
Most advice on the fastest computer language is wrong because it treats speed like a single leaderboard. That is not how production systems fail, and it is not how good CTOs choose a stack.
You do not buy “fastest” in the abstract. You buy lower inference latency, faster batch completion, better CPU utilization, safer concurrency, and a hiring plan your organization can execute. A language that wins a microbenchmark can still lose your quarter if your team cannot ship with it.
For AI systems, the core question is speed for what. Kernel-level inference code, scientific simulation, streaming services, and internal prototyping all reward different choices. Raw runtime matters. So do library maturity, debugging costs, onboarding time, and whether you can hire senior engineers without stalling the roadmap.
Here is the blunt version. If you need the hottest possible path to run fast, pick a systems language. If you need numerical computing with near-native speed and a much friendlier workflow, Julia deserves serious attention. If you need service orchestration around models, network behavior often matters more than benchmark bragging rights.
TLDR What Is the Fastest Language
The fastest language is the one that removes your bottleneck at an acceptable operating cost.
If your problem is tensor math, the answer is different from a model gateway, a feature pipeline, or an internal experimentation stack. CTOs get this wrong when they buy a language for benchmark prestige instead of latency targets, cloud spend, and hiring reality.
Use this scorecard to make the first cut.
| Language | Best fit | Raw speed signal | Main trade-off |
|---|---|---|---|
| C | Custom kernels, embedded inference, low-level systems | Top-tier native performance for tightly controlled code paths | Manual memory management and higher defect risk |
| C++ | Model runtimes, performance-critical services, existing ML infra | Consistently strong for CPU-bound and latency-sensitive production code | Complexity becomes expensive fast |
| Rust | Safe systems code, performance-sensitive services | Near-native speed with much better safety guarantees than C or C++ | Smaller hiring pool and slower ramp for many teams |
| Julia | Numerical AI, simulation, research-to-production math workloads | Excellent performance for compute-heavy numerical work | Weaker ecosystem outside technical computing |
| Go | API layers, concurrent services, model gateways | Strong fit for network-heavy services with simple concurrency needs | Weak choice for the hottest numeric loops |
| Python | Prototyping, orchestration, ML glue | Fastest path to a working system, not the fastest runtime | Performance usually depends on native libraries or moving hot paths out of Python |
My recommendation is simple.
- Choose C, C++, or Rust for the code that directly sets your latency floor.
- Choose Julia when numerical performance matters and you want faster iteration than a traditional systems stack.
- Choose Go for model-serving infrastructure, worker fleets, and service layers where concurrency and operational simplicity matter more than raw math speed.
- Choose Python for prototyping, orchestration, and product discovery. Then rewrite only the parts that burn CPU time or miss your SLOs.
The business decision matters as much as the runtime decision. A language that is 15 percent slower in theory can still win if it cuts hiring time in half, reduces incident risk, and gets features shipped this quarter. If you are evaluating service-layer runtime trade-offs, this comparison of Go vs Java for backend performance and operations is a useful companion read.
Recommendation: pick the fastest language for the expensive part of the system, not the fastest language on a generic chart.
Who This Guide Is For
This is for CTOs, VPs of Engineering, staff engineers, and founders making an architecture decision in the next few weeks. You are building or reworking an AI feature, and one part of the stack has become performance-critical.
The mistake I see most often is treating “fastest” as one dimension. It is at least four:
- Latency: how fast a single request completes
- Throughput: how much work the system clears over time
- Startup behavior: how quickly a process becomes useful
- Operational drag: how much engineering effort it takes to keep that speed in production
That is why the fastest computer language for a recommendation service may differ from the right language for a backtesting engine or a document ingestion pipeline.
You are the right reader if any of these sound familiar:
- Your Python service works, but hot loops are too slow
- Your team wants Rust or C++, but hiring looks painful
- You are choosing between Julia and Python for numerical workloads
- Your API is mostly waiting on network and serialization, not matrix math
- You need a decision that balances runtime performance with time-to-hire
This is not for students looking for a universal ranking. It is for operators who need a stack choice they can defend to finance, product, and recruiting.
A Framework for Choosing Your Language
Speed only matters in the unit your business pays for.
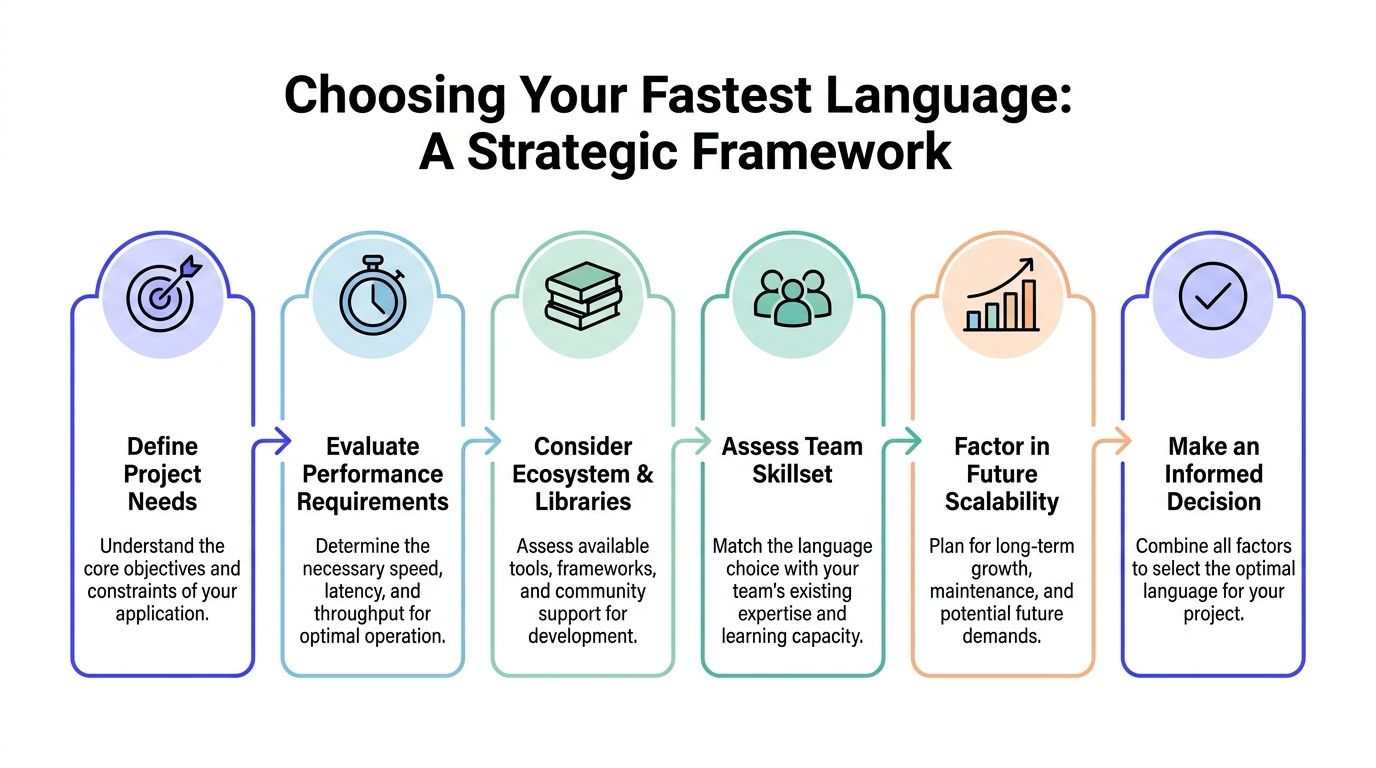
A language choice should follow the workload, the latency target, and the hiring plan. Teams that skip this sequence usually end up with an expensive rewrite that improves benchmark scores more than customer outcomes.
Define the constraint that matters
Pick the one metric that changes the business result.
For AI systems, that usually means one of four things:
- Request latency. Use this for ranking, fraud scoring, copilots, and online inference.
- Throughput. Use this for ingestion pipelines, feature generation, backfills, and training prep.
- Startup behavior. Use this for serverless jobs, bursty workers, and short-lived batch tasks.
- Cost per unit of work. Use this for edge inference, heavy batch scoring, and any workload running at enough volume to move cloud spend.
That choice drives the language shortlist. A low-latency inference service and a document pipeline should not get the same answer just because both are "AI."
Classify the bottleneck before you rewrite
Profile first. Then choose.
You need to know whether the slowdown comes from CPU, memory movement, I/O, serialization, model loading, or coordination between services. Language changes pay off only when the language sits on the critical path.
Use this filter:
- CPU-bound numeric work: look at C, C++, Rust, or Julia
- Memory-sensitive systems code: favor Rust, C, or C++
- I/O-heavy services: Go, Java, and Python often win on delivery speed and operational simplicity
- Mixed workloads: split the system. Keep orchestration in a productive language, move only the hot path into native code
As noted earlier from the primary Niklas Heer speed comparison repository, languages like Julia, C, C++, and Rust can land very close to each other on tightly optimized numeric tasks. The takeaway is not "Julia always wins." The takeaway is that raw execution speed at the top end is often close enough that ecosystem fit and staffing become the deciding factors.
Check ecosystem fit before you commit
A fast language without the right runtime, libraries, and tooling slows the whole program down.
Ask the practical questions:
- Do you need direct integration with PyTorch, TensorFlow, or ONNX Runtime?
- Are you serving models, writing custom kernels, or building infrastructure around model execution?
- Will the system depend on GPU toolchains, vector databases, streaming systems, or WebAssembly targets?
- Does your team need to stay close to the Python ML stack while pulling selected components into compiled code?
If the answer is yes to that last question, read this guide on the future of Python in production AI systems. It covers the pattern that works in practice. Keep Python where it accelerates development. Push bottlenecks into faster layers only where the profiler justifies it.
Price total cost of ownership, not just runtime speed
Runtime is one line item. Engineering drag is the bigger bill.
A language decision changes hiring difficulty, debugging time, onboarding speed, incident rate, and the cost of replacing people six months from now. C and C++ can deliver excellent performance, but they raise the cost of correctness. Rust reduces memory risk, but the hiring pool is smaller. Julia can be a strong fit for numerical teams, but recruiting is narrower than Python or Go. Python often loses microbenchmarks and still wins the business case because teams ship faster and can hire faster.
Use this table to force that discussion early:
| Decision factor | Expensive choice | Lower-risk choice |
|---|---|---|
| Team familiarity | No production experience in the language | Existing internal expertise |
| Hiring market | Small, specialist talent pool | Larger backend or ML talent pool |
| Debugging burden | Manual memory management, weak tooling fit | Better observability and safer defaults |
| Migration scope | Full rewrite | Replace one hot component |
One rule holds up in production. If one component is slow, replace one component.
Use the workload-to-language map
Make the decision by workload type.
- Online inference with strict latency budgets: keep the serving layer simple. Use Rust, Go, Java, or C++ based on the bottleneck and your team.
- Numerical research that may become production code: Julia is a serious option if the team can staff it.
- Data pipelines and ETL around AI systems: Go, Java, and Python are usually the right economic choice unless compute kernels dominate runtime.
- Python application with a few slow paths: keep Python. Move the hot loop into C++, Rust, Cython, or a native library.
- Edge or embedded inference with tight memory and startup constraints: choose Rust or C.
The fastest language is the one that improves the metric you care about without inflating hiring cost, delivery time, or operational risk. That is the framework.
Language Showdown Speed vs Developer Velocity
CTOs asking for the fastest language usually ask the wrong question. Ask which language cuts latency enough to matter, without driving up hiring cost, slowing delivery, or making operations brittle.
Use this scorecard to evaluate the trade, not to crown a winner.
Language Performance & Ecosystem Scorecard for AI Workloads
| Language | Raw Speed (Latency) | Concurrency | Memory Safety | AI/ML Ecosystem | Developer Velocity | Hiring Difficulty |
|---|---|---|---|---|---|---|
| C | Excellent | Manual, powerful, low-level | Low | Strong through foundational libraries and native integrations | Low to medium | High |
| C++ | Excellent | Strong | Low to medium | Excellent in production ML infrastructure | Medium | High |
| Rust | Excellent | Strong | High | Growing and practical for infra | Medium | High |
| Go | Good for services, weaker for numeric hot loops | Excellent | High enough for most backend work | Moderate for AI infra, less for core numerical computing | High | Medium |
| Julia | Excellent for numerical workloads | Good | Managed, simpler than C-family systems work | Strong in numerical and scientific computing | Medium to high for the right team | High |
| Java | Good | Strong | High | Solid enterprise ecosystem, less attractive for low-level ML kernels | High in enterprise orgs | Medium |
| Python with native accelerators | Depends on what runs in native code | Good enough with the right architecture | High at app level | Dominant for ML workflows | Very high | Low |
Kernel speed, service speed, and team speed are different problems
C and C++ still own the top tier for raw execution speed in hot paths. That matters for custom kernels, inference runtimes, vector search internals, and edge deployments with hard memory limits. As noted earlier, broad cross-language benchmarks consistently place them near the front.
That does not make them the default choice.
C gives you control and bills you for every mistake. C++ gives you performance and a large production ecosystem, but the language itself carries real complexity. Rust gives you similar performance characteristics with much better safety, which lowers defect rates in long-lived infrastructure, but it also raises onboarding time and narrows the hiring pool. Pick from this group only when CPU time or memory behavior is a first-order business constraint.
Julia wins a narrower, important category
Julia is the best fit when the workload is math-heavy, experimental, and still likely to become production code. That includes simulation, optimization, scientific ML, and research teams that keep rewriting Python prototypes into something faster.
The upside is obvious. You keep more logic in one language, reduce the handoff between research and engineering, and avoid some Python-plus-native-extension complexity.
The downside is staffing. If you cannot hire or retain Julia talent, the technical elegance does not help the roadmap.
Go and Java win where compute is not the bottleneck
A large share of AI systems spend more time on coordination than on math. They fan out requests, join features, call model backends, enforce auth, manage retries, and keep queues healthy. In those systems, service latency often comes from network and orchestration overhead, not from the language runtime.
Go is usually the best economic choice here. It is easy to read, fast enough, operationally simple, and much easier to staff than systems-heavy alternatives. Use it for gateways, feature services, ingestion workers, and control-plane APIs. Teams shipping Artificial Intelligence business solutions often get better margins by keeping these layers boring and maintainable instead of chasing theoretical speed gains in the wrong tier.
Java still works well in companies with strong JVM infrastructure, mature platform teams, and strict enterprise integration requirements. For a net-new AI serving layer, I would only choose Java if that organizational advantage already exists.
Python should keep the workflow, not the bottleneck
Python remains the default for model development, orchestration, experimentation, and glue code because it maximizes iteration speed. Rewriting an entire Python stack in a lower-level language is usually a bad use of engineering budget.
The production pattern that works is simple.
- Keep product logic, experimentation, and orchestration in Python.
- Measure where time and memory go.
- Move one hot path into C++, Rust, Cython, or a native library.
- Expose it through bindings or a service boundary.
This gives you the performance gain where it pays, while preserving the hiring and delivery advantages that made Python attractive in the first place. If you are planning the longer-term role of Python in your stack, this analysis of the future of Python in production software teams is a useful companion.
Practical stance: keep Python at the workflow layer. Put systems languages on the expensive path.
My opinionated picks by scenario
For low-latency inference
Choose C++ when you need maximum compatibility with existing ML runtimes and native serving infrastructure. Choose Rust when memory safety, reliability, and long-term maintainability matter as much as latency. Choose C only for constrained environments or very specialized runtime work.
For numerical R&D that may become a product
Choose Julia if the work is dominated by numerical methods and the team can hire for it. Otherwise, stay in Python for research and push the expensive kernels into native code.
For model-serving platforms and AI service layers
Choose Go first. It is usually the right answer for request handling, concurrency, feature retrieval, and service orchestration. Pair it with a native inference core when profiling proves you need one.
For enterprise AI inside a JVM-heavy company
Choose Java if the business already benefits from JVM tooling, platform standards, and a deep internal talent pool. Do not choose it as a compromise candidate for speed.
Practical Examples for Production AI Systems
Architectures win, not language purity tests.
Example one with a hybrid inference server
A common production pattern is a Go service layer with a native inference core.
Use it when:
- your product handles lots of concurrent requests
- the network edge, auth, logging, and retries belong in a backend service
- the scoring or ranking logic must run closer to native speed
A simple layout looks like this:
| Layer | Language | Responsibility |
|---|---|---|
| API gateway | Go | Routing, auth, concurrency, request shaping |
| Feature retrieval | Go or Java | Cache access, feature joins, service orchestration |
| Inference core | Rust or C++ | Hot-path scoring, custom ops, low-level optimization |
| Monitoring | Mixed | Metrics, tracing, error capture |
Representative FFI-style call flow:
// Go service calls a native scoring functionscore := C.run_inference(inputPtr, inputLen)if score < threshold {// fallback or reject}This pattern keeps the expensive engineering effort contained. You do not force every backend engineer to become a systems programmer. You only apply systems-language complexity where the CPU work justifies it.
Tip: isolate the hot path behind a narrow interface. If you expose too much native surface area, debugging cost rises fast.
Example two with a Julia data pipeline
Now a different shape. A fintech or scientific platform may spend most of its time in numerical transformation, simulation, or matrix-heavy preprocessing. In that setting, Julia can be the strongest choice.
The case for Julia is straightforward. It is designed for high-performance numerical work, and benchmark summaries describe it as rivaling C-class speed while keeping Python-like syntax. The same benchmark-oriented source also notes 100-1000x faster execution than pure Python on matrix operations and simulations, and points to DifferentialEquations.jl solving complex models 50x faster than MATLAB (Khired on fastest programming languages).
A practical before-and-after decision scorecard:
| Question | Python-heavy pipeline | Julia-heavy pipeline |
|---|---|---|
| Team writes fast prototypes | Strong | Strong |
| Numerical code stays in one language | Usually no | Often yes |
| Need to drop into native extensions early | Often | Less often |
| Better fit for simulation-heavy workflows | Mixed | Strong |
This is especially relevant for teams building pricing models, forecasting engines, or optimization pipelines. If your workload looks closer to applied mathematics than web development, Julia deserves more attention than it usually gets.
If you are evaluating broader implementation patterns for AI products, this roundup of Artificial Intelligence business solutions is useful because it frames how language choice fits into larger product and operations decisions.
Two production rules I would enforce
Keep one language for orchestration
Your orchestration layer should stay boring. Pick a language your broader team can maintain.
Move only proven bottlenecks
Do not rewrite a system because benchmark charts look exciting. Rewrite because profiling identified a hot path and the business impact is clear.
Benchmarking and Hiring Implications
Benchmark discussions often fail because teams benchmark the wrong thing, then hire for the wrong profile.
Benchmark with production shape, not toy logic
Use your own workload or the closest reproducible proxy.
A good benchmark process looks like this:
- Pick one representative task. A real inference request, a batch transform, or a ranking computation.
- Control the environment. Use a clean cloud instance or dedicated machine. Do not trust a laptop full of background noise.
- Measure more than runtime. Include CPU utilization, memory pressure, tail latency, startup behavior, and operational overhead.
- Run enough iterations to catch variance. Single runs are misleading.
- Benchmark the whole path when needed. Serialization and RPC overhead can erase language wins.
For heavily parallel numeric work, the ceiling for C is still hard to ignore. The Computer Language Benchmarks Game reports C consistently leading multi-threaded tasks, with execution times 1.5-3x faster than Rust and 5-10x faster than Go on parallel matrix computations, and cites a path where teams use C for low-latency MLOps kernels integrated into higher-level services, with 30-60% lower inference costs in some scenarios (Computer Language Benchmarks Game).
That does not mean you should write your whole system in C. It means benchmark results often support a hybrid architecture.
Hire for bottlenecks, not for ideology
The best hiring move is usually not “find six Rust engineers.” It is “find one or two engineers who can own the performance-critical layer and integrate well with the broader team.”
Look for these interview signals:
- Can the candidate profile before optimizing?
- Can they explain memory layout and data movement clearly?
- Have they shipped code across language boundaries?
- Can they describe failure modes, not just benchmark wins?
A compact interview kit:
| Role need | Better interview question |
|---|---|
| Native performance engineer | Walk through how you would profile a slow inference path before changing languages |
| Systems-focused backend engineer | When would you choose Go for a service layer and C++ or Rust for a library behind it |
| Numerical computing lead | Describe a workload where Julia beats a Python-plus-extension approach on team productivity |
If you are staffing these roles, this guide on how to hire AI engineers is useful because the stack decision and the hiring plan should happen together.
Hiring rule: for performance-critical work, seniority matters more than language fandom.
What usually works best
- One language for the product surface
- One high-performance language for the bottleneck
- A hiring plan that matches both
That combination is easier to benchmark, easier to maintain, and easier to scale than a full-stack rewrite driven by benchmark envy.
Download Your Language Selection Checklist
Use this one-page checklist before you let anyone rewrite a service.
Language selection checklist
- Primary metric: What matters most right now, latency, throughput, startup behavior, or cost per unit of work?
- Workload type: Is the pain CPU-bound, memory-bound, or mostly I/O-bound?
- Hot path scope: Is one function slow, one service slow, or the whole system slow?
- Integration reality: Do you need direct support for TensorFlow, PyTorch, ONNX Runtime, or an internal platform?
- Team fit: Who on your team can own C++, Rust, Julia, or Go in production?
- Hiring plan: Can you realistically add the needed skills without stalling roadmap work?
- Operational complexity: How will you debug crashes, memory issues, and cross-language boundaries?
- Migration pattern: Can you isolate the bottleneck behind FFI or a service boundary instead of rewriting everything?
- Benchmark setup: What exact production-shaped task will you test first?
- Exit criteria: What result would justify staying put, and what result would justify a change?
Use it as a gate, not a formality
If your team cannot answer those questions crisply, you are not ready to choose the fastest computer language for your AI stack.
The checklist also surfaces a useful truth. The best answer is often Python or Go for the shell, C++ or Rust for the core, Julia for numerical specialists. That is not compromise. That is mature architecture.
What To Do Next
Take three steps.
First, run the checklist against one real workload. Not a toy benchmark. Use the inference route, data transform, or simulation job that is currently causing pain.
Second, benchmark two realistic options only. For many teams, that means a hybrid design versus the current stack, not a six-language bake-off.
Third, staff the decision before you finalize it. A strong architecture choice without the right engineers is just a slide.
One resource I like for staying sharp on applied AI thinking is Parakeet AI's blog. It is useful for teams that want practical perspectives on shipping AI systems, not just discussing them.
If your result is still ambiguous, that is normal. The next move is usually a short pilot that validates the hot path, confirms integration effort, and exposes hiring risk early.
Frequently Asked Questions
Is Assembly the fastest computer language
For absolute low-level control, yes, Assembly can be the fastest in narrow cases. It is also the wrong choice for almost every product team.
Use Assembly only for extremely specialized kernels, compiler work, or hardware-specific paths where every instruction matters and the maintenance burden is justified. Many teams should stop at C, C++, or Rust.
Is Fortran still relevant
Yes. Fortran still matters in scientific and high-performance computing, especially in established research and simulation environments.
But it is rarely the best primary choice for modern AI product stacks that need service integration, model serving, and fast-moving product teams. If your work is tied to legacy scientific code, Fortran may stay in the picture. For most SaaS and fintech AI systems, it will not lead the architecture.
Where does WebAssembly fit
WebAssembly matters when you need fast code in browsers, sandboxed environments, or some edge deployments.
It is not a replacement for your core backend stack. It is a delivery target. Rust is often a strong candidate when WebAssembly is part of the roadmap because it compiles cleanly to that environment and keeps performance-sensitive logic portable.
Should I rewrite Python services in Rust or C++
Usually no. Rewrite only the bottleneck.
Keep Python where it helps your team move fast. Move expensive computation into a native module or a separate service once profiling proves the need.
What is my default recommendation
If you need a single default stance, use this:
- keep Python for research and orchestration
- use Go for service-heavy AI platforms
- use C++ or Rust for low-latency hot paths
- use Julia when numerical computing is central to the business
If you are choosing a language for a production AI system and need engineers who have already shipped these trade-offs in practice, talk to ThirstySprout. You can Start a Pilot or See Sample Profiles for senior AI, MLOps, and systems engineers who can help you benchmark the bottleneck, design the right hybrid architecture, and ship without wasting a quarter on the wrong rewrite.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.