
TL;DR
- Hire a Data Scientist to explore data, test hypotheses, and build proof-of-concept models. Their goal is to find actionable insights and answer "What if?".
- Hire a Machine Learning Engineer to build, deploy, and scale production-grade ML systems. Their goal is to ship reliable, low-latency services that customers use.
- Use our framework: First, define if your project is in an exploration or production phase. This single decision clarifies which role you need now.
- Key difference: Data Scientists deliver insights and prototype models. ML Engineers deliver scalable, production-ready software. One finds the signal; the other productizes it.
Who This Is For
This guide is for CTOs, Heads of Engineering, Founders, and Product Leaders who need to hire talent for AI-powered features.
If you are scoping roles, setting budgets, or building a hiring plan for a remote AI team, this guide provides a clear framework. We cut through the academic jargon to focus on practical, real-world decisions that directly impact your product roadmap and business outcomes. The goal is to help you hire the right person for the right job at the right time.
Quick Framework: When to Hire an ML Engineer vs. a Data Scientist
The choice between a Machine Learning Engineer and a Data Scientist boils down to one question: Is your immediate goal exploration or production?
Your answer determines which role will deliver the most value in the shortest time. Get this wrong, and you risk stalled projects and technical debt. Get it right, and you accelerate your time-to-value.
Use this decision tree to map your business need to the right hire.
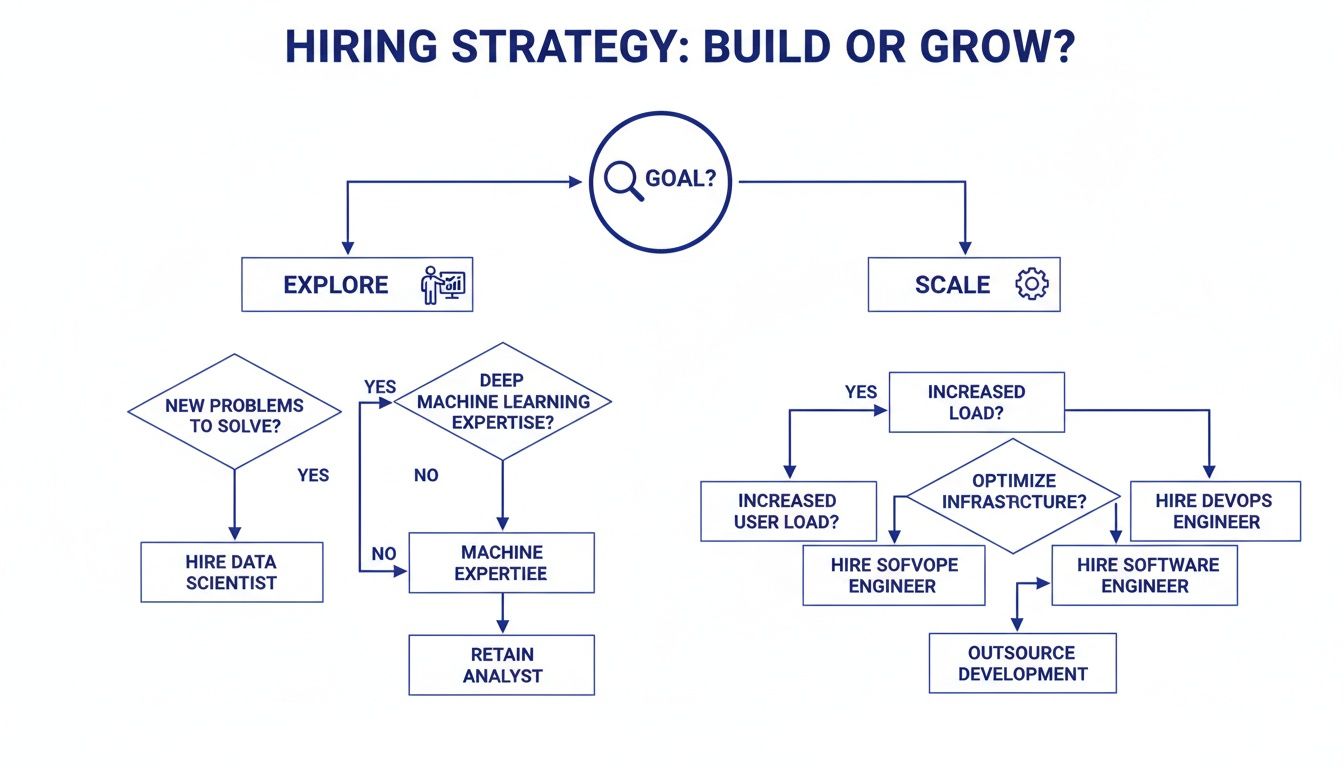
Decision Matrix: Project Stage vs. Required Role
This matrix maps common business needs to the correct role. While skills overlap, their core functions address distinct stages of the product lifecycle. Understanding this difference is also key when comparing similar roles, like an AI engineer vs ML engineer.
Practical Examples (2)
Abstract definitions are fuzzy. Let's look at two real-world scenarios to see how each role drives business impact at different stages.
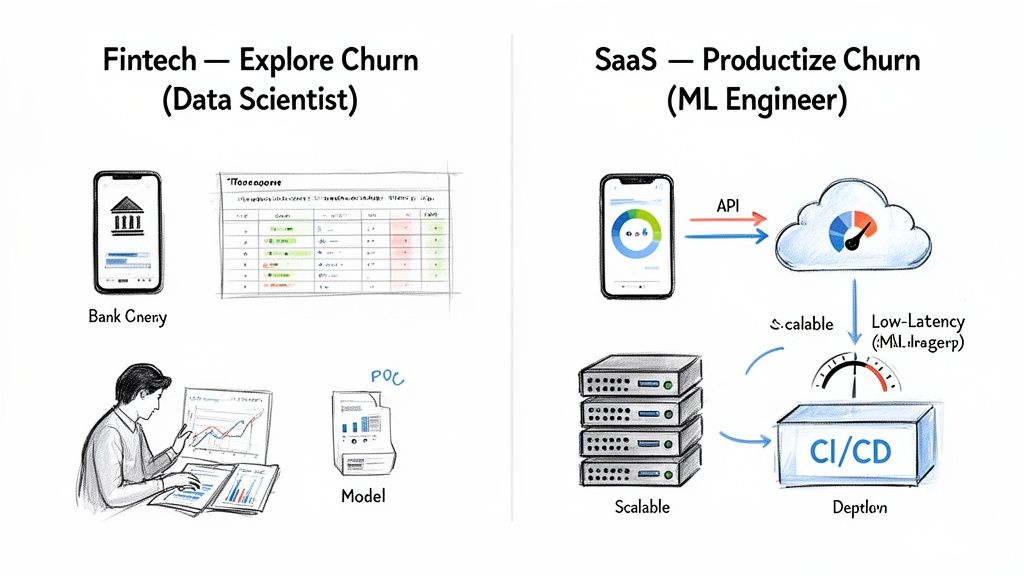
Example 1: A Fintech Startup Exploring Churn (Exploration Phase)
Imagine a Series A fintech company sees customer churn rising but doesn't know why. They need data-backed answers before investing in expensive retention campaigns.
- The Goal: Uncover the key drivers of customer churn and build a PoC model to identify at-risk users.
- The Right Hire: A Data Scientist.
The business needs answers, not a high-throughput prediction engine. A Data Scientist's workflow is built for this.
- Data Exploration: They dig into transaction histories, support tickets, and app usage logs using SQL and Python to find potential features.
- Hypothesis Testing: They use statistical methods to validate assumptions. (e.g., "Do customers with a failed transaction churn more often?")
- Model Prototyping: Working in Jupyter Notebooks, they rapidly train several models (Logistic Regression, Gradient Boosting) to find one that accurately predicts churn and explains why.
The deliverable is not a product feature. It's a report identifying the top 3–5 churn drivers and a model file (.pkl) achieving >80% accuracy in testing. This insight directly informs the product and marketing roadmap, preventing wasted effort.
Example 2: A SaaS Scale-Up Productizing Churn Prediction (Production Phase)
Now, consider a Series C SaaS company. Their data science team already validated a churn model. The new goal is to integrate real-time predictions into the product to trigger proactive retention campaigns.
- The Goal: Deploy the churn model as a scalable, low-latency service.
- The Right Hire: A Machine Learning Engineer.
The problem has shifted from research to engineering.
- Production Code: The ML Engineer refactors the Data Scientist's notebook code into a clean, modular, and tested Python application.
- API Development: They build a REST API using a framework like FastAPI to serve predictions.
- Infrastructure & Deployment: They containerize the application with Docker and deploy it on a scalable platform like AWS SageMaker or a Kubernetes cluster, ensuring it can handle thousands of requests per minute with latency under 200ms.
- Monitoring & Automation: They set up monitoring for model drift and system health, and build a CI/CD pipeline for automated model updates.
The deliverable is a production-grade system that directly reduces churn and protects revenue. The ML Engineer owns the operational excellence of the AI feature.
Deep Dive: Skills, Responsibilities, and Trade-offs
A Data Scientist's job is to turn raw data into actionable intelligence for data-driven decision making. A Machine Learning Engineer's job is to build and maintain the software systems that deliver that intelligence at scale.
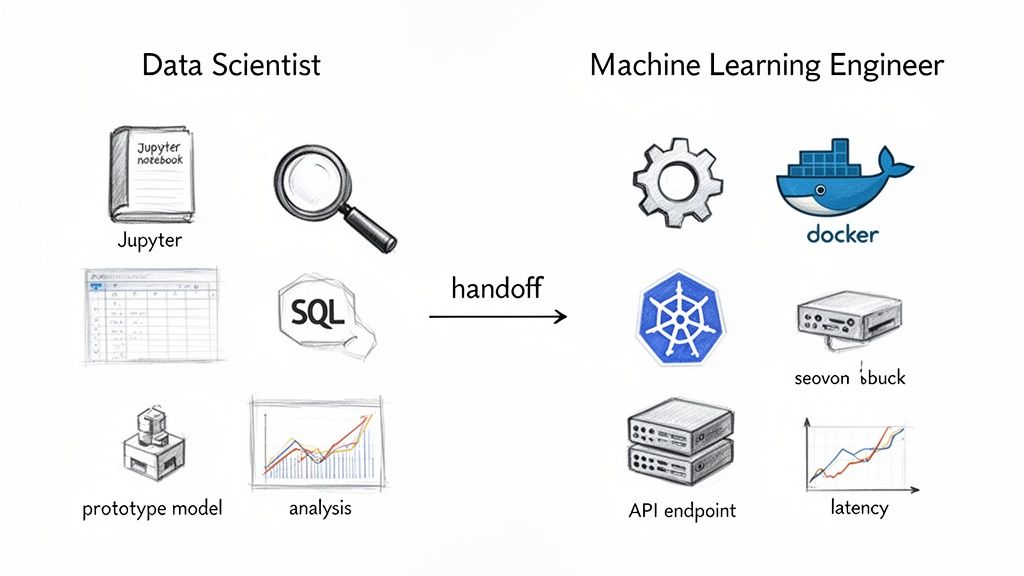
The Data Scientist: From Exploration to Insight
A Data Scientist's workflow is built around investigation and discovery.
- Core Tasks: Data exploration, hypothesis testing, model prototyping, and communicating findings.
- Key Skills: Statistics, experimental design, data visualization, and business acumen.
- Common Tools: SQL, Python (pandas, scikit-learn), Jupyter Notebook, Tableau, and Looker.
- Final Deliverable: A report, a dashboard, or a model file (
.pkl) that answers a business question and proves what is possible.
The ML Engineer: From Production to Scale
A Machine Learning Engineer’s work begins where the Data Scientist's prototype ends. More details on the core competencies can be found in our guide to the skills that define a Machine Learning Engineer.
- Core Tasks: Production code development, containerization, API development, CI/CD automation, and system monitoring.
- Key Skills: Software engineering, MLOps, system architecture, API development, and cloud computing.
- Common Tools: Python (FastAPI, Flask), Docker, Kubernetes, AWS/GCP/Azure, Prometheus, and Grafana.
- Final Deliverable: A production system—a live API, an integrated feature, or an automated training pipeline that generates business value.
Compensation, Seniority, and Trade-offs
The market consistently pays a premium for production skills. ML Engineers typically earn more than Data Scientists because their work directly ships scalable, revenue-generating products. Knowing the principles of what is salary benchmarking is critical for making competitive offers.
- Salary: Recent data shows ML engineers in the US command a median total pay of $159,000 annually versus $154,000 for data scientists. This gap widens for senior roles.
- Seniority: A junior DS might run pre-defined analyses, while a junior MLE implements a single API endpoint. A senior DS influences business strategy with data, while a senior MLE designs the architecture for entire ML platforms.
- The Trade-off: Hiring a Data Scientist first gets you answers and reduces the risk of building the wrong thing. Hiring an ML Engineer first gets you infrastructure but risks having nothing valuable to deploy on it.
Checklist: Your AI Hiring Framework
Making the right hire begins with an honest assessment of your business needs. This checklist provides a repeatable framework to move from a vague idea to a confident offer.
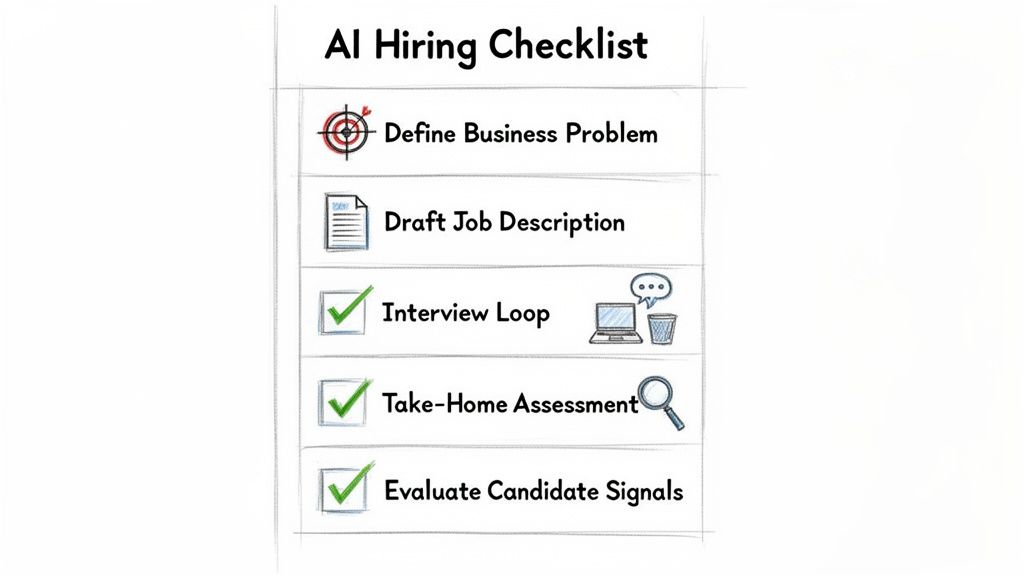
Step 1: Define the Business Problem
- Exploration (Need answers/validation): You need a Data Scientist.
- Production (Need a scalable service): You need a Machine Learning Engineer.
Step 2: Draft the Job Description
- For a Data Scientist: Use keywords like "analysis," "insights," "statistical modeling," "experimentation," and "visualization." List tools like SQL,
pandas,scikit-learn, and Tableau. - For an ML Engineer: Use keywords like "production systems," "scalability," "deployment," "MLOps," and "system architecture." List tools like Docker, Kubernetes, and FastAPI.
Step 3: Design the Interview Loop
- Data Scientist Loop: Include a statistical deep dive, a case study on A/B test design, and a non-technical presentation.
- ML Engineer Loop: Include a system design interview ("Design a real-time recommendation API"), a clean code challenge, and an MLOps discussion.
Step 4: Create the Take-Home Assessment
- Data Scientist Assessment: Provide a messy dataset and ask for an exploratory analysis and insights in a Jupyter Notebook.
- ML Engineer Assessment: Provide a pre-trained model file (
.pkl) and ask them to wrap it in a containerized API with clear instructions.
Step 5: Evaluate Candidate Signals
- Strong Data Scientist Signal: A portfolio showing how their analysis influenced product decisions. For more on evaluation, see our guide on how to hire AI engineers.
- Strong ML Engineer Signal: A GitHub profile with well-documented, production-quality code and experience maintaining live ML systems.
What to Do Next
- Define Your Stage: Use the framework above to decide if you are in the exploration or production phase for your next AI project.
- Draft a Role: Use the checklist to create a job description and interview plan that targets the exact skills you need.
- Book a Scoping Call: If you need to hire vetted, production-ready AI talent quickly, ThirstySprout can connect you with senior experts who have shipped real-world systems.
Ready to build your team?
ThirstySprout connects you with senior AI and ML experts. Start a pilot in 2–4 weeks.
References
- Salary Data: U.S. Bureau of Labor Statistics, Occupational Outlook Handbook for Data Scientists and similar roles.
- Skills & Tools: Documentation for Python, scikit-learn, Docker, Kubernetes.
- AI Engineer vs. ML Engineer: What's the Difference?
- How to Hire AI Engineers: The Definitive Guide
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.