
You're probably in the same spot many CTOs hit on their first serious LLM feature. Product wants an AI assistant that uses private company data. Engineering wants something shippable in the next two weeks. Security wants to know where the data lives. Finance wants to know whether you're buying an experiment or a long-term platform decision.
That's where LLM fine tuning vs RAG stops being an abstract AI debate and becomes an operating decision. The wrong choice usually doesn't fail on model quality first. It fails on maintenance burden, missing team skills, or governance friction that nobody priced in during planning.
LLM Fine Tuning vs RAG The Executive Summary
If you need a fast answer, use this.
- Choose Retrieval-Augmented Generation (RAG) when your feature depends on private, changing, or operational data such as docs, policies, tickets, contracts, or product updates.
- Choose fine-tuning when the job is to change the model's behavior, such as tone, output format, routing logic, or brand personality.
- RAG is usually the safer first production move for a first enterprise feature because updates happen in the data layer, not through retraining.
- Fine-tuning becomes attractive when consistency matters more than freshness, especially for structured outputs and stable tasks.
- Hybrid often wins once the use case is proven, with retrieval handling current facts and fine-tuning shaping style or domain behavior.
Here's the fast comparison most leaders need early:
| Decision factor | RAG | Fine-tuning |
|---|---|---|
| Best for | Changing knowledge | Stable behavior changes |
| Update cycle | Update documents and indexes | Retrain to absorb changes |
| Typical first project fit | Internal search, support assistant, policy Q&A | Brand voice, response formatting, classification patterns |
| Main risk | Weak retrieval leads to weak answers | Data prep and retraining become expensive |
| Team pressure point | Data pipelines and evaluation | ML training workflow and experiment management |
This guide is for CTOs, product leaders, and engineering heads who need to commit to an architecture soon, not after a quarter of research. The practical question isn't “which is better?” It's which option fits your data volatility, your team's current skills, and your governance model right now.
A useful rule: if your feature must answer from the latest internal truth, start with RAG. If your feature must always sound, format, or behave a certain way, start evaluating fine-tuning.
A short explainer is worth watching before you commit to an implementation path:
A Decision Framework for Choosing Your Approach
Decision-makers frequently make this decision too early and with the wrong inputs. They compare model capability before they've clarified whether the problem is really knowledge access, behavior control, or both.
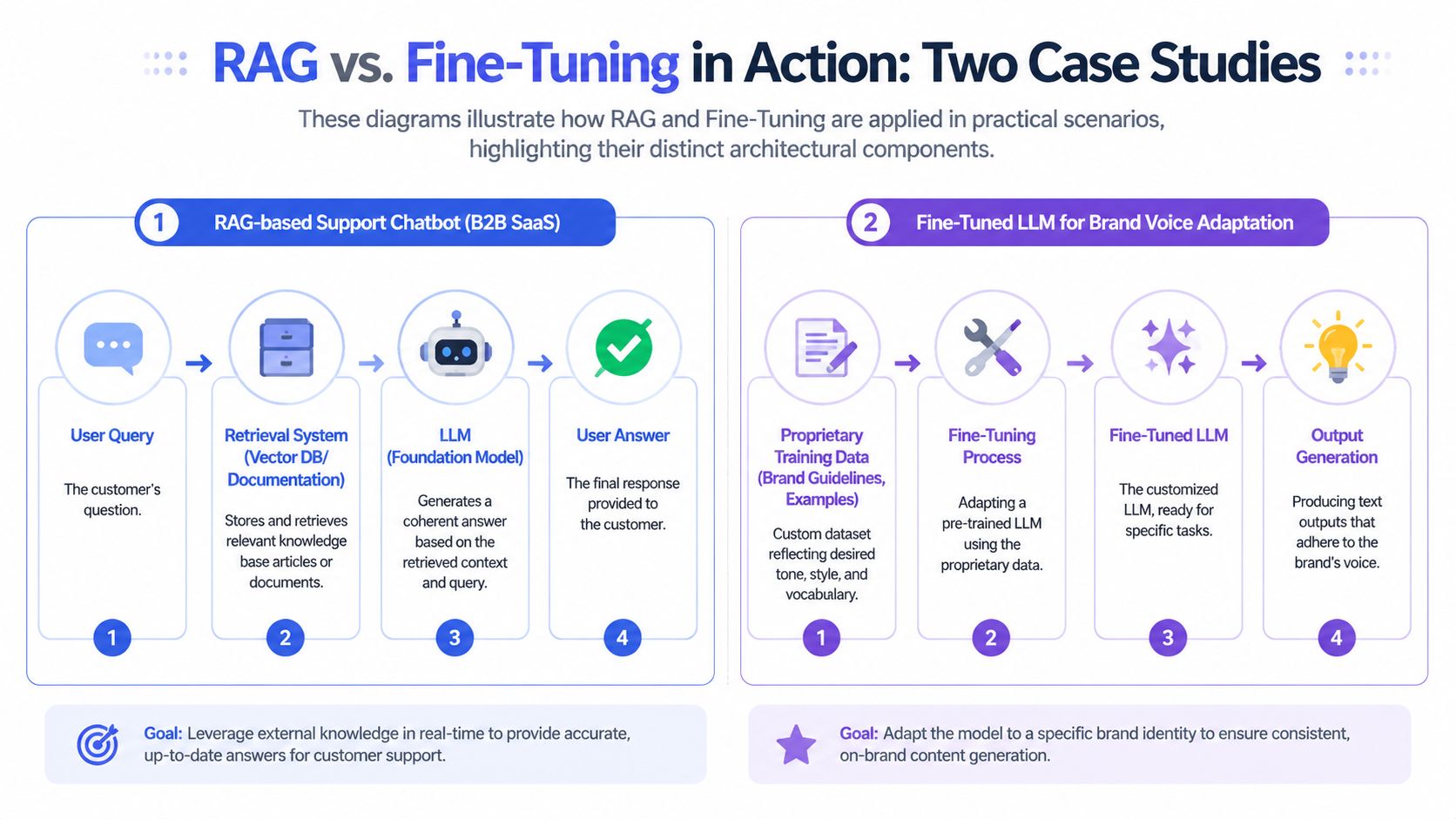
Caption: These diagrams illustrate how RAG and Fine-Tuning are applied in practical scenarios, highlighting their distinct architectural components.
Start with the business constraint
Ask these questions in order:
- Does the answer depend on information that changes often?
- Are you trying to inject knowledge, or change how the model responds?
- Can your team support retrieval infrastructure, or do you already run model training workflows?
- Where will governance be easier, in external data systems or inside model lifecycle controls?
If the feature depends on changing knowledge, RAG usually moves faster. Oracle and IBM's 2024 comparison of RAG and fine-tuning says RAG can reduce compute resource costs by up to 60% compared with fine-tuning, and notes that RAG systems can be updated instantly while fine-tuning can take days or weeks to absorb new information.
A practical decision tree
Use this in a planning meeting.
If your primary problem is freshness
- Product manuals change
- Support policies change
- Compliance rules change
- Internal knowledge is spread across docs, tickets, or wikis
Recommendation: Start with RAG.
If your primary problem is output behavior
- You need a strict response format
- You need a consistent voice
- You need the model to follow task-specific patterns repeatedly
Recommendation: Evaluate fine-tuning first.
If both are true
- Current facts matter
- Presentation style also matters
Recommendation: Design for a hybrid path, but don't build full hybrid complexity on day one unless the business case is already proven.
Practical rule: If the product manager says “it needs the latest answer,” that's usually a retrieval problem. If they say “it needs to answer like us every time,” that's usually a fine-tuning problem.
The second-order effects most teams miss
This choice also changes who you need on the team.
RAG pulls you toward data engineering, search quality, metadata design, chunking strategy, and runtime evaluation. Fine-tuning pulls you toward dataset curation, experiment tracking, GPU or managed training workflows, and model version control.
That's why early teams often derive more benefit from prompt and retrieval design before touching weights. If your team is still learning the basics of prompts, context construction, and evaluation, it helps to align first on what prompt engineering looks like in production.
Real World Examples RAG vs Fine Tuning in Action
The easiest way to make the call is to look at the failure mode you can't afford.
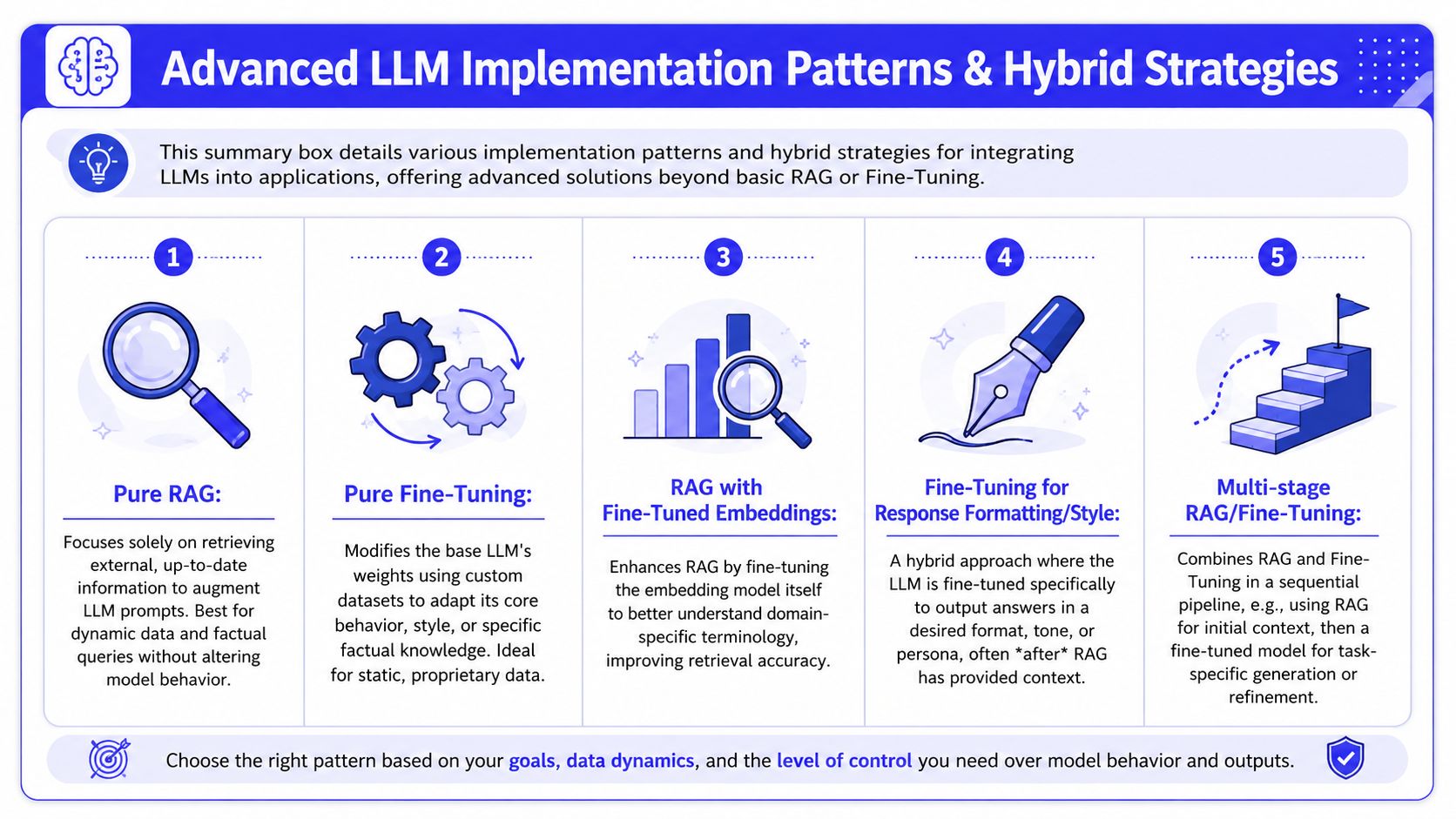
Caption: This summary box details various implementation patterns and hybrid strategies for integrating LLMs into applications, offering advanced solutions beyond basic RAG or Fine-Tuning.
Example one, a B2B SaaS support assistant
A SaaS company wants an internal and customer-facing support assistant. The product changes often. New features ship, help articles get rewritten, and enterprise customers have version-specific documentation.
In that setup, the biggest risk isn't tone. It's wrong answers from stale knowledge.
A simple architecture works:
- User asks a question
- Retrieval layer searches docs, release notes, and support content
- Foundation model answers using retrieved context
- The system logs citations and failed queries for review
This is a classic RAG use case. Actian's guidance on RAG versus fine-tuning puts it cleanly: for use cases where factual accuracy from up-to-date data is critical, like a support bot with the latest product info, RAG is the primary choice.
What works here:
- Document ownership: someone owns the source of truth for docs and release notes
- Metadata discipline: product area, version, date, and audience tags improve retrieval
- Answer review queue: unresolved or low-confidence answers get inspected weekly
- Fallback behavior: if retrieval is weak, the assistant says it doesn't know instead of guessing
What doesn't work:
- dumping a wiki into a vector database without cleanup
- skipping access control design
- judging quality only by whether the demo looks fluent
A support bot that cites the wrong version of a feature is worse than no bot. It creates new ticket volume and erodes trust fast.
Example two, a D2C brand content generator
A direct-to-consumer brand wants a copywriting assistant for product descriptions, email hooks, and ad variations. Their pain isn't factual retrieval. It's that generic LLM output sounds bland and off-brand.
That makes fine-tuning more sensible.
The training set in this case would include:
- approved campaign examples
- tone and vocabulary patterns
- examples of what the brand never says
- preferred output structures for different channels
The goal is to teach the model to behave differently, not to remember last week's pricing or inventory. RAG can inject current facts, but it won't reliably create a distinctive voice by itself.
What works here:
- Tight task scope: start with one content type, such as product descriptions
- Clear approval criteria: brand team signs off on good and bad examples
- Structured training data: input-output pairs are consistent
- Post-launch review: low-performing generations feed the next data iteration
What doesn't work:
- treating all historical brand content as training-ready
- mixing multiple tones and campaign styles without labels
- expecting fine-tuning to solve missing factual context
A third pattern worth considering
Some teams split the problem.
Use RAG to retrieve policy, product, or account context. Then use a model that has been tuned for style, formatting, or workflow compliance to produce the final answer. That can be the right move when you need both trustworthy knowledge access and predictable presentation.
Detailed Comparison Data Privacy Cost and Performance
At this juncture, the LLM fine tuning vs RAG decision becomes operational instead of conceptual. Both can work. They fail for different reasons.
RAG vs Fine-Tuning Key Trade-Offs
| Dimension | Retrieval-Augmented Generation (RAG) | Fine-Tuning |
|---|---|---|
| Knowledge freshness | Pulls from external data at runtime | Static until retrained |
| Initial cost profile | Lower entry cost for many enterprise teams | Higher initial infrastructure and engineering effort |
| Ongoing cost profile | Recurring retrieval and context costs | More cost shifted upfront into training |
| Development speed | Faster when data already exists in documents or systems | Slower because data preparation and training workflow matter |
| Privacy model | Sensitive knowledge can remain in governed stores | Sensitive patterns may become harder to isolate once embedded in weights |
| Evaluation focus | Retrieval precision, recall, and answer faithfulness | Task-specific output quality such as BLEU, ROUGE, accuracy, or F1 |
| Maintenance model | Curate data, embeddings, indexing, and retrieval quality | Curate datasets, retrain, validate, and redeploy |
| Best fit | Dynamic enterprise knowledge | Stable tasks needing behavior change |
Cost is not just a budget line
Heavybit's analysis of RAG versus fine-tuning notes that fine-tuning incurs significantly higher initial infrastructure and engineering costs than RAG, while RAG saves time and money by keeping knowledge in a retrievable layer and improving the system through retrieval pipeline changes instead of model weight changes.
That distinction matters in the first two weeks.
With RAG, teams usually spend time on:
- document cleanup
- chunking and metadata design
- vector indexing
- retrieval evaluation
- prompt templates and answer guards
With fine-tuning, the work shifts toward:
- supervised dataset creation
- data quality review
- training job orchestration
- validation sets
- regression testing across model versions
Data privacy is a design choice, not a footnote
RAG often gives security teams a more familiar control model because documents stay in external systems where access, retention, and deletion policies already exist. Fine-tuning can complicate deletion, lineage, and audit discussions because information becomes part of model behavior rather than remaining a directly governed record.
That doesn't make fine-tuning non-compliant. It means governance work moves earlier and gets more specialized.
For teams thinking about user trust and privacy expectations at the application layer, it's useful to study a concrete example like 1chat's commitment to privacy, because it shows the kind of explicit data handling posture enterprise buyers increasingly expect.
Security teams rarely block AI because of the model alone. They block it because nobody can explain where sensitive data enters, where it persists, and how it gets removed.
Performance is more than model quality
RAG and fine-tuning optimize different parts of the stack.
According to the earlier Oracle and IBM comparison, RAG prioritizes retrieval precision, recall, and answer faithfulness, while fine-tuning is commonly measured with BLEU, ROUGE, accuracy, and F1. Those aren't interchangeable goals. If you evaluate RAG like a training problem, or fine-tuning like a search problem, you'll get misleading results.
From an engineering operations angle:
- RAG performance work means better retrieval, better source curation, and tighter grounding.
- Fine-tuning performance work means better labeled data, better task framing, and stronger evaluation discipline.
If your team is building production workflows around either path, mature MLOps best practices for deployment, monitoring, and rollback are no longer optional.
The hidden trade-off is maintenance ownership
RAG creates a living system. Someone must own document freshness, index quality, and retrieval monitoring.
Fine-tuning creates a model lifecycle. Someone must own datasets, retraining triggers, validation, and release controls.
Neither path is “set and forget.” The better question is which maintenance burden matches the team you already have.
Implementation Patterns and Hybrid Strategies
The choice isn't always binary. Many of the strongest systems separate knowledge access from response behavior on purpose.

Pattern one, pure RAG
This is the best starting point when your problem is access to current information. Legal policies, support content, internal SOPs, or sales enablement materials fit here.
Use this when:
- the data changes often
- citations matter
- you want faster iteration without touching model weights
Pattern two, pure fine-tuning
This pattern fits when the output itself is the product. Think classification behavior, response style, consistent formatting, or domain-specific writing norms.
Use this when:
- the task is stable
- you can prepare clean examples
- output consistency matters more than live knowledge refresh
Pattern three, fine-tune for style, use RAG for facts
This is the preferred hybrid. The retrieval layer injects current facts. The tuned model shapes the answer into the right structure, persona, or workflow output.
Examples include:
- a financial assistant with current document retrieval and controlled advisory tone
- a legal drafting tool with current policy retrieval and consistent memo formatting
- an enterprise support assistant with up-to-date knowledge and standardized answer templates
Hybrid is worth it when one failure mode is factual error and the other is unusable formatting. If only one of those matters, keep the system simpler.
Pattern four, hybrid for knowledge-intensive domains
There is evidence that hybrid can outperform either method alone in the right context. A 2020 NIH meta-analysis on RAG, fine-tuning, and hybrid FT+RAG approaches found that RAG outperformed fine-tuning alone on knowledge-intensive tasks, while the hybrid FT+RAG approach achieved a METEOR score of 0.258, indicating stronger semantic alignment from combining domain expertise with retrieval.
The catch is operational complexity.
A hybrid system asks your team to do all of this well:
- retrieval pipeline quality
- labeled dataset curation
- training and validation
- cross-system evaluation
- governance across both data and models
If your organization is early, don't build hybrid because it sounds advanced. Build it because a plain RAG or plain fine-tuned system cannot satisfy the product requirement. If you want a deeper operating view of the model side, this guide on fine-tuning an LLM for production use is a good companion.
Your Decision Checklist and Team Skill Matrix
You can make this decision in one meeting if the right people are in the room.

Quick decision checklist
Score each item as high, medium, or low urgency for your use case.
- Does the system need current internal data to answer safely?
- Do you need a strict format, tone, or decision style?
- Do you have clean documents, or do you have clean labeled examples?
- Is it easier to govern data in external stores or in a model training lifecycle?
- Do you already have stronger data engineering skills or stronger ML training skills?
If freshness is the top concern, that points toward RAG. Monte Carlo's comparison of RAG and fine-tuning emphasizes that RAG improves factual accuracy by grounding responses in real-time external data, and that its modular design allows instantaneous data updates via vector databases without retraining.
Team skill matrix
| Capability | RAG-heavy project | Fine-tuning-heavy project |
|---|---|---|
| Data engineering | Critical | Helpful |
| Search and retrieval design | Critical | Low priority |
| Prompt and context design | Critical | Important |
| Dataset labeling workflow | Helpful | Critical |
| ML experiment tracking | Helpful | Critical |
| Model training operations | Low priority | Critical |
| Security and access control | Critical | Critical |
| Evaluation design | Critical, especially retrieval quality | Critical, especially task benchmarks |
Hiring implication most teams underestimate
RAG often looks easier because you can keep the base model unchanged. That's true at first. But good RAG still needs serious engineering around ingestion, access control, source ranking, and evaluation.
Fine-tuning often looks more direct because it promises behavior change in one place. But the hard part is almost always the dataset and validation loop, not the training call itself.
Don't ask “Can one engineer build this?” Ask “Who owns it after launch?” That question usually exposes the real architecture fit.
A practical staffing split for a first feature:
- For RAG-first builds, prioritize a strong data engineer or MLOps engineer, plus an application engineer who can instrument evaluation and fallback behavior.
- For fine-tuning-first builds, prioritize an ML engineer with data curation discipline, plus someone who can build repeatable validation and release checks.
- For hybrid, make sure you truly need both. Otherwise you'll add coordination cost before you've proven business value.
What to Do Next
Your CTO asks for a recommendation by next Friday. Product wants a pilot this quarter. Security wants to know where company data will sit. That is the point where this decision stops being a model debate and becomes an execution plan.
Start with one workflow that matters enough to ship, but small enough to evaluate quickly. Support answers, internal policy Q&A, and structured content generation are good candidates because you can define success clearly and review outputs without weeks of setup.
Then scope a pilot that your team can own after launch. Keep the data slice narrow. Lock the evaluation rubric before testing. Pick one business outcome that determines whether the pilot continues.
Review staffing and governance before you compare model vendors.
RAG is usually the faster first move when answers depend on current internal knowledge, but it also creates ongoing work that teams often under-budget. Someone has to maintain ingestion, permissions, source quality, and retrieval evaluation. If those responsibilities are unclear, the pilot may look good in a demo and fail once documents change, access rules tighten, or content owners stop cleaning up bad source material.
Fine-tuning makes more sense when you need repeatable behavior, stable output structure, or domain-specific phrasing that prompt engineering does not reliably produce. The hidden cost sits in data curation, labeling discipline, regression testing, and release management. If your team cannot produce and maintain a clean training set, the training job is the easy part and the operating model is the problem.
If both knowledge freshness and behavior control matter, treat hybrid as a phase-two option. Earn it after the first pilot proves usage, accuracy, and ownership.
A practical next step for the next two weeks:
- Pick one use case and name the business owner.
- Choose the failure you cannot tolerate. Stale answers, inconsistent format, data exposure, or high operating cost.
- Assign post-launch ownership across engineering, security, and the domain team.
- Run a pilot with a fixed rubric and a clear stop-or-scale decision.
Teams that make this decision well do not ask only which approach performs better in a test. They ask which system they can maintain, govern, and improve for the next year.
If you want to move from debate to delivery, ThirstySprout can help you Start a Pilot with senior AI engineers, MLOps specialists, and LLM builders who've shipped production systems. You can also See Sample Profiles and map the exact team you need for a RAG-first, fine-tuning-first, or hybrid rollout, including help if you need to hire remote MLOps engineers.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.