
You’re probably in one of two situations right now. You need to hire someone who says they “know MongoDB,” or you’re preparing candidates for a process where shallow answers won’t survive the second round. In both cases, most interview loops fail for the same reason. They test memorized definitions instead of operational judgment.
That’s a mistake. MongoDB interviews should tell you whether a candidate can model data cleanly, keep queries fast, scale safely, and avoid production incidents. That matters even more in AI and data teams, where MongoDB often sits under feature stores, event pipelines, model metadata, prompt catalogs, and application backends that can’t afford sloppy schema or indexing decisions.
These 10 interview questions on mongodb give you a tighter way to evaluate candidates from junior through senior. Each one includes what a strong answer sounds like, what follow-up questions expose weak understanding, and what mini-task you can use if you want proof instead of talk. You’ll also see where startup and enterprise expectations diverge. A seed-stage engineer may need to make clean trade-offs fast. A senior enterprise hire needs to think about failover, write concern, shard key design, backup recovery, and operational risk.
MongoDB’s adoption has grown substantially since its launch by 10gen in 2009, with the first stable release in 2010 and sharding becoming production-ready by 2013 through mongos, config servers, and automatic chunk balancing, according to this MongoDB interview overview from InterviewBit. That’s exactly why these topics keep showing up in interviews. They’re not trivia. They’re the difference between a system that works in development and one that survives production load.
Use this list as an interview pack. Ask the core question. Push on the follow-up. Then give the mini-task. You’ll learn more in 15 minutes than you will from an hour of buzzwords.
1. Document Structure and Data Modeling in MongoDB
A candidate joins your AI platform team and models every relationship the same way. Three months later, user profiles are bloated, fraud reviews are slow, feature lookups need extra round trips, and nobody can explain which collections own which data. Start your MongoDB interview here because weak data modeling creates downstream problems in performance, scaling, and maintainability.
Ask this: How would you model related data in MongoDB, and when would you embed versus reference?
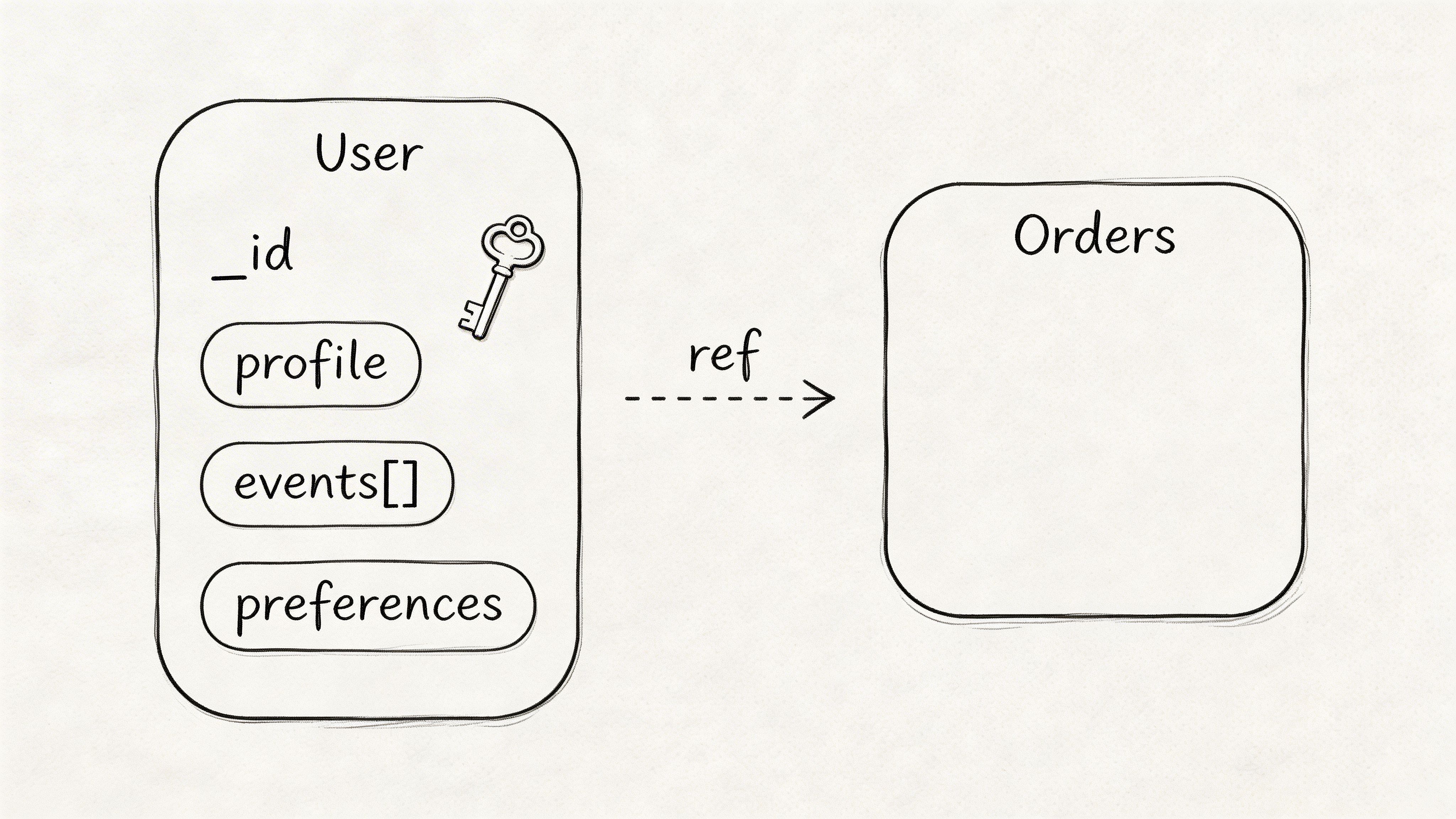
Strong candidates start with access patterns, ownership, and growth limits. If the application reads data together and the child set stays bounded, embed it. If records grow without a clear cap, change independently, or need separate lifecycle rules, reference them. I want that logic stated plainly.
Use a real scenario. A recommendation system often needs the current user profile and a short window of recent interactions on every request. The right answer is usually to embed a bounded recent-history snapshot inside the user document and keep long-term event history in a separate collection. That design cuts read complexity for the hot path while protecting the document from unbounded growth.
This is also where hiring gets more precise. Startup candidates should make a clean trade-off fast. Enterprise or senior AI/data candidates should go further and explain schema versioning, update contention, document size risk, and how the model affects downstream pipelines, audit requirements, and service boundaries.
Model answer you want to hear
A strong answer includes these points:
- Embed for hot reads: Keep related fields together when the application fetches them together on the critical path.
- Reference for unbounded or shared entities: Split data into separate collections when child records grow continuously, require independent updates, or are reused across services.
- Set document boundaries on purpose: Define what a document owns. Do not mix profile data, event logs, and workflow state into one catch-all record.
- Plan schema evolution: Add a schema version field and a migration approach before multiple writers create inconsistent shapes.
- Use validation early: Apply collection validation so teams do not slowly corrupt the model with optional fields and conflicting types.
- Design for workload, not theory: A customer dashboard, a fraud queue, and a batch feature job may need different read models from the same source entities.
Practical rule: Ask the candidate to justify one schema choice using query frequency, update pattern, growth limit, and failure mode. If they cannot do that, they do not understand MongoDB modeling well enough.
One useful follow-up is operational. Ask how their model would affect caching, especially for read-heavy APIs that sit in front of MongoDB. Candidates who understand production systems can connect document shape to cache key design, invalidation complexity, and response size. If you want a simple reference point for that discussion, see this guide to Node.js caching patterns for read-heavy application paths.
Follow-up questions that expose weak understanding
Use one or two of these. Do not ask all of them unless you want a long technical screen.
- What would make you reverse an embed decision later?
- How do you stop embedded arrays from growing without limit?
- When would you duplicate a small amount of data across documents on purpose?
- How would you model a feature store record with feature metadata, owner, version, and rollout status?
- What breaks if two services write different shapes into the same collection?
Good candidates talk about bounded arrays, archival collections, selective duplication, validation rules, and migration strategy. Weak candidates fall back to “MongoDB is flexible,” which is exactly the problem.
Mini-task and scoring rubric
Mini-task: Give them three entities, User, Order, and OrderEvent. Ask them to sketch a model for:
- a customer dashboard,
- a batch analytics pipeline,
- a fraud-review tool.
What you want to see:
- Junior: Identifies basic embed versus reference trade-offs and can explain the main read path.
- Mid-level: Accounts for document growth, write frequency, and query simplicity.
- Senior: Explains ownership boundaries, schema versioning, update contention, archival strategy, and how the model supports both product features and data workloads.
The best answers change the model based on the use case instead of forcing one “pure” design across all three. This is a definitive evaluation. MongoDB rewards candidates who can model for actual access patterns, not candidates who repeat generic rules.
2. Indexing Strategies and Query Optimization
If a candidate says they know MongoDB, indexing should come up fast. Ask this early: How do you decide what indexes to create, and how do you verify that they’re helping?
This separates real operators from people who’ve only used MongoDB on toy projects. Strong candidates know indexes are not “always add more.” They improve reads, but they add write overhead and storage cost.
MongoDB indexing is a top interview topic because it can produce up to 100x query speedup when designed well, but updates can also incur extra maintenance and over-indexing can bloat storage, according to the same source. That’s exactly the trade-off your candidate needs to articulate.
Model answer you want to hear
A good answer starts with query patterns, not with index types. The candidate should say they inspect filters, sorts, and projections, then create the smallest useful set of indexes to support those paths. I also want them to mention explain('executionStats') and the difference between IXSCAN and COLLSCAN.
A practical example works well here. Suppose your training data pipeline retrieves events by user_id and sorts by latest timestamp. The candidate should propose a compound index like:
db.events.createIndex({ user_id: 1, timestamp: -1 })That answer gets stronger if they add that $match should happen early in aggregation and that partial indexes are useful when only a subset of documents matter, such as active users.
If they bring up caching as a complement, not a substitute, that’s a good sign. For app teams running hot read paths, pairing sound MongoDB indexing with a Node.js caching strategy often reduces unnecessary database pressure.
Bad sign: the candidate lists text, geospatial, and TTL indexes but never explains when they’d choose one.
Follow-up and scoring
Ask this next: What happens if you add too many indexes to a write-heavy collection?
Good answers should mention:
- write amplification,
- extra storage,
- slower updates,
- the need to remove unused indexes,
- validating real usage before keeping an index.
Mini-task: Give them a query and a collection shape. Ask them to propose an index, then tell you what they’d look for in explain() output. A junior can identify a basic single-field or compound index. A senior should also talk about index order, covered queries, maintenance cost, and when not to index.
3. Aggregation Pipeline and Data Processing
Ask this when you want to know whether the candidate can do more than CRUD: How would you build an aggregation pipeline for analytics or feature engineering in MongoDB?
This question matters because many AI and data workloads depend on transforming raw events into usable inputs. If the candidate can’t reason through aggregation stages, they’ll struggle with real reporting, ETL, or model-prep work.
A useful scenario is user events for a recommendation system. Ask them to compute per-user event counts and recent activity windows. Strong candidates will usually reach for $match, $group, $sort, and maybe $project without wasting effort on irrelevant stages.
For visual learners in your interview loop, this walkthrough helps ground the discussion:
What to listen for
You want practical sequencing. MongoDB indexing guidance emphasizes placing $match early so the pipeline can use indexes before expensive stages. The same verified guidance also notes that moving $match early in aggregation can cut CPU significantly in indexed workloads, and covered queries can avoid document reads entirely, based on the indexing summary already cited earlier. You don’t need candidates to quote numbers. You need them to apply the principle.
A strong answer usually sounds like this:
- Filter first: Use
$matchearly to reduce the working set. - Shape data deliberately: Use
$projectto keep only the fields the pipeline needs. - Aggregate carefully: Use
$grouponly after narrowing the data. - Debug in slices: Test one stage at a time, not the whole pipeline blindly.
A realistic mini-task is to ask for a pipeline that prepares daily event summaries for model training. Candidates who’ve worked on actual data systems may mention bucketing by time window, grouping by user or entity, and writing outputs to another collection.
If your data team also runs Python-based pipelines, it’s useful to compare their MongoDB answer with how they’d handle a broader ETL workflow in Python. Strong candidates understand where database-native transformation ends and external processing should begin.
Keep pushing if they only describe stages by name. Ask why each stage belongs where it does.
Follow-up
Ask: When would you move a transformation out of MongoDB and into Spark, Python, or another processing layer?
A senior candidate should talk about complexity, memory pressure, operational clarity, and ownership boundaries, not just personal preference.
4. Replication and High Availability
Your model API is live, traffic spikes, and the primary node drops. The candidate in front of you either knows what happens next or they don’t. That is why replication questions matter. They expose operating judgment fast.
Ask: How do replica sets work in MongoDB, and how would you use them for high availability?
A hireable answer explains the election process, write routing, replication lag, client behavior during failover, and the trade-off between fresher reads and higher read capacity. If someone stops at “one primary, multiple secondaries,” keep pushing. That answer is textbook memory, not production experience.
What a strong answer should include
Candidates should explain the normal path first. The primary accepts writes. Secondaries copy the oplog and stay close enough to take over if the primary fails. During an election, one eligible secondary becomes the new primary, and the application must tolerate a short period of write disruption while drivers reconnect and reroute requests.
Then test whether they understand application-level consequences. Good candidates mention write concern, read preference, retryable writes, and idempotency. They should know that w: "majority" reduces the risk of acknowledging writes that disappear after failover, and that reading from secondaries can return stale data.
Use a concrete scenario. An AI feature store, inference metadata service, or annotation platform may run a three-node replica set. Online writes go to the primary. Offline analytics or low-priority read jobs may use secondaries if slight staleness is acceptable. For enterprise roles, expect candidates to mention stricter consistency expectations, election tuning, and observability. For startup roles, accept a leaner answer if they still understand the failure path and the app behavior.
Follow-up questions that separate levels
Ask: Would you let model training jobs read from secondaries? Why?
A weak candidate gives a yes or no. A strong one asks about tolerance for stale data, replication lag, feature freshness, and whether the training pipeline can absorb small inconsistencies without corrupting labels or offline evaluation.
Ask: What should the application team verify after a primary failover?
Look for these points:
- Driver reconnection and topology discovery work as expected
- Retry logic does not create duplicate side effects
- Write concern matches the business risk
- Read preference does not send latency-sensitive requests to stale nodes
- Replication lag and election events are monitored
- Runbooks and failover drills exist, not just assumptions
Mini-task for the interview
Give them this prompt: The primary fails during peak inference traffic. Walk me through the next 60 seconds.
A strong candidate will describe election behavior, temporary write errors, driver retries, possible stale reads from secondaries, alerting, and the checks they would run after recovery. A senior candidate will also mention what they would test before production. Failover drills, connection pool settings, and request idempotency usually come up.
How to score the answer
Use a simple rubric.
- Basic: Knows primary and secondary roles, mentions automatic failover
- Mid-level: Explains elections, read preference, replication lag, and write concern
- Senior: Connects failover behavior to application correctness, SLOs, driver settings, and incident response
- Strong fit for AI or data platforms: Can judge when stale reads are acceptable for training, analytics, feature generation, or backfills, and when they would break product behavior
This section is where your interview pack should do more than ask a definition. Use the model answer, the follow-up, the mini-task, and the rubric together. That gives you a cleaner signal on whether the candidate can run MongoDB under pressure, not just describe it.
5. Sharding and Horizontal Scaling
A candidate can recite what shards, mongos, and config servers do and still make a bad production decision. Ask the question that exposes judgment: When would you shard a MongoDB collection, and how would you choose the shard key?
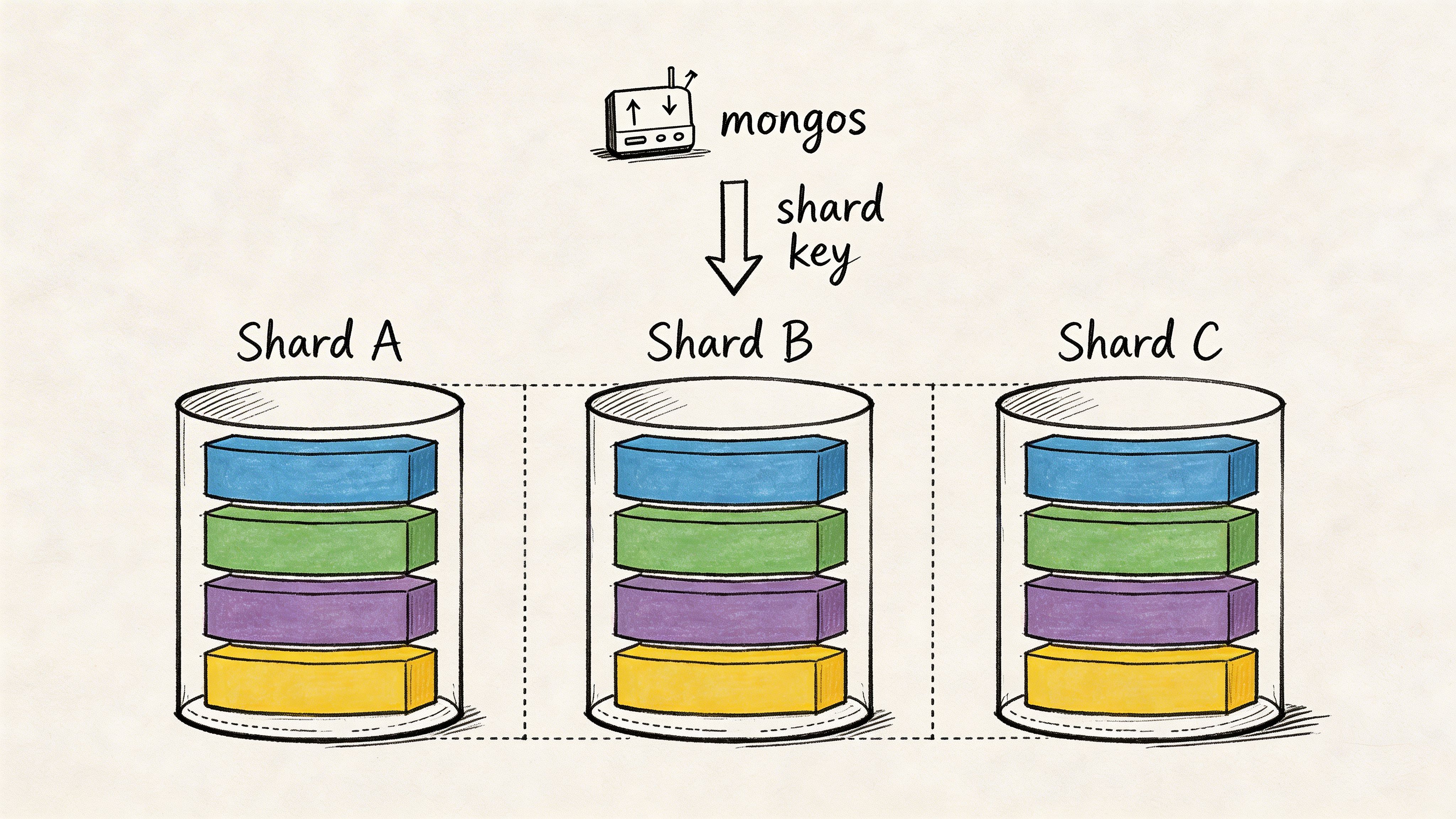
The best candidates start with the trigger, not the definition. You shard when a single replica set can no longer handle storage growth, write throughput, or query load within your latency and cost targets. Then you pick a shard key based on workload shape, because the shard key decides data distribution, hotspot risk, and whether queries hit one shard or many.
What a strong answer sounds like
A senior candidate should explain chunk splitting and balancing in plain language, then spend most of the answer on shard key tradeoffs. That is the decision that sticks.
Look for these points:
- High cardinality: A shard key with many distinct values spreads data and write load better.
- No monotonic insert pattern: Sequential values can push fresh writes to one shard and create a hotspot.
- Query alignment: The key should match common filters, especially high-volume reads and writes.
- Hashed or compound keys when appropriate: Hashed keys help distribution. Compound keys can balance distribution with query targeting.
If a candidate says the shard key can always be changed later, mark that down. Resharding is possible, but it is still an expensive correction to a bad design choice. Strong candidates treat shard key selection as an architecture decision with migration cost, operational risk, and application impact.
Model answer
A solid answer sounds like this:
“I would shard when vertical scaling stops meeting growth or latency targets, or when one replica set becomes a write or storage bottleneck. I would choose a shard key by looking at the highest-volume queries and write patterns first. I want enough cardinality to distribute data well, and I want to avoid a key that increases in order because that can concentrate new writes on one shard. If reads often filter by tenant and time, I would test a compound key that supports those access patterns. If write distribution matters more than targeted reads, I would consider a hashed key. I would also check how many queries become scatter-gather queries after sharding, because a well-distributed key can still be a poor key if every important query fans out to every shard.”
That answer shows operational thinking. It connects MongoDB mechanics to application behavior.
Follow-up questions that separate mid-level from senior
Use follow-ups fast. This topic gets shallow if you let candidates stay at the definition level.
Ask:
- What makes a shard key bad even if distribution looks even?
- When would you choose a hashed key over a ranged key?
- What queries turn into scatter-gather after your design, and is that acceptable?
- How would you shard multi-tenant AI workload data where some tenants are much larger than others?
- When would zone sharding make sense?
A senior candidate should talk about geographic placement, data residency, or workload isolation for zone sharding. For AI and data roles, listen for whether they can separate online serving traffic from analytics or backfill patterns. Startup candidates should show speed and pragmatism. Enterprise candidates should add compliance, tenant isolation, and migration planning.
Mini-task for the interview
Give them this prompt: A recommendation system stores user events with customerId, eventType, and timestamp. Write volume spikes every evening, and one shard is taking most of the insert load. Redesign the shard key and explain the tradeoffs.
Good candidates will reject timestamp alone. Better candidates will compare options such as a hashed customerId, or a compound key that reflects tenant and access patterns. The strongest candidates will ask one more question before answering: what queries matter most, real-time lookups by customer, recent-event windows, or large analytics scans?
That question matters because the right shard key for a startup event stream may be wrong for an enterprise feature store.
How to score the answer
Use a simple rubric.
- Basic: Knows that sharding spreads data across shards and mentions
mongos - Mid-level: Explains shard keys, hotspots, chunk balancing, and scatter-gather risk
- Senior: Chooses between hashed, ranged, and compound keys based on workload shape and query patterns
- Strong fit for AI or data platforms: Connects shard design to tenant skew, time-series write patterns, batch backfills, compliance placement, and migration cost
This topic should test design judgment under realistic load, not memorized terminology. Use the model answer, follow-ups, mini-task, and rubric together. That gives you a much cleaner hiring signal for MongoDB roles in startups and enterprise AI teams.
6. Transactions and ACID Compliance
Ask this when the role touches billing, workflow coordination, model registry updates, or any data path where partial writes are unacceptable: When should you use transactions in MongoDB, and when should you avoid them?
This question filters out candidates who swing to extremes. Some people still talk as if MongoDB can’t handle transactions. Others try to wrap every write in one. Both are wrong.
Good answer versus weak answer
A strong candidate will say single-document operations are already atomic, and multi-document transactions should be reserved for cases where consistency across documents or collections matters more than throughput cost. They’ll also say schema design should reduce the need for transactions where possible.
Use a practical scenario. A model deployment flow updates:
- the model registry,
- the serving configuration,
- the feature manifest.
If all three must succeed together, a transaction can make sense. If the system can tolerate asynchronous reconciliation, then an event-driven design may be cleaner and cheaper.
Good candidates usually mention:
- sessions,
- retry behavior for transient failures,
- keeping transactions short,
- using appropriate write concern for durability.
Interview mini-task
Give them this prompt: “A fine-tuning pipeline writes a dataset record, a validation record, and a training job record. Validation fails after the first two writes. How would you keep the system consistent?”
A junior candidate may say “use a transaction.”” That’s acceptable as a starting point. A senior should go further and ask whether those records require synchronous atomicity, whether one document model could reduce the problem, and how retries or idempotency should work.
Strong engineers don’t just know that transactions exist. They know when the business cost of inconsistency justifies them.
What to probe next
Ask: What are the downsides of long-running transactions in a busy system?
Good candidates should discuss contention, resource use, operational complexity, and the importance of minimizing the transaction scope. You’re not testing textbook ACID definitions. You’re testing whether they can protect correctness without dragging down the rest of the platform.
7. Change Streams and Real-Time Data Capture
A lot of candidates know CRUD, indexing, and maybe aggregation. Fewer can speak clearly about event-driven systems. That’s why this question is useful for AI platforms, internal tools, and products with live updates.
Ask: What are MongoDB change streams, and how would you use them in a production system?
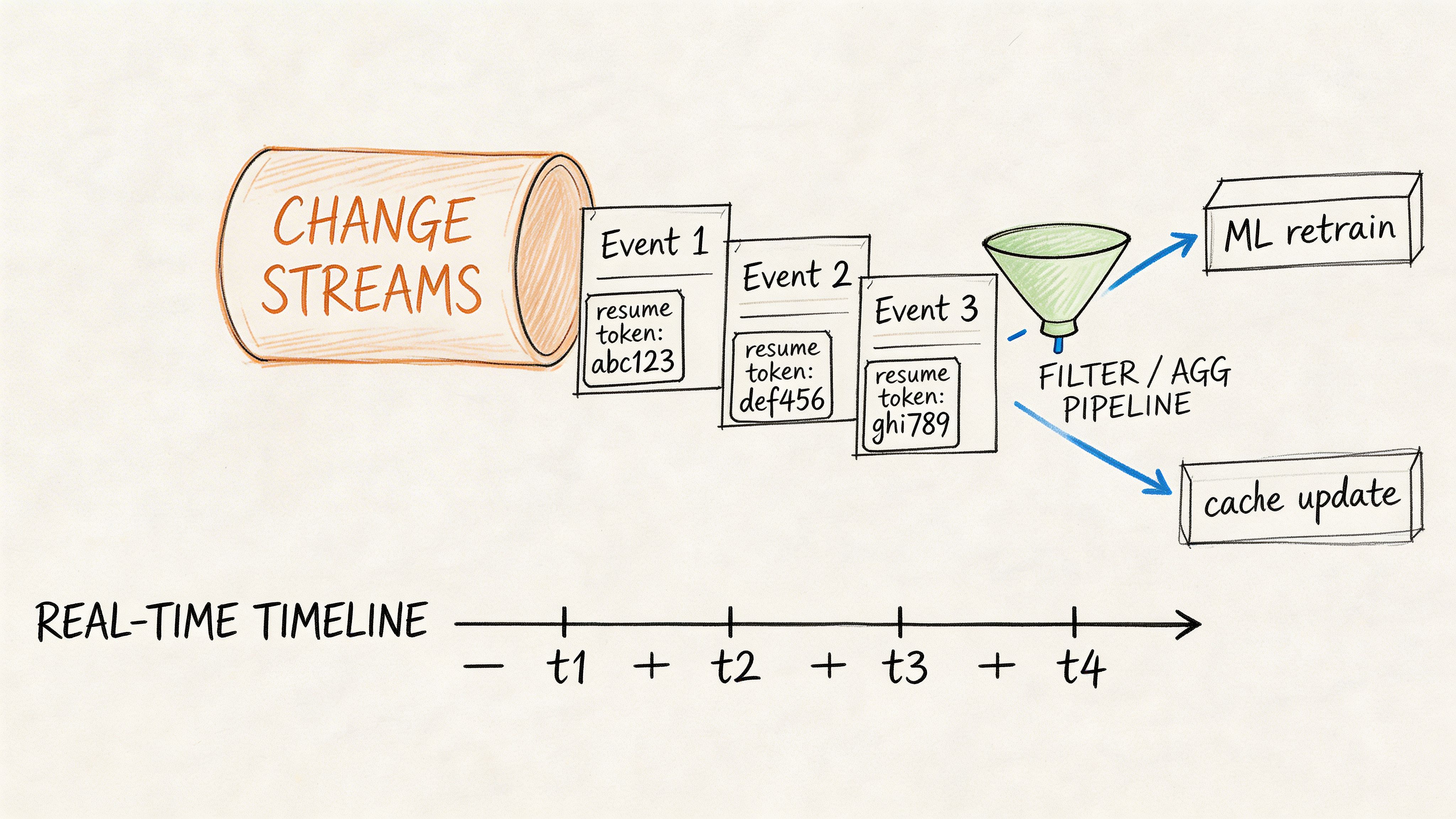
A strong answer explains that change streams let applications subscribe to database changes and react to inserts, updates, deletes, or replacements without polling the database constantly.
Real-world use cases
Practical examples are essential here. Ask the candidate to pick one.
A few good ones:
- invalidate an inference cache when a feature record changes,
- trigger retraining workflows when labeled data updates arrive,
- sync a prompt-template collection into downstream serving systems,
- update analytics or search indexes when application data changes.
The candidate should also mention resume tokens, fault tolerance, filtering the stream, and what happens if the consumer falls behind or crashes.
Mini-task and rubric
Give them a scenario: “A recommendation engine stores user interactions in MongoDB. We want downstream services to react to profile updates quickly without hammering the database. Design the flow.”
Good answers usually include:
- a filtered change stream on the relevant collection,
- resume token handling,
- a consumer process with reconnection logic,
- an optional message bus if multiple consumers depend on the same event.
A startup-level engineer can stop there. A senior enterprise engineer should also discuss delivery guarantees, replay behavior, duplicate handling, and whether to use fullDocument: 'updateLookup'.
If a candidate says change streams are “basically webhooks,” keep digging. That answer is too shallow for platform ownership.
Follow-up: When would you avoid change streams and use an explicit event log instead?
That question reveals whether they understand boundary design and operational ownership.
8. Backup, Recovery, and Point-in-Time Restore
Most MongoDB interview packs underweight this topic. That’s a mistake. If you’re hiring for senior backend, data platform, or MLOps roles, backup and recovery questions are mandatory.
Ask this directly: How would you design backup and restore for a production MongoDB deployment?
The candidate should immediately move beyond “take backups.” You want to hear restore testing, retention policy, recovery objectives, and the difference between a backup existing and a backup being usable.
Why this question matters
One of the clearest gaps in common MongoDB interview resources is production operations and disaster recovery. Apollo Technical’s MongoDB interview summary highlights that many interview guides emphasize schema and query topics but rarely cover backup and restore, write concern configuration, or recovery planning in distributed environments, as described in this MongoDB interview gap analysis.
That’s exactly why this question belongs in your loop. A senior engineer who’ll own data infrastructure must be able to recover from mistakes, not just write good queries.
What a strong answer includes
Good candidates usually cover:
- automated backups,
- restore drills,
- snapshot versus logical dump trade-offs,
- retention windows,
- point-in-time recovery needs,
- geographically separate backup storage for serious environments.
Use a realistic AI/data example. A team stores training datasets and model metadata in MongoDB. A bad migration corrupts records used for reproducibility. Ask the candidate how they would restore just enough data to investigate and recover without blindly rolling back everything.
Mini-task: “Explain your recovery plan after accidental deletion of a critical collection.”
A solid junior answer mentions recent backup and restore process. A senior answer adds:
- restore validation,
- dependency mapping,
- how to limit blast radius,
- how to prevent the same failure path from recurring.
9. Security Authentication Authorization and Encryption
If your candidate treats database security as “DevOps will handle it,” that’s a hiring signal, and not a good one. Ask this: How would you secure a production MongoDB deployment?
For AI and data teams, this matters because MongoDB often stores prompt data, feature values, internal event logs, user content, and operational metadata. Weak access design turns one app bug into broad data exposure.
A strong candidate should cover authentication, role-based access control, network restrictions, and encryption in transit and at rest. They should also know that security is layered. Database credentials alone aren’t enough.
What good answers sound like
You want practical statements such as:
- use least-privilege roles,
- separate application users from admin users,
- enforce TLS,
- restrict network access,
- avoid shared credentials,
- log administrative activity where appropriate.
This is also where domain understanding matters. A mature answer for an AI platform may separate data scientist read access from platform engineer admin rights and service-account write paths. That’s much better than “give the team readWrite on the database.”
If you want a broader companion read for your team, this guide on data security in big data systems is useful because the same principles show up across warehouses, streams, and operational databases.
Security questions expose discipline. Strong candidates think in roles, boundaries, and failure modes. Weak candidates think in passwords.
Follow-up and mini-task
Ask: How would you design RBAC for a team with backend engineers, data scientists, and SREs?
Mini-task: Give them three roles and three collections. Ask them to define who should be able to read, write, or administer each one.
A junior engineer should demonstrate least-privilege thinking. A senior engineer should also mention auditability, operational separation, credential rotation, and why broad shared permissions become a long-term risk.
10. Monitoring, Logging, and Performance Diagnostics
A MongoDB outage rarely starts with the database going fully down. It starts with a dashboard release, a feature flag, or a new aggregation that causes a gradual increase in read latency until users notice. This interview topic tells you whether a candidate can catch that slide early, isolate the cause, and fix it without guessing.
Ask: How do you monitor MongoDB performance and troubleshoot slowdowns?
Good candidates frame diagnostics as a system, not a one-off check. They should cover query behavior, slow operation visibility, replication health, resource pressure, connection patterns, and baseline comparisons before and after a change. If they only say “watch CPU and memory,” they are not ready to own production.
What to expect from a strong answer
The strongest answers are specific. You want candidates who know which signals matter and what each one helps them rule out.
They should mention:
explain('executionStats')to inspect query plans and document scans- the profiler to identify slow operations and recurring patterns
- replication lag to catch second-order effects during write spikes or failover pressure
- connection pool behavior at both the driver and database level
- resource trends over time, especially memory pressure, disk I/O, and cache effectiveness
- alerts tied to clear runbooks instead of vague threshold notifications
A strong candidate also explains order of operations. That matters in an interview because it shows discipline under pressure.
Use a concrete scenario: a feature retrieval service starts timing out right after a release. The candidate should work through this in a sensible sequence:
- identify the exact slow query or workload that changed
- inspect
explain('executionStats')to confirm scans, stage cost, and index usage - compare current behavior to the previous query shape or release version
- check whether a new aggregation, sort, or filter broke index support
- review connection behavior and application retry patterns
- confirm whether replication lag, disk pressure, or cache churn is amplifying the issue
This topic is useful because it forces candidates to connect earlier MongoDB subjects into one production workflow. Good diagnostics require data modeling judgment, indexing knowledge, and an understanding of distributed behavior. That combination is what separates someone who has read about MongoDB from someone who can run it.
What good answers sound like
Listen for language like this:
- “I start by finding the slow operation, not by staring at host metrics.”
- “I use
explain('executionStats')to check whether the query is scanning too many documents or missing an index.” - “I compare before-and-after query shapes after a deployment.”
- “I check whether the application changed connection usage or retry behavior.”
- “I confirm the fix under realistic load, then watch for regression.”
That level of specificity is what you want in startup and enterprise hiring. For startup AI teams, speed matters. They need someone who can debug a live issue fast. For enterprise data roles, consistency matters. They need someone who can diagnose carefully, document the finding, and prevent repeat failures with alerting and runbooks.
Mini-task
Present this incident: “Latency jumps after a new dashboard launches. Reads now scan far more documents than before.”
Ask the candidate to walk through their debugging plan.
A junior candidate should identify the slow query, inspect explain('executionStats'), and suggest an index or query rewrite.
A senior candidate should go further:
- isolate whether the dashboard changed filters, sorts, or aggregation stages
- verify whether the index still matches the access pattern
- test the proposed fix under production-like concurrency
- check for collateral effects on write performance or replica lag
- define what to monitor after rollout so the problem does not return
How to score it
Use a simple rubric:
- Weak: lists generic metrics but cannot connect them to root-cause analysis
- Acceptable: knows profiler,
explain(), and basic index troubleshooting - Strong: follows a clear diagnostic sequence and ties symptoms to likely failure modes
- Excellent: adds validation, regression monitoring, tradeoff awareness, and environment-specific judgment for startup versus enterprise workloads
Monitoring questions expose operational maturity. The best candidates do not chase symptoms. They identify the exact workload, prove the bottleneck, fix the right layer, and verify the result.
Top 10 MongoDB Interview Topics Comparison
| Item | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes ⭐📊 | Ideal Use Cases | Key Advantages ⭐ |
|---|---|---|---|---|---|
| Document Structure and Data Modeling in MongoDB | Moderate, planning for embeds vs refs, schema evolution | Low–Moderate, storage varies with denormalization | High, flexible models, efficient feature storage | Feature stores, embeddings, nested user events, prompt templates | Natural OO mapping, fewer joins, easy schema evolution |
| Indexing Strategies and Query Optimization | Moderate–High, requires query analysis and tuning | Moderate–High, RAM and storage for indexes, maintenance cost | Very High, orders-of-magnitude read latency improvement | Real-time inference, semantic/text search, metadata filtering | Dramatically improves query performance, supports diverse index types |
| Aggregation Pipeline and Data Processing | High, stage ordering and complex debugging | Moderate, CPU/memory; allowDiskUse for large workloads | High, in-db transformations, reduced data movement | Feature engineering, ETL, real-time metric calculations | Powerful server-side transformations, fewer external ETL tools |
| Replication and High Availability | Moderate, replica set configuration and failover tuning | High, additional nodes, network overhead, storage | High, uptime, durability, read scaling via replicas | Production inference serving, global services, batch extracts | Automatic failover, read scaling, point-in-time recovery via oplog |
| Sharding and Horizontal Scaling | High, shard key design and operational complexity | Very High, multiple shard nodes, config servers, balancer | High, horizontal scale for large datasets when keyed well | Massive feature stores, time-series at scale, geo-distribution | Linear scaling potential, geographic zoning, parallelized ops |
| Transactions and ACID Compliance | Moderate–High, session and transaction management | Moderate, memory for transactional state, replica dependence | High, atomic multi-document consistency and rollback | Model registry updates, coordinated feature changes, metadata ops | Multi-doc ACID guarantees, snapshot isolation, automatic rollback |
| Change Streams and Real-Time Data Capture | Moderate, consumer infra and filtering logic required | Moderate, persistent connections, consumer processing infra | High, low-latency event-driven triggers and syncs | Real-time feature updates, retraining triggers, cache invalidation | Push-based change delivery, resume tokens for fault tolerance |
| Backup, Recovery, and Point-in-Time Restore | Moderate, backup strategy, scheduling, and testing | High, storage for backups, time and resources for restores | High, recoverability, compliance, forensic capability | Production feature store backups, model registry snapshots | Point-in-time restore, disaster recovery, dataset reproducibility |
| Security: Authentication, Authorization, and Encryption | High, RBAC, key management, network policies | Moderate, performance overhead for encryption, key ops | Very High, protects sensitive data, meets compliance needs | PII feature stores, regulated industries, enterprise ML systems | Encryption, audit logging, granular RBAC and network controls |
| Monitoring, Logging, and Performance Diagnostics | Moderate, tooling, alerting, and runbook creation | Moderate, storage for metrics/logs, monitoring services | High, proactive detection, capacity planning, SLA assurance | Production ML infra, SLA monitoring, performance tuning | Identifies bottlenecks, supports root-cause analysis and alerts |
Next Steps Level Up Your Hiring Process
These 10 interview questions on mongodb work best when you stop treating them as a trivia list and start using them as a hiring system. That means three things.
First, match the question depth to the role. A junior backend engineer doesn’t need to give a polished answer on chunk migration failure handling. They do need to explain embedding versus referencing, basic indexing, and how replica sets support failover. A senior platform or data engineer should be able to go much further. They should reason about shard key design, operational trade-offs, write concern, recovery planning, and what to monitor before users notice a problem.
Second, score answers on judgment, not vocabulary. Don’t reward candidates for naming every MongoDB feature. Reward them for making sound decisions with constraints. A useful internal rubric looks like this:
- Basic pass: Can explain the concept accurately and apply it to a simple app scenario.
- Strong pass: Can explain trade-offs, identify failure modes, and connect the decision to latency, reliability, or maintainability.
- Senior pass: Can design for production, discuss limits, and show how they’d validate the choice with tooling, testing, or operational monitoring.
Third, add a mini-task to at least half your MongoDB interviews. With these tasks, weak candidates fade quickly. Give them a schema design prompt. Ask for an index. Show them a query and ask what explain() should reveal. Present a recovery or failover scenario and ask for the next actions. If they can reason under pressure in a small exercise, they’re much more likely to perform on the job.
This matters even more for AI and data roles. In those environments, MongoDB often supports live feature retrieval, model metadata, internal tools, prompt storage, event capture, and serving infrastructure. A poor hire won’t just write clumsy queries. They can create stale reads in training workflows, overload primaries with bad index choices, or leave you exposed during an incident because no one tested restore paths.
I also recommend giving candidates room to ask strong questions back. The quality of those questions often tells you as much as their prepared answers. If you want a useful benchmark, this list of strategic questions to ask from an interviewer is worth reviewing with your hiring team.
Use this article as a repeatable interview pack. Turn each section into a scorecard. Standardize follow-ups. Save candidate notes in the same format across loops. Within one hiring sprint, you’ll get far more signal and far fewer “sounds smart, but I’m not sure what they can do” interviews.
If you need to hire for MongoDB-heavy AI, data engineering, or MLOps work, don’t settle for generic backend screening. Build an interview process that tests operational judgment from day one.
If you need help hiring engineers who can run MongoDB in production, not just talk about it, ThirstySprout can help.com) can help. We match startups and enterprises with vetted AI, data, and backend talent who’ve shipped real systems across ML platforms, data pipelines, and distributed infrastructure. Start a Pilot or see sample profiles if you want to fill critical roles fast without lowering the bar.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.