
TL;DR
- When to Fine-Tune: When you need to change a model’s behavior (style, format, complex instructions), not just give it new information. For knowledge gaps, use Retrieval-Augmented Generation (RAG) first.
- How to Fine-Tune: Use Parameter-Efficient Fine-Tuning (PEFT), specifically LoRA or QLoRA. It offers 90%+ of the performance of full fine-tuning for a fraction of the cost ($2k-$20k project cost vs. $50k+).
- What You Need: A high-quality dataset of 500–5,000 structured examples (JSONL format is best). Quality over quantity is non-negotiable.
- Actionable First Step: Scope a 2-week pilot with a 1,000-example dataset to validate if fine-tuning can meet your business goal (e.g., improve classification accuracy by 15%).
Who This Is For
- CTO / Head of Engineering: Deciding whether to invest in fine-tuning vs. RAG or a third-party API for a new AI feature.
- Founder / Product Lead: Scoping the budget, timeline, and team required to build a specialized AI capability.
- Staff+ AI/ML Engineer: Tasked with executing a fine-tuning pilot and choosing the right architecture and tools.
This guide is for technical leaders who need to make a build-vs-buy decision on a 1–4 week timeline and require a practical, no-fluff framework for success.
Your Quick Framework for Fine Tuning LLMs
Deciding to fine-tune a Large Language Model (LLM) is a major step. You're moving from using a model to actively molding its behavior. The business case isn't just a small accuracy bump; it’s about deep specialization that prompt engineering alone can't deliver.
For example, a generic model can summarize a support ticket. A fine-tuned model can output that summary in your company's exact JSON format, using your internal product codes, and flagging the sentiment metrics your product team actually uses. That is a direct boost to team efficiency.
Step 1: Choose Your Customization Path
Before you dive in, ask if fine-tuning is the right tool. You can often get what you need faster and cheaper with smart prompt engineering or a Retrieval-Augmented Generation (RAG) system.
This decision path is critical.
Alt text: A flowchart showing the decision process for LLM customization. It starts with a problem, moves to prompt engineering, then splits: if the issue is a knowledge gap, use RAG; if it's a skill or behavior gap, use fine-tuning.
The flowchart makes it clear: if your model fails because it lacks current or proprietary information, start with RAG. If it fails because it doesn’t understand how to perform a task or behave in a certain style, fine-tuning is your answer.
Key Insight: Fine-tuning teaches a model how to think, while RAG teaches it what to know. You fine-tune for behavioral changes (style, format, complex instructions) and use RAG for knowledge injection (latest company docs, product specs).
Step 2: Decide Between Full Tuning and PEFT
If fine-tuning is the right path, your next decision is the method. This choice directly impacts your budget, timeline, and the talent you need.
For nearly every business case, Parameter-Efficient Fine-Tuning (PEFT) is the correct choice.
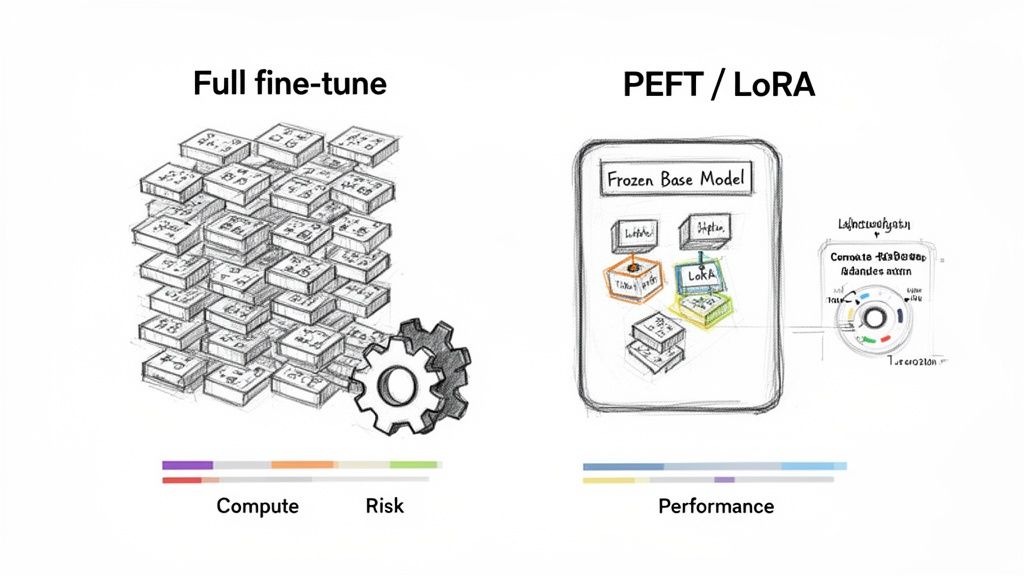
Alt text: A diagram comparing Full Fine-Tuning, which updates all model weights and is costly, with PEFT/LoRA, which freezes the base model and trains small, efficient adapters, reducing cost and risk.
Full Fine-Tuning: The Heavy-Lifting Approach
Full fine-tuning updates every single weight in the model (e.g., all 7 billion parameters). It offers maximum power to alter model behavior but has serious drawbacks:
- Massive Cost: Requires a cluster of high-end GPUs, pushing costs into the tens or hundreds of thousands of dollars.
- High Risk: Prone to "catastrophic forgetting," where the model forgets its general knowledge and becomes over-specialized.
- Large Data Needs: Requires a much larger dataset to avoid overfitting.
This method is mainly for deep-pocketed R&D teams creating new base models. For 99% of companies, it’s overkill.
PEFT and LoRA: The Pragmatic Choice
PEFT methods freeze the base model and train a tiny fraction of new parameters. The most popular PEFT method is Low-Rank Adaptation (LoRA).
LoRA adds small, trainable "adapter" modules into the model's layers. During training, only these lightweight adapters (often <1% of the model's size) are updated. This approach provides 90-95% of the performance of a full fine-tune for a fraction of the cost and time. You can explore more about these fine-tuning cost trends on consultingwhiz.com.
Practical Examples of Fine-Tuning in Action
Theory is good, but real-world application is better. Here are two examples of how teams use PEFT to solve specific business problems.
Example 1: FinTech Transaction Classification with QLoRA
A fintech startup needed to classify bank transactions into its proprietary categories. Off-the-shelf models like GPT-4 couldn't handle their nuanced business logic.
- Problem: A generic model saw "Stripe Transfer" and incorrectly labeled it a software expense, when it was a customer payout.
- Solution: We used QLoRA, a memory-efficient version of LoRA, to fine-tune an open-source 7-billion parameter model.
- Data: A targeted dataset of just 5,000 hand-labeled transaction descriptions.
- Outcome: The fine-tuned model achieved 98% accuracy on their custom categories. The entire fine-tuning run cost less than $100, and the model now runs on affordable infrastructure. This translated to a 40% reduction in manual review time for their operations team.
Example 2: Generating Structured API Support Snippets
A SaaS company was drowning in support tickets about their complex API. Human agents spent hours writing repetitive code examples for authentication and endpoint usage.
- Problem: A generic LLM knew nothing about their private, versioned API. A RAG system was too slow for their real-time chat support goals.
- Solution: We used a "distillation" strategy. We prompted GPT-4 with their internal API documentation to generate 5,000 high-quality question-and-answer pairs, formatted in a structured JSONL format.
- Data Format Snippet (JSONL):
{"messages": [{"role": "system", "content": "You are a helpful assistant for 'InnovateAI'. Answer API questions with code examples."},{"role": "user", "content": "How do I authenticate a request to the /v2/analytics/query endpoint?"},{"role": "assistant", "content": "To authenticate a request to `/v2/analytics/query`, include an `Authorization` header with your API key: `Authorization: Bearer YOUR_API_KEY`."}]} - Outcome: We used this synthetic dataset to fine-tune a 7B model with LoRA. The new model could answer 90% of API-related questions accurately, cutting agent workload by 30% in the first month. The entire pilot took three weeks.
Deep Dive: The Fine-Tuning Workflow & Pitfalls
A successful fine-tuning project is a disciplined engineering process, not an art. It moves from data preparation to deployment with clear checkpoints.
Step 1: Build Your Data Pipeline
Your model is only as good as your data. The goal is to build a small, laser-focused dataset that demonstrates the exact behavior you want to teach.
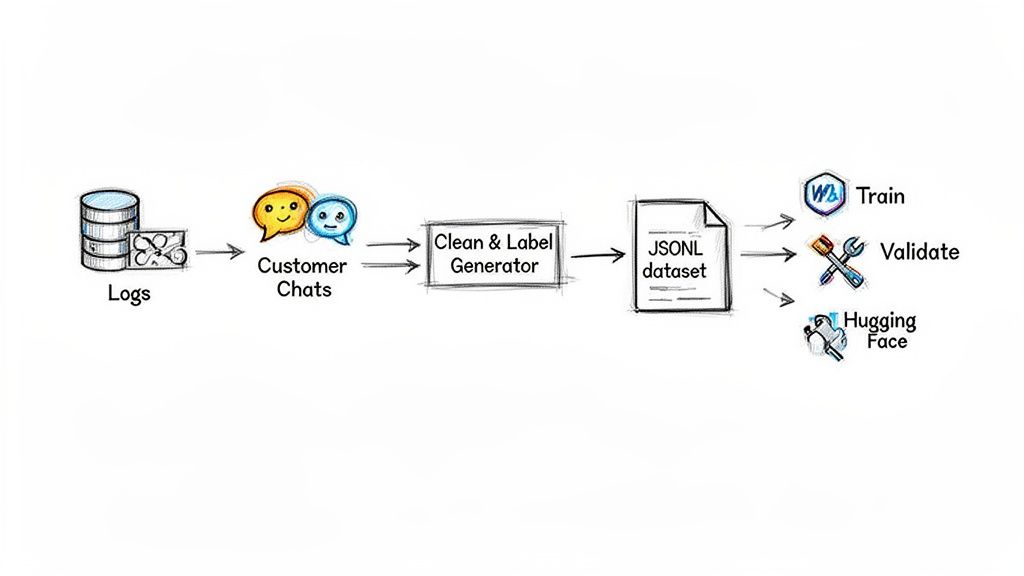
Alt text: A diagram of a data pipeline for LLM fine-tuning. It shows raw customer chats being processed, cleaned, and formatted into a structured JSONL dataset ready for training.
A robust data pipeline includes:
- Ingestion: Scripts pull raw data from sources like support chats or sales call transcripts.
- Preprocessing: Clean text, remove PII, and format it into a structured format like JSON Lines (JSONL), where each line is a JSON object representing one training example.
- Validation & Splitting: Split data into training (
80%), validation (10%), and test (~10%) sets. This is non-negotiable for preventing overfitting. - Versioning & Storage: Store versioned datasets in a central repository like S3 or Hugging Face Datasets. Use tools like Weights & Biases to track experiments and link models to specific data versions. To learn more, check out our guide on the best data pipeline tools.
Step 2: Train the Model
With a clean dataset, you can launch the training job. Using libraries from Hugging Face, you'll configure key LoRA hyperparameters.
- Rank (
r): The size of the trainable adapters. Start small (8 or 16) for faster training and less risk of overfitting. - Alpha (
α): A scaling factor. A common rule of thumb isalpha = 2 * r. - Learning Rate: Controls how quickly the model learns. Start in the
1e-4to3e-5range.
Example LoRA Configuration Snippet:
# A practical configuration for a LoRA fine-tuning jobfrom peft import LoraConfiglora_config = LoraConfig(r=16, # Rank of the adapter matriceslora_alpha=32, # Scaling factor (2 * r)lora_dropout=0.05, # Dropout to prevent overfittingtarget_modules=["q_proj", "v_proj"], # Apply LoRA to attention layerstask_type="CAUSAL_LM",)Annotation: This configuration creates small, efficient adapters (r=16) and applies them to the query and value projections in the model's attention mechanism, a common and effective strategy.
Step 3: Evaluate for Business Impact
A dropping loss curve is not a business outcome. You must evaluate for real-world performance.
- Quantitative: Benchmark against your test set using metrics like precision, recall, and F1-score for classification tasks.
- Qualitative: Conduct side-by-side comparisons. Have a human expert review outputs from the base model and your fine-tuned model against the same prompts. This is the only way to truly assess improvements in tone, style, or instruction following.
- Adversarial: Actively try to break your model. Test for safety, bias, and alignment by feeding it prompts designed to trigger harmful or off-topic responses.
Step 4: Deploy for Efficiency
Getting your trained model into production affordably is critical for ROI.
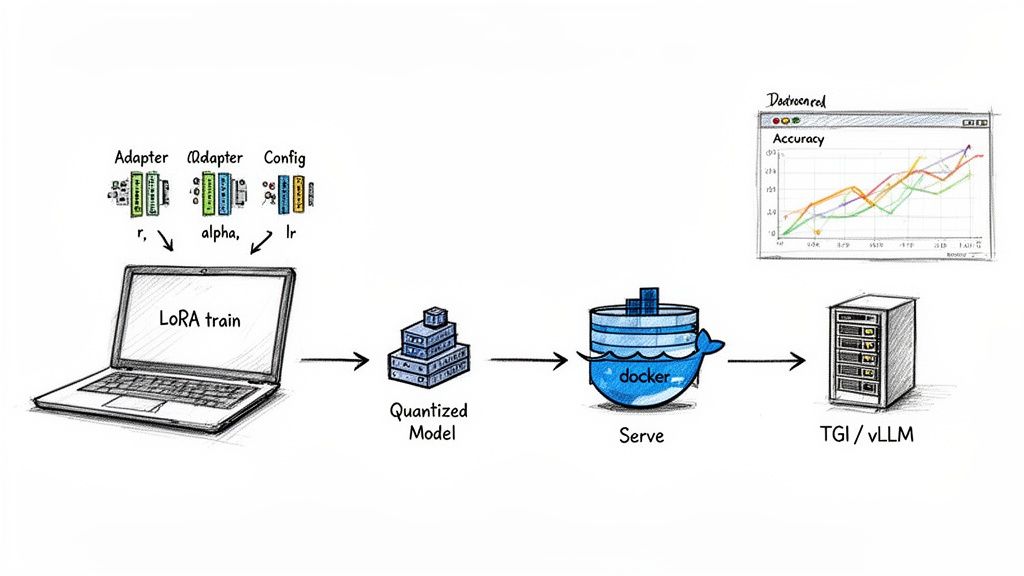
Alt text: A workflow for LLM deployment. It shows a LoRA-trained adapter being quantized, packaged in Docker, and served via an optimized inference server like TGI or vLLM, with monitoring for performance.
- Quantization: Use 4-bit or 8-bit quantization to shrink the model's memory footprint by up to 75% and speed up inference with minimal performance loss.
- Containerization: Package the model and dependencies into a Docker container for portability.
- Optimized Serving: Use a specialized inference server like Text Generation Inference (TGI) or vLLM. Their features, like continuous batching, can dramatically increase throughput and reduce latency.
Smart deployment can cut inference costs by 50-90%, turning an expensive experiment into a profitable feature. For a broader look, see our guide on machine learning model deployment tools.
Common Pitfalls to Avoid
The most common failure modes are strategic, not technical.
- Overfitting: Your model memorizes the training data but can't generalize. Your validation loss will be flat or increasing while your training loss plummets. Fix: Use a larger, more diverse dataset or reduce training time.
- Catastrophic Forgetting: A risk with full fine-tuning. The model becomes a specialist but forgets its general abilities. Fix: Use PEFT/LoRA, which freezes the base model to prevent this.
- Wrong Base Model: Trying to fine-tune a coding model like Code Llama to write poetry is an expensive uphill battle. Fix: Start with a base model that already has the core capabilities you need.
Research confirms these trade-offs. A 2024 study showed that while full fine-tuning with a large dataset yields top accuracy, Quantized LoRA (QLoRA) retains 90-95% of that performance while training over 99% fewer parameters. It's a game-changer for teams with limited GPU access. You can discover the full research about these fine-tuning trade-offs.
Checklist: Is Your Fine-Tuning Project Ready?
Use this checklist to ensure your project is set up for success before you commit significant resources.
Strategy & Scope
- You have confirmed that prompt engineering or RAG cannot solve your problem.
- Your goal is to change model behavior (style, format, skill), not inject knowledge.
- You have a clear business metric to measure success (e.g., reduce agent response time by 20%, increase classification accuracy to 95%).
- You have selected a base model aligned with your target task (e.g., instruction-tuned for chat, code model for generation).
Data & Preparation
- You have sourced a high-quality dataset of at least 500 examples.
- Your data is cleaned, anonymized, and formatted into structured JSONL.
- You have split your data into training, validation, and test sets.
- Your data pipeline is versioned and repeatable.
Execution & Deployment
- You have chosen a PEFT method like LoRA or QLoRA.
- You have a plan for both quantitative (metrics) and qualitative (human review) evaluation.
- Your deployment plan includes quantization and an optimized inference server.
- You have the right team in place: an AI/ML engineer for experimentation and an MLOps engineer for production.
What to Do Next
- Scope a 2-Week Pilot: Define a narrow business problem and gather a 500-example dataset. The goal is to get a quick signal on whether fine-tuning is viable.
- Identify Your Team: Determine if your current team has the AI/ML and MLOps skills needed for the pilot. Consider fractional experts to accelerate the process. Our guide on building an AI-native engineering team can help.
- Start Your Pilot: If you need expert support, ThirstySprout connects you with vetted AI and MLOps engineers who have the practical experience to de-risk your project and deliver results.
Ready to build a team that can ship production AI? Start your pilot today.
References
- LoRA: Low-Rank Adaptation of Large Language Models - Hugging Face Docs
- QLoRA: Efficient Finetuning of Quantized LLMs - arXiv:2305.14314
- A Survey on In-context Learning (discusses fine-tuning vs. RAG) - arXiv:2403.11524
- How to Build an AI-Native Engineering Team - Prommer.net
- Cross-Functional Team Building - ThirstySprout
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.