
You're probably in one of two situations right now. Either your team wants to add an AI feature and keeps jumping straight to model names, or you're hiring for AI and can't tell whether you need a computer vision engineer, an LLM engineer, or someone who can keep a training pipeline alive after launch.
That's where neural network architecture stops being an academic topic and becomes an operating decision. The architecture you choose affects your data requirements, your cloud bill, your latency profile, your hiring plan, and whether you can ship a useful V1 in weeks instead of burning a quarter on experimentation.
The right question isn't “what's the most advanced model?” It's “what architecture gets us to business value with the data, talent, and infrastructure we have?”
Practical rule: Start with the problem shape and the data shape. Only then pick the model family.
How to Choose a Neural Network Architecture Framework
A good architecture decision starts earlier than is commonly believed. Before you compare CNNs, LSTMs, or transformers, define the product decision the model will support. Are you classifying defects from photos, summarizing support tickets, forecasting demand, or ranking products from user behavior?
If that question is fuzzy, your model choice will be fuzzy too.
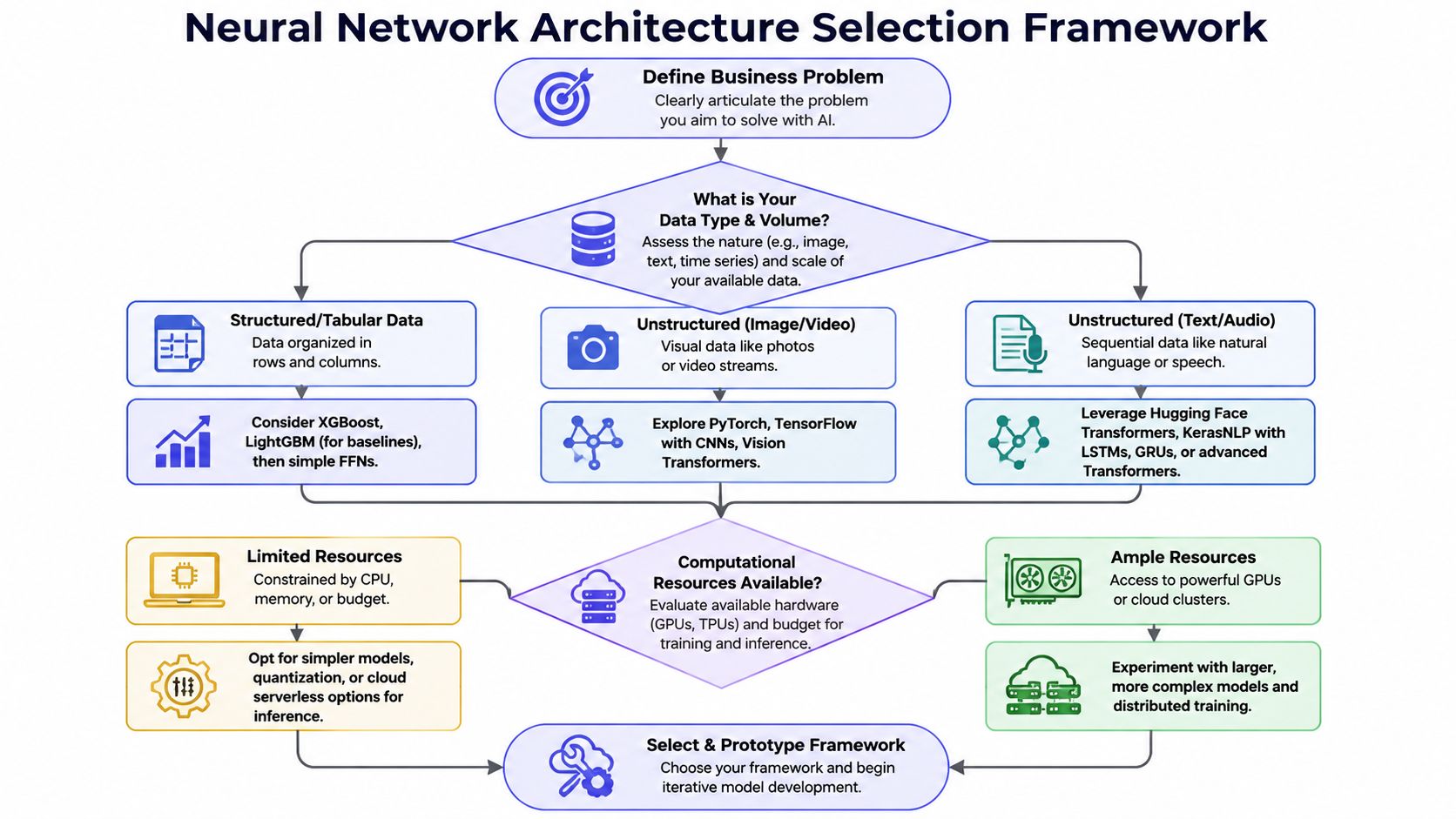
After the problem is clear, move through a simple decision tree based on data type, failure cost, and production constraints. This is also the point where many teams benefit from reviewing proven workflows and top prototyping tools for 2026 so they can test assumptions before building a full training stack.
Start with the data you actually own
Most first-time AI features fit into one of these buckets:
| Data shape | Best first architecture family | Why it usually fits |
|---|---|---|
| Images or video | CNNs first, sometimes vision transformers later | Strong spatial bias, efficient feature extraction |
| Text | Transformers | Better context handling for language tasks |
| Time-series or event sequences | RNNs or LSTMs for focused sequence work | Useful when order and memory matter |
| Tabular business data | Simpler baselines first, then shallow feed-forward networks if needed | Faster path to value than deep models in many V1 cases |
For CTOs, the most important move here is disqualification. If you're solving a product-image matching problem, don't start with a general-purpose language model. If you're summarizing multi-turn support conversations, don't force a CNN into a language job.
Use constraints to narrow the field fast
Architecture choice isn't just about fit. It's also about whether your team can operate it.
Ask these questions before writing a job description:
What's the latency budget?
Real-time product features usually punish oversized models.How much labeled data do we have?
Sparse or messy labels often favor transfer learning over training from scratch.What can we monitor in production?
If you can't detect drift, retrain safely, and roll back, choose the simpler architecture.What talent do we already have?
A team comfortable with PyTorch, computer vision pipelines, and embedding search can ship vision faster than a team that only knows API-based LLM integration.
A strong V1 architecture is the one your team can train, deploy, monitor, and improve without heroics.
Turn architecture into a staffing and platform decision
Once you've narrowed the model family, decide whether your stack supports it. A vision system usually needs image preprocessing, batch inference, and vector indexing if search is involved. A text system often needs prompt evaluation, model versioning, and retrieval or summarization workflows.
That's why architecture planning and platform planning happen together. If you're mapping tooling choices for experiments, serving, and deployment, this overview of best machine learning platforms is useful for scoping what your team will need to run.
A practical mental model looks like this:
- Choose by data type first
- Filter by latency and cost second
- Filter by talent availability third
- Only then compare model sophistication
That order saves time. It also keeps your first major AI feature tied to business reality instead of research ambition.
Two Practical Architecture Examples in Production
A CTO greenlights the company's first AI feature. The next question is rarely, “Which architecture is most advanced?” It is usually, “What can this team ship in one or two quarters, with acceptable cost, and enough quality to change a business metric?” That is the right lens for architecture choice.
Two common V1 cases make the trade-offs clear. One is visual search for commerce. The other is support ticket summarization. Both use neural networks. The staffing plan, data requirements, operating cost, and path to value are very different.
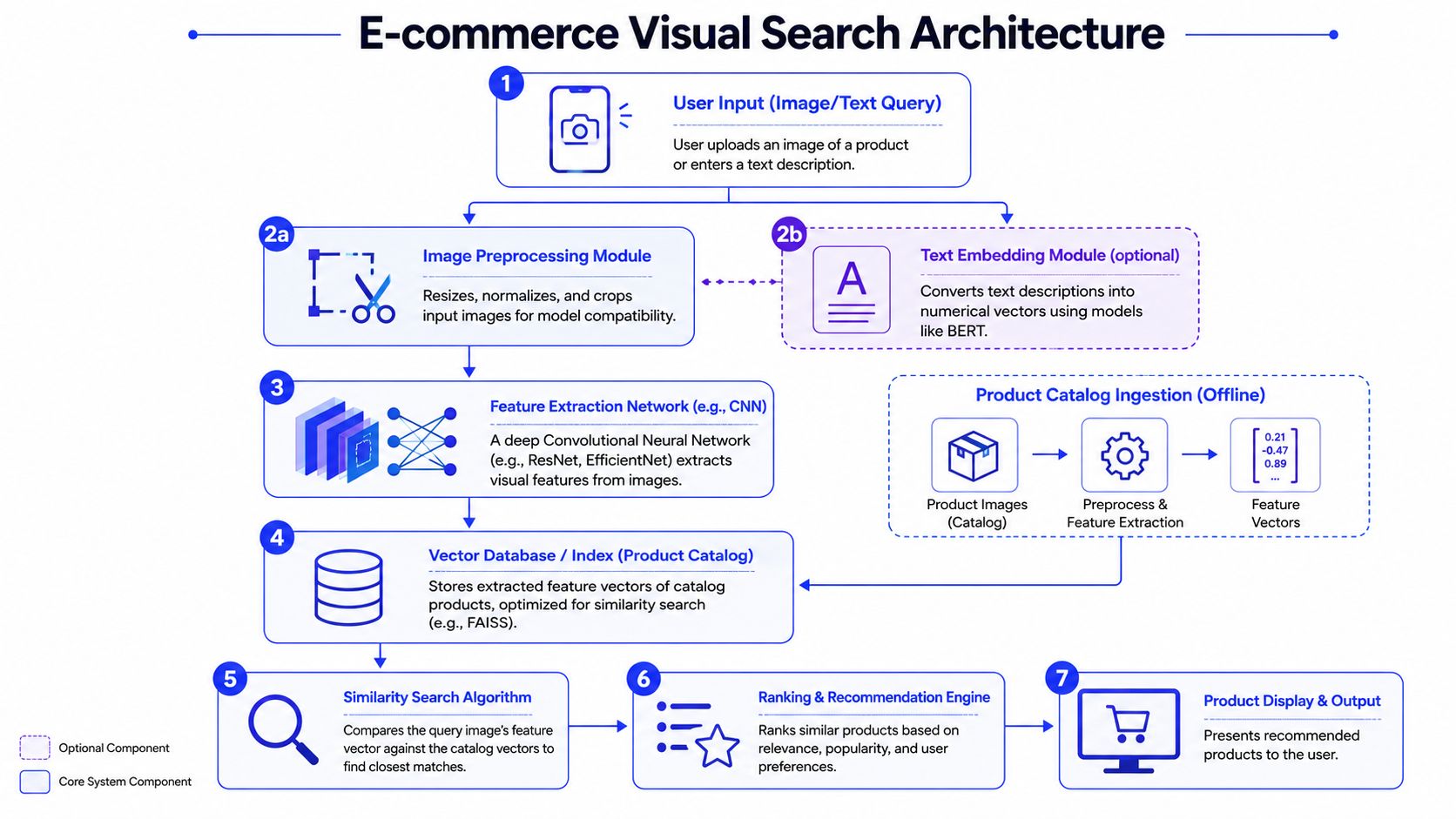
Example one e-commerce visual search with a CNN
An e-commerce team wants users to upload a product photo and find similar catalog items. That sounds ambitious, but the first production version is usually narrower than people expect. The goal is not open-ended multimodal reasoning. The goal is accurate visual retrieval against a controlled catalog.
A CNN is often the best starting point because the problem is feature extraction from images, then nearest-neighbor search. For a remote team, that matters. CNN-based retrieval is easier to staff than a custom multimodal system, easier to evaluate, and usually cheaper to run at scale.
A solid production design looks like this:
- Input layer: User-uploaded image
- Preprocessing: Resize, normalize, crop
- Feature extractor: CNN backbone such as ResNet
- Index layer: Vector database such as FAISS or another ANN index
- Ranking layer: Similarity score plus business rules like stock and popularity
The business case depends on catalog quality as much as model quality. If product images are inconsistent, backgrounds are cluttered, or labels are wrong, retrieval quality drops fast. Teams often underestimate this and blame the architecture. In practice, strong image standards and clean catalog metadata do as much for V1 performance as the model choice.
The hiring plan is usually modest:
- A machine learning engineer with vision experience
- A backend engineer who can own the retrieval service
- An MLOps engineer or platform-minded engineer if retraining and deployment need to be reliable from day one
There is a real trade-off here. A CNN-based system may miss cross-modal intent such as “show me this chair in walnut.” A larger multimodal model can handle more of that intent, but it raises inference cost, increases latency risk, and usually requires stronger evaluation and prompt management. If image-to-image similarity is enough to improve conversion or reduce search abandonment, ship that first.
I have seen teams save months by holding that line. Image-first retrieval gets customer behavior data early. Then the team can decide whether text embeddings, reranking, or multimodal search will pay for themselves.
Example two support ticket summarization with a transformer
A support organization wants every long ticket thread summarized before an agent replies. The work is less about visual pattern matching and more about handling long context, messy language, and inconsistent writing across messages, notes, and status changes. That usually points to a transformer-based approach.
For a V1, the practical decision is not “build a custom language model or not.” It is whether a pretrained transformer can produce summaries that save agent time without creating review risk. In many teams, the answer is yes, especially if the rollout starts with internal use only and clear human review rules.
A practical production design often uses:
- Pretrained transformer model
- Instruction or task-specific prompting for early validation
- Evaluation set built from real support threads
- Optional fine-tuning only after baseline quality is understood
- Human review path for risky outputs
Evaluation is the hard part.
If the support lead cannot define what a good summary includes, such as root issue, current status, promised next action, and customer sentiment, the team will argue about model quality without making progress. For remote AI teams, this usually becomes an operating problem before it becomes a modeling problem. Someone has to curate examples, write acceptance criteria, and review failures every week.
The team shape reflects that:
| Role | What they own |
|---|---|
| ML engineer with NLP focus | Model selection, prompt or fine-tune workflow |
| Data engineer | Ticket ingestion, redaction, structured storage |
| MLOps engineer | Model serving, observability, rollback |
| Product owner or support lead | Acceptance criteria and review rubric |
The main trade-off is speed versus specialization. A pretrained transformer gets a pilot live faster and reduces the amount of labeled data you need on day one. Fine-tuning can improve tone, structure, and domain fit, but it adds annotation work, evaluation overhead, versioning, and deployment complexity. That is often the wrong first investment unless summarization quality directly affects regulated workflows or high-value accounts.
A remote team also needs to decide who owns prompt changes, failure review, and redaction policy. Those are architecture-adjacent decisions with real cost. If no one owns them, the model may work in demos and still fail in production.
The broader lesson from both examples is simple. Architecture choice is a business decision disguised as a technical one. The right V1 model is the one your team can support with available talent, enough data quality, acceptable inference cost, and a feedback loop that improves the product after launch.
A Tour of Foundational Architectures CNNs and RNNs
A remote team shipping its first AI feature rarely needs the newest model class. It needs a model the team can train, deploy, monitor, and improve without turning the quarter into a hiring scramble.
That is why CNNs and RNNs still matter.
These architectures solve narrower problems than modern transformers, but they often win on time-to-value. They are easier to benchmark, easier to serve on modest infrastructure, and easier to assign to a small team with one ML engineer and strong product constraints.
CNNs for vision workloads
CNNs are still a practical choice for image classification, defect detection, OCR pre-processing, and visual similarity systems. They work by learning local visual patterns first, then composing those patterns into higher-level features. Weight sharing keeps the model size and compute budget under control, which matters when the business case depends on low-latency inference across large image volumes.
The trade-off is straightforward. CNNs perform well when the visual task is well defined and the labeling standard is clear. They are less attractive when the product needs open-ended reasoning across images and text, or when the roadmap is likely to shift toward multimodal assistants.
A well-known benchmark illustrates the efficiency case. The original ResNet paper reports that deeper residual CNNs improved ImageNet results over earlier CNN families while remaining trainable at scale, and common implementations list ResNet-50 at roughly 25.6 million parameters versus VGG-16 at roughly 138 million parameters. See the ResNet paper and the PyTorch model documentation for VGG and ResNet. For a CTO, the practical point is not the leaderboard. It is that architecture choice changes serving cost, training time, and the hardware budget for a V1.
Latency claims also need context. GPU speed depends on kernel fusion, batch size, input resolution, memory bandwidth, and the exact serving stack. NVIDIA's TensorRT documentation and benchmarks show how architecture and optimization choices can materially reduce inference latency for convolution-heavy vision models, but the gain is workload-specific. Teams should test their own pipeline instead of planning around a single percentage.
Choose a CNN when you need:
- Stable image classification with predictable error modes
- Visual inspection or defect detection on a fixed camera setup
- Product matching or image similarity on a bounded catalog
- A model your team can retrain without specialized research talent
RNNs and LSTMs for ordered sequences
RNNs are still useful when order matters and the problem scope is tight. Sensor forecasting, keyword spotting, log event prediction, and some speech pipelines still fit this pattern.
Vanilla RNNs struggle with long-range dependencies because gradients fade over time. LSTMs address that with gated memory. They decide what to keep, what to discard, and what to expose to the next step. That design makes them more stable on practical sequence tasks where the context window is limited and the data arrives in time order.
For business teams, the appeal is operational. An LSTM model for forecasting or event sequence classification is often smaller, cheaper, and easier to debug than a transformer built for the same narrow task. It also lowers the staffing bar. A solid ML engineer with experience in time-series features, data leakage checks, and evaluation design can usually get an LSTM-based V1 into production faster than a team trying to adapt a larger architecture it does not fully understand.
The constraint is equally clear. If the product requires broad language reasoning, long-context synthesis, or flexible tool use, an RNN is the wrong abstraction. If the task is bounded and sequence order carries most of the signal, it remains a sensible choice.
Where these architectures still win
Foundational models are a good business decision when the problem is narrow, labeled data is available, and the remote team needs a model it can own end to end. That includes industrial vision, document routing, anomaly detection on sensor streams, event sequence modeling, and some forecasting workloads.
They also fit organizations that are still building AI muscle. You can hire for these systems more easily, set up evaluation with less ambiguity, and keep infrastructure costs aligned with a V1 budget. That matters if the primary bottleneck is not model quality alone, but team capacity across data engineering, ML operations, and product review.
For teams planning a future agent layer on top of these systems, the Robotomail guide to AI agents is a useful complement. Start with a dependable model for the narrow task first. Then add orchestration once the underlying prediction loop is stable.
Older architectures are not legacy by default. They are often the shortest path to a shipped product with clear unit economics.
The Modern Architectures Powering AI Today
A CTO usually hits this section of the decision tree when the prototype already works in a notebook and the actual question becomes operational. Do we build on a transformer API and ship in six weeks, or hire for custom model work and accept a longer path to value? Do we need a model that writes, reasons, and routes tasks, or one that generates images at scale with moderation and storage built in?
That is the split in modern architectures. Transformers are the default choice for language and multimodal product features. Diffusion models fit products that generate or edit media. Both can create value. Both can also create expensive infrastructure and staffing problems if the architecture decision gets ahead of the business case.
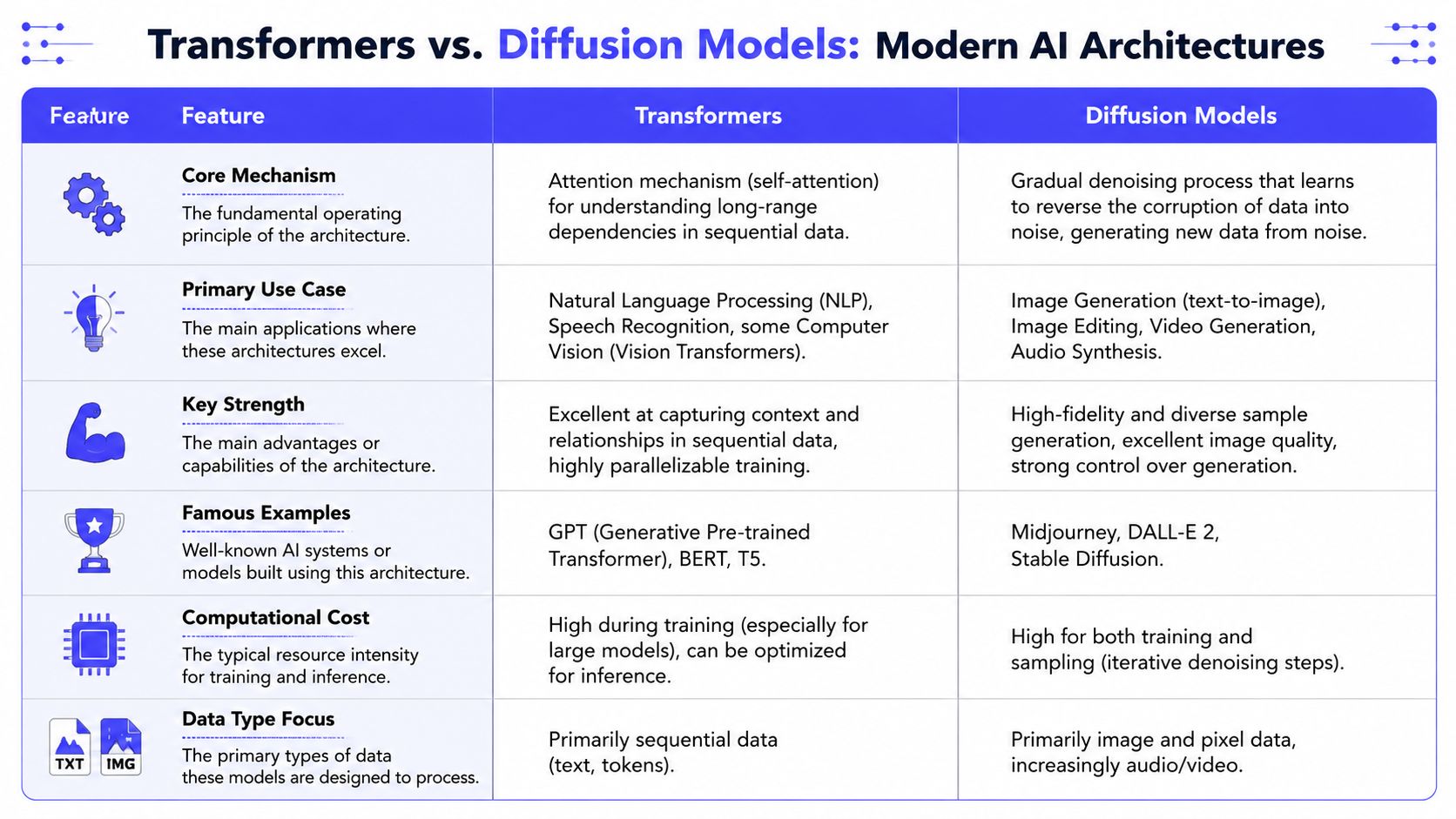
Why transformers lead most new AI products
For a remote team building its first serious AI feature, transformers usually offer the fastest route to a working V1. The reason is practical. You can start from strong pretrained models, adapt with prompt engineering or light fine-tuning, and put evaluation effort into your domain instead of spending months training from scratch.
They are a good fit for:
- Summarization
- Classification over long text
- Translation
- Question answering
- Chat and assistant interfaces
- Multimodal systems built on shared token-style representations
The trade-off is cost discipline. Transformer-based systems can look cheap during prototyping and become expensive once traffic, context length, and latency requirements show up. Teams also underestimate the talent mix. A successful launch rarely depends on prompt writers alone. It depends on product engineers, data engineers, and MLOps support that can evaluate outputs, control inference spend, and keep rollbacks simple. A good starting point is to treat model serving and observability as part of the architecture decision, not cleanup work for later; this approach underscores why MLOps best practices for production AI systems matter.
If you're planning an assistant, tool-using workflow, or internal copilot, the model is only half the system. The orchestration layer matters just as much. The Robotomail guide to AI agents is useful here because it connects model choice to the workflow patterns teams have to operate.
Where diffusion models fit
Diffusion models make sense when the product creates or edits media rather than interpreting text. Image generation, image editing, style transfer, creative asset production, and some video workflows fit this family well.
That changes the operating model.
A language feature often fails in a way users can flag and recover from. A media generation feature adds moderation queues, storage growth, rights review, prompt abuse controls, and heavier GPU planning. The architecture choice affects more than model quality. It affects who you need to hire and what your support process looks like after launch.
| Product need | Typical fit |
|---|---|
| Text-to-image generation | Strong fit for diffusion |
| Image editing | Strong fit for diffusion |
| Synthetic asset creation | Often diffusion-led |
| Language summarization or chat | Poor fit, use transformers instead |
This video gives a useful visual overview of the newer model architectures:
What works and what usually breaks
Modern architectures reward teams that stay narrow early.
What usually works:
- Pretrained models before custom training
- Tight evaluation sets built from your real tasks
- Guardrails around output quality and failure handling
- A deployment path that includes monitoring and rollback
What often breaks:
- Choosing a giant model before defining acceptance criteria
- Treating prototype quality as production quality
- Ignoring inference cost and latency until late in the project
- Hiring prompt specialists without platform ownership
For most first-generation AI products, the best decision is not the most advanced architecture. It is the one your team can staff, evaluate, ship, and afford to run once usage grows.
The Production-Ready Architecture Checklist
A model can look good in a notebook and still be the wrong architecture for production. That's why the final architecture decision should happen inside an operational checklist, not a benchmark slide.
The most useful checklist forces your team to answer questions about data, deployment, cost, monitoring, and staffing before you commit to a model family.
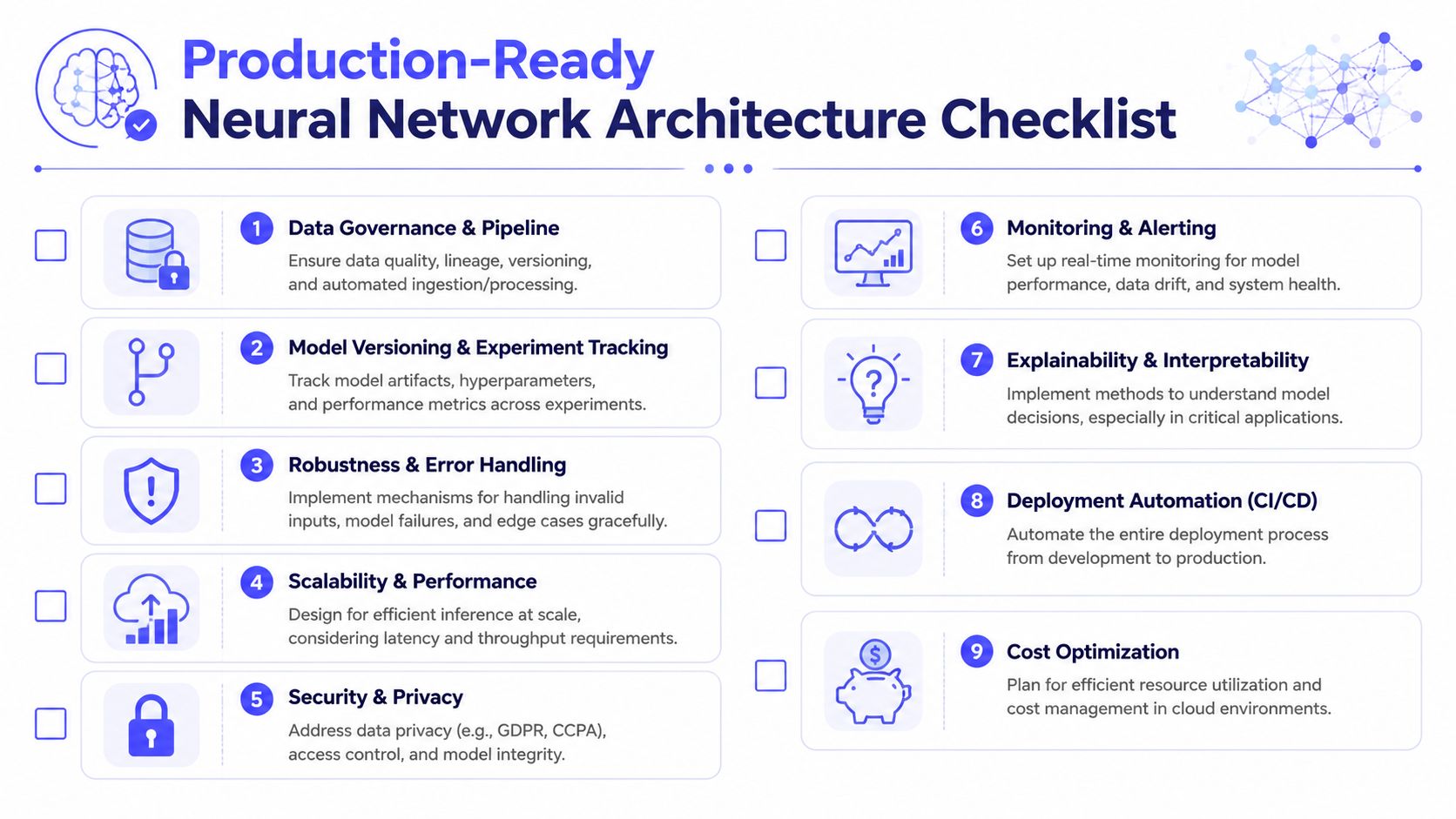
The architecture review questions that matter
Use this as a planning template in your next design review.
What user action will this model improve?
Tie the model to a workflow, not a demo. If the answer is vague, pause the build.What input data do we control?
Confirm where data comes from, how it's labeled, how often it changes, and who owns quality.What's our acceptable failure mode?
Some features can degrade gracefully. Others need hard fallbacks and human review.Can we support the serving pattern?
Real-time APIs, batch jobs, and human-in-the-loop review pipelines have different operational needs.How will we retrain or update safely?
If the answer is “manually,” you're not ready for a fast-changing use case.
Don't ignore the simpler-model option
One of the most useful production insights right now is that older or simpler architectures aren't always dead ends. Recent MIT research reported that networks previously seen as unsuitable can improve dramatically after a short guided alignment phase with a stronger model, which changes the practical question from “which architecture is best in theory?” to “which architecture becomes viable after guidance or distillation?” as described in this MIT CSAIL report on guided learning.
That matters for budgets and team design. A simpler student model can be easier to serve, monitor, and maintain than a heavyweight teacher system. In practice, that can make the difference between a pilot that stays in staging and one that survives traffic growth.
When cost, latency, and reliability matter, ask whether a guided or distilled simpler model can do the job before you scale up architecture complexity.
A hiring and operations scorecard
Here's a compact scorecard you can adapt:
| Review area | What good looks like |
|---|---|
| Data pipeline | Versioned inputs, clear lineage, repeatable preprocessing |
| Model ops | Experiment tracking, artifact versioning, rollback path |
| Serving | Chosen for actual latency and throughput needs |
| Monitoring | Drift, quality, and system health visible after launch |
| Security | Access controls, privacy checks, safe logging |
| Team | Clear owners across ML, platform, backend, and product |
If your team is formalizing how these practices should work in production, this guide to MLOps best practices is a good companion for turning architecture intent into reliable operations.
A practical staffing rule helps here. Hire for the architecture you'll run, not the architecture you admire. A stable CNN service and a transformer-based summarization system require different engineering habits, deployment patterns, and evaluation workflows.
Your Next Steps to Build With AI Talent
Architecture decisions don't fail because teams can't name the right model family. They fail because nobody owns the path from prototype to production. The missing piece is usually senior execution.
If you've chosen the rough direction for your neural network architecture, the next move is operational. You need the right people, the right acceptance criteria, and a realistic scope for V1.
Step one narrow the first release
Pick one user workflow and one architecture family. Don't launch “AI search, recommendations, chat, and automation” in a single initiative.
A better first move looks like this:
- For vision: Product matching, defect detection, or document image classification
- For language: Ticket summarization, intent classification, or knowledge answer drafting
- For sequences: Forecasting or event anomaly detection in a bounded domain
The narrower the workflow, the easier it is to evaluate quality and the easier it is to staff correctly.
Step two hire for shipped experience
A first AI feature needs people who've already dealt with data messiness, deployment surprises, and stakeholder pressure. That usually matters more than chasing someone with the broadest research background.
Look for engineers who can talk concretely about:
- How they evaluated a model before launch
- What broke in production
- How they monitored quality drift
- How they changed architecture when latency or cost got in the way
If you're building the team now, this guide on how to hire AI engineers is a practical place to start because it maps the roles behind real shipping work, not just experimentation.
The best AI hires don't just know models. They know what to simplify so the product can launch.
Step three run a pilot with explicit exit criteria
The fastest way to waste time is to run an “AI exploration” project with no decision point. Run a pilot instead.
Define these before kickoff:
| Pilot question | Example decision |
|---|---|
| What job is the model doing? | Summarize support tickets before agent response |
| How will humans judge quality? | Internal review rubric on clarity, accuracy, usefulness |
| What happens if the model fails? | Fallback to manual workflow |
| What unlocks phase two? | Quality threshold met, acceptable latency, team can operate it |
That framework keeps architecture tied to business evidence. It also makes hiring simpler because you can assign clear ownership across modeling, data, platform, and product.
The biggest mistake I see is overcommitting too early. Don't hire a broad AI team for a fuzzy mandate. Start with the smallest senior group that can validate the architecture choice, ship the feature, and leave behind a maintainable operating model.
If you need senior engineers who've already shipped LLM, computer vision, MLOps, and applied ML systems, ThirstySprout can help you assemble a remote AI team quickly. You can Start a Pilot or See Sample Profiles to match the architecture you've chosen with operators who know how to deliver it.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.