
A lot of teams think they have Express error handling covered because they added one app.use((err, req, res, next) => ...) block and saw a 500 response in local development. That's enough for demos. It's not enough for production.
The real test happens when a database call rejects, an upstream API times out, logs lose the request context, or the process ends up in a bad state after an unhandled exception. At that point, error handling stops being a framework detail and becomes an operations problem. It affects downtime, incident response speed, and whether your API consumers can recover cleanly.
This guide focuses on Express error handling as a production discipline. The route-level mechanics matter, but the bigger win comes from combining central middleware, async safety, structured errors, correlation IDs, monitoring, and process-level safeguards.
TL;DR
- Use a real error middleware signature: Express only treats a handler as an error handler when it has exactly four parameters:
(err, req, res, next). - Put it last: Your catch-all error handler belongs after routes and other
app.use()registrations. - Treat async code as a separate problem: Forward promise failures to
next(err)manually, or adopt a wrapper or package consistently. - Return sanitized responses, log rich context: Clients need stable error formats. Engineers need stack traces, request metadata, and correlation IDs.
- Test failure paths on purpose: If you haven't tested rejected promises, validation failures, and process-level crashes, your error handling isn't finished.
Who this is for
This is for CTOs, platform leads, and senior Node.js engineers running Express services that already matter to customers. If you own a SaaS API, an internal AI platform, or a fintech backend, this is the layer that keeps a bug from turning into a noisy outage.
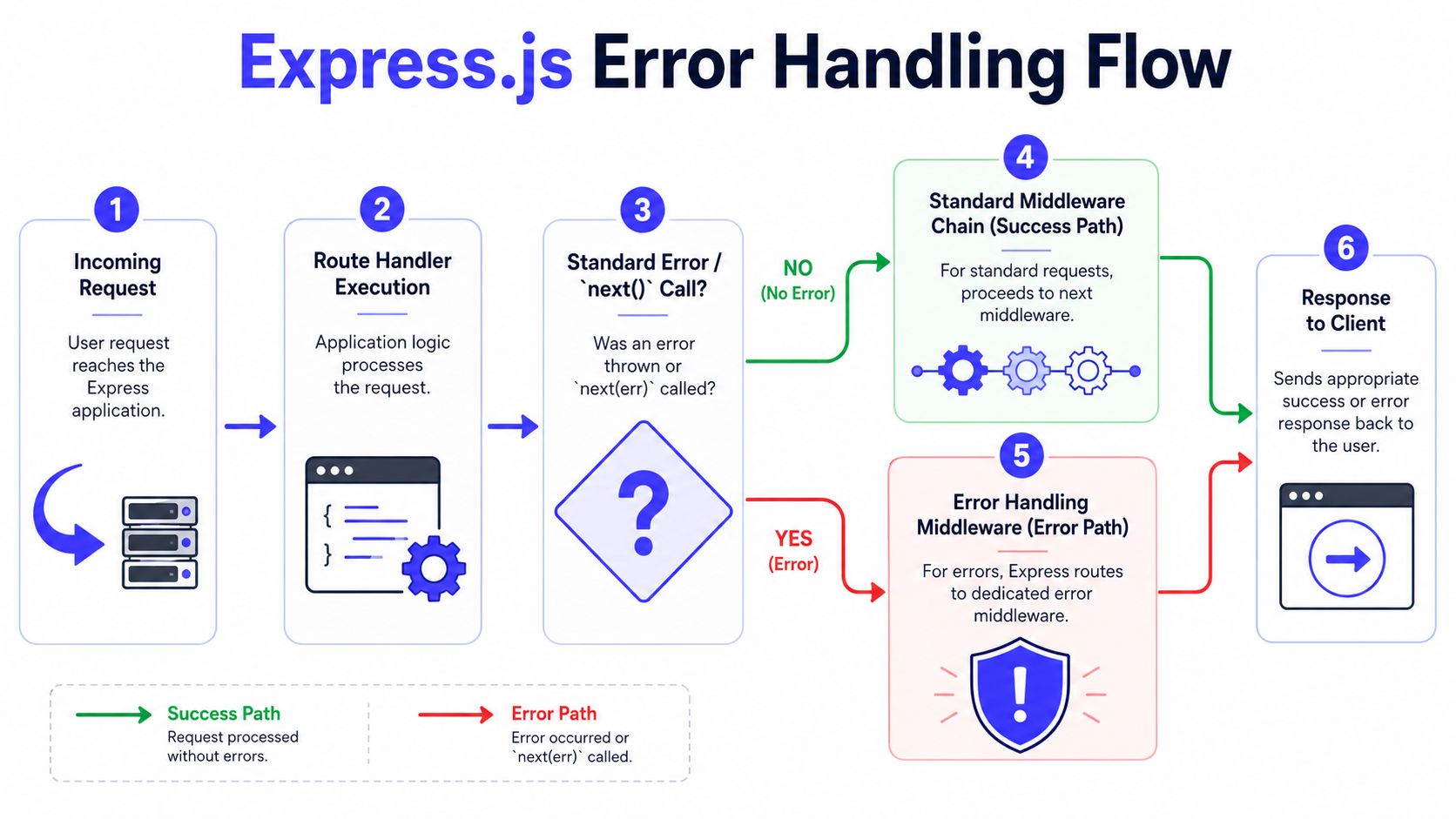
The Foundational Error Handling Pattern
Express makes one design choice that every production app depends on. Error middleware is identified by its function signature, not by its name or where you store it. If the function doesn't declare (err, req, res, next), Express won't treat it as an error handler.
That sounds small, but it's the source of many broken implementations. The verified guidance is explicit: in Express.js, error-handling middleware is uniquely identified by a signature requiring exactly four parameters, and using only three causes Express to treat it like standard middleware, creating 100% unnecessary execution overhead on every request and risking state corruption.
The golden rule
A minimal central handler looks like this:
import express from "express";const app = express();app.use(express.json());app.get("/orders/:id", (req, res, next) => {const order = null;if (!order) {const err = new Error("Order not found");err.statusCode = 404;return next(err);}res.json(order);});app.use((err, req, res, next) => {const status = err.statusCode || 500;res.status(status).json({error: {message: status >= 500 ? "Internal server error" : err.message}});});This does three jobs:
- Receives forwarded errors from
next(err). - Normalizes the response so clients don't get random payload shapes.
- Prevents route-level duplication of error formatting logic.
Practical rule: If your global error middleware isn't the last middleware in the app, assume it's wrong until proven otherwise.
The most common mistake
This looks harmless, but it's not an error handler:
app.use((req, res, next) => {// wrong shape});And this is also wrong if you intended it to catch errors:
app.use((err, req, res) => {// missing next});Express expects all four parameters to identify the function correctly. Don't optimize the signature for aesthetics.
Placement is not optional
Register the handler after all route definitions and middleware. Express skips regular middleware once an error is passed forward and jumps to matching error middleware. If your handler sits too early, later routes won't be protected.
A simple stack usually looks like this:
| Order | Middleware |
|---|---|
| 1 | request parsing, CORS, auth |
| 2 | routes |
| 3 | 404 generator |
| 4 | global error handler |
If you're still mixing Node core concepts and Express framework behavior, this breakdown of Express.js vs Node.js is useful because error flow lives at the Express layer, not the raw HTTP server layer.
Handling Asynchronous Code and Promises
This situation frequently results in service instability. Teams assume Express catches async failures the same way it catches synchronous throws. That assumption causes silent gaps, noisy crashes, and incidents that are harder to trace than they should be.
Express.js first shipped in November 2010 and introduced a built-in default error handler at the end of the middleware stack. That handler writes errors passed with next(err) back to the client and shows stack traces outside production environments. That default behavior is useful, but it doesn't remove the need to forward async failures correctly.
What works in sync code
Synchronous route failures are straightforward:
app.get("/sync-example", (req, res) => {throw new Error("Something broke");});Express can catch that and route it to its default or custom handler.
What breaks in async code
Async handlers need more care:
app.get("/users/:id", async (req, res, next) => {const user = await userService.findById(req.params.id);res.json(user);});If findById rejects and your setup doesn't automatically forward that rejection, you can end up with an unhandled failure instead of a controlled HTTP error response.
The verified guidance calls this out directly. 45% of unhandled asynchronous crashes in production Node.js deployments stem from forgetting to forward errors from async functions to next(err). The same guidance says graceful recovery increased from 20% to 98% when express-async-errors was implemented before route definitions.
Async failures are where beginner-friendly Express code stops being safe.
Pattern one, manual try catch
This is the most explicit option:
app.get("/users/:id", async (req, res, next) => {try {const user = await userService.findById(req.params.id);if (!user) {const err = new Error("User not found");err.statusCode = 404;throw err;}res.json(user);} catch (err) {next(err);}});Use this when:
- You want maximum clarity: Every route shows exactly how failures are forwarded.
- You're training a mixed-seniority team: Fewer hidden behaviors.
- You only have a small number of routes: The repetition is manageable.
The downside is drift. Some handlers will call next(err). Others won't. One missed route is enough to create a production-only bug.
Pattern two, async wrapper or package
A wrapper reduces repetition:
const asyncHandler = (fn) => (req, res, next) =>Promise.resolve(fn(req, res, next)).catch(next);app.get("/users/:id",asyncHandler(async (req, res) => {const user = await userService.findById(req.params.id);res.json(user);}));Another option is express-async-errors, which patches async behavior globally when added before route definitions.
Use this when:
- You run a larger API surface: Consistency matters more than explicit per-route boilerplate.
- You've had incidents from missed
next(err)calls: The wrapper pays for itself quickly. - You want cleaner route code: Business logic reads more clearly.
Trade-off table:
| Option | Good fit | Main risk |
|---|---|---|
Manual try/catch | Small apps, explicit teams | Inconsistent adoption |
| Async wrapper | Medium to large services | Another team convention to enforce |
express-async-errors | Teams that want less boilerplate | Hidden magic if engineers don't know it's loaded |
My default recommendation is simple. Use a wrapper or express-async-errors for broad consistency, and keep manual try/catch for places where you need route-specific cleanup or compensation logic.
Building a Centralized and Structured Error Hub
A useful error handler doesn't just catch failures. It classifies them, logs them with context, and returns a response shape that API clients can work with.
That means moving beyond raw Error objects and ad hoc res.status(500).send(...) calls.
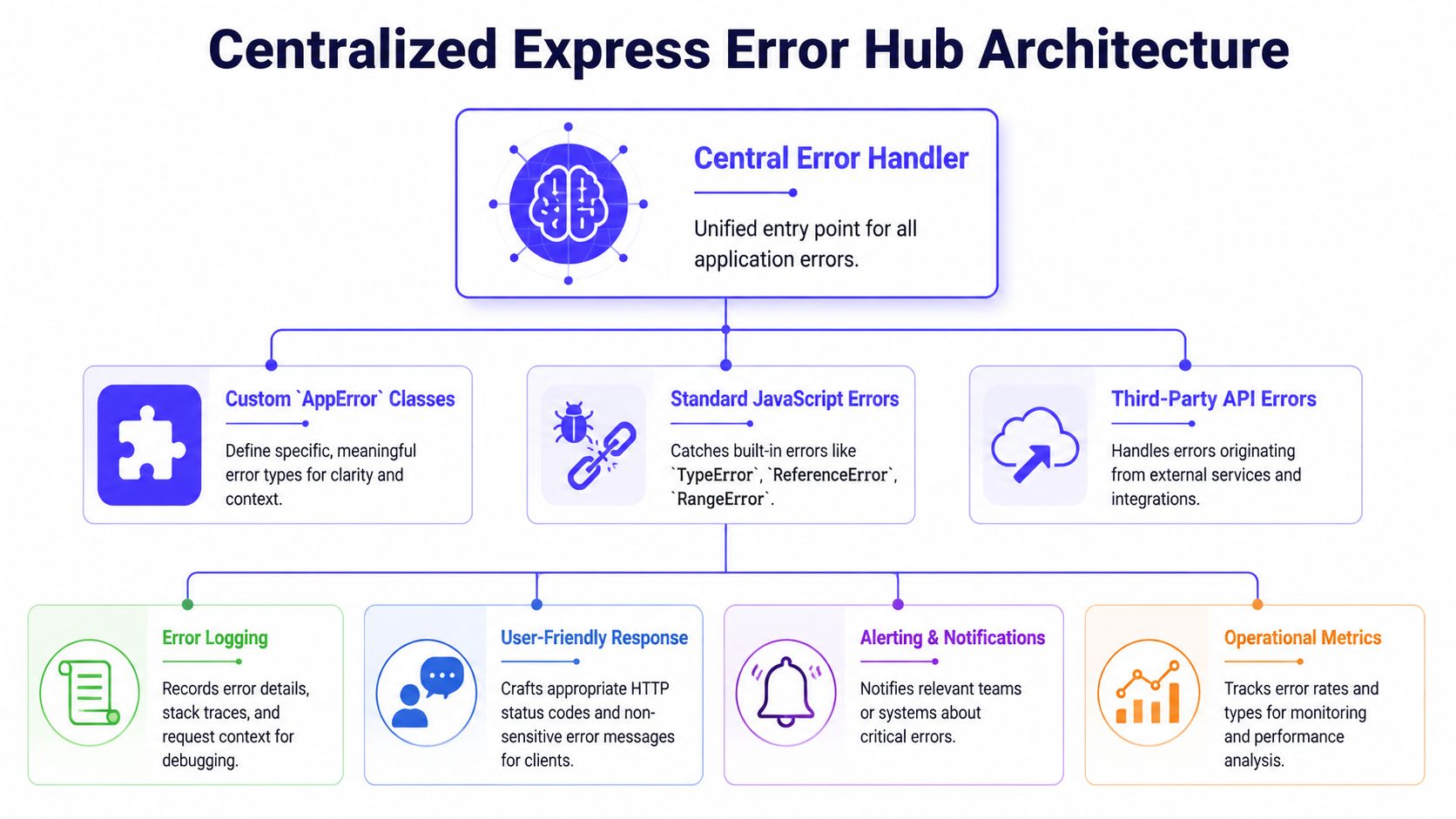
Start with an application error class
A simple base class gives your handler enough information to make decisions:
class AppError extends Error {constructor(message, statusCode = 500, options = {}) {super(message);this.name = this.constructor.name;this.statusCode = statusCode;this.isOperational = options.isOperational ?? true;this.code = options.code || "INTERNAL_ERROR";this.details = options.details || null;}}Then create specific subclasses where they help:
class ValidationError extends AppError {constructor(message, details) {super(message, 400, { code: "VALIDATION_ERROR", details });}}class NotFoundError extends AppError {constructor(message = "Resource not found") {super(message, 404, { code: "NOT_FOUND" });}}This gives you a clean split between:
- Operational errors, such as invalid input, missing records, or upstream timeouts
- Programmer errors, such as undefined access, bad assumptions, or logic bugs
That distinction matters. Operational errors should produce controlled client responses. Programmer errors should be logged aggressively and investigated.
Build one global handler that maps and sanitizes
Express's default error handler is environment dependent. In development, it returns a detailed HTML stack trace when NODE_ENV !== 'production'. In production, it returns a simplified message to reduce information leakage. That's useful, but JSON responses are often required instead of HTML.
A production-ready handler looks more like this:
app.use((err, req, res, next) => {if (res.headersSent) {return next(err);}const statusCode = err.statusCode || 500;const isOperational = err.isOperational ?? false;logger.error({message: err.message,code: err.code || "UNHANDLED_ERROR",statusCode,stack: process.env.NODE_ENV === "production" ? undefined : err.stack,correlationId: req.correlationId,path: req.originalUrl,method: req.method});res.status(statusCode).json({error: {code: err.code || "INTERNAL_ERROR",message:isOperational && statusCode < 500? err.message: "Internal server error",correlationId: req.correlationId}});});A critical warning from the verified technical guidance: 30% of custom implementations fail on the double next() scenario, where an error handler calls next(err) again without ending the response cycle. That can trigger the built-in handler too, causing duplicate traces or response conflicts.
If your custom handler sends a response, stop there. Don't call
next(err)afterward.
This video gives a useful companion walkthrough of the same centralization pattern and common implementation details:
Add correlation IDs early
Correlation IDs are the difference between “something failed in checkout” and “request 7f2... hit auth, billing, and email before dying in the tax service.”
A minimal version:
import crypto from "crypto";app.use((req, res, next) => {req.correlationId = req.headers["x-correlation-id"] || crypto.randomUUID();res.setHeader("x-correlation-id", req.correlationId);next();});Include that ID in:
- Application logs
- Monitoring events
- Client error responses
- Background job payloads, when the request triggers async work
Mini-case with business impact
A support team gets a ticket saying “invoice creation failed.” Without structured errors, engineering has to grep logs by timestamp and guess across services.
With custom error classes and correlation IDs, support can ask for the x-correlation-id from the client response. Engineering searches one ID, sees the request path, error code, upstream failure, and stack trace, and starts with the right service immediately. That doesn't eliminate incidents. It shortens the expensive part of them.
Integrating with Monitoring and Alerting Tools
A clean error response helps the client. It doesn't help your on-call engineer at 2 a.m. unless that same error also lands in a system your team watches.
That's why the next step in Express error handling is observability. Structured logs should flow into a monitoring tool that can group errors, show stack traces, preserve request context, and trigger alerts when behavior changes fast.
A practical path from error to incident
Say your /api/payments/confirm route starts failing because an upstream dependency is timing out. The route throws an operational error. Your central handler logs:
{"message": "Payment provider timeout","code": "PAYMENT_TIMEOUT","statusCode": 502,"correlationId": "req_123","path": "/api/payments/confirm","method": "POST"}If that log goes to Sentry, Datadog, Elastic, or another monitoring stack, your team gets more than a line in a terminal window. You get grouped incidents, searchable context, trend visibility, and alert routing.
In error handling, dashboards earn their keep. If you're deciding between log-centric and metrics-centric observability flows, this comparison of Kibana vs Grafana is a good starting point for choosing how your team will inspect failures.
What to send to the monitoring platform
Keep the payload consistent. At minimum, send:
- Error identity: message, name, internal code
- Request context: method, path, correlation ID
- Execution detail: stack trace in a safe channel
- Business context: authenticated user ID or tenant ID, if available
- Environment markers: service name, deploy version, environment
A lightweight example with Sentry-style reporting:
app.use((err, req, res, next) => {monitoring.captureException(err, {tags: {path: req.originalUrl,method: req.method},extra: {correlationId: req.correlationId,userId: req.user?.id}});next(err);});Alert on rates, not just single events
Single exceptions matter less than patterns. The strongest operational setups alert on error rate shifts.
Verified 2023 industry reporting found that 68% of enterprise Node.js applications using Express.js experienced fewer than 5 production errors per month due to centralized error handling middleware, compared to 32% of applications relying only on the default handler. The same reporting says teams using anomaly detection triggers for error rates above 10% of requests saw a 45% reduction in critical 5xx incidents within defined warm-up periods.
That doesn't mean every service should use the same threshold. It means threshold-based alerting works better than waiting for customers to file tickets.
On-call rule: Alert on symptoms customers feel. A burst of 5xx responses matters more than one isolated stack trace.
Mini-case with a scaling team
A Series B SaaS API team runs payment, auth, and AI inference behind one Express gateway. Before central monitoring, engineers chased failures through raw logs. After pushing structured errors into a dashboard and alerting on 5xx spikes, incidents became easier to triage because each alert already contained route, correlation ID, and stack context.
If you need help designing the backend ownership model around this kind of production readiness, teams often bring in platform or API engineers through networks such as ThirstySprout, alongside tools like Sentry, Datadog, Winston, and Elastic.
Testing Your Error Paths and Operational Readiness
Developers often test happy paths first and never come back for the failure paths. That's a mistake. If your API promises structured error responses, those responses are part of the product and need the same level of verification as your success payloads.
Express's own guidance emphasizes a gap many tutorials miss. Production failures aren't just route-level exceptions. Async errors must be passed to next(), built-in behavior can expose stack traces unless replaced, and process-level safeguards like unhandledRejection and uncaughtException matter in real systems, as noted in the Express error handling guide.
Test the contract, not only the code
With Jest and Supertest, start by asserting what the client sees.
Example one, validation failure:
it("returns 400 for invalid input", async () => {const res = await request(app).post("/users").send({ email: "" });expect(res.status).toBe(400);expect(res.body.error.code).toBe("VALIDATION_ERROR");expect(res.body.error.message).toBeDefined();});Example two, unexpected server failure:
it("returns sanitized 500 response", async () => {jest.spyOn(userService, "create").mockRejectedValue(new Error("db down"));const res = await request(app).post("/users").send({ email: "a@b.com" });expect(res.status).toBe(500);expect(res.body.error.message).toBe("Internal server error");});For broader API quality, this guide to RESTful API testing is useful because it treats response shape, contract behavior, and edge cases as testable surface area, not afterthoughts.
Add operational tests
Application tests aren't enough by themselves. Also verify that your service behaves correctly when the process gets into trouble.
A practical checklist:
- Rejected promise path: Confirm async route failures reach the global handler.
- Headers already sent: Verify the app doesn't try to write a second response.
- Correlation ID propagation: Confirm the response includes the same request ID your logs record.
- Monitoring handoff: Make sure severe errors are reported to Sentry, Datadog, or your chosen system.
- Graceful shutdown path: If the process receives a fatal event, stop accepting new work and exit cleanly.
A basic process-level guard looks like this:
process.on("unhandledRejection", (reason) => {logger.error({ type: "unhandledRejection", reason });shutdownGracefully();});process.on("uncaughtException", (err) => {logger.fatal({ type: "uncaughtException", message: err.message, stack: err.stack });shutdownGracefully();});Treat incidents as a repeatable workflow
Testing doesn't end when code ships. Teams that recover faster also document how they investigate and review failures. If you want a lightweight way to standardize that part, these templates to improve incident response with templates help teams capture cause, impact, remediation, and follow-up actions without reinventing the process each time.
A good error-handling system doesn't just return a 500. It gives support, engineering, and on-call a shared path to resolution.
Express Error Handling Checklist
Use this as a working audit for any Express service. It's short enough for code review and strict enough for production readiness.

Initial setup
- Register one catch-all error middleware with the exact four-parameter signature
(err, req, res, next). - Place the handler last after routes, parsers, auth middleware, and your 404 generator.
- Set
NODE_ENVcorrectly so development and production behavior don't blur together.
Development patterns
- Use one async strategy consistently across the codebase. Manual
try/catch, an async wrapper, orexpress-async-errors. - Create custom error classes for operational failures such as validation, auth, missing resources, and upstream dependency errors.
- Attach a correlation ID to every request and include it in logs and responses.
Pre-deployment review
- Sanitize 5xx client responses so internal details don't leak.
- Log structured context including error code, request path, method, correlation ID, and stack trace in safe channels.
- Avoid double
next()mistakes in custom handlers. Send the response or delegate. Don't do both.
Operations
- Forward serious errors to monitoring tools such as Sentry, Datadog, Winston pipelines, or Elastic-based stacks.
- Alert on abnormal 5xx patterns instead of waiting for user reports.
- Install process-level safeguards for
unhandledRejectionanduncaughtException. - Test error paths regularly with integration tests, not just manual spot checks.
If a service fails more than one or two items in this checklist, don't treat that as cleanup work for later. Treat it as reliability debt.
If you're building AI, SaaS, or fintech products and need senior engineers who can harden Node.js and Express services for production, ThirstySprout helps companies hire vetted remote AI and backend talent for platform engineering, MLOps, and application reliability work. You can start a pilot, review sample profiles, and add specialists who've shipped observable production systems rather than just prototype APIs.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.