
Your data pipeline probably isn't failing because your model team picked the wrong embedding size. It's failing because the ingestion layer is brittle. Requests get blocked, regions return different results, test traffic pollutes production assumptions, and nobody owns the edge where outside data enters your stack.
That's where a Proxy Server API stops being a scraping detail and becomes an architecture decision. If your AI roadmap depends on public web data, external APIs, competitor monitoring, or regional product testing, the proxy layer sits in the same category as your message bus, feature store, and observability stack. Treat it casually, and the rest of the system inherits that fragility.
Why Your AI Team Needs a Proxy Server API Strategy
If you're a CTO, Head of Engineering, or platform lead, the practical question isn't “what is a proxy.” It's whether your team can trust the data entering training jobs, evaluation runs, and market intelligence workflows.
A Proxy Server API gives your systems a controlled intermediary for outbound and inbound API traffic. In AI teams, that usually shows up in three places: collecting public web data, testing AI products from different geographies, and shielding internal services behind a policy layer.
The market signal here is already clear. As of the 2025 annual research era, the market for Web Data APIs used in AI training and deployment benchmarks includes 13 major proxy server providers, which points to a fragmented but standardized infrastructure layer in the AI supply chain, according to Proxyway benchmark coverage on Newswire.
TLDR for engineering leaders
- Use a proxy strategy when external data matters. If your models, alerts, or product experiments rely on public web data, you need a managed edge for routing, identity, and policy enforcement.
- Design for statelessness first. Stateful proxy behavior becomes an operational tax when traffic patterns change.
- Separate business need from proxy type. Scraping, geo-testing, and API protection are different workloads. They shouldn't share the same assumptions.
- Treat proxy selection like infrastructure procurement. Reliability, observability, and compliance matter more than getting requests through on day one.
- Review policy and ownership early. Teams that already work through AI governance best practices usually make cleaner decisions about data provenance, rate control, and vendor risk.
For leaders working through broader platform planning, this also fits into the larger question of strategic AI for business growth. The data edge isn't separate from product strategy. It determines whether your AI systems get timely, representative inputs or stale, biased, and operationally expensive ones.
Practical rule: If a pipeline depends on external web data and nobody can explain how requests are routed, throttled, authenticated, and audited, you don't have a data pipeline. You have a liability.
A Framework for Deciding on a Proxy Server API
A common pitfall is to start with the wrong question. They ask which proxy vendor is best. The better question is what failure mode you're trying to remove.
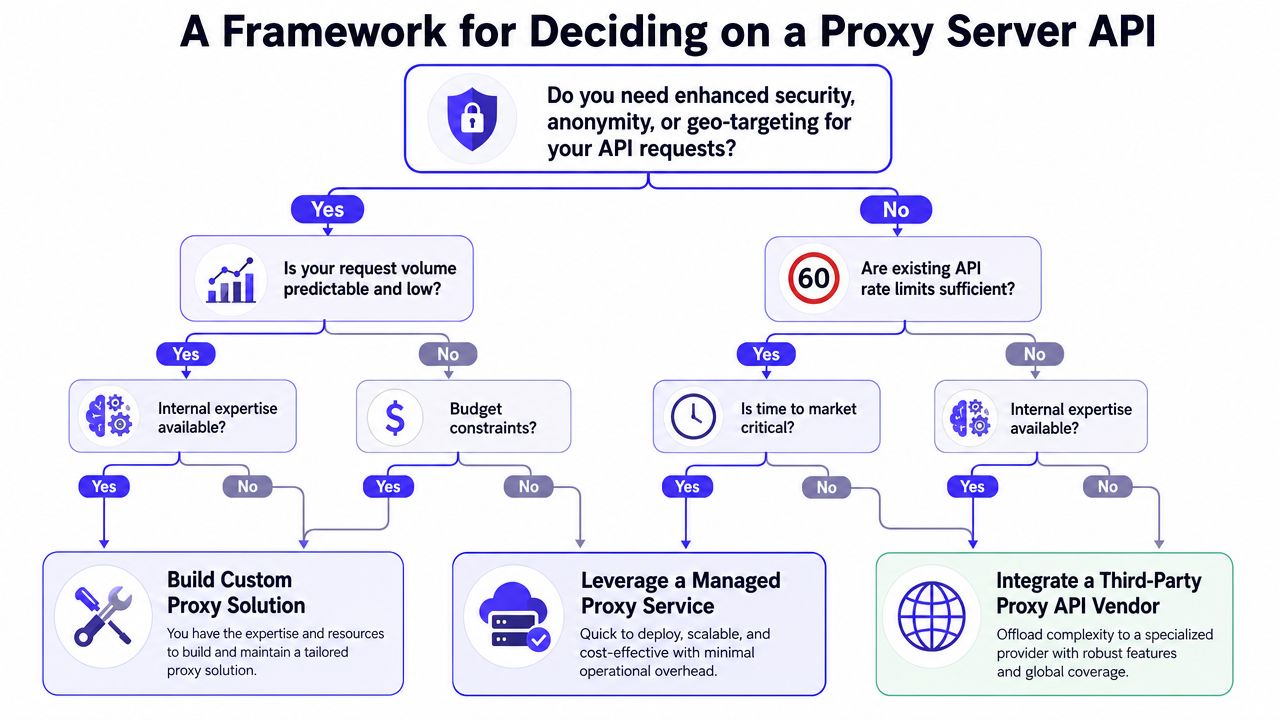
The selection mistake is common enough that it shows up in hard outcomes. A 2025 Bright Data study found that 42% of scraping projects fail due to poor proxy selection, and residential proxies outperformed data center proxies in 73% of geo-targeted tasks, as cited in Shifter's discussion of proxy provider questions.
Start with the business job
Use this decision sequence.
Training data ingestion
- You're collecting public product pages, reviews, job listings, news, or catalog data.
- The core risk is inconsistent retrieval and blocked requests.
- Decision bias: favor vendors or architectures that support rotation, request policy control, and strong observability.
AI product testing
- You need to see what users in different regions experience.
- The core risk is false confidence from tests that only reflect one geography or one network profile.
- Decision bias: prioritize geo-targeting and stable request routing.
Market intelligence
- You're monitoring competitor pricing, assortment, ranking, or public changes over time.
- The core risk is false data, not just failed data.
- Decision bias: prefer systems that let you validate response consistency and annotate provenance.
Security boundary for internal APIs
- You want a front door for authentication, rate limiting, and backend shielding.
- The core risk is exposing services directly and scattering policy logic across apps.
- Decision bias: a custom reverse proxy or API gateway pattern may fit better than a scraping-focused provider.
- Can your current stack tolerate request variance? If not, build validation into the proxy path.
- Does the team need regional realism or just throughput? Those are different procurement decisions.
- Who owns vendor risk and traffic policy? If the answer is “nobody yet,” don't scale usage.
- Is time to market more important than bespoke controls? Early-stage teams often gain more from managed services than from building edge plumbing themselves.
- Request router that maps incoming paths or parameters to target endpoints
- Authentication layer for API keys, bearer tokens, OAuth, or internal service identity
- Rate limiter to protect your backend or external quotas
- Cache to reduce repetitive fetches
- Transformation logic for headers, payload formats, or field normalization
- Logging and monitoring so teams can audit behavior and troubleshoot failures
- the transformation is cross-cutting,
- multiple consumers need the same shape,
- and you want one audit point for schema changes.
- transformations are model-specific,
- business logic changes frequently,
- or the proxy would become a hidden application server.
- Credentials stay out of source code because the API key comes from environment variables.
- The worker sends intent, not network instructions. It says which page it wants and which region matters.
- Error handling stays explicit. Retry policy should be deliberate, not hidden inside a helper nobody revisits.
- Authentication enforcement for client identity before requests hit backend systems
- Rate limiting so one consumer or one bug doesn't overwhelm the platform
- Request filtering to block malformed or obviously malicious traffic
- Backend shielding so internal services aren't exposed directly
- responses are reused across consumers,
- freshness can be defined clearly,
- and you can invalidate safely.
- content is highly dynamic,
- stale results would poison model evaluation,
- or consumers depend on exact point-in-time responses.
- Structured logs
Include request identifiers, target classification, auth outcome, policy outcome, and latency. - Clear ownership
One team needs authority over routing rules, credentials, and escalation. - Key management
Centralize and encrypt downstream credentials rather than letting applications hold direct service keys. - Rate policies by consumer
Different clients need different limits. One global cap is crude and usually painful. - Monitoring for bad data
Availability metrics alone aren't enough. You also need signals for response drift and unexpected payload shapes. - Embedding proxy logic in every service. This creates policy drift and duplicate code.
- Letting application teams bypass the proxy “temporarily.” Temporary network shortcuts tend to become permanent.
- Treating observability as optional. You can't debug false data with only uptime checks.
- Using one proxy pattern for every use case. Scraping, internal API security, and geo-testing have different priorities.
- What part of the problem is strategic? If IP management isn't differentiating your business, buying is often rational.
- Who will run this at 2 a.m.? Ownership is the hidden line item in every build decision.
- How much policy variation do teams need? Central standards are good. Total rigidity usually isn't.
- Can you audit data provenance? For AI use cases, this matters as much as uptime.
- Will this choice still work when more teams adopt it? Local optimizations break fast once a platform becomes shared infrastructure.
Then choose the operating model
A simple matrix helps.
| Situation | Better fit | Why |
|---|---|---|
| Fast launch, limited infra team | Managed proxy service | You offload rotation, operational support, and part of the network edge |
| Tight product-specific rules, strong platform team | Custom proxy layer | You control transformation, auth, routing, and logging deeply |
| Mixed use cases across teams | Third-party proxy API vendor plus internal gateway | Vendor handles network access, your platform handles policy and normalization |
Questions that expose the right answer
Teams usually don't regret paying for the right proxy layer. They regret letting application engineers debug network behavior at midnight.
Proxy Server API Architecture Patterns
A good proxy architecture doesn't just forward traffic. It creates a stable contract between your clients and volatile external systems.
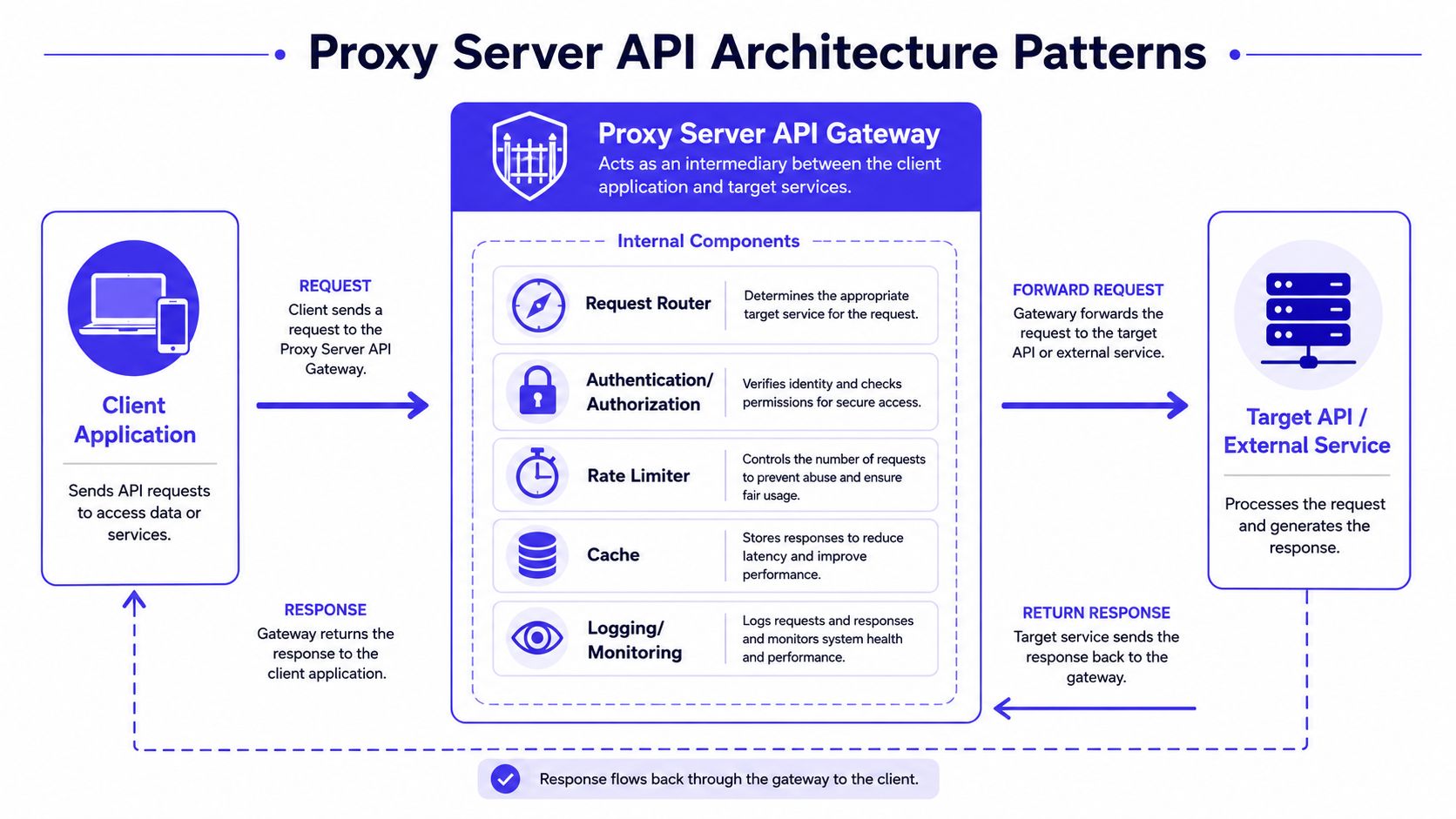
At the core, a Proxy Server API is usually a reverse proxy pattern with API-aware controls layered on top. Requests arrive from a client or internal service, the proxy authenticates and inspects them, applies routing and policy, optionally transforms the payload, and forwards the request to a target service. The response takes the same route back.
The architectural rule that matters most
Apigee's documentation is explicit: API proxy servers can use reverse proxy configurations generated from OpenAPI Specifications to route inbound requests to existing HTTP backend services, enabling stateless architectures that do not hold session-specific data between requests, as described in Apigee's simple API proxy guide.
That statelessness matters because it changes scaling economics. When the proxy doesn't keep per-session state, you can put multiple instances behind a load balancer without inventing sticky-session workarounds.
What sits inside the proxy path
Typical components include:
Here's a representative request shape for an internal proxy endpoint:
{"target_url": "https://example.com/reviews","region": "us","render": false,"headers": {"accept-language": "en-US"}}That design is useful because the client doesn't need to know how rotation, authentication, retries, or header policies work. The proxy becomes the one place where network behavior is codified.
For teams building service layers around this pattern, a practical companion is a disciplined API contract. This guide on how to create an API is a good reminder that consistency at the interface level saves more time than clever retry logic later.
A short video can help if you want a visual mental model of the flow:
Mini example one with request normalization
Suppose your ML ingestion service pulls product data from several retailers. One returns nested JSON. Another returns HTML that your scraper parses into an internal shape. A third exposes a legacy field set.
Put normalization in the proxy layer when:
Keep it out of the proxy when:
Mini example two with backend protection
A customer-facing AI assistant often needs one public endpoint while the backend consists of several internal services. The proxy can terminate auth, validate headers, route requests, and hide internal addresses. That reduces accidental exposure and gives platform teams a better control point than embedding the same checks in every service.
Put identity, routing, and coarse-grained policy in the proxy. Keep product logic in services. Mixing them is how “lightweight edge code” turns into a second application stack.
Proxy API Integration Examples for AI Teams
Theory is easy. The useful test is whether a team can wire a Proxy Server API into a data pipeline without creating another fragile dependency.
A common AI use case is collecting product reviews for sentiment analysis, retrieval augmentation, or market intelligence. The proxy sits between your ingestion worker and the public site, so you can centralize credentials, routing, and response handling.
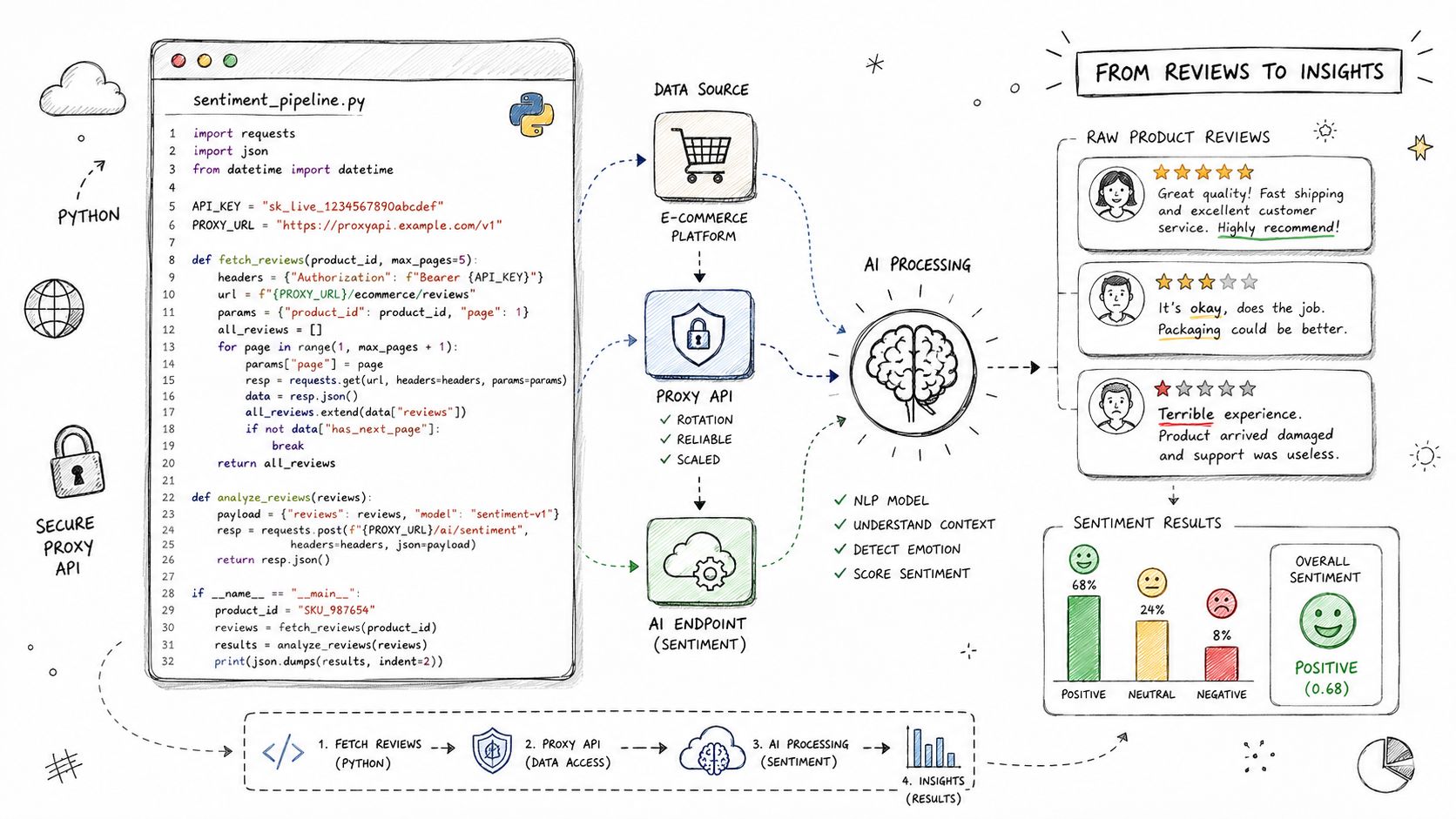
Mini case with Python
This example assumes your team exposes an internal proxy endpoint instead of letting every scraper hit third-party infrastructure directly.
import osimport requestsPROXY_API_URL = os.environ["PROXY_API_URL"]PROXY_API_KEY = os.environ["PROXY_API_KEY"]payload = {"target_url": "https://example.com/product/123/reviews","region": "us","render": False,"headers": {"accept-language": "en-US,en;q=0.9"}}headers = {"Authorization": f"Bearer {PROXY_API_KEY}","Content-Type": "application/json"}try:response = requests.post(PROXY_API_URL, json=payload, headers=headers, timeout=30)response.raise_for_status()data = response.json()reviews = data.get("reviews", [])for review in reviews:print(review.get("title"), review.get("rating"))except requests.HTTPError as err:print(f"HTTP error: {err}")except requests.RequestException as err:print(f"Request failed: {err}")Why this works in practice:
Mini case with Node.js
For teams standardizing on JavaScript or TypeScript services, the pattern is almost identical.
const axios = require("axios");const PROXY_API_URL = process.env.PROXY_API_URL;const PROXY_API_KEY = process.env.PROXY_API_KEY;async function fetchReviews() {try {const response = await axios.post(PROXY_API_URL,{target_url: "https://example.com/product/123/reviews",region: "us",render: false,headers: {"accept-language": "en-US,en;q=0.9"}},{headers: {Authorization: `Bearer ${PROXY_API_KEY}`,"Content-Type": "application/json"},timeout: 30000});const reviews = response.data.reviews || [];reviews.forEach((review) => {console.log(review.title, review.rating);});} catch (error) {if (error.response) {console.error("Proxy response error:", error.response.status, error.response.data);} else {console.error("Request failed:", error.message);}}}fetchReviews();What teams usually miss
The code isn't the hard part. The hard part is choosing where ownership lives.
| Decision | Good default | What goes wrong if you skip it |
|---|---|---|
| Credential storage | Environment variables or secret manager | Keys leak into repos or CI logs |
| Response validation | Validate expected fields before storage | Bad HTML or partial JSON enters training data |
| Region handling | Make region explicit in request payload | Teams assume “global” results are representative |
| Retry policy | Retry only for known transient failures | Duplicate ingestion and noisy vendor billing |
Some teams also need region-aware access for remote operators, QA reviewers, or analysts validating what the pipeline sees in restricted environments. In those cases, this overview of solutions for remote professionals in China is a useful operational reference because it highlights the realities of network access constraints outside a standard office setup.
Don't let every scraper team negotiate the internet independently. Give them one controlled entry point and a contract they can code against.
Scaling and Securing Your Proxy API in Production
A prototype proxy is easy to ship. A production proxy is where architecture discipline shows up.
The single biggest rule is simple. An API proxy server must enforce a stateless architecture by not holding session-specific data between requests, enabling horizontal scaling via load balancers during traffic surges and supporting high availability and fault tolerance, according to API2Cart's explanation of scalable proxy design.
If you ignore that, you end up with edge instances that can't scale cleanly, can't fail over cleanly, and can't be reasoned about under load.
Security belongs at the edge
A proxy earns its keep when it becomes the first policy checkpoint, not just a pass-through.
Strong edge design usually includes:
A practical threat review helps here, especially for teams connecting sensitive market data, model evaluation services, or partner APIs. This overview of Accelerate IT Services Inc. insights is useful because it frames threat assessment as an operating discipline, not a compliance checkbox.
Performance is a cost decision, not just a speed decision
Caching at the proxy layer matters when multiple downstream jobs request the same public resource or the same internal metadata. The benefit isn't just lower latency. It's lower backend load, fewer repeated external calls, and less wasted compute in ingestion workers.
Use caching when:
Skip or minimize caching when:
If you're operating several proxy instances, pair stateless design with the same traffic engineering mindset you'd use elsewhere in the platform. This guide to load balancing software is a solid reminder that balancing policy and balancing traffic are tightly linked.
Production controls that actually matter
Here's the shortlist I'd insist on before calling a proxy layer production-ready:
What doesn't work well
A few patterns look cheap early and become expensive later:
A proxy layer should reduce complexity for application teams. If it introduces more special cases than it removes, the architecture is wrong.
Checklist Building vs Buying a Proxy API Solution
Teams shouldn't ask whether they can build a proxy layer. They can. The better question is whether they should own it over time.

One operational clue comes from Apigee's production guidance. In Apigee Edge for Private Cloud, customers are required to submit API proxy traffic statistics daily, with recommendations to automate the process through cron jobs for production data integrity, as documented in Apigee's traffic data reporting process. That's a reminder that production proxy ownership includes reporting and governance work, not just request forwarding.
Build vs buy scorecard
Use this checklist in an architecture review or vendor selection meeting.
| Criteria | Build in-house if... | Buy from vendor if... |
|---|---|---|
| Time to market | your proxy is core IP | you need working infrastructure quickly |
| Development cost | platform team already has edge expertise | you'd be pulling product engineers into infra work |
| Maintenance and support | you can fund on-call, updates, and policy operations | you want vendor support for the network layer |
| Scalability needs | traffic patterns are well understood | demand may change and you need elasticity |
| Security expertise | your team already runs auth, keys, and abuse controls well | you need a mature edge posture sooner |
| Feature flexibility | your workflows need highly custom routing or transformation | standard proxy features cover most use cases |
| Internal bandwidth | infra work won't delay roadmap commitments | product deadlines are tighter than platform capacity |
| Compliance requirements | you can document and audit edge behavior internally | you need established controls from a specialist vendor |
Five questions to ask before signing anything
A useful working habit is to score each row red, yellow, or green for both options. If buy wins on most operational rows and build wins only on theoretical flexibility, the decision is usually already made.
Your Next Steps with Proxy APIs
Start small, but don't treat this as a side utility.
First, identify the primary job your proxy layer needs to handle. Training data ingestion, geo-testing, market intelligence, and API protection each deserve different design choices.
Second, run a narrow pilot. Pick one scraper, one regional test flow, or one external-facing API path. Define success around reliability, data quality, and operational effort, not just whether requests complete.
Third, decide who owns the edge. If your team lacks a senior engineer who has built API, data, and platform controls in production, fill that gap before adoption spreads. That's usually the difference between a useful control plane and a pile of edge exceptions.
If you need engineers who can design a production-ready proxy layer around AI data pipelines, API security, and MLOps workflows, ThirstySprout can help. Start a Pilot to scope the architecture with senior AI and platform talent, or See Sample Profiles to review engineers who've shipped real-world ML infrastructure.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.