- Deploy with monitoring and rollback paths
- Feed production learning back into scope
These phases aren't separate departments. They're a management loop. A strong deployment creates better feedback. Better feedback improves data. Better data sharpens the next version of the product.
What changes for startup teams
The management job also shifts. As AI handles more routine coordination work, the human role moves toward prioritization, oversight, and intervention design. You don't need a project manager chasing status updates all day. You need someone who can force hard decisions early, spot weak assumptions, and stop the team from polishing a model nobody can operationalize.
Figure 1: The AI Project Management Flywheel. A continuous loop for effective AI initiative execution.
Defining Scope and Success Metrics
Most startup AI projects begin with a sentence that sounds reasonable and means almost nothing. “We want a recommendation engine.” “We need AI search.” “Let's automate support.” Those are product directions, not scoped AI problems.
Good AI project management starts by turning a vague ambition into a machine-learnable task with a measurable business outcome. That means defining three things together: the decision the model supports, the workflow it changes, and the metric the business cares about.
Start with a one-page problem definition canvas
Use a simple canvas before anyone starts building:
| Field | What to write |
|---|---|
| Business problem | The operational pain, in plain English |
| User decision | The decision the system will support or automate |
| AI task type | Classification, ranking, extraction, generation, forecasting, or anomaly detection |
| Input data | Systems, tables, documents, events, labels |
| Output | Prediction, ranked list, summary, recommendation, alert |
| Human in loop | Where approval, review, or override is required |
| Business success metric | The operational or financial outcome that matters |
| Model metric | The technical measure used during evaluation |
| Failure cost | What happens if the system is wrong |
| Launch boundary | What the first version will not do |
That last line matters more than teams expect. Most first projects fail because they try to solve too many edge cases in version one.
A strong AI charter says what the system will ignore, not just what it will do.
A mini-case on scoping a recommendation engine
An early-stage commerce startup often starts here: “We need AI recommendations to increase conversion.”
That brief is too broad. It mixes product intent, revenue hope, and modeling assumptions. A usable project charter might look more like this:
- Business problem: New and returning users struggle to discover relevant products quickly.
- User decision: Help users choose the next product to view.
- AI task: Rank products for a logged-in user on category and product detail pages.
- Inputs: Product metadata, clickstream events, purchase history, inventory status.
- Output: Top product recommendations shown in two placements only.
- Human review: Merchandising team can pin or suppress products.
- Business metric: Improved engagement with recommended items and better downstream conversion quality.
- Model metric: Ranking quality on held-out interaction data.
- Launch boundary: No home page recommendations, no anonymous user personalization, no cross-device identity stitching in phase one.
That level of clarity is what keeps an AI team from wandering into six side projects.
Separate model success from business success
Many founders frequently encounter this pitfall. A model can improve technically and still fail commercially. If the system creates friction, adds review overhead, or recommends things nobody can fulfill, the project loses.
A PMI-based analysis reported that AI-enhanced project management can raise project success rates by 25% to 35%, with 61% on-time delivery for AI-adopting organizations versus 47% for non-adopters, according to Tommaso Maria Ricci's guide on AI for project management. My read is simple: teams that define success well tend to ship better.
Use two metric layers:
Business metrics
- Workflow impact: Did the user or operator complete the task better?
- Decision quality: Did the recommendation, summary, or prediction improve the actual decision?
- Operational effect: Did this reduce manual effort, delays, or avoidable rework?
Model metrics
- Offline evaluation: How the model performs on held-out data
- Online behavior: How the system performs in the live workflow
- Failure profile: Where the model is predictably weak
If you can't explain both layers on one page, the scope still isn't ready.
Assembling Your AI Strike Team
A startup doesn't need every AI title on day one. It does need clear ownership. Most first projects go off track because everybody is involved and nobody is accountable.
The lean approach is to form a strike team with decision power and narrow scope. The scale-up approach is to specialize earlier, usually because there's more platform complexity, more data surface area, and more deployment risk.
Lean team versus specialized team
For a Seed or Series A startup, a practical team usually looks like this:
- AI product manager or founder proxy: Owns use case, success criteria, and stakeholder alignment
- Data engineer: Handles data access, pipelines, joins, quality checks, and feature availability
- ML engineer: Builds experiments, trains models, evaluates results, and prepares production inference
- CTO or founder: Makes trade-off calls on speed, risk, architecture, and staffing
In a scale-up, these responsibilities often split further:
- Product owner for AI workflow design
- Data platform engineer for ingestion and serving
- ML engineer or applied scientist for modeling
- MLOps engineer for deployment, registry, CI/CD, and monitoring
- Security or compliance partner for regulated use cases
The mistake is copying a larger company's org chart too early. Startups need fewer people with broader range.
When to hire full-time and when not to
Founders often ask whether to hire a full internal team or bring in specialists. The honest answer is phase-dependent.
Use full-time hires when the work is core to the product, touches proprietary workflows, or requires long-term iteration with the rest of engineering. Use fractional experts or contractors when you need help with a bounded issue such as data labeling setup, initial architecture review, MLOps bootstrapping, or vendor evaluation.
A useful operating split looks like this:
| Project need | Better fit |
|---|---|
| Core product logic and roadmap ownership | Full-time internal team |
| Initial model architecture review | Fractional specialist |
| One-time data migration or pipeline setup | Contractor or agency partner |
| Ongoing model tuning tied to product changes | Full-time internal owner |
| Labeling bursts or annotation ops | Managed service or contractor |
If you need help organizing cross-functional handoffs, this guide on cross-functional team building is a useful companion.
Sample RACI Matrix for a Lean AI Project Team
| Activity | AI Product Manager | Data Engineer | ML Engineer | CTO/Founder |
|---|---|---|---|---|
| Define business problem | A | C | C | I |
| Approve success metrics | A | C | C | I |
| Audit source data | C | A | C | I |
| Build training dataset | I | A | C | I |
| Define labeling rules | A | C | R | I |
| Train and evaluate model | C | I | A | I |
| Design production integration | C | R | A | I |
| Set release guardrails | C | C | R | A |
| Stakeholder updates | A | I | C | C |
R means responsible, A means accountable, C means consulted, and I means informed.
If the founder is still resolving annotation disputes, deployment approvals, and metric definitions personally, the team isn't staffed. It's improvising.
Mastering Data Readiness and Labeling
I've seen projects with solid engineers and a sensible use case stall for one reason: the data looked available on paper but wasn't usable in practice. Tables existed. Access didn't. Labels existed. Definitions were inconsistent. Events were logged. Nobody trusted their timestamps.
The core task in AI project management is not “do we have data,” but “can this data support the exact decision we want the model to make?”

The fastest way to fail is to skip the audit
A startup once wanted a churn prediction model. The team assumed product usage logs, billing events, and support history were enough. After kickoff, they found three blocking issues: the churn definition changed across teams, support tags weren't consistent, and historical account merges made user histories unreliable. The project didn't fail because prediction was hard. It failed because the target itself wasn't stable.
Run a data readiness check before model work begins:
- Access and governance: Who can access what, under what approval rules
- Schema reliability: Whether fields mean the same thing over time
- Event integrity: Whether timestamps, identifiers, and joins are trustworthy
- Coverage: Whether the data represents the business cases you care about
- Label feasibility: Whether you can define and produce labels consistently
- Operational freshness: Whether the data arrives fast enough for the intended use
Figure 2: AI Data Readiness Assessment Checklist. Essential steps to prepare your data for successful AI projects.
A practical labeling workflow
Labeling is where startups either get disciplined or get expensive. The common mistake is to hand vague instructions to contractors, then treat disagreement as noise instead of a signal that the problem definition is still weak.
Use a simple workflow:
- Draft labeling rules with examples and edge cases.
- Run a small pilot batch.
- Review disagreements with a domain expert.
- Revise the instructions.
- Lock the rubric and continue.
- Re-sample labeled items for quality checks during the project.
A lightweight scorecard for label quality helps keep this concrete:
| Check | What good looks like |
|---|---|
| Definition clarity | Annotators can explain the rule the same way |
| Edge-case handling | Borderline cases are documented, not guessed |
| Domain fit | Labels match the real business decision |
| Review loop | Disagreements trigger rubric updates |
| Traceability | You can trace each label to a versioned guideline |
Build, outsource, or automate part of it
There isn't one right answer for labeling operations.
- In-house labeling works when the task needs domain expertise from support leads, clinicians, fraud analysts, or operations staff.
- Managed labeling services work when throughput matters more than deep context, and your rules are mature enough to hand off cleanly.
- Programmatic labeling or weak supervision can help when manual labeling is too slow, but you still need humans to validate whether the rules are actually capturing the business concept.
The key trade-off is control versus speed. In-house work gives better context but pulls key people off their day jobs. External help increases throughput but only if your instructions are precise. Programmatic approaches can scale faster, but they also scale hidden assumptions.
Running Model Development and MLOps Pipelines
AI development doesn't behave like ordinary backlog work. A normal software team can estimate a feature because the behavior is largely specified in advance. In AI, the team is testing whether the data can support the behavior at all. That makes model development partly engineering and partly structured experimentation.
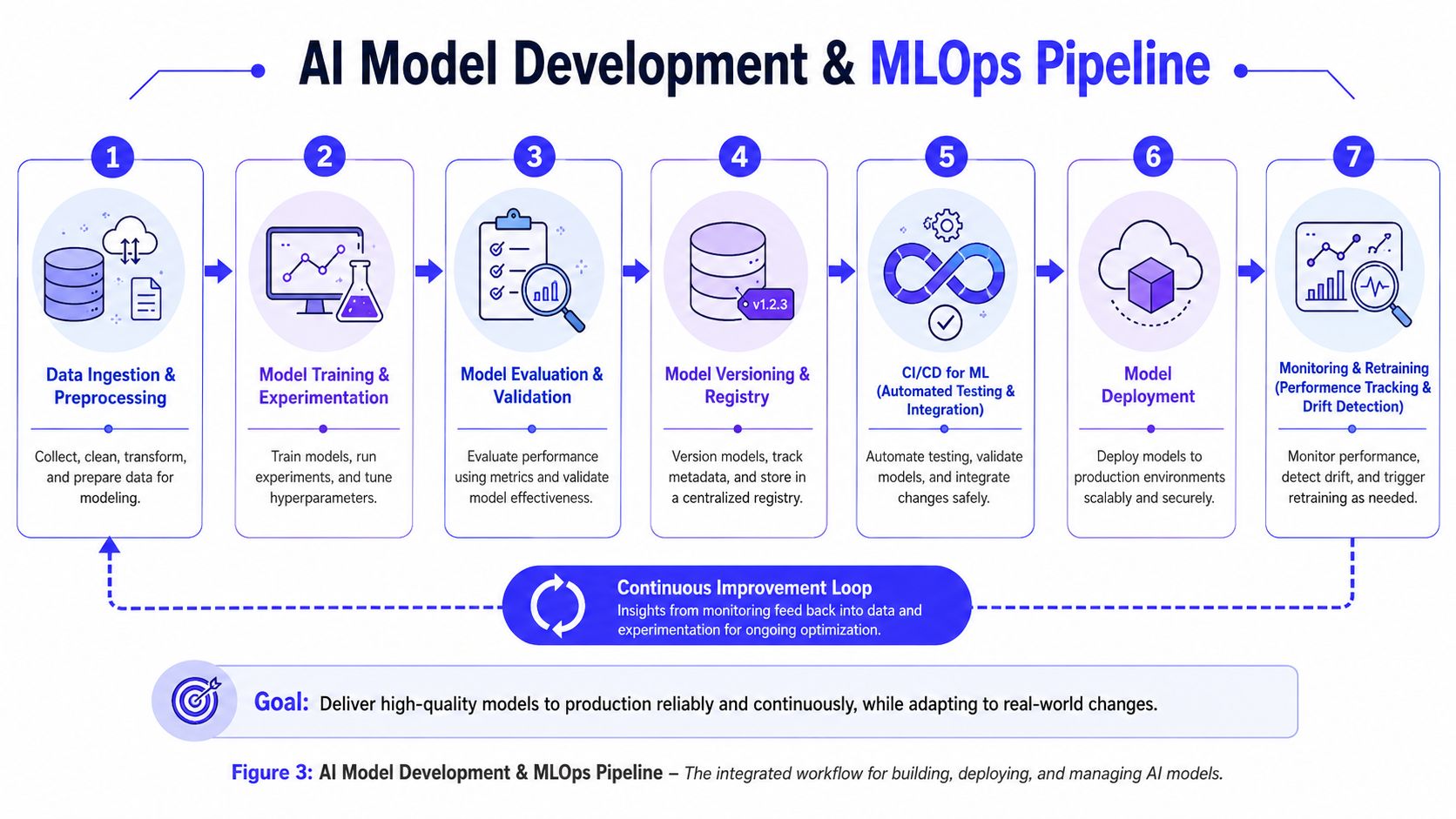
Treat development as experiments with gates
A useful cadence is to run short experiment cycles with explicit checkpoints. Don't ask, “Are we done?” Ask, “Did this experiment reduce enough uncertainty to justify the next one?”
A practical six-week pattern often looks like this:
| Week | Focus |
|---|---|
| 1 | Baseline, data pull, and target definition validation |
| 2 | Feature prep, initial model or prompt experiments |
| 3 | Error analysis and label review |
| 4 | Second-round experiments and integration design |
| 5 | Validation, failure testing, and deployment prep |
| 6 | Limited release and instrumentation review |
That rhythm protects the team from the classic trap of polishing a promising demo while the production path remains undefined.
Don't let a notebook become a roadmap. If the experiment can't survive validation, rollback planning, and runtime constraints, it isn't a product candidate yet.
What MLOps actually changes
Machine Learning Operations, or MLOps, is the layer that makes repeated model delivery possible. It's the difference between one successful experiment and a system the business can trust.
This is the point in the workflow where teams usually gain real efficiency. Industry coverage cited by Invensis Learning on AI in project management reports that AI can increase productivity by up to 40%, reduce project duration by up to 30%, and produce average cost savings of 20%. In practice, much of that gain comes from making testing, deployment, and monitoring repeatable instead of manual.
Figure 3: AI Model Development and MLOps Pipeline. The integrated workflow for building, deploying, and managing AI models.
Here's a useful primer if your team is still building that muscle: DevOps for machine learning.
Later in the pipeline, this walkthrough is worth watching:
The minimum pipeline a startup should have
You don't need enterprise tooling on day one. You do need discipline in a few places:
- Experiment tracking: Record dataset version, parameters, outputs, and notes so results are reproducible.
- Model registry: Store approved versions with metadata and release status.
- Automated tests: Check data schema, inference behavior, and integration compatibility before release.
- Deployment workflow: Move models to production through a repeatable path, not ad hoc scripts.
- Monitoring: Watch prediction quality, latency, failures, and drift signals.
- Retraining trigger: Define when a model should be updated and who approves it.
That last point is where startups often under-invest. Continuous training doesn't mean constant retraining. It means having a controlled process for deciding when new data justifies a new version.
A mini-case on shipping from notebook to service
Take a support triage model as an example. The first notebook may classify inbound tickets reasonably well on historical data. But production introduces new demands: malformed payloads, missing fields, low-confidence predictions, and category drift when support policy changes.
A production-ready version adds:
- Input validation before inference
- Confidence thresholds with fallback to human routing
- Versioned prompts or models
- Audit logs for predictions and overrides
- A monitoring view that flags changing ticket distributions
That's why AI project management has to own both the science loop and the operating loop. If you only manage experimentation, the team creates interesting artifacts. If you only manage delivery, the team ships brittle systems.
Managing Risk and Communicating with Stakeholders
This is the part founders tend to underrate because it feels less technical. It's also where trust is won or lost.
PMI reports that 49% of professionals have little to no experience with or understanding of AI in project management, according to PMI's thought leadership on shaping the future of project management with AI. In other words, many of the people approving budget, reviewing timelines, or reacting to project risk may not have a strong mental model for how AI work behaves. If you don't communicate clearly, they'll fill the gaps with either hype or fear.
Use a stakeholder update that avoids jargon
A monthly AI update should fit on one page. It should answer five questions:
- What changed: New experiment result, deployment milestone, or risk discovered
- What it means for the business: Workflow impact, launch implication, or decision required
- Where risk sits now: Data quality, privacy, bias, reliability, security, or vendor dependency
- What happens next: The next milestone and owner
- What leadership needs to decide: Scope cut, budget approval, policy review, or staffing change
That format keeps the conversation grounded. It stops the team from hiding behind technical detail when the actual issue is that a dependency is blocked or the use case needs to narrow.
A calm stakeholder update is a risk control tool. It turns vague concern into explicit decisions.
Keep a lightweight AI risk register
You don't need a giant governance process for every startup project. You do need a visible risk register with owners. Track items such as:
| Risk area | What to document |
|---|---|
| Data privacy | Sensitive fields, access controls, retention rules |
| Model behavior | Known failure modes and fallback path |
| Security | Exposure points, third-party dependencies, approval gates |
| Bias and fairness | Where outcomes need review by humans |
| Operations | Monitoring gaps, rollback process, alert ownership |
| Compliance | Legal or industry rules that affect deployment |
For higher-stakes environments, you'll want stronger controls around auditability, approval paths, and model oversight. This guide on AI governance best practices is a good starting point.
Set expectations before the first demo
The worst stakeholder pattern is early overconfidence followed by late surprise. Avoid that by stating three things early:
- What the first release is meant to prove
- What classes of errors are expected
- Where a human will still review, approve, or override
That's how you keep an AI initiative from turning into a science project on one side or a political problem on the other.
Your AI Project Launch Kit
A startup doesn't need a massive AI transformation plan. It needs a clear launch kit. If the team can answer the right questions before kickoff, the odds of a useful first release go up fast.
Use this as a pre-flight checklist:
- Problem clarity: Is the AI task tied to a real business workflow?
- Success definition: Do business and model metrics both exist?
- Team ownership: Does every critical activity have one accountable owner?
- Data readiness: Can the team access, trust, label, and operationalize the data?
- MLOps path: Can the model be versioned, tested, deployed, monitored, and rolled back?
- Risk controls: Are privacy, security, and human approval points explicit?
- Feedback loop: Is there a plan to learn from production and iterate?
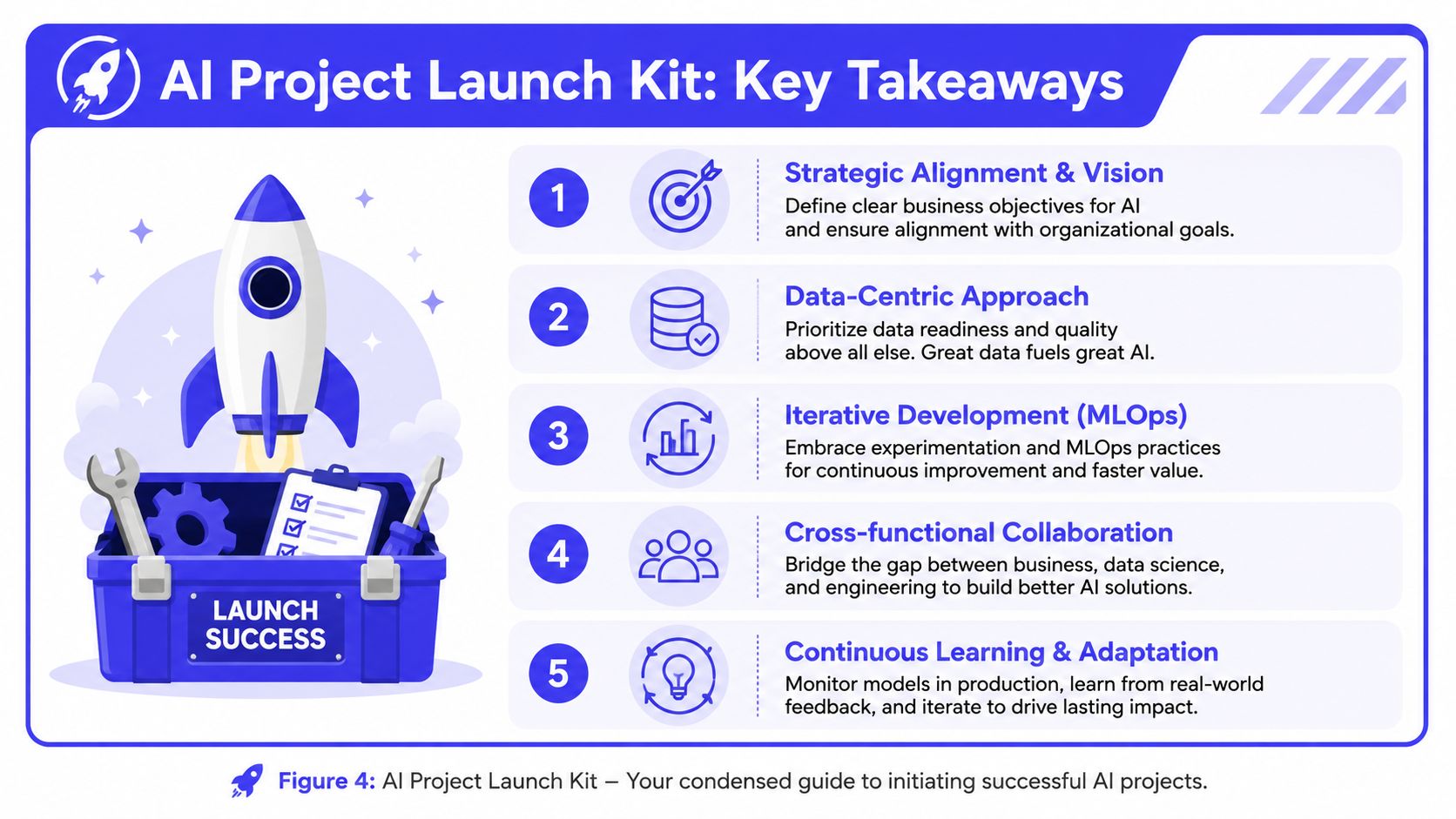
Figure 4: AI Project Launch Kit. Your condensed guide to initiating successful AI projects.
If you're about to start your first major AI initiative, do three things next:
- Score your current project against the checklist above.
- Identify the weakest area. It's usually scope, data, or ownership.
- Decide whether your gap is best solved by hiring, fractional support, or a short pilot with a tightly scoped use case.
AI project management works best when it stays boring in the right places. Clear scope. Clean ownership. Reliable data. Repeatable delivery. Honest reporting. That's what turns AI from an internal experiment into an operating capability.
If you're planning an AI build and want a faster path from idea to a staffed, workable pilot, ThirstySprout helps startups hire vetted AI engineers, ML talent, MLOps specialists, and AI product experts who've shipped production systems. You can Start a Pilot, validate your scope with the right team shape, and See Sample Profiles for experts who can plug into your stack and timeline.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.