
You’re probably in one of two situations right now. Your roadmap includes AI features, workflow automation, or a customer-facing application that can’t slip another quarter. At the same time, hiring locally is slow, expensive, and unpredictable, especially when you need people who’ve shipped production systems instead of just experimented with notebooks.
That’s where nearshore application development becomes interesting. Not as a generic outsourcing move. As an operating model for teams that need real collaboration, strong engineering habits, and enough overlap to make product, design, data, and infrastructure decisions in the same working day.
Used well, nearshore can help you move faster without accepting the communication drag that often comes with fully offshore delivery. Used poorly, it creates a second engineering organization with unclear ownership, weak technical vetting, and a lot of expensive meetings. The difference isn’t geography. It’s how you choose, hire, and govern the team.
Practical rule: If your project depends on rapid feedback between product, engineering, and AI infrastructure, optimize for collaboration quality first and hourly rate second.
Onshore vs Offshore vs Nearshore Development Models
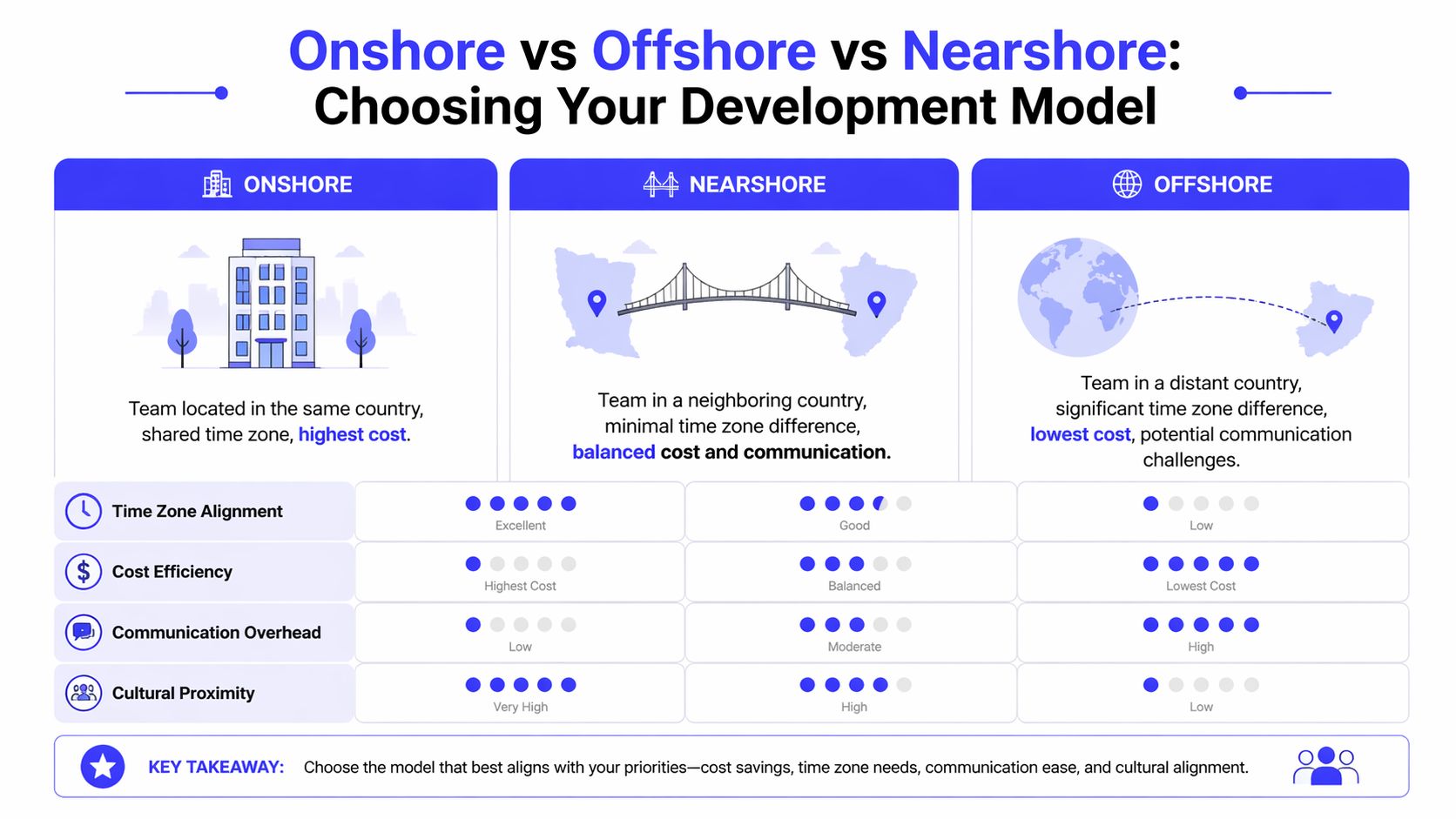
In broad terms, onshore and offshore are already understood. Onshore means your external team sits in the same country. Offshore usually means a distant geography with a large time gap. Nearshore application development sits in the middle. It gives you external capacity and cost relief without giving up the ability to collaborate in real time.
That middle ground matters more on AI and modern application work than it did on older, spec-heavy projects. If your team is building retrieval-augmented generation flows, event-driven backends, model evaluation pipelines, or cloud-native mobile apps, requirement changes happen constantly. You need engineers who can join standups, answer product questions quickly, and unblock architecture decisions before they turn into rework.
The practical differences that actually matter
Here’s how I frame the three models when evaluating a build, platform rewrite, or AI initiative.
| Model | Best fit | Main strength | Main weakness |
|---|---|---|---|
| Onshore | Regulated work, high-trust internal collaboration, heavy stakeholder access | Tightest communication and legal alignment | Highest cost and a tighter talent pool |
| Nearshore | Agile product development, AI/ML delivery, cloud modernization, cross-functional execution | Balance of speed, overlap, and cost | Quality varies sharply if vetting is weak |
| Offshore | Well-scoped execution, maintenance, test-heavy delivery, follow-the-sun workflows | Lowest cost and broad scale | Higher communication latency and more management overhead |
The strategic shift toward nearshore isn’t theoretical. The global nearshore software development services market was valued at USD 48.3 billion in 2024 and is projected to grow from USD 50.8 billion in 2025 to USD 85 billion by 2035 at a CAGR of 5.2%, while 80% of North American companies are exploring nearshore development, according to nearshore software development market projections from Wise Guy Reports.
Why nearshore keeps winning complex work
For straightforward feature factories, offshore can work well if your documentation discipline is excellent. For highly sensitive systems, onshore still has a clear place. Nearshore wins when the work is collaborative, iterative, and architecture-heavy.
A few patterns show up repeatedly:
- Product ambiguity is still high: You’re learning from users while building.
- Architecture is evolving: APIs, model interfaces, and cloud infrastructure are still moving.
- Cross-functional input matters daily: Engineering, product, data, security, and QA need overlap.
- The local market is too tight: You can’t wait for the perfect hire to appear domestically.
If you need a deeper look at the offshore side before making that call, this comprehensive guide on Offshore Development Centers is useful for understanding where dedicated offshore structures fit and where they create coordination trade-offs.
For teams comparing broader sourcing options, it also helps to review the operational models behind IT outsourcing services, especially if your decision goes beyond one application team and into platform or support functions.
A simple mental model
Use onshore when control and domestic alignment matter most.
Use offshore when cost efficiency and scale matter most.
Use nearshore when speed, collaboration, and execution quality need to stay in balance.
That’s the strategic sweet spot. But it’s only a sweet spot if the team you hire can handle the technical depth your project requires.
The Business Case Benefits Versus Real-World Risks
Nearshore application development gets sold too often as a cost story. That’s incomplete. The stronger case is operational. You get faster decision loops, more workable collaboration habits, and access to talent that’s hard to hire locally.
Those benefits are real. So are the failure modes.
Where nearshore creates business value
The first benefit is speed through shared working hours. When product managers, backend engineers, mobile developers, and ML engineers can resolve questions the same day, less work gets built on stale assumptions. That matters on anything iterative, especially AI features where prompt design, evaluation criteria, and data contracts shift quickly.
The second benefit is access to modern technical depth. Strong nearshore teams increasingly work across ML, DevOps, cloud, React, Node.js, Python, microservices, and CI/CD, which lets them integrate into application programs that mix product engineering with AI workloads. According to nearshore software development guidance from TDSGS, nearshore teams often bring technical depth in ML, DevOps, and cloud, and mobile apps with AI features can reach market in 12-16 weeks via agile sprints.
The third benefit is less management drag than many leaders expect. This is the hidden advantage. When your engineering lead doesn’t spend half the day writing long clarification documents for the next time zone, they can stay focused on architecture, quality, and business trade-offs.
Where nearshore breaks down
The common mistake is assuming time zone overlap solves everything. It doesn’t. A team can share your workday and still be the wrong team.
The sharpest risk appears in specialized AI work. A 2023 Accelerance report noted 40-70% cost savings, but integration hurdles can lead to 20-30% higher project delays in AI workflows due to retraining needs, and some surveys show 15% of U.S. fintech and SaaS firms reported AI project failures from nearshore skill gaps, as summarized in this analysis of nearshore application development risks.
That tracks with what operators see in the field. Plenty of teams can build CRUD apps, dashboards, or standard APIs. Far fewer can handle:
- LLM productionization: evaluation loops, prompt versioning, retrieval quality, fallback behavior
- MLOps discipline: feature pipelines, model deployment workflows, observability, rollback plans
- AI governance: data boundaries, auditability, output risk, human review design
- Platform integration: vector stores, event streaming, secrets management, identity, rate limits
Nearshore is not a shortcut around technical leadership. It raises the quality ceiling only if you set a high bar for vetting and governance.
The trade-offs that don’t show up in vendor decks
A realistic nearshore business case should include these trade-offs:
- Communication is better, but not automatic: Good overlap still needs clear ownership, written specs, and strong English in technical settings.
- Rates may be lower, but oversight still matters: You save money only if you avoid churn, rework, and role confusion.
- Strong generalists are easier to find than niche AI specialists: Vet aggressively for production experience, not tool familiarity alone.
- Security and compliance don’t disappear: You still need access controls, repository policies, audit logs, and contract language that protects IP and data.
What works versus what doesn’t
What works is assigning nearshore teams to outcomes they can own. A feature pod, a platform slice, a model-serving service, or a mobile product lane.
What doesn’t work is hiring a loosely assembled remote team and expecting them to infer your product priorities, architecture standards, and quality bar through osmosis.
If the work is business-critical and model-driven, your operating question isn’t “Can nearshore be cheaper?” It’s “Can this team reduce cycle time without increasing production risk?” That’s the test worth using.
A Decision Framework for Choosing Your Model
You don’t need a philosophy session to choose between onshore, nearshore, and offshore. You need a decision rule your team can apply in one meeting.
I use a simple scorecard. Rate each model against the nature of the work, not your abstract preferences. The more the project depends on rapid iteration, cross-functional collaboration, and specialized engineering judgment, the more nearshore tends to pull ahead.
Outsourcing Model Decision Rubric
Score each factor from 1 to 5, where 5 means the model is a strong fit.
| Decision Factor | Onshore Score | Nearshore Score | Offshore Score |
|---|---|---|---|
| Need for same-day product and engineering decisions | 5 | 4 | 2 |
| Agile work with frequent requirement change | 5 | 5 | 2 |
| Budget sensitivity | 2 | 4 | 5 |
| Access to broad external talent | 2 | 4 | 5 |
| Specialized AI/ML collaboration needs | 4 | 4 | 2 |
| Tolerance for asynchronous workflows | 2 | 3 | 5 |
| Compliance and legal simplicity | 5 | 3 | 2 |
| Need for close leadership oversight | 5 | 4 | 2 |
| Suitable for tightly scoped execution work | 3 | 4 | 5 |
| Suitable for architecture-heavy modernization | 5 | 5 | 2 |
This isn’t mathematical truth. It’s a practical way to get alignment.
The key variable is collaboration latency
The strongest factual signal in favor of nearshore is the impact of overlap on execution speed. Nearshore application development typically uses 1-4 hour time zone differences and can deliver 20-30% faster development cycles than offshore models through shorter feedback loops and reduced requirement drift, according to Wonderment Apps on nearshore application development.
That matters most when your project has lots of unresolved questions. A small delay in clarifying one API contract or prompt-handling rule can cascade through frontend, backend, QA, and infra. Teams feel that as friction. Leadership feels it as missed sprint goals.
How to use the rubric in practice
Use this sequence in your planning meeting:
Name the work accurately
Is this maintenance, a platform migration, an AI pilot, or a new product line? Don’t call exploratory work “well scoped” just because finance wants predictability.List your essential requirements
Examples include regulatory constraints, real-time collaboration, niche MLOps expertise, or a fixed launch date.Score each model fast
Don’t debate every row for an hour. If leadership can’t score a factor in two minutes, the requirement probably isn’t clear enough.Pressure-test the winner
Ask what would make this choice fail. For nearshore, the answer is often weak vetting or weak governance. For offshore, it’s usually feedback lag. For onshore, it’s hiring speed or cost.
Decision shortcut: If the project needs active product discovery and production-grade AI work at the same time, nearshore is often the best default starting point. If the work is highly regulated, onshore may still win. If the work is stable and spec-driven, offshore can be the most efficient option.
Example scorecard uses
Two quick examples make the rubric easier to apply.
| Project type | Likely fit | Why |
|---|---|---|
| LLM-powered internal copilot with security review | Nearshore or onshore | Frequent iteration, sensitive workflows, architecture decisions need overlap |
| Well-defined QA automation backlog for an existing product | Offshore or nearshore | Clear scope, process-driven work, less need for same-day product decisions |
The point isn’t to force every project into one model. It’s to choose the delivery model that matches the communication pattern and technical risk profile of the work.
How to Hire and Vet a Nearshore AI Team
Most hiring mistakes happen before the first interview. The role is vague, the evaluation criteria are generic, and the team confuses “strong engineer” with “strong fit for this system.”
That’s especially dangerous in nearshore application development for AI work. You don’t need people who can talk about machine learning. You need people who can ship model-driven features inside a production application with the same reliability standards you’d expect from your core platform team.

Start with role design, not a job title
“ML Engineer” is too broad to hire well. Break the work down by delivery responsibility.
Examples:
- LLM application engineer for retrieval, orchestration, evaluations, and API integration
- MLOps engineer for pipelines, deployment, observability, and rollback
- AI product engineer for full-stack delivery with model integration
- Data engineer for ingestion, transformation, feature flows, and governance
If you want a better baseline for designing a repeatable funnel, this guide to an efficient recruitment and hiring process is a useful reference for tightening stages and reducing decision lag.
Good role design also lets you source more intelligently. If you know you need Kubernetes, model serving, CI/CD, and Python, you’ll screen for very different signals than if you’re hiring for prompt workflows inside a TypeScript-heavy product team.
Vet for shipped systems, not vocabulary
Strong nearshore teams can integrate quickly into modern stacks across ML, DevOps, cloud, React, Node.js, Python, microservices, and CI/CD. That’s valuable because it reduces ramp-up and makes them useful earlier in the project lifecycle. As noted earlier in the article, some teams can move AI-enabled mobile apps from concept to market in 12-16 weeks when the delivery model is disciplined.
What matters in interviews is proof. Ask candidates to explain choices they made under production constraints.
Use a structured process:
Portfolio screen
Look for systems with users, uptime constraints, model lifecycle issues, or cloud complexity.Architecture interview
Have the candidate map the service boundaries, data flow, and failure modes for a realistic system.Hands-on exercise
Keep it short. Make it representative. Evaluate decisions, not polish.Operational deep dive
Test what happens after launch. Monitoring, rollback, retraining, access control, cost control.Collaboration interview
Don’t skip this. Nearshore success depends on communication habits as much as syntax skill.
Mini example of a take-home brief
For an MLOps engineer, I’d use a scoped exercise like this:
You inherit a Python inference service running in containers on Kubernetes. Users report inconsistent latency and stale model outputs. Outline how you’d instrument the service, version the model, add a safe deployment workflow, and define rollback triggers.
What I’m looking for:
- Clear observability plan
- Separation of code version and model version
- Safe release flow such as canary or staged rollout
- Practical alerting thresholds
- Awareness of data drift or concept drift
- Security basics around secrets and access
After the candidate explains their approach, ask where this design could fail. Strong engineers usually volunteer trade-offs without being prompted.
Here’s a useful video overview before you build your own funnel:
High-signal interview questions for nearshore AI hiring
Use questions that force concrete answers.
Describe a production incident involving model quality or drift.
What failed first, how was it detected, and what changed afterward?How would you evaluate an LLM feature before launch?
Listen for evaluation sets, failure categories, human review, and rollback planning.Tell me about a CI/CD setup you owned for ML or application delivery.
You want specifics on gates, environments, testing, and release safety.How do you design a retrieval pipeline for changing source documents?
Good answers mention ingestion freshness, chunking strategy, metadata, and debugging poor retrieval.What belongs in synchronous discussion versus written documentation?
This question matters more than people think. It exposes collaboration maturity.
A quick hiring scorecard
| Signal | Strong answer looks like | Weak answer looks like |
|---|---|---|
| Production ownership | Mentions incidents, rollback, monitoring, trade-offs | Talks only about building features |
| AI depth | Explains evaluation, data flow, deployment constraints | Lists tools without context |
| Systems thinking | Connects app, infra, data, and product behavior | Treats components in isolation |
| Communication | Clarifies assumptions and asks sharp questions | Jumps to buzzwords or generic best practices |
If you need external support for the funnel itself, it’s worth reviewing options to hire remote AI developers with demonstrated production experience instead of running an unstructured search from scratch.
Structuring and Governing Your Nearshore Partnership
Hiring the team is the easy part. The harder part is deciding how they plug into your operating system. Most nearshore partnerships fail because the engagement model is fuzzy. The team is “helping,” but nobody knows who owns what, how performance is measured, or how decisions get made when product and model behavior conflict.
There are two structures that work most often. Everything else is usually a messy hybrid.
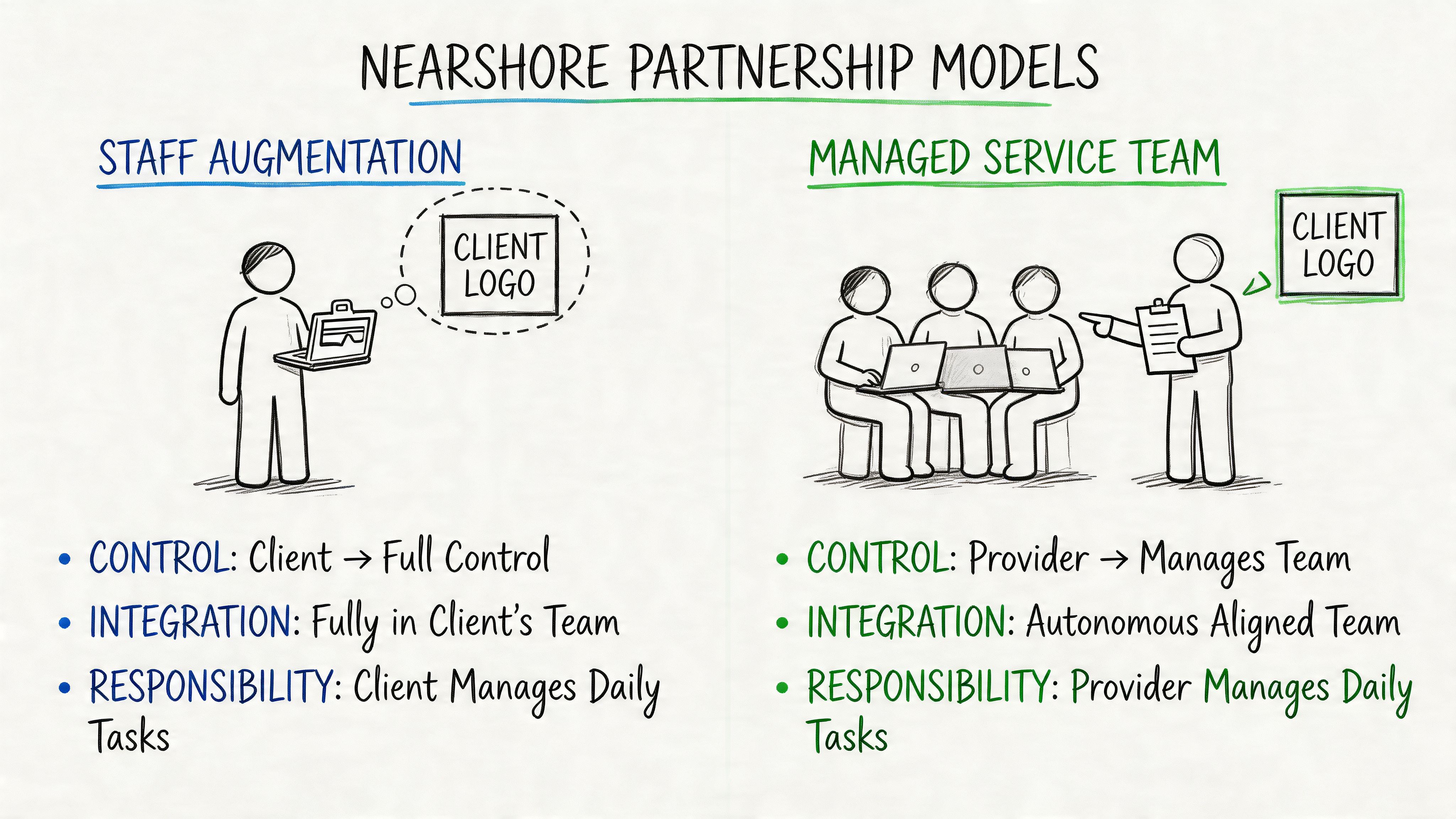
Staff augmentation versus managed pods
Staff augmentation works when your internal engineering leadership is strong and bandwidth exists to manage day-to-day execution. You embed nearshore engineers directly into your squads, use your rituals, and keep architecture control in-house.
Managed pods work better when you need a self-contained unit with its own delivery accountability. A pod usually owns a feature area, platform slice, or AI workflow with a clear product interface and measurable outcomes.
Here’s the trade-off:
| Model | Best when | Watch out for |
|---|---|---|
| Staff augmentation | You have strong internal EM, staff engineer, or tech lead coverage | Remote engineers can become task-takers if ownership is weak |
| Managed pod | You need faster execution with clearer external accountability | Misalignment grows fast if goals and acceptance criteria are vague |
For leaders comparing both structures, this breakdown of managed services vs staff augmentation is useful because it forces the ownership question early.
Governance for AI projects is different
Generic software KPIs aren’t enough for model-driven systems. Velocity alone won’t tell you if the system is getting safer, more reliable, or more useful.
Use governance that combines software delivery with AI performance. Your metrics should cover four layers:
Delivery health
Sprint predictability, escaped defects, lead time for changes, release qualitySystem reliability
Service uptime, pipeline health, failed job recovery, incident response processModel behavior
Evaluation pass criteria, drift review cadence, output quality review, fallback ratesBusiness fit
User adoption, workflow completion, support burden, manual review load
A nearshore AI team should never be managed on hours alone. Manage them on service quality, release quality, and business impact.
Example governance template
For a managed pod building an AI-assisted workflow, I’d expect the contract and operating plan to define:
Named ownership
Who owns product decisions, model evaluation, infrastructure, security, and production sign-off.Acceptance criteria for each release
Not just “feature complete.” Include quality gates, test expectations, observability requirements, and rollback readiness.Model-specific operating rules
Evaluation set review, prompt or model version control, retraining triggers, incident escalation path.IP and data boundaries
Clear language on repository ownership, derivative work ownership, training data use, and access revocation procedures.Review cadence
Weekly delivery review, monthly architecture review, periodic security review, and post-incident retrospectives.
Mini example of KPI language
A lightweight scorecard can look like this:
| Area | Example KPI or SLA language |
|---|---|
| Application delivery | Feature work must meet agreed acceptance criteria before sprint close |
| CI/CD quality | Releases require automated test passage and documented rollback path |
| AI behavior | Changes to prompts, retrieval, or model settings require evaluation review before release |
| Operations | Production incidents require owner assignment and written follow-up |
Avoid fake precision here. Many teams write numerical targets too early and then spend weeks gaming them. Start with measurable definitions and tighten thresholds once you understand the system.
Contracting tips that prevent expensive confusion
A few clauses matter more than many teams realize:
- Ownership of artifacts: Source code, prompts, evaluation sets, infra-as-code, runbooks, and documentation should be explicitly covered.
- Access control: Define who can access production systems, datasets, model endpoints, and secrets.
- Subcontractor restrictions: If the vendor can swap people freely, your quality bar won’t hold.
- Transition obligations: Require documentation and handoff support if the partnership ends.
- Change control: For AI work, scope drift is normal. Your contract should define how changing model behavior, evaluation criteria, or data requirements are handled.
If your managers are still learning how to lead distributed engineers well, these effective remote team management tips are a good complement to the governance layer. Process discipline matters more once the team spans countries and functions.
Nearshore in Action Two Mini Case Studies
The fastest way to tell whether nearshore application development fits your company is to look at the kind of problems it solves well. Two scenarios come up repeatedly. One is early-stage AI exploration where speed matters. The other is modernization work where reliability matters just as much as speed.
Mini case one for a fintech RAG pilot
A Series A fintech team had a familiar problem. Their support organization was overloaded with repeat questions across onboarding, card controls, account verification, and policy edge cases. Product wanted an AI-assisted support layer. Engineering didn’t want to bolt a weak chatbot onto a sensitive domain.
They chose a small nearshore pod because the work required tight iteration with product, compliance, and backend engineering. The team shape was simple:
- 1 AI product lead
- 2 ML-focused engineers
- 1 backend engineer from the internal platform team
- 1 compliance stakeholder in weekly review
The pilot worked because ownership was narrow. The pod didn’t “do AI.” It owned a single use case. Search support content, retrieve the right policy source, draft a bounded answer, and route uncertain cases to a human.
What they built
The initial architecture was deliberately boring:
- Document ingestion into a searchable knowledge layer
- Retrieval with metadata filters for product area and policy freshness
- A bounded answer generator with strict source grounding
- Confidence thresholds that triggered human handoff
- Event logging for review of bad answers and missed retrievals
The product manager met with the pod in overlapping hours several times each week. That mattered more than any tool choice. Feedback on answer quality happened while the implementation context was still fresh.
“Keep the first RAG pilot narrow enough that legal, support, and engineering can all review failures without creating a committee.”
What worked and what didn’t
What worked:
- Tight scope
- Clear fallback behavior
- Daily engineering overlap
- Shared review of bad outputs
What didn’t:
- Early prompt changes without a version log
- Ambiguous ownership for source content freshness
- Too many edge cases in the first evaluation set
The nearshore setup was a good fit because the work needed iterative product judgment. An offshore team could have built the components, but the number of same-day clarifications would have made the loop slower and noisier.
Mini case two for an e-commerce recommendation rewrite
A Series C commerce company had a different problem. Their recommendation engine lived inside a legacy monolith. Releases were brittle. Data dependencies were poorly documented. Every model change felt risky because nobody trusted the deployment path.
This company didn’t need idea generation. They needed disciplined modernization.
They used a nearshore MLOps-heavy team as a managed pod attached to an internal staff engineer and product analytics lead. The pod owned:
- Model packaging and release workflow
- CI/CD pipeline improvements
- Service extraction from the monolith
- Monitoring for inference behavior and deployment failures
- Documentation for handoff to the platform team
The delivery approach
The rewrite started with system mapping, not coding. The pod documented where recommendations were generated, which upstream data jobs fed the system, and where the highest operational risk sat.
Then they split the work into three lanes:
| Lane | Goal | Owner |
|---|---|---|
| Extraction | Separate recommendation logic from the monolith | Nearshore backend and platform engineers |
| Release safety | Add test gates, staged rollout, rollback plan | Nearshore MLOps lead |
| Observability | Make model and service behavior visible to product and ops | Shared pod ownership |
The team used overlapping hours for architecture reviews and incident response planning. The rest of the work ran asynchronously without much friction because the system boundaries were now clear.
Why the model fit
Nearshore often outperforms both alternatives.
Onshore would likely have worked, but at a higher cost and with the same need for internal oversight. Offshore could have been efficient for parts of the build, but the migration involved enough architecture review, release risk discussion, and cross-team dependency management that the feedback loop needed to stay tight.
The result wasn’t magic. It was governable progress. More predictable releases. Better documentation. Cleaner ownership between platform and product engineering. Above all, leadership could see whether reliability was improving before the full migration finished.
The common thread in both cases
These examples look different, but the pattern is the same. Nearshore works best when the team owns a clear problem with meaningful overlap into product and engineering decision-making.
It works poorly when companies outsource ambiguity and keep ownership fuzzy.
Use nearshore application development when you need people who can collaborate closely, write production-quality code, and operate inside a modern engineering system. Don’t use it as a substitute for architecture leadership, role clarity, or disciplined governance.
If you’re building AI products and need nearshore engineers who’ve actually shipped production systems, ThirstySprout can help you start a pilot quickly. You can bring in one specialist or a full remote AI team across LLMs, machine learning, MLOps, data engineering, and AI product. If you want to move from hiring uncertainty to a scoped delivery plan, start with a pilot and see sample profiles.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.