
Your team has a model that looked strong in a notebook. It passed offline evaluation, made it through demo day, and now sits behind a customer-facing feature. Then support tickets start. Predictions drift. Product asks whether the issue came from new user behavior, a broken feature pipeline, a dependency change, or the model itself. Nobody can answer quickly.
That's the core problem behind devops for machine learning. Production ML fails less often from one dramatic event and more often from weak operating discipline. If your team can't reproduce training inputs, trace model lineage, monitor live behavior, and roll back safely, you don't have a productized ML system. You have a fragile experiment with an API.
TL;DR
- DevOps for machine learning means applying release discipline, observability, and automation to code, data, models, and environments.
- MLOps is the operational practice. DataOps covers the data lifecycle that is often under-invested in.
- Start with five patterns: CI/CD for ML, artifact versioning, reproducible infrastructure, production monitoring, and retraining triggers.
- Tooling matters, but team design matters more. Clear handoffs are essential between data engineering, ML engineering, and platform or MLOps ownership.
- If you're hiring, prioritize people who've debugged production failures, not just trained strong models.
The Production Gap Why Your ML Model Is Not a Product
A software feature usually fails in ways your engineering team already understands. A machine learning feature fails in more ambiguous ways. The endpoint is up, latency is normal, and logs look clean, yet business output degrades because the world changed faster than the training set.
That gap is why ad hoc deployment breaks down. A model artifact alone isn't the product. The product is the full operating system around it: feature generation, validation, registry, deployment controls, live monitoring, rollback, and retraining policy.
Traditional DevOps already solved part of this problem for software teams. According to an industry DevOps roundup, 77% of organizations use DevOps practices, and companies adopting DevOps saw a 68% reduction in deployment failures. That matters because ML systems depend on the same release discipline, deployment hygiene, and operational feedback loops.
What usually goes wrong first
In practice, the first production break often looks boring:
- A data schema changes and a feature arrives with a new null pattern.
- A batch job runs late and the model serves stale features.
- A dependency update lands and inference output shifts slightly.
- A retrain job succeeds technically but promotes a model trained on misaligned data.
Practical rule: If your team can't answer “what data, code, and environment produced this prediction?” within minutes, your ML stack isn't production-grade yet.
The business issue is operational uncertainty
CTOs rarely need another model benchmark. They need fewer incidents, faster root-cause analysis, and predictable delivery. DevOps for machine learning gives you that only when you treat ML as an operational system, not a research output.
DevOps for ML MLOps and DataOps Explained
The terminology gets sloppy fast, so it helps to be precise.
DevOps for machine learning is the broad operating philosophy. It applies DevOps ideas to the full ML lifecycle. MLOps is the implementation layer focused on training, packaging, deployment, monitoring, and model governance. DataOps focuses on the upstream data lifecycle: ingestion, transformation, quality checks, lineage, and dataset reliability.
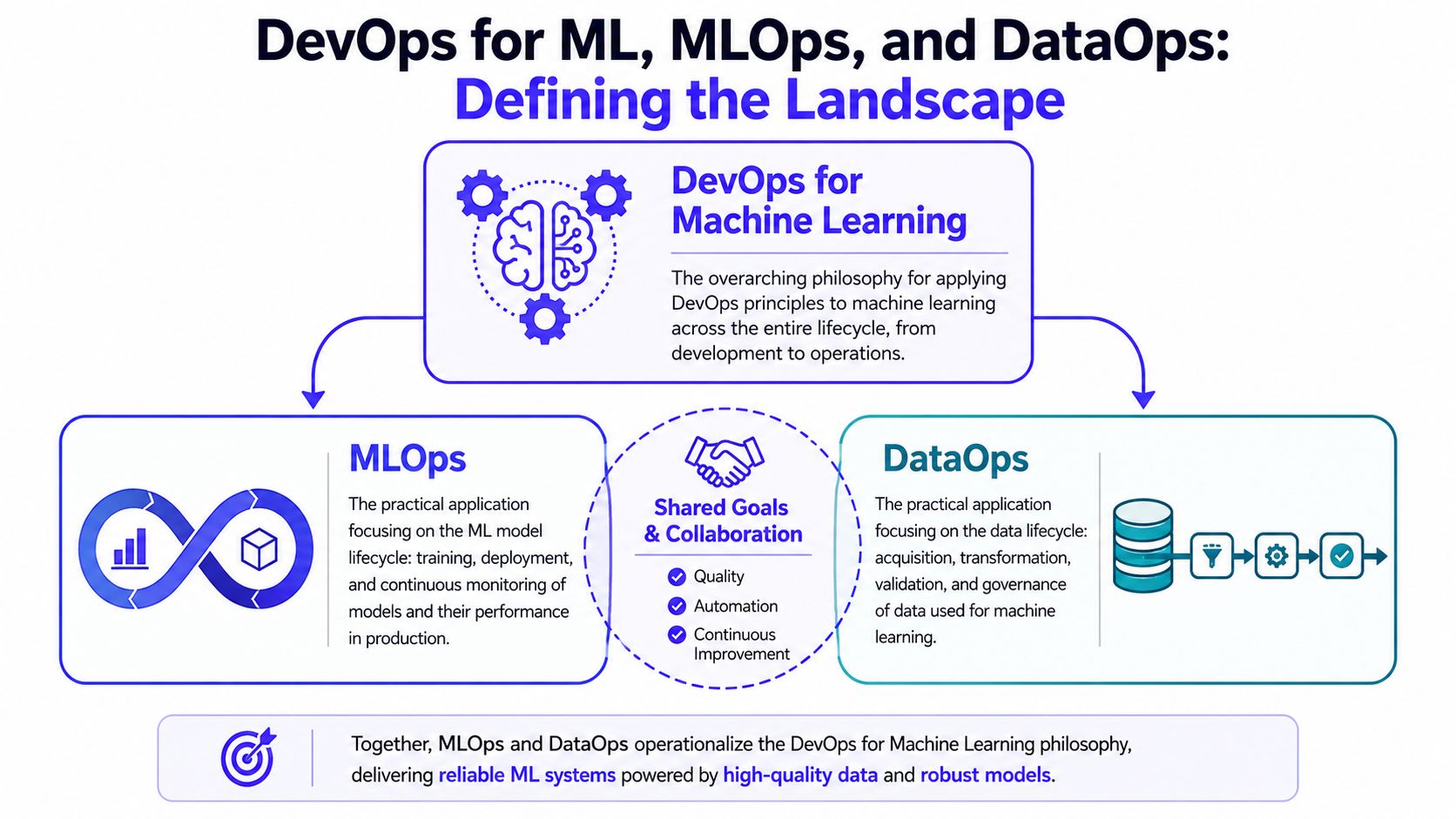
This concept map clarifies the core terminology used in bringing engineering rigor to machine learning, differentiating the overarching philosophy from its practical implementations focusing on models and data.
The key distinction from standard DevOps
The biggest shift is this. In software delivery, code is usually the primary artifact. In ML, data, models, and environments must also be treated as first-class versioned artifacts.
The MLOps principles published by ml-ops.org make that distinction explicit. MLOps extends DevOps by versioning data, models, and environments so teams can determine whether performance loss came from code, data, or runtime differences instead of treating the model as a black box.
A CTO should care because this changes what “done” means. A feature isn't done when a model endpoint responds. It's done when your team can reproduce training, promote models safely, and investigate failures without guesswork.
A simple operating model
Think of the responsibilities like this:
| Practice | Main concern | Failure if missing |
|---|---|---|
| DevOps for ML | Overall delivery and operations philosophy | Teams ship disconnected components |
| MLOps | Model lifecycle and production controls | Models deploy, but degrade silently |
| DataOps | Data quality, lineage, and change control | Good models fail on bad or shifted data |
Strong ML organizations don't separate model operations from data operations. They connect them under one release and observability discipline.
The Five Core MLOps Patterns
Many teams don't need a massive platform on day one. They need a handful of patterns implemented well. These are the ones that matter most.
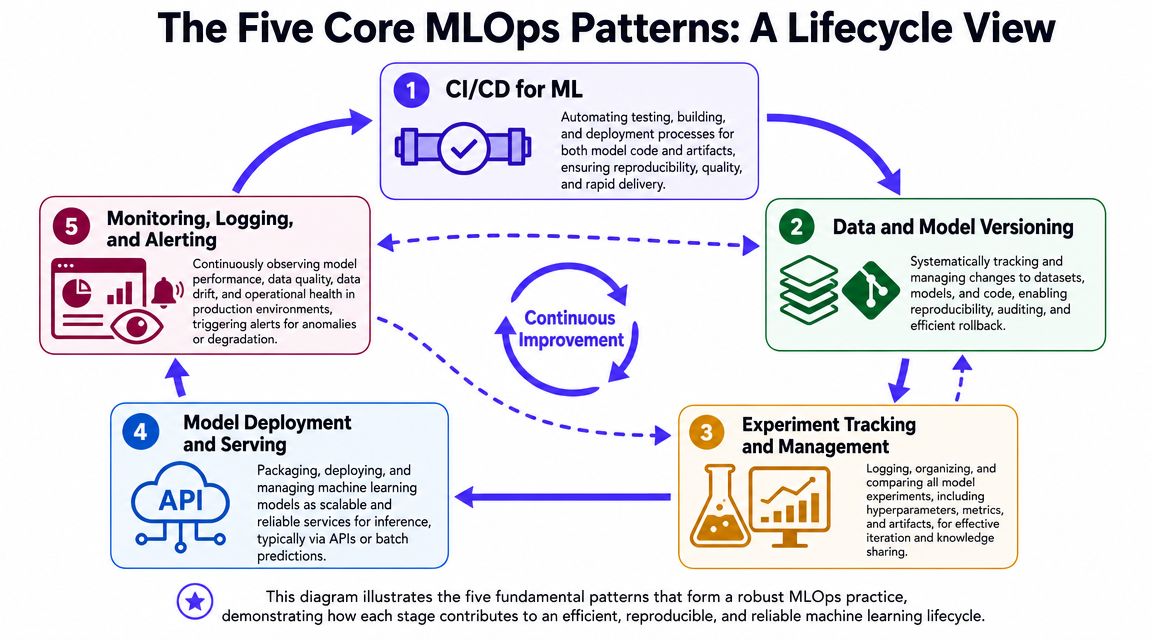
This diagram illustrates the five fundamental patterns that form a sound MLOps practice, demonstrating how each stage contributes to an efficient, reproducible, and reliable machine learning lifecycle.
CI and CD for ML
CI/CD for ML isn't just unit tests plus a Docker build. You need tests for data assumptions, feature logic, training code, packaging, and promotion gates.
A practical release flow might look like this:
- Validate data contracts before training starts.
- Run training pipeline with tracked parameters and artifacts.
- Evaluate candidate model against a held-out set and deployment policy.
- Register approved artifact in a model registry.
- Promote to staging or canary with rollback ready.
Mini example
A GitHub Actions or GitLab CI job for ML usually includes checks like:
- Schema validation: fail the run if expected columns or types changed.
- Training smoke test: ensure the pipeline can complete on a sample.
- Inference contract test: confirm request and response schemas still match the application.
Data and model versioning
Git alone won't solve reproducibility. Large datasets, generated features, trained weights, and metadata need separate lineage controls.
Use a pattern that records:
- Dataset snapshot or timestamp
- Feature logic version
- Training code commit
- Model artifact version
- Runtime image or dependency lockfile
That record lets your team answer the hard question during incidents: did the model degrade because of code, data, or environment drift?
Infrastructure as code and reproducible environments
A notebook environment that “works on one GPU box” is not an operating model. Use Terraform, Pulumi, or cloud-native templates to define the infrastructure around training and serving. Use containers for training and inference so teams stop debating which library version produced the last model.
Mini example
A lean setup often starts with:
- Terraform for cloud resources
- Docker for training and inference images
- Kubernetes or managed endpoints for deployment targets
- Secrets manager for credentials instead of local config files
Monitoring and observability
Application uptime is necessary, but it's not enough. Production ML needs monitoring for model behavior and input quality.
AWS describes continuous monitoring in MLOps as tracking both data and model metrics, while continuous training retrains models after system changes. The practical implication is important: retraining should react to production signals such as input drift or accuracy degradation, not just fixed schedules.
A useful alerting policy usually includes:
- Feature distribution shifts
- Missing or delayed upstream data
- Prediction score anomalies
- Business KPI degradation tied to model output
- Validation gate failures before promotion
Here's a short walkthrough that complements this lifecycle view:
Automated retraining and feedback loops
Not every model should retrain automatically. Some domains need approval steps, especially in regulated workflows. But every production ML system should at least define when retraining is triggered, how it's validated, and who can approve promotion.
Retraining without validation is just automated risk.
For many teams, the right compromise is event-driven retraining with manual approval for promotion to production.
Example Reference Architecture and Tool Landscape
A useful architecture for devops for machine learning should be boring in the right places. Clear stages. Clear owners. Clear interfaces. Teams often encounter difficulties when mixing experimentation, batch processing, online serving, and monitoring into one opaque workflow.
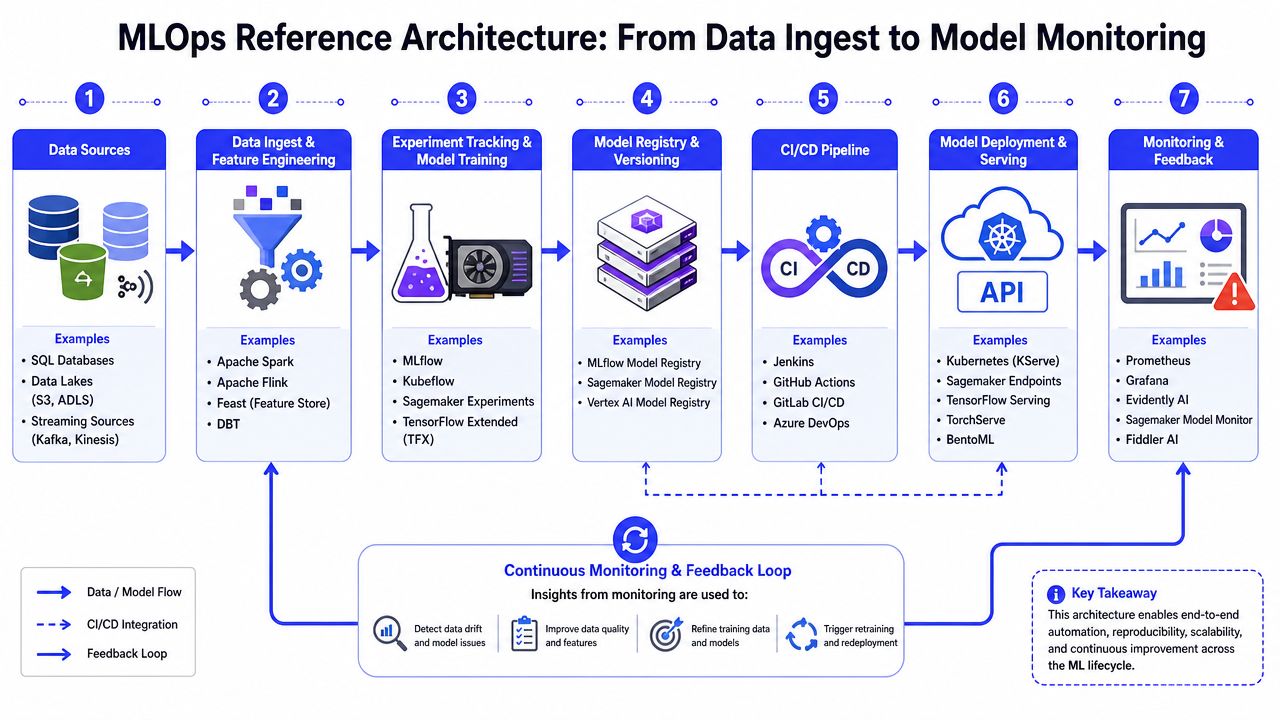
This reference architecture provides a concrete visual representation of an MLOps pipeline, detailing the key components and demonstrating how various tools fit together to manage the machine learning lifecycle effectively.
A practical stack by function
The market is crowded because demand is real. One industry DevOps summary reports that 70% of leading enterprises have integrated AI and machine learning into their DevOps pipelines, and projects the broader DevOps market to reach USD 108.26 billion by 2035. More tools doesn't mean more clarity, so choose by operating need, not feature list.
Here's a working way to evaluate categories:
| Category | Good default choice | When it fits | Main trade-off |
|---|---|---|---|
| Orchestration | Airflow | Strong for batch workflows and broad team familiarity | Less ML-native metadata than dedicated ML pipelines |
| Orchestration | Kubeflow Pipelines | Better when training and deployment are deeply Kubernetes-centric | More platform overhead |
| Experiment tracking | MLflow | Good default for teams that want open components | You own more integration details |
| Experiment tracking | Weights & Biases | Strong UX for experiment comparison and collaboration | More platform dependence |
| Serving | KServe on Kubernetes | Fits platform teams already running Kubernetes | Higher ops burden |
| Serving | Managed cloud endpoints | Faster path when you value speed over control | More vendor lock-in |
What works in early-stage teams
If you're building your first serious production setup, don't assemble every category at once. Start with a narrow path from training to deployment to monitoring.
A practical starter stack often looks like:
- Data transforms: dbt or Spark
- Experiment tracking and registry: MLflow
- CI/CD: GitHub Actions, GitLab CI/CD, or Azure DevOps
- Serving: managed cloud endpoint first, Kubernetes later if needed
- Monitoring: Prometheus and Grafana for service health, plus a model-focused layer
If you're comparing deployment options in more depth, this guide to machine learning model deployment tools is useful because it frames choices by deployment context rather than by vendor marketing.
Mini case on tool selection
A SaaS company shipping batch scoring for churn risk usually doesn't need Kubeflow on day one. Airflow, MLflow, a registry, and a scheduled validation-plus-promotion flow are often enough.
A platform team supporting multiple product squads with real-time inference may justify Kubernetes-native serving, stronger model registry workflows, and centralized monitoring earlier because the cost of inconsistency across teams is higher.
How to Structure and Hire Your MLOps Team
Most MLOps failures look like tool failures from a distance. Up close, they're ownership failures. The model team assumes platform owns deployment. Platform assumes data engineering owns feature reliability. Data engineering assumes ML owns training-serving consistency. The gaps sit in the handoffs.
The core roles and where they differ
You don't need a huge org chart. You do need clear boundaries.
- Data Engineer: owns ingestion, transformation, data quality checks, and reliable feature pipelines.
- ML Engineer: owns feature logic, training code, evaluation, and inference integration.
- MLOps Engineer or Platform ML Engineer: owns automation, registries, deployment paths, environment reproducibility, monitoring, and rollback strategy.
A conventional DevOps engineer can help early on, especially if the first workload is simple batch inference. But once your team operates more than one meaningful ML service, a dedicated MLOps owner becomes valuable because the failure modes are different from standard app delivery.
Mini case on handoffs that work
A fintech team building transaction-risk scoring can split work like this:
| Role | Primary output | Key handoff |
|---|---|---|
| Data Engineer | Trusted event pipeline and feature tables | Delivers validated training and serving inputs |
| ML Engineer | Trained model and evaluation package | Delivers candidate model plus expected data contract |
| MLOps Engineer | CI/CD, registry, serving, monitoring, rollback path | Promotes and governs production release |
That structure prevents the classic argument where everyone touched the system but nobody owns the production behavior.
Hire for operational scars. Ask candidates about a broken pipeline, a drifting model, or a failed deployment they had to unwind.
When to hire dedicated MLOps talent
Make the first dedicated hire when any of these become true:
- Your ML systems affect customer-facing workflows
- You have repeated retraining or release cycles
- More than one team depends on the same model platform
- Your incidents are hard to debug because ownership is fragmented
For hiring context, LatoJobs' data science market report is a useful read because it shows how demand is shifting toward production-oriented ML work rather than purely research-heavy roles.
If you're filling delivery gaps quickly, this page on hiring machine learning engineers helps separate platform-minded ML builders from candidates who've mostly worked in notebooks.
Interview questions that reveal real experience
Try questions like these:
- A model's business performance drops, but service health looks normal. How do you isolate whether the cause is data drift, code change, or environment drift?
- Describe the release path you'd design for a retrained model. Where do you put validation gates and rollback controls?
- How would you prevent training-serving skew when separate teams own feature generation and deployment?
Good candidates answer with systems, not buzzwords.
Common Pitfalls and Your Migration Checklist
The most common MLOps mistake is also the most expensive. Teams over-focus on model deployment and under-manage changing data. That's backwards.
The AltexSoft overview of MLOps methods and tools calls out this blind spot clearly: many resources focus on CI/CD for models but offer little guidance on dataset versioning or training-serving skew, even though some of the hardest production failures come from changing data, not changing code.
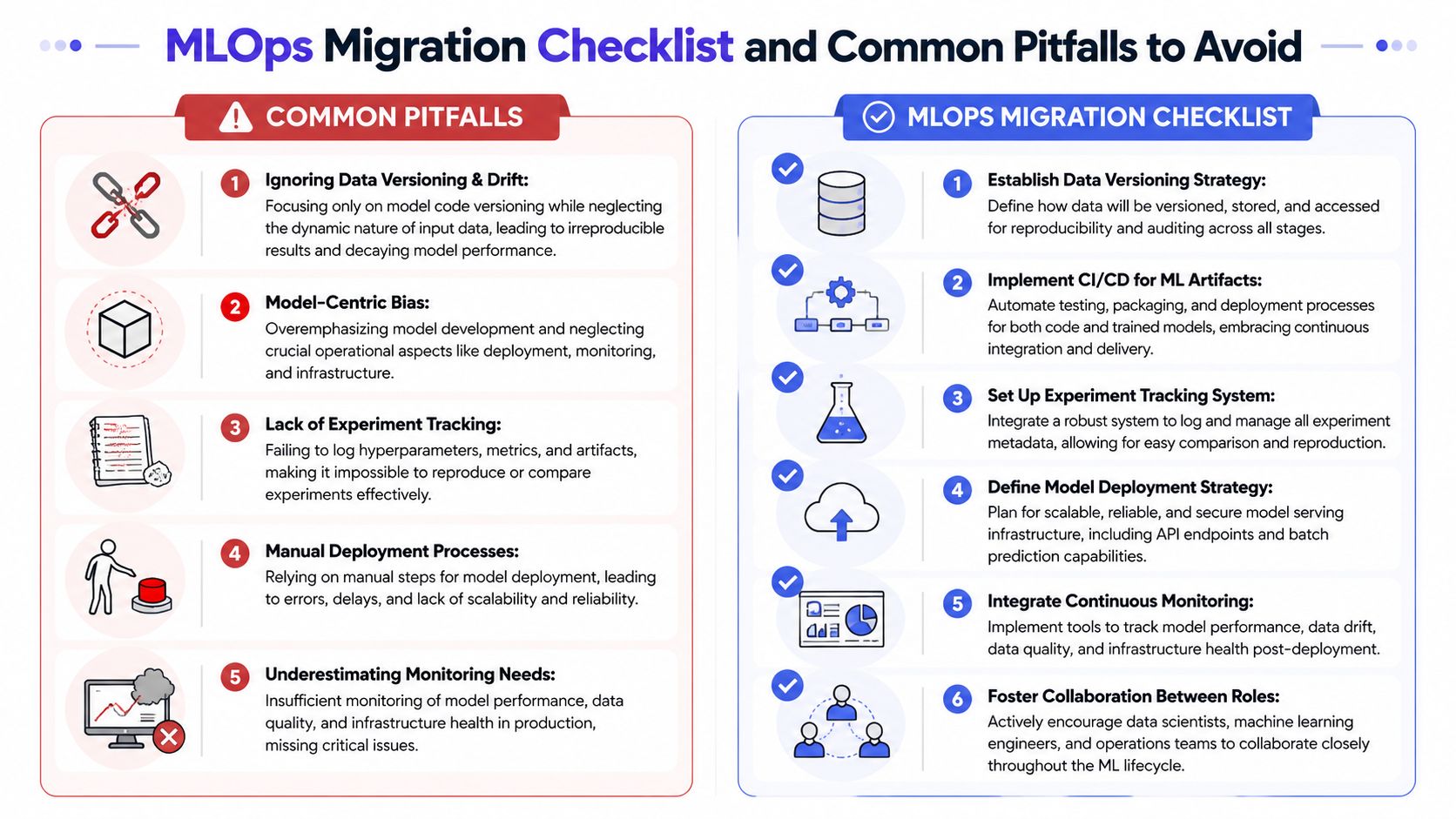
This infographic highlights key pitfalls to avoid when implementing MLOps and provides actionable steps for organizations to successfully migrate towards a more reliable and automated machine learning operational pipeline.
What breaks teams during migration
Three patterns show up repeatedly.
First, teams buy a platform before they define a release process. The result is expensive tooling layered on top of unclear ownership.
Second, they track models but not datasets. That gives a false sense of reproducibility.
Third, they monitor API uptime but not feature quality or prediction behavior. The service looks healthy while the ML outcome decays.
A practical maturity checklist
Use this as a working scorecard with your engineering lead, data lead, and product owner.
- Reproducibility: Can you reconstruct the exact training data, code version, model artifact, and runtime image used for a production model?
- Release control: Do you have automated validation gates before a model reaches production?
- Monitoring: Are you tracking both service metrics and model or data metrics in production?
- Retraining policy: Are retraining triggers defined by production signals, not just calendar schedules?
- Ownership: Can each pipeline stage be mapped to a named team or role?
- Data change management: Do you detect schema changes, feature breakage, and training-serving skew early?
The migration usually stalls where data ownership is vague. Fix ownership before you add another tool.
If you want a more detailed operating standard, these MLOps best practices are a useful companion for turning the checklist into team policy.
What to Do Next Scaling ML with Expert Talent
There are three realistic options.
Build means hiring a full internal team. That gives you long-term control, but hiring takes time and early architecture mistakes are expensive.
Buy means adopting a managed platform. That can speed up deployment and standardization, but it can also lock your operating model to one vendor's assumptions.
Partner means bringing in senior people who've already shipped production ML systems and can work inside your stack. That's often the fastest path when you need to stand up release discipline, observability, and team workflows without pausing product delivery.
The right choice depends on your stage.
- Early product teams usually need a small, senior group that can design the first reliable path from data to serving.
- Growth-stage teams often need platform standardization and stronger role definition.
- Larger organizations need governance, shared tooling, and clearer boundaries across data, platform, and ML teams.
For many companies, the best near-term move is simple: pick one production ML workflow, assign clear owners, implement versioning and monitoring, and test the release path end to end before expanding.
If you need to stand up devops for machine learning without a long hiring cycle, ThirstySprout can help you start a pilot with senior MLOps, ML, and data engineering talent who've shipped production systems. That gives you a practical way to validate the architecture, fill skill gaps, and move from prototype to reliable delivery.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.