
You're likely in a familiar spot. Product wants the strongest model you can ship. Legal wants explanations. Engineering wants something maintainable. Security wants test coverage across the app, not just the model. Hiring wants to know whether you need an applied scientist, an MLOps lead, or both.
That's why the usual black box versus white box debate is too shallow. In practice, the choice doesn't stop at model accuracy or interpretability. It changes your compliance posture, your CI/CD pipeline, your incident response process, and the exact skills you need on the team.
The useful framing is simple. Black-box models are often better at handling complex non-linear relationships and are generally associated with higher predictive accuracy, while white-box models are easier to inspect and explain for humans and stakeholders, as summarized in this machine learning overview on interpretability and performance. That trade-off sounds academic until you have to explain a loan denial, debug an LLM workflow, or justify a release decision to your CTO.
Here's the short answer.
- Choose white box first when explanation is part of the product, policy, or audit trail.
- Choose black box first when prediction quality creates the primary business value and explanation is secondary.
- Don't treat testing the same way you treat model selection. Many AI products need a black-box model but a combined black-box and white-box testing strategy.
- Budget for second-order effects. A more opaque model usually increases your burden in monitoring, tooling, and specialist hiring.
- Make the decision use-case by use-case, not company-wide. The right answer for fraud review may be wrong for image search or document classification.
| Decision area | Black box approach | White box approach |
|---|---|---|
| Primary value | Strong predictive power on complex patterns | Clear reasoning and inspectable logic |
| Best fit | Ranking, vision, speech, complex language tasks | Decision support, policy-heavy workflows, regulated judgments |
| Product risk | Harder to explain failures | Can underfit complex behavior |
| Engineering cost | More effort in monitoring, debugging, and observability | More effort in feature design and domain framing |
| Compliance posture | Often needs added interpretability controls | Easier to defend in reviews and audits |
| Hiring impact | More MLOps, platform, and systems depth | More statistics, domain expertise, and model governance discipline |
A Quick Decision Framework for Choosing Your Model
A CTO usually doesn't need a philosophy lecture. You need a recommendation you can defend in a planning meeting.
Start with five questions. If you answer “yes” to the first two, begin with a white-box model. If you answer “yes” to the last two, begin with a black-box model. If your answers split, plan for a hybrid path.
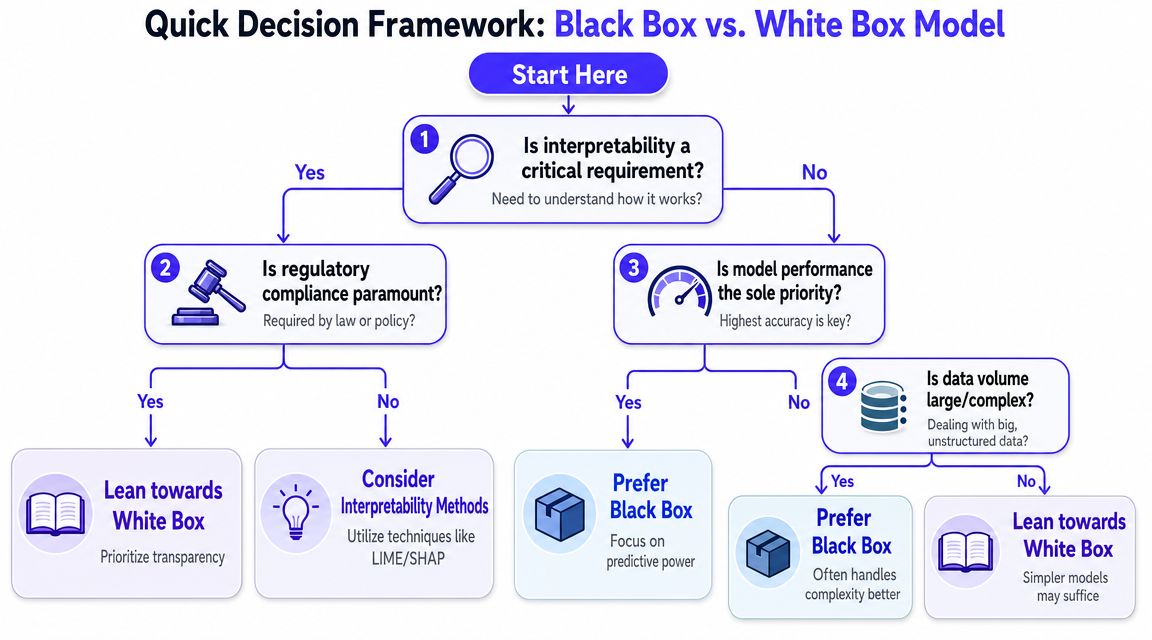
Ask these questions first
Does each prediction need an explanation?
If a customer, analyst, regulator, or internal reviewer needs to understand why the model produced a result, white box is the safer starting point.Is the use case regulated or policy-constrained?
Lending, insurance, healthcare decision support, and employment-related workflows often need defensible logic and documentation.What's the business cost of lower predictive performance?
If a modest drop in model quality damages conversion, detection quality, or user trust, black box becomes more attractive.Is the data complex, high-dimensional, or unstructured?
Images, audio, free text, and layered behavioral data usually push you toward black-box methods.Can your team support the operational burden?
A high-performing opaque model isn't “just a model.” It often requires stronger monitoring, failure analysis, and deployment discipline.
Practical rule: If explanation is a release requirement, don't start with a black-box model and hope to explain it later.
A scorecard you can use in kickoff
Use this simple scoring pattern in a project review:
- White-box signals: regulated workflow, user-facing explanation, audit trail, easier approval process
- Black-box signals: unstructured data, complex interactions, winner-take-most accuracy dynamics
- Hybrid signals: explainability matters, but raw model quality also matters enough to justify extra controls
If the room is split, treat it like a product architecture decision, not a modeling preference. The same way you'd weigh build versus buy software, you're balancing control, speed, and downstream cost.
Where teams get this wrong
Two mistakes show up repeatedly.
First, teams optimize for benchmark performance before they define the explanation requirement. That creates expensive rework.
Second, teams assume a white-box model is always cheaper. Sometimes it is. Sometimes it isn't. A transparent model can still demand deep feature engineering, stronger domain input, and more careful business-rule design. Cheap to explain doesn't always mean cheap to build.
Two Practical Scenarios Black Box vs White Box in Action
The fastest way to make the right call is to anchor it to the business context.
Scenario one, credit decisions in fintech
A fintech team is building a loan prequalification system. Product wants better approval routing. Risk wants consistency. Compliance wants a reason a customer can understand.
In that situation, a white-box model is usually the right starting point. Not because it's academically cleaner. Because the business needs to defend individual outcomes. When a customer asks why they were denied or routed differently, “the model found a complex pattern” isn't enough. The team needs logic they can inspect, document, and review with legal.
The hidden benefit is operational. Debugging is easier. Policy updates are easier. Model reviews are easier. You can trace whether a bad outcome came from data quality, feature design, or thresholding instead of guessing at internal interactions.
The trade-off is obvious. You may leave some predictive performance on the table. In a regulated workflow, that can still be the right decision.
The strongest model isn't always the best product choice. The most defensible model often ships faster because fewer people block the release.
Scenario two, plant identification from photos
Now switch contexts. A startup is building an app that identifies plant species from user-uploaded photos. Users care about one thing first. Is the answer right?
That use case points toward a black-box model. The data is visual and pattern-heavy. The value comes from handling complex image features that simple interpretable models usually won't capture well. A user rarely needs a detailed explanation of why the app identified a leaf as one species instead of another. They need a reliable answer and a good experience.
The engineering priorities also shift. Instead of explanation workflows, the team focuses on inference performance, image preprocessing, failure monitoring, and continuous evaluation on real user uploads.
That same pattern appears in many AI products built on modern language systems. If your product relies on a large model to summarize support tickets, classify documents, or power a copilot, you often start with a powerful black-box foundation and build controls around it. If you need a refresher on the underlying model category, this guide on what a large language model is is a useful reference.
The practical takeaway
The right question isn't “Which model class is better?” It's “What failure can the business tolerate?”
- In regulated decisioning, unexplained outcomes are often the biggest failure.
- In perception-heavy products, weak model performance is often the biggest failure.
That's why black box and white box choices should come from product risk, not team preference.
A Deep Dive on AI Models and Software Testing
A team can choose a highly accurate black-box model and still ship a weak product if it tests the wrong layer.
That mistake shows up in production more often than model benchmarks suggest. The model may perform well in isolation, while the actual system fails in retrieval, prompt assembly, business-rule enforcement, or fallback logic. The testing plan has to reflect how the product is built, not just how the model is described.
The terms black box and white box started outside modern AI. In systems theory, a black box is studied through observable behavior while its internals are treated as out of scope, as described in this history of black box theory. Software engineering turned that distinction into a practical split. One approach checks outputs against inputs. The other inspects implementation details such as code paths, control flow, and internal state.
Teams still use the same words for two different decisions, and that creates avoidable confusion.
In machine learning
In ML, black box versus white box usually refers to model transparency.
Black-box models are harder to explain from their internal structure. White-box models are easier to inspect, document, and defend in review. ActiveState's discussion of white-box and black-box algorithms in machine learning captures the trade-off well. Teams often choose black-box models for harder prediction tasks and white-box models when explanation, governance, or operational simplicity matter more.
That choice changes hiring and maintenance costs. A black-box stack usually needs stronger experimentation discipline, better monitoring, and people who can debug drift, calibration issues, and model-specific failure modes. A white-box stack often lowers the burden on review, onboarding, and audit preparation because more of the system can be explained directly from features, coefficients, or tree logic.
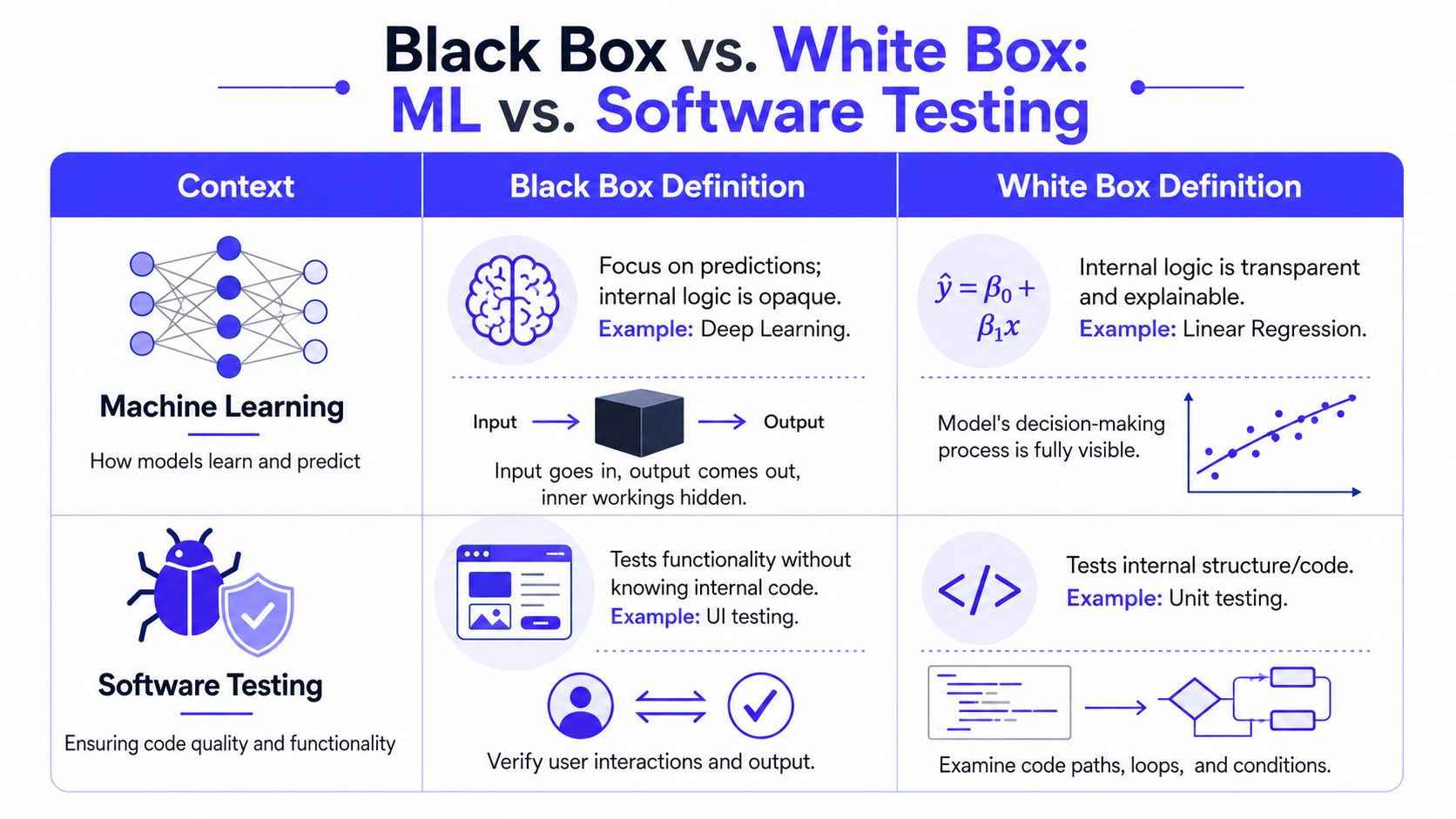
In software testing
In testing, the same terms describe how the team validates behavior.
White-box testing inspects the implementation. Black-box testing evaluates the system from the outside. White-box methods usually track coverage across statements, branches, conditions, paths, and loops. Black-box methods focus on user-visible behavior through techniques such as equivalence partitioning, boundary value analysis, decision tables, and state transitions.
For AI products, that distinction has direct MLOps implications. Black-box tests belong in CI for end-to-end flows, regression suites, and release gates that reflect what customers experience. White-box tests belong around the code your team owns, especially data transformations, routing logic, policy checks, and service boundaries where small changes can create silent failures.
| Aspect | Black box approach | White box approach |
|---|---|---|
| Core focus | External behavior | Internal implementation |
| In AI models | Opaque but often strong on complex prediction | Transparent and easier to explain |
| In software testing | Inputs and outputs only | Code paths and control flow |
| Main strength | Realism from user or attacker perspective | Better diagnosis and structural coverage |
| Main limitation | Harder to trace root cause | Higher information burden and more setup |
| Typical question answered | “Does it behave correctly?” | “Did we exercise the logic correctly?” |
Why AI products need both
A black-box model does not remove the need for white-box engineering controls.
That matters in LLM systems in particular. Prompt routing, retrieval pipelines, guardrails, post-processing, scoring thresholds, and escalation rules usually live outside the model. Those parts are code, and they should be tested like code. If a support copilot leaks restricted content because a policy filter was skipped on one branch, model interpretability does not solve the incident. Branch coverage and integration tests do.
The split also affects compliance work. Legal and security reviewers rarely ask only whether the model is accurate. They ask whether the full system behaves predictably, whether failures can be reproduced, and whether changes are controlled across releases. Teams that need a shared QA language usually benefit from separating verification and validation in software testing, because those conversations map cleanly to AI release processes.
A practical architecture view
For a production AI application, test by layer.
- Model layer: prediction or generation quality, calibration, drift, and failure analysis
- Orchestration layer: prompts, retrieval, ranking, tool use, fallback logic, and policy enforcement
- Application layer: APIs, UI, auth, workflows, observability, and audit logging
Use black-box testing across the full user flow. Use white-box testing where internal logic can fail without obvious symptoms.
That combination costs more upfront, but it reduces expensive surprises later. It also changes who you need to hire. Teams shipping black-box models at scale need people who can run evaluations, monitor production behavior, and maintain test harnesses around opaque components. Teams relying more on white-box models can often shift effort toward application engineering, domain review, and compliance documentation because the model itself is easier to inspect.
Unlocking the Black Box with Interpretability Methods
A team ships a high-performing model, then the first serious review starts. Compliance asks why a customer was denied. Support wants a repeatable way to explain edge cases. MLOps needs signals that catch regressions before they hit production. If the model stays opaque, every one of those requests turns into manual investigation.
Interpretability methods help, but they do not convert a black-box model into a transparent system. They give engineering, risk, and operations teams better evidence for debugging, review, and release decisions.

LIME for local explanation
LIME approximates model behavior around one prediction. Use it when the question is narrow and urgent: why this loan review, why this fraud score, why this ticket routing decision.
That makes it useful for operations teams. Analysts can inspect a case without waiting for a full model retrain or a custom analysis from the ML team. In practice, that shortens incident response and gives customer-facing teams something concrete to work with.
Its limit is also clear. LIME explains a small neighborhood of behavior. It does not tell you whether the model is consistent across segments, releases, or data shifts.
SHAP for feature attribution
SHAP assigns contribution values to input features. That gives teams a structured way to examine what appears to be driving a prediction.
The business value is less about satisfying curiosity and more about reducing review time. Product teams can check whether the model relies on signals that match the intended policy. Risk and compliance can look for unstable proxies or variables that create avoidable review friction. Engineers can compare attribution patterns across retraining runs and add those comparisons to CI checks.
Use SHAP as evidence, not proof. If a regulator or internal auditor needs decision logic that is straightforward to inspect, a post hoc explanation may still fall short.
Distillation for operational clarity
Model distillation trains a simpler student model to mimic a more complex teacher model. This is often the most practical interpretability move when the business still wants the accuracy profile of the larger model.
I have seen distillation pay off in two places. First, it gives reviewers a rough map of broad decision patterns, which helps with documentation and model risk review. Second, it creates a fallback path for products that need lower latency, lower cost, or simpler explanations in specific workflows.
The second-order effect shows up in staffing and pipelines. If you use distillation seriously, you now own two model tracks instead of one. Someone has to measure fidelity between teacher and student, decide when divergence is acceptable, and keep both evaluation suites current. That usually means stronger MLOps and better release discipline, not just better modeling.
Interpretability also intersects with security and audit work. Teams dealing with developer compliance for secrets often discover the same pattern in ML systems. A tool that explains behavior is helpful, but audit readiness still depends on access controls, versioned artifacts, reproducible runs, and clear ownership.
Use these methods as risk controls
Interpretability methods work best as risk controls around a black-box model.
They help teams debug failures faster, review model behavior with more discipline, and document decisions without rewriting the entire system. They also add maintenance overhead. Explanation pipelines can break, attribution outputs can drift after retraining, and someone has to validate that these diagnostics still mean what the team thinks they mean.
If the blocking stakeholder only needs better diagnostics, these methods can be enough. If the blocking stakeholder needs decision logic that is easy to inspect and defend, choose the simpler model sooner.
A short primer helps if your team is new to this space:
Evaluating Risk Compliance and Team Skill Requirements
The model choice is only the surface layer. The more expensive consequences show up later in risk management, platform ownership, and hiring.
Risk coverage changes with access
Security teams have lived with this trade-off longer than most ML teams. Black-box penetration testing simulates an outsider with no prior system knowledge, while white-box testing gives full access and enables deeper review of internal data flows and control structures. For AI systems, the same tension shows up in testing strategy.
What matters now is combination, not ideology. Recent guidance on combining black-box and white-box testing in modern AI and LLM systems points to a practical reality. End-user behavior, retrieval layers, prompts, model outputs, application code, and dependencies interact in ways that neither method covers alone.
A good release pipeline usually assigns them different jobs:
- Black-box checks for end-to-end user flows, prompt injection behavior, output regressions, and integrated systems
- White-box checks for orchestration code, data transformations, control flow, access control, and policy enforcement
Compliance affects architecture, not just paperwork
Teams often treat compliance as a review step at the end. That's a mistake.
If a use case needs transparency, auditability, or tighter internal controls, the architecture should reflect that from the start. Logging, model cards, approval trails, prompt versioning, and secret handling all become part of the system design. For teams tightening internal controls, this guide on developer compliance for secrets is useful because secret access and auditability often become part of the same operational review as model governance.
Hiring shifts with the choice you make
A white-box-first strategy usually increases demand for people who can do three things well:
- Frame the problem cleanly. Strong feature design and statistical reasoning matter.
- Work closely with domain owners. The model has to reflect policy, not just data.
- Document logic clearly. Explanations need to survive review by non-ML stakeholders.
A black-box-first strategy changes the staffing profile.
You usually need more strength in:
- MLOps and platform engineering
- Model serving, monitoring, and rollback design
- Evaluation pipelines for drift, regressions, and failure analysis
- Data and systems engineering across retrieval, APIs, and application code
If you choose an opaque model, you're often choosing a more demanding operating model too.
That's the second-order effect many teams miss. The hard part isn't training the model. The hard part is supporting it after launch with the right people, controls, and release discipline.
Your Action Plan for Choosing and Integrating an Approach
Teams often don't need a universal policy. They need a repeatable way to make a defensible choice on each product surface.
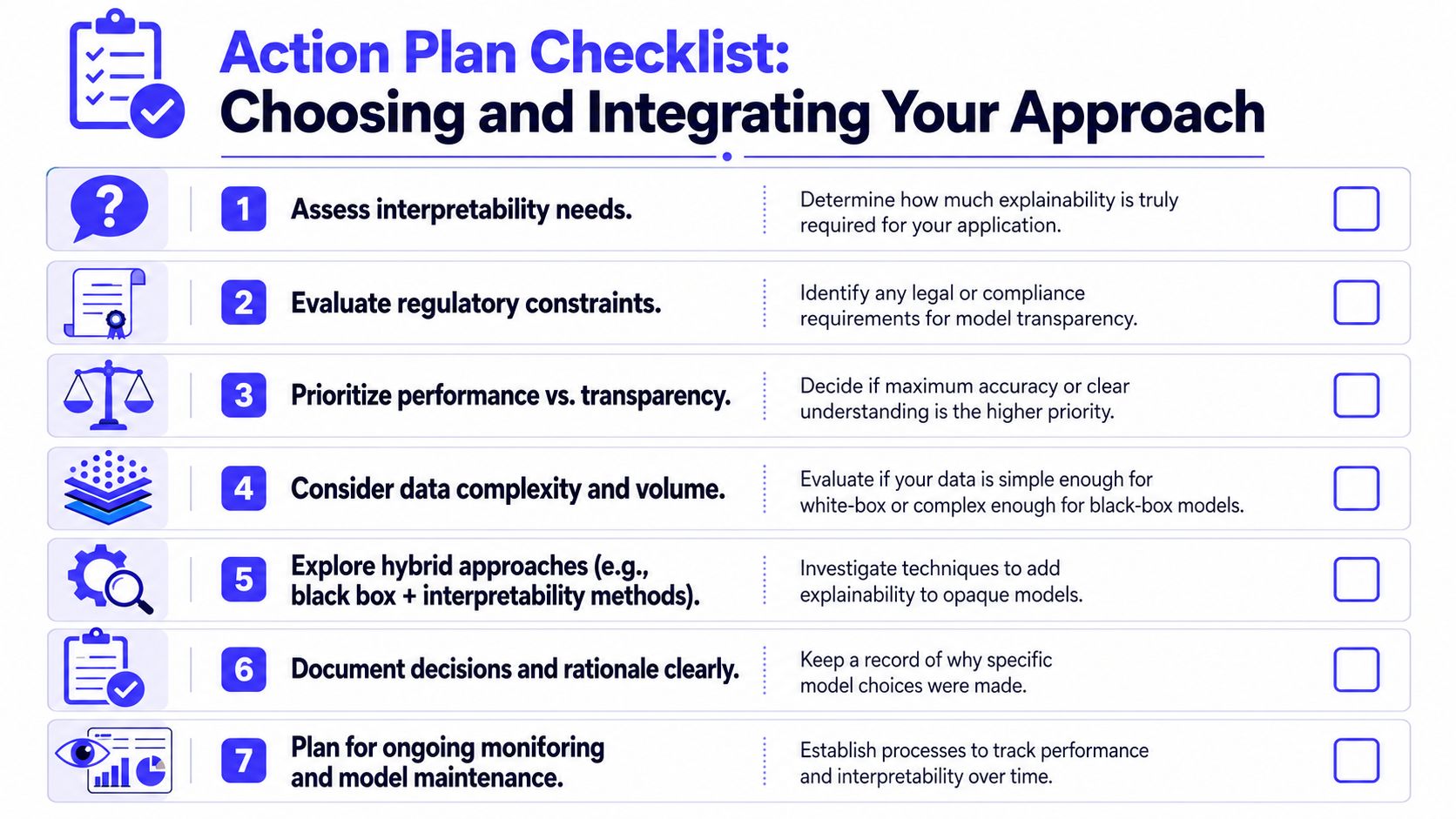
A working checklist for your next kickoff
Use this in a planning meeting with product, engineering, data, and legal.
- Interpretability requirement: Does someone need to understand individual predictions, or is aggregate performance enough?
- Regulatory and policy review: Are there internal or external rules that make opaque decisions risky?
- Performance sensitivity: If the simpler model performs worse, what breaks in the business?
- Data shape: Are you dealing with tabular policy-driven data, or complex text, images, and behavioral signals?
- Testing allocation: Which parts of the stack need end-to-end black-box checks, and which need white-box coverage of internal logic?
- Team fit: Do you have the people to operate the model you want, not just build it?
- Documentation: Can you record why this approach was chosen and what controls are in place?
Decide based on loss, not preference
Security teams already know this pattern. Black-box testing is the most realistic simulation of an external attacker, while white-box testing is more thorough for internal logic and architecture. The missing question is usually the important one: what coverage do you lose or gain at each access level, and which choice is more cost-effective for the release or threat model? That framing is highlighted in this penetration testing discussion of access-level trade-offs.
The same logic applies to models.
Don't ask which model family is better in theory. Ask:
- What risk do we accept if we can't explain a decision?
- What risk do we accept if we ship a simpler but weaker model?
- What extra engineering work appears if we choose the opaque path?
That last question is where strategy gets real. Teams making enterprise AI bets often need a broader operating model, not just a better model choice. This perspective on Doczen's enterprise AI insights is useful if you're aligning technical selection with governance and rollout planning.
Three next steps
- Score one live use case today. Don't debate AI in the abstract. Pick one workflow and run the decision framework.
- Pull legal and security in early. A short review now is cheaper than redesign later.
- Map skills against the operating model. If you choose black box, check your monitoring and MLOps depth. If you choose white box, check your domain and modeling discipline.
The right black box and white box strategy usually isn't one choice. It's a layered decision across model selection, testing depth, and team design.
If you need senior engineers who've shipped real AI systems and can help you make this call without slowing product delivery, ThirstySprout can help you build the right team fast. You can Start a Pilot or explore vetted AI, MLOps, and platform talent for explainable systems, high-performance model stacks, and production-ready CI/CD.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.