
Stop asking “What are microservices?” If you're hiring a senior engineer into a distributed system, that question tells you almost nothing. Most candidates can repeat the definition. Far fewer can explain what happens when payment succeeds, settlement fails, the retry queue backs up, and support asks whether customers were double-charged.
That gap matters because the standard definition is only the starting line. Martin Fowler's architectural description still frames the baseline well: microservices are “small services” that communicate over “HTTP resource APIs” and are “independently deployable” through automated machinery, as summarized in ByteByteGo's discussion of core microservices interview topics. In practice, the interviews that work best test whether a candidate can reason through boundaries, failures, deployment, and recovery under pressure.
This guide gives you a full interview kit, not just a question list. You'll get scoring ideas, expected answer patterns, practical scenarios, and business impact signals for each topic. The point is simple. Separate candidates who've read about distributed systems from the ones who've shipped them.
Use this when you're hiring a staff engineer, a senior backend lead, a platform engineer supporting AI services, or a fintech engineer where correctness matters more than cleverness.
TL;DR
- Ask scenario questions, not trivia. Put candidates in failure-heavy production situations.
- Score trade-off quality. Strong candidates explain what they'd optimize, what they'd sacrifice, and why.
- Look for testing and observability depth. That's where textbook knowledge usually falls apart.
- Hire for T-shaped strength. You want one area of real depth and broad competence across the rest.
- Use a repeatable rubric. It reduces bias and makes debriefs much faster.
1. Microservices Architecture & Design Patterns
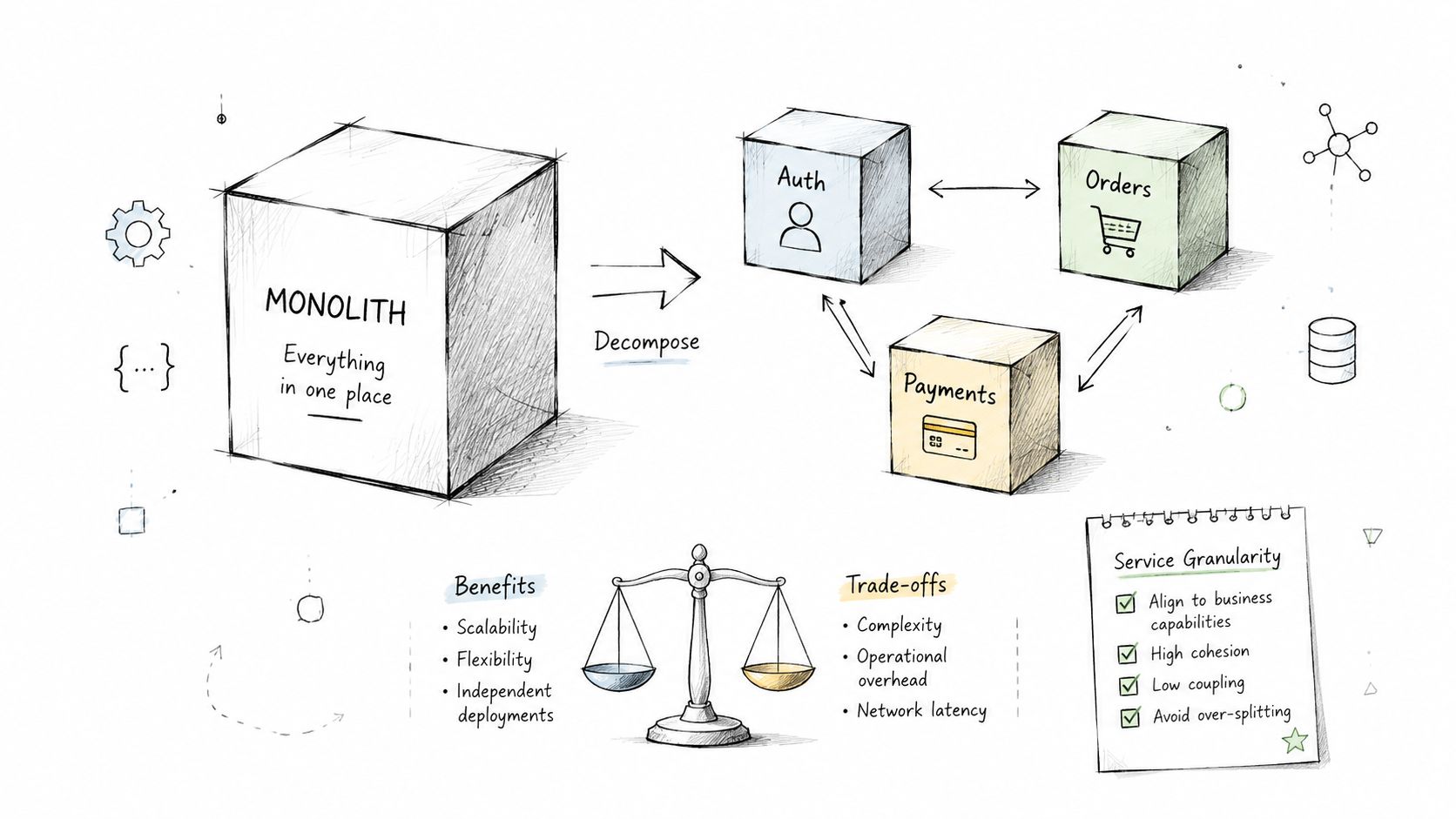
A strong interview starts with system boundaries. Not definitions. Not “monolith vs microservices” as a philosophy debate. Ask the candidate to decompose a product under real load, real team constraints, and real failure modes.
For context, microservices fit large applications with multiple teams where parts of the system need to scale independently, not systems that always scale as one unit. That architectural fit is discussed in this microservices architecture overview. Good candidates know that splitting a system too early creates operational drag. Great candidates can tell you when they'd keep a monolith.
What to ask
Give a concrete prompt. Example:
“You're joining a fintech startup. Transactions are growing fast. Today everything sits in one backend. What would you split first, what would you leave alone, and how would you handle partial failure between payment and settlement?”
A solid answer usually separates payment, ledger, and settlement because they have different risk profiles and ownership concerns. But the service diagram isn't enough. Push on the ugly part. If payment succeeds and settlement fails, what state does the customer see, and how do operators repair it?
What a good answer sounds like
Strong candidates talk in bounded contexts, team ownership, and failure recovery. They'll often introduce a Saga-style workflow, or at least an explicit compensation path, instead of pretending distributed writes are atomic.
They'll also say when not to split. A SaaS platform may keep the product core in a monolith and extract identity first because auth often has distinct security, scaling, and compliance requirements. That answer is usually stronger than someone who immediately pitches 25 services because “that's what Netflix does.”
Practical rule: If a candidate can't explain what breaks first after the split, they probably haven't operated microservices in production.
Simple scoring rubric
- Weak. Lists patterns and famous companies. Doesn't define service boundaries in business terms.
- Good. Proposes sensible decomposition and discusses ownership, deployment, and failure handling.
- Excellent. Explains migration sequencing, rollback strategy, test approach, and a case where they'd merge a service back into a larger boundary.
Business impact is easy to trace here. Bad boundaries create duplicate data, more incidents, slower delivery, and unclear ownership. Good boundaries reduce coordination overhead and keep the system easier to change without turning every release into a cross-team event.
2. Service Communication & API Design
A senior engineer should know that communication style is a business decision as much as a technical one. Synchronous calls are easy to reason about until they stack latency and spread failures across a chain. Asynchronous flows absorb spikes better, but they make state, retries, and debugging harder.
A practical interview prompt
Ask this:
“Design communication for a SaaS platform with a public API, internal low-latency service calls, and a payment workflow that must not double-charge users.”
Good candidates usually split the answer by use case. Public APIs often stay HTTP and JSON because clients value clarity and compatibility. Internal service-to-service paths may use gRPC where latency and schema discipline matter. Payment processing often goes async around non-user-facing steps so the system can retry safely and isolate downstream failures.
If the candidate says every service should call every other service synchronously over REST, keep digging. That design often hides coupling.
What to look for in the answer
A strong answer mentions versioning, backward compatibility, idempotency keys, timeout budgets, and contract ownership. If they bring up Pact or another contract testing tool without prompting, that's a good sign. If they can also explain when contract tests are insufficient, even better.
For teams refining their external interface standards, this comparison of API vs REST API design choices is a useful framing reference. And if you want a candidate exercise, have them review a practical API documentation template and critique how they'd improve it for internal consumers.
Mini case and scoring cues
Mini case. An engineer proposes REST for browser-facing endpoints, gRPC for internal recommendation calls, and a message queue for payment confirmation. They add idempotency keys on charge requests and define a retry policy that won't repeat the business action blindly. That's usually a strong answer because it shows protocol choice follows behavior, not fashion.
Use these score cues:
- Weak. Talks only about REST verbs or says “we use Kafka” without explaining why.
- Good. Matches protocol to workflow and covers retries, versioning, and ownership.
- Excellent. Explains schema evolution, observability for request chains, and where they would intentionally keep a synchronous edge despite the risk.
The business angle is direct. Poor API choices raise support burden, break clients, and make every dependency change expensive. Good communication design lowers integration risk and keeps internal teams moving without constant coordination.
3. Data Consistency & Distributed Transactions
Many interviews finally reveal the difference between a senior engineer and a good storyteller. Ask about consistency and you'll learn whether the candidate has dealt with money, inventory, or any workflow where “eventually correct” isn't enough without guardrails.
Scenario that works in interviews
Use a marketplace example:
“An order service writes order state internally. Payment runs through Stripe. How do you keep the system correct when a charge succeeds but your internal confirmation step fails?”
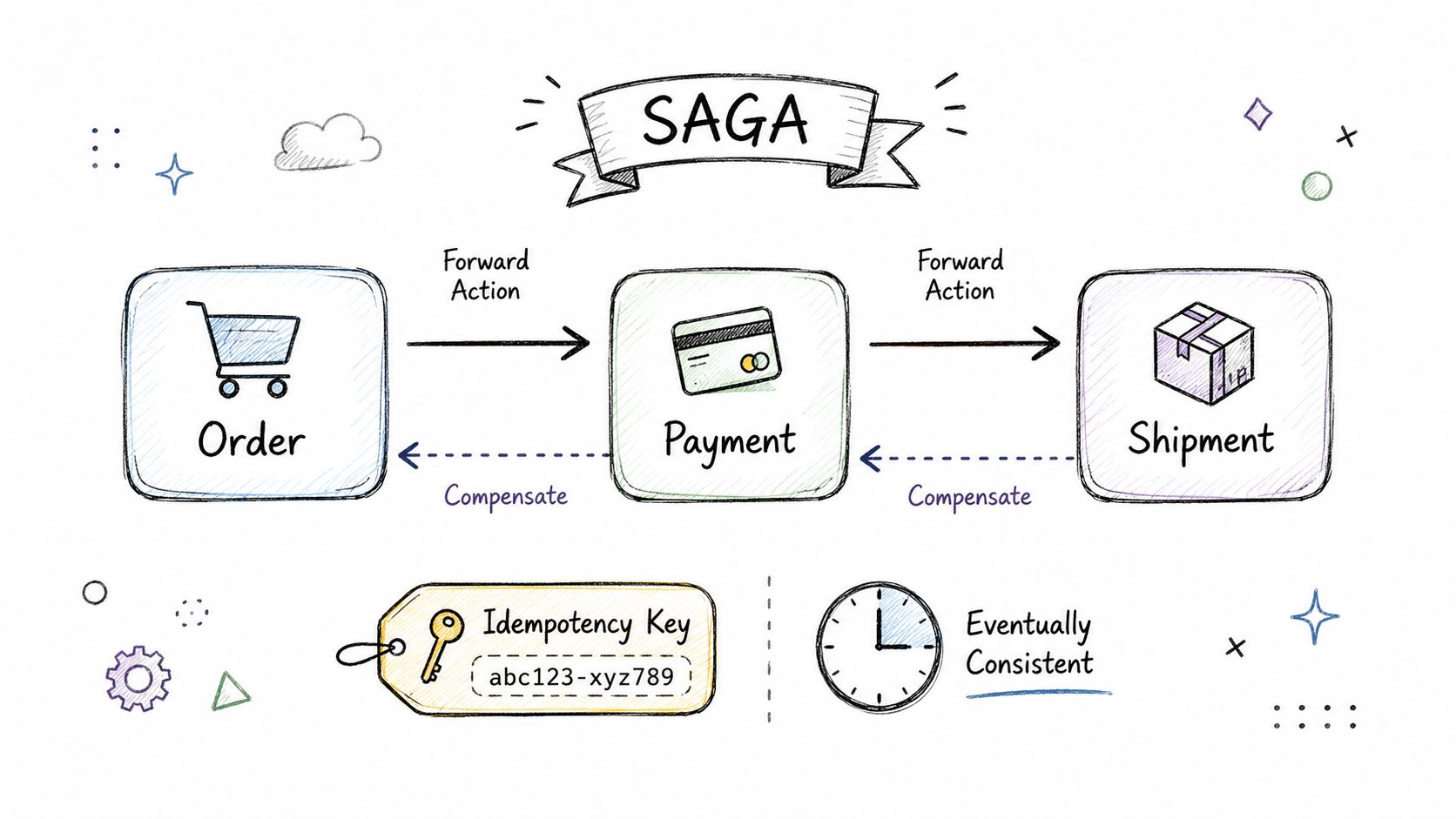
Good candidates won't promise perfect distributed atomicity unless they have a very narrow reason. They'll usually propose a Saga. Create a pending order. Attempt the charge. Confirm the order when the payment event arrives. If payment fails, cancel the order. Then they'll talk about webhook retries, duplicate events, and idempotency.
A more advanced candidate may propose a transactional outbox when a service must save local state and publish an event reliably from the same business action. That answer usually signals they've seen “database updated, event lost” in real life.
The follow-up that separates people fast
Ask this next:
“What's the worst thing that could happen if your consistency check fails?”
Weak candidates say “the data might be wrong.” Strong ones name a user and business consequence. Double shipment. Duplicate charge. Incorrect balance. Manual reconciliation queue. Compliance issue. Support escalation.
Rubric for this topic
- Weak. Mentions eventual consistency as a slogan. No remediation path.
- Good. Describes Saga or outbox and covers retries, idempotency, and timeout handling.
- Excellent. Explains reconciliation jobs, dead-letter handling, operator visibility, and how to alert on stuck workflows.
The best candidates don't treat inconsistency as a purely technical bug. They treat it as an operational workflow with customer impact.
Business impact is usually highest here. If a candidate can't reason through distributed transaction failure, you're not just risking bugs. You're risking revenue leakage, customer trust, finance cleanup, and long incident calls between engineering and operations.
4. Resilience, Fault Tolerance & Observability
Ask candidates to describe a production incident. Then stay quiet. This section tells you who has carried responsibility.
Many senior interview loops overemphasize architecture diagrams and underweight reliability. That's a mistake. A recent angle in microservices interviews is the balance between automation and observability, with ByteByteGo-linked expert analysis summarized in this video noting that 70% of senior engineers now face questions in that area. That tracks with what strong hiring teams already do. They probe how systems fail and how engineers see the failure.
Start with this prompt:
“A user-facing service depends on auth, inventory, and recommendations. One dependency slows down hard. What fails open, what fails closed, and what do you monitor first?”
A mature answer usually keeps auth strict, degrades recommendations gracefully, and puts hard timeout budgets around inventory calls. The candidate should talk about retries with backoff, circuit breakers, and bulkheads without treating retries as free.
Here's a useful media reference for the reliability conversation:
What strong candidates mention unprompted
They bring up correlation IDs, distributed tracing, and dashboards that align to service-level symptoms. They don't say “Kubernetes will restart the pod” as if that solves a cascading failure. It doesn't.
If you're evaluating their tooling judgment, compare how they think about logs and metrics in platforms like Kibana vs Grafana for observability workflows. The specific tool matters less than whether they know what each one is for.
Incident story scorecard
- Weak. Gives a neat textbook answer. No concrete debugging sequence.
- Good. Describes timeout tuning, circuit breakers, logs, metrics, and traces in a coherent order.
- Excellent. Explains a real incident, root cause isolation, dashboard or alert design, and the post-incident change that prevented recurrence.
“If every dependency is critical, your design is already failing before production does.”
Business impact here is straightforward. Resilient systems protect conversion, reduce incident toil, and keep teams from burning release days on emergency fixes. Observability shortens diagnosis time, which often matters more than raw uptime slogans.
5. Container Orchestration, Deployment & Infrastructure
A lot of candidates can write Dockerfiles. Fewer can explain how code moves from commit to production, how rollout risk is controlled, and what rollback means when state is involved.
This topic matters even more in larger environments because Kubernetes has become the default operating layer for many enterprises. Fortune 500 companies have reached a 96% adoption rate for Kubernetes according to this LinkedIn-cited industry summary. That doesn't mean every company uses Kubernetes well. It does mean senior microservices interview questions should test real operational knowledge around deployments, sidecars, service mesh trade-offs, and operator patterns.
Interview prompt that reveals depth
Ask this:
“Walk me through your last deployment from commit to production. Include tests, rollout strategy, and how you knew whether to continue or roll back.”
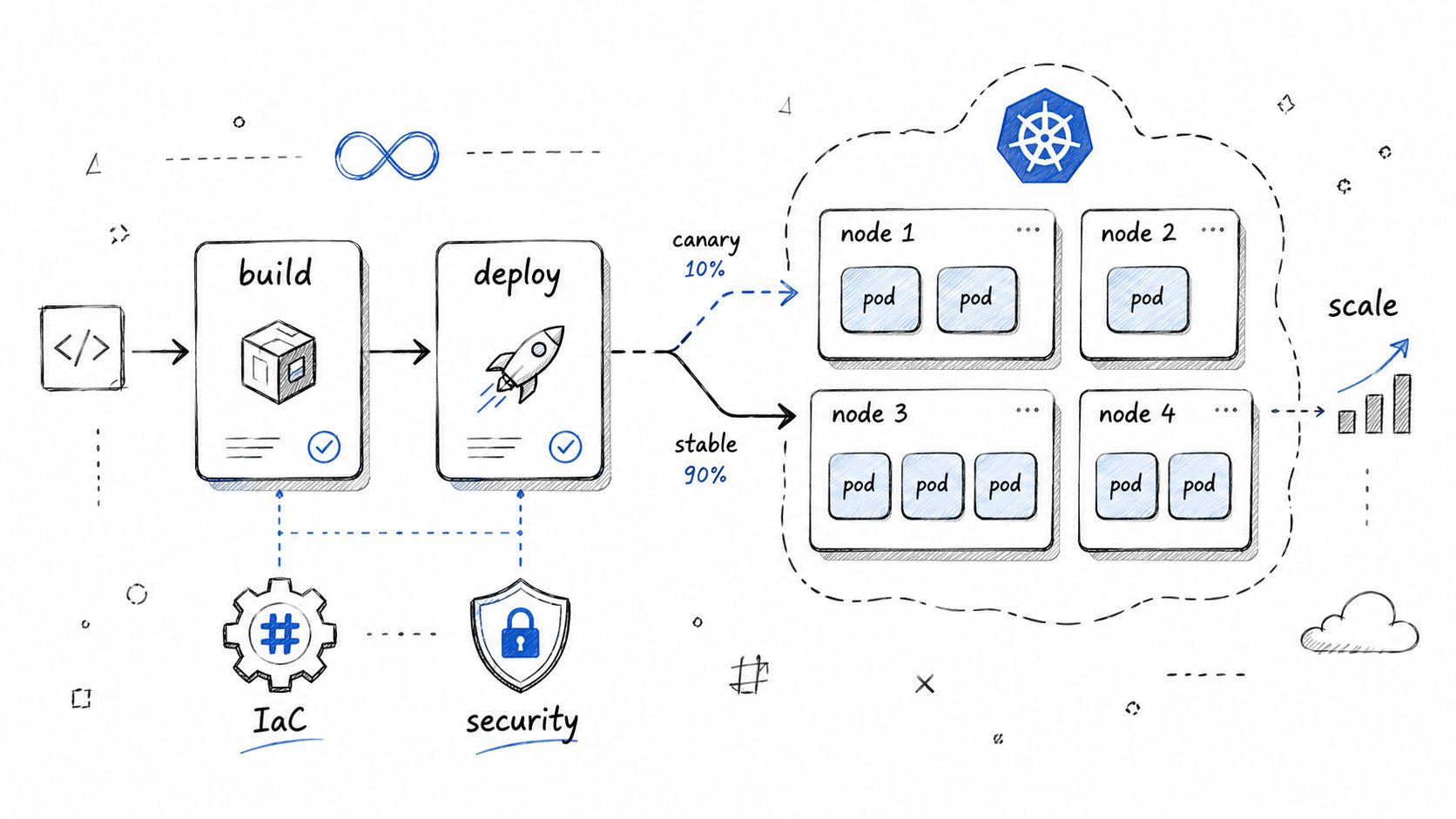
Good candidates answer in sequence. Build. Unit tests. Image creation. Deploy to staging. Smoke tests. Progressive rollout such as canary or blue-green. Observe error rate, latency, and business signals before promoting. They mention secrets handling and config separation without prompting.
A representative snippet
This kind of simplified Kubernetes deployment answer is usually a positive sign if the candidate can explain each field:
apiVersion: apps/v1kind: Deploymentmetadata:name: paymentsspec:replicas: 3strategy:type: RollingUpdatetemplate:spec:containers:- name: paymentsimage: registry/payments:vNextreadinessProbe:httpGet:path: /health/readyport: 8080The snippet alone proves nothing. The explanation does. Why readiness and not just liveness? What metrics gate promotion? How do you protect zero-downtime assumptions when the app has schema changes?
What to look for
For teams comparing local orchestration and production patterns, Docker Compose vs Kubernetes is a useful framing link. In interviews, strong candidates explain when the platform is overkill and when it's justified.
Score it this way:
- Weak. Talks about containers in generic terms. No rollout safety.
- Good. Explains CI/CD stages, health checks, rollback triggers, and secret separation.
- Excellent. Discusses progressive delivery, schema migration strategy, and how deployment signals connect to business impact.
Business impact shows up in release confidence. Bad deployment practice slows shipping and raises incident risk. Good platform discipline lets you release more often without turning every launch into an outage lottery.
6. Service Discovery, Configuration & Secrets Management
This category often gets skipped, which is a mistake. You can hire a strong coder who still creates dangerous operational debt if they don't understand how services find each other, where config belongs, and how credentials should be rotated.
Service discovery is a concrete mechanism, not an abstraction. In dynamic environments, clients query a registry to locate service instances instead of relying on hardcoded locations. Services register themselves with instance metadata, and clients can use that data for discovery and load balancing, as described in Metoro's explanation of service discovery patterns. Ask candidates to explain this plainly.
Interview prompt
Use something operational:
“Your startup grows from a handful of services to dozens. How do services discover each other, where does configuration live, and how do you rotate a database password without downtime?”
Good candidates usually map the answer to the environment. In Kubernetes, they may rely on internal DNS for discovery, ConfigMaps for non-sensitive config, and a proper secret store or sealed-secret workflow for credentials. In regulated environments, they should go further and discuss Vault, auditing, role-based access control, and staged rotation.
Mini case
A candidate says, “Secrets are in environment variables.” Keep pushing. That can be part of the delivery mechanism, but it isn't the full secret management story. Ask how they'd limit access, detect accidental exposure, and rotate credentials safely.
A stronger answer might include:
- Discovery path. Kubernetes service DNS for internal lookups, plus clear naming and ownership.
- Config strategy. Environment-specific config stored outside the app artifact.
- Secret rotation. Dual credentials or phased rotation so old and new credentials overlap briefly.
- Remediation plan. Immediate revocation, audit review, and secret scanning if a credential hits Git.
Operator note: Secrets management isn't a compliance checkbox. It's outage prevention and blast-radius control.
Scoring signals
- Weak. Hardcodes service locations or treats config and secrets as the same thing.
- Good. Explains discovery, externalized config, access controls, and rotation steps.
- Excellent. Adds auditing, incident response for leaks, and production-safe credential cutovers.
The business impact is risk reduction. Weak secret handling leads to avoidable incidents, customer trust issues, and expensive cleanup. Clean discovery and configuration practices also shorten onboarding because engineers don't need tribal knowledge to run or debug services.
7. Testing in Microservices Unit, Integration & Contract Testing
This is the most underrated category in microservices interview questions. Plenty of guides cover definitions. Very few test whether a candidate knows how to verify a distributed system without creating a brittle, slow, misleading test suite.
That gap is real. One industry summary argues that 99% of interview questions skip practical testing scenarios in microservices. I wouldn't treat the exact figure as the point. The point is the pattern. Teams often under-interview testing judgment, even though production failures frequently come from broken contracts and weak fallback behavior.
The question I'd always ask
“How would you test a Saga that spans multiple services when you can't rely on a perfect end-to-end environment?”
Strong candidates immediately stop chasing the fantasy of testing everything only through end-to-end flows. They'll break the answer into layers. Unit tests for local business logic. Integration tests for database and broker interaction. Contract tests for service boundaries. A small number of end-to-end tests for critical user journeys.
They should also talk about failure-path testing. What happens when a downstream service times out? What if the compensating action fails? How do they validate idempotency?
What strong testing judgment sounds like
Microservices can't be fully tested end to end in the same way a monolith can because services are independent and network behavior is part of the system. The best candidates know this and design partial confidence models instead of pretending they can simulate production perfectly.
A good answer often includes:
- Contract focus. Consumer-driven contracts to catch API drift early.
- Selective integration. Real databases or brokers where behavior matters.
- Sparse end-to-end tests. Only for revenue-critical or high-risk flows.
- Fast feedback. Keep the suite small enough to run often.
A practical scoring pattern
Give the candidate a flaky integration suite. Ask what they'd fix first.
- Weak. Says “add more end-to-end tests.”
- Good. Prioritizes contract stability, deterministic test data, and isolating slow dependencies.
- Excellent. Explains test ownership, failure triage, and how to keep the suite trusted by the team.
If the candidate also mentions circuit breakers and fallback-path tests, that's a sign they understand software as it fails, not just software as it's designed.
7-Point Microservices Interview Topics Comparison
| Topic | 🔄 Implementation complexity | ⚡ Resource requirements | ⭐ Expected outcomes | 📊 Ideal use cases | 💡 Key advantages |
|---|---|---|---|---|---|
| Microservices Architecture & Design Patterns | High, needs principled decomposition and architecture trade-offs | Moderate, design time, operational tooling, experienced reviewers | High, modularity and independent scaling when justified | Complex domains, large teams, services with different scale/SLAs | Promotes DDD-led boundaries; avoids over-engineering when applied prudently |
| Service Communication & API Design | Medium, choose between REST/gRPC/async and design contracts | Moderate, API gateways, message brokers, contract testing tools | High, better latency, reliability, and clear service contracts | Low-latency internal APIs, public client APIs, mixed sync/async flows | Clear contracts, versioning and fault-tolerance patterns reduce integrations risk |
| Data Consistency & Distributed Transactions | Very high, requires understanding of consistency models and patterns | High, saga/orchestrator tooling, observability, idempotency support | Critical, preserves correctness; may trade latency for safety | Financial flows, inventory/reservations, booking systems | Ensures business correctness via compensations and idempotency; prevents data loss |
| Resilience, Fault Tolerance & Observability | Medium, apply patterns (circuit breakers, bulkheads) and tracing | Moderate‑High, tracing, metrics, logging, alerting infrastructure | Very high, reduces MTTR and blast radius of failures | Any production system, especially customer-facing or high-availability apps | Faster detection and recovery, graceful degradation, reduced outages |
| Container Orchestration, Deployment & Infrastructure | High, orchestration, CI/CD, IaC and security practices needed | High, clusters, CI runners, IaC tooling, ops expertise | High, repeatable, scalable deployments and faster delivery | Microservices at scale, frequent deploy cadence, multi-env pipelines | Automates deployments, enables scaling, improves reproducibility and security |
| Service Discovery, Configuration & Secrets Management | Medium, DNS, config stores, secrets rotation and RBAC considerations | Moderate, Vault/Secrets Manager, ConfigMaps, audit tooling | High, secure, auditable, and environment-aware service connectivity | Dynamic clusters, regulated environments, teams with many services | Prevents credential leaks, supports rotation and auditability, enables safe rollouts |
| Testing in Microservices: Unit, Integration & Contract Testing | Medium, designing test pyramid and contract tests across services | Moderate, test infra, containers for integration tests, CI time | High, catches integration regressions, increases deployment confidence | Systems with external deps, CI/CD pipelines, teams aiming for low-risk releases | Reduces production bugs via contract testing and layered fast/slow tests |
Putting It All Together Your Interview Scorecard
The best hiring loops don't treat these topics as seven isolated trivia buckets. They build a whole picture. You're looking for someone who can make sound technical decisions under business constraints, explain trade-offs clearly, and operate a system after the architecture slide is gone.
A practical scorecard should rank each candidate across the seven areas above using consistent levels such as weak, good, and excellent. Keep the rubric behavioral. Did the candidate reason from user impact? Did they discuss failure modes without prompting? Did they offer remediation, not just design? Did they speak in terms of ownership, testing, and operations, or only frameworks and buzzwords?
The interview process separates book knowledge from production judgment. A candidate may be excellent in Kubernetes and still be the wrong hire if they hand-wave distributed consistency or testing. Another candidate may not have used your exact stack, but they may show the stronger pattern recognition you need. In practice, the hires that work best are T-shaped. They go deep in one area, such as platform, data consistency, or observability, and they're reliably competent across the rest.
I'd recommend using scenario prompts in the live interview, then writing the debrief in the same structure every time:
- Architecture judgment. Did they choose sensible service boundaries?
- Communication design. Did they match protocol to use case?
- Consistency thinking. Could they reason through partial failure?
- Reliability depth. Did they know how to degrade gracefully?
- Deployment maturity. Could they ship safely?
- Operational hygiene. Did they understand discovery, config, and secrets?
- Testing realism. Could they build confidence without fantasy end-to-end coverage?
There's also a talent signal many teams miss. Ask what they regret. Ask about a boundary they'd merge back. Ask what monitoring they wish they had earlier. Candidates who've really run these systems usually answer with specifics and humility. Candidates who haven't tend to stay abstract.
If you want one outside prompt to sharpen your own hiring process, this article on how candidates can dominate technical interviews is also useful from the other side of the table. It helps you see what polished but shallow answers can sound like.
If you're hiring for AI, fintech, or SaaS systems where microservices reliability affects product delivery, this kind of scorecard is worth standardizing across the panel. ThirstySprout is one option if you need help finding engineers who've shipped production systems and can work across backend, platform, and AI-heavy environments.
If you're hiring senior engineers who need to design, ship, and run microservices in production, ThirstySprout can help you meet vetted remote AI and engineering talent quickly. You can start a pilot, review sample profiles, and build an interview loop around the scorecard ideas in this guide.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.