
Your AI team is shipping models, but every deployment is a manual, multi-day scramble. Environments drift. Experiments aren't reproducible. Your strongest ML engineer keeps getting pulled into Dockerfiles, GPU drivers, IAM policies, and broken pipelines instead of training better models.
That situation is common because much advice on best practices for devops stops at web apps. AI teams live in a different reality. You’re not only deploying code. You’re moving datasets, model artifacts, feature pipelines, notebooks, batch jobs, online inference services, and sometimes large language model workflows that fail in ways normal application guides don’t cover.
The gap matters. MLOps-specific DevOps practices are still poorly covered, even though a cited industry summary says a 2025 Gartner report notes that 85% of AI projects fail due to MLOps deficiencies, while fewer than 20% of DevOps resources integrate ML-specific workflows such as Kubeflow or MLflow with Kubernetes baselines (Firefly AI on DevOps best practices). If you’re building an AI product, weak platform foundations turn into slower releases, higher cloud spend, brittle compliance, and incidents your team can’t explain after the fact.
TL;DR: DevOps Best Practices for AI Teams
- Automate everything: Use Infrastructure as Code (IaC) for environments and CI/CD for model and code deployment.
- Version everything: Track code, data, model artifacts, and experiment metadata with tools such as DVC and MLflow.
- Observe everything: Monitor model behavior, data quality, drift, latency, and infrastructure health together.
- Structure the team: Assign dedicated MLOps or platform ownership instead of making ML engineers babysit infrastructure.
This guide is for CTOs, Heads of Engineering, founders, and platform leads building an AI team that has to ship reliably within weeks, not quarters. The order below is deliberate. Start with the platform basics that remove operational drag first, then add ML-specific controls that make the whole system reproducible and safe.
1. Infrastructure as Code for AI and ML environments
If your team rebuilds environments by hand, you already have hidden outages. The damage usually shows up as “works on staging,” notebook drift, broken CUDA dependencies, or a training cluster that no one can reproduce.
For AI teams, IaC is the line between a platform and a pile of cloud resources.
What good looks like
Use Terraform or CloudFormation to define the full stack. Network, storage, GPU nodes, IAM roles, secret references, batch queues, and managed databases should all live in versioned code. That gives you reviewable changes, repeatable environments, and a record of who changed what.
A simple operating model works well:
- Separate environments: Use isolated state or workspaces for dev, staging, and prod so experiments don’t leak into production.
- Reusable modules: Build modules for common ML patterns such as training jobs, notebook servers, vector databases, and model-serving services.
- Policy checks: Gate infrastructure changes with policy-as-code before apply, especially around public access, encryption, and over-broad permissions.
Practical rule: If an engineer can click it into existence in the console, another engineer can forget how it was built.
A common mini-case looks like this. An AI startup starts with one managed notebook instance and a manually created inference VM. Six months later, they have three clouds accounts, ad hoc security groups, and no idea why staging uses a different base image than production. Moving that setup into Terraform doesn’t just clean things up. It makes scaling possible because the next environment becomes a pull request, not a week of tribal knowledge.
What usually fails
Teams often write IaC once, then bypass it during deadlines. That destroys trust in the codebase. The fix is simple. Make the code authoritative. Production changes happen through pull requests only.
Another mistake is over-designing modules too early. Start with a small set of composable modules that reflect how your AI team works. A clean module for a GPU training node pool is more useful than a giant “ml-platform” abstraction nobody understands.
Here’s a representative Terraform shape for a training cluster module:
module "training_gpu_pool" {source = "./modules/gpu-node-pool"environment = "staging"instance_type = "gpu-optimized"min_nodes = 0max_nodes = 4labels = {workload = "training"owner = "ml-platform"}}That snippet matters less than the habit behind it. Treat infrastructure exactly like product code. Review it. Test it. Version it. Roll it back.
2. CI and CD pipelines for model and code deployment
Many AI teams have some form of CI for application code but almost none for model delivery. That split creates the worst kind of release process. App changes are automated. Model changes are passed around in Slack.
High-performing DevOps teams separate themselves by mastering the four DORA metrics. One industry analysis summarizing DORA reports says elite teams deploy code up to 46 times more frequently than low performers, with lead times measured in hours, change failure rates in the 0 to 15% range, and mean time to recovery under one hour (Growin on DevOps KPIs). AI teams need the same discipline, applied to both software and model artifacts.
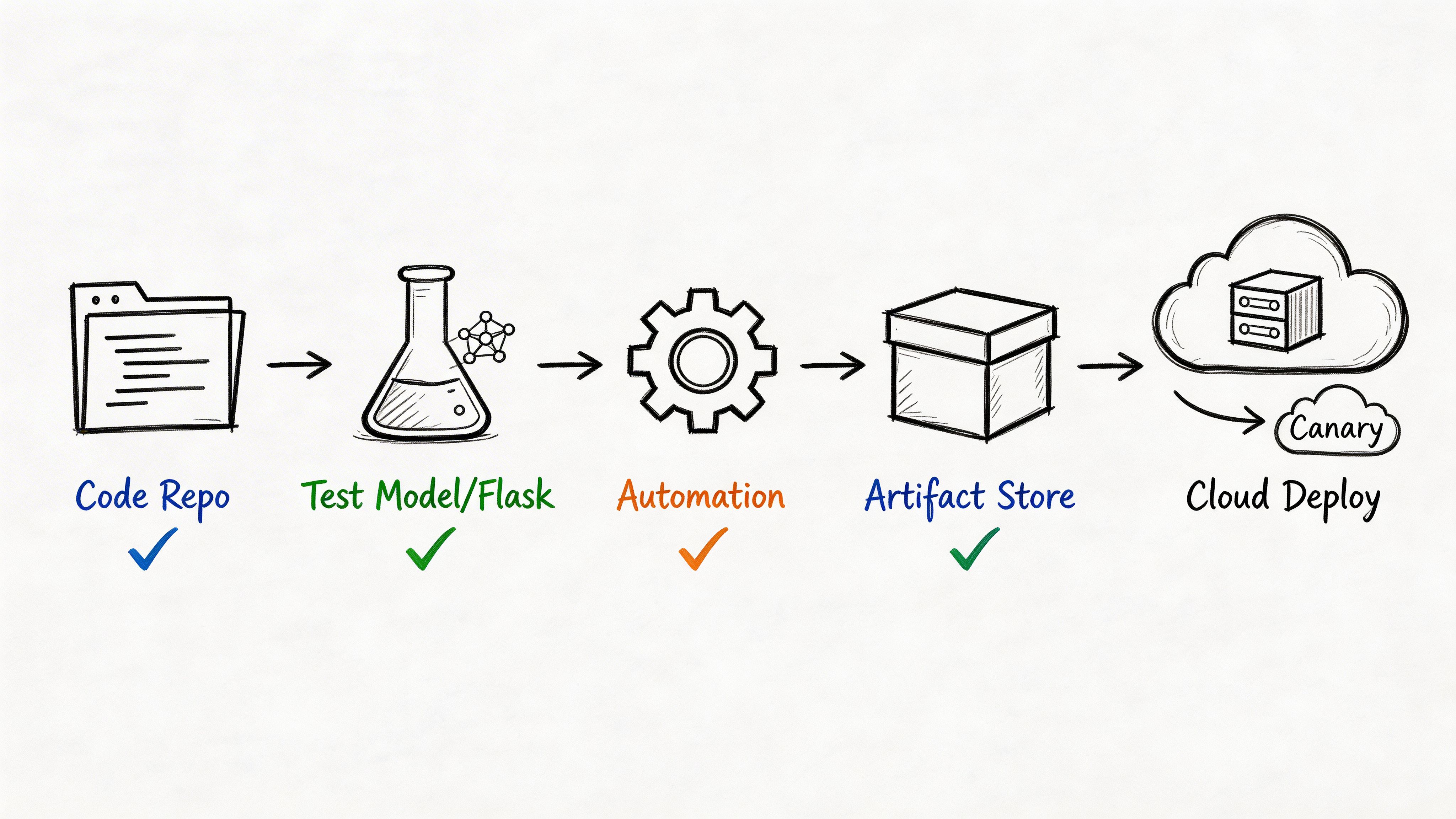
Build one pipeline, not two disconnected ones
Your pipeline should validate four things before release:
- Code health: Unit tests, dependency checks, linting, and API contract tests.
- Data expectations: Schema checks, missing-value thresholds, and feature availability.
- Model quality: Evaluation against a known baseline before promotion.
- Deployment safety: Progressive rollout, health checks, and auto-rollback.
A practical GitHub Actions flow often looks like this:
name: model-releaseon:push:branches: [main]jobs:validate:runs-on: ubuntu-lateststeps:- uses: actions/checkout@v4- name: Run testsrun: make test- name: Validate data contractrun: make validate-data- name: Evaluate modelrun: make evaldeploy:needs: validateruns-on: ubuntu-lateststeps:- name: Deploy canaryrun: make deploy-canary- name: Run smoke checksrun: make smokeWhat works in practice
Don’t retrain on every commit. That slows feedback loops and teaches engineers to ignore CI. Use cached artifacts, frozen datasets for quick checks, and scheduled or event-driven training for heavier jobs.
Canary releases and feature flags matter more for models than for normal app code. A bad model can look healthy from a CPU and memory perspective while damaging decisions. Roll out to a small slice first. Compare business-facing behavior. Then promote.
One useful pattern for AI products is split ownership. Platform engineers own the release system. ML engineers own evaluation criteria and acceptance thresholds. That keeps the pipeline consistent without turning platform into a model-approval bottleneck.
3. Containerization and orchestration with Docker and Kubernetes
Containers are where many AI teams either get serious or get stuck. If every developer uses a slightly different Python stack, and every serving service bakes dependencies differently, reliability never gets better.
Kubernetes won because it gives teams a common control plane for deployment, scaling, recovery, and scheduling. For AI teams, that includes GPU workloads, batch workers, feature services, online inference, and internal tools.
A good starting point is understanding where orchestration helps. If you’re weighing local multi-service setups against cluster orchestration, this comparison of Docker Compose vs Kubernetes offers a practical decision point.
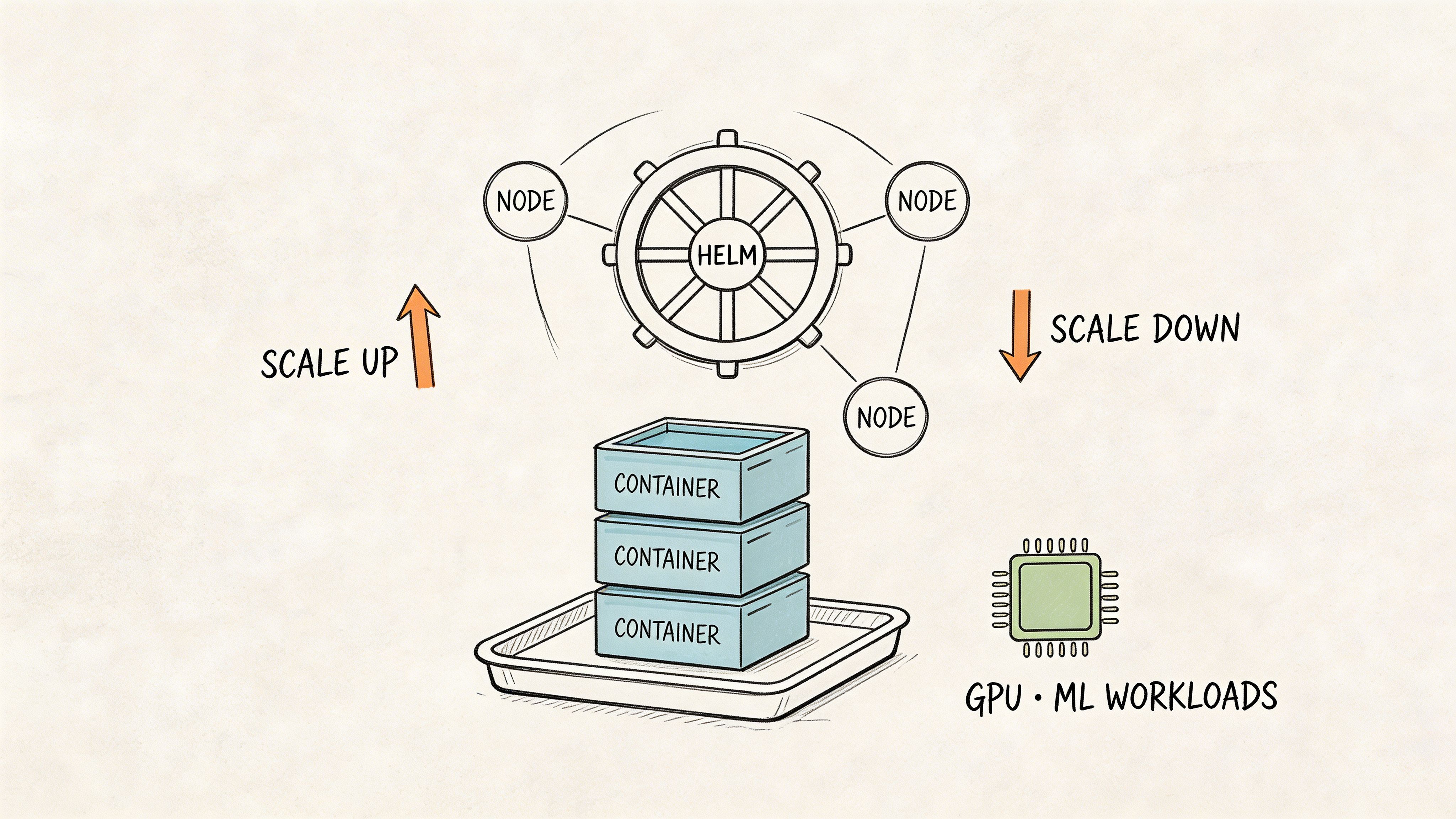
Container discipline matters more than the cluster
Most production pain starts in image design, not in Kubernetes itself.
Use slim base images. Pin dependencies. Separate training images from inference images. They have different needs. A training image may need notebooks, compilers, and experiment tools. An inference image should be as small and predictable as possible.
A practical split looks like this:
- Training image: Built for batch jobs, larger dependency set, often tied to GPU libraries.
- Serving image: Minimal runtime, explicit model artifact download or mount, fast startup.
- Utility image: Data validation, migration, feature backfills, and diagnostics.
Keep one rule firm. If you can’t rebuild the image from scratch and get the same runtime behavior, you don’t have a deployable system.
Scheduling ML workloads without wasting money
Kubernetes resource requests and limits are not optional in shared AI clusters. Without them, one training job can starve your inference service or leave GPUs idle because no one declared resource intent clearly.
For stateful ML systems such as feature-serving caches or metadata services, use the right workload type and persistent storage patterns. Don’t force every component into the same deployment template.
Teams often overcomplicate things with Helm charts before they have stable service boundaries. It’s usually better to standardize a few deployment patterns first, then package them.
Here’s the later media placement promised earlier. If your team needs a visual walkthrough of orchestration concepts, this video is a useful primer before you design your own cluster conventions.
4. Monitoring, observability, and alerting for ML systems
A CTO gets a page at 2:00 a.m. The inference service is up, latency is inside the SLO, and Kubernetes reports healthy pods. Revenue is still down because the model has been scoring on stale features for three hours.
That is the failure pattern to design for in MLOps. Traditional DevOps monitoring catches infrastructure faults. AI platforms also need to catch silent model failures, data quality regressions, and training-serving mismatches before they turn into bad decisions, wasted GPU spend, or customer impact.
As noted earlier in the article, an Octopus DevOps statistics report points to a familiar operational problem. Teams often split observability across too many tools and still struggle to reduce time to resolution. ML teams feel this more sharply because system telemetry, data pipeline health, and model behavior usually live in separate places with separate owners.

Watch the full ML service, not just the endpoint
A useful production view for AI systems answers three questions fast:
- Is the service available and meeting latency targets?
- Is the input data complete, fresh, and shaped the way the model expects?
- Are predictions still behaving within business and statistical guardrails?
That means combining infrastructure telemetry with ML-specific signals. Track request latency, saturation, queue depth, and GPU utilization. Track schema changes, null spikes, feature freshness, and distribution shifts. Track output drift, confidence changes, class mix, and offline-to-online skew.
I usually advise teams to assign one owner for that end-to-end picture. The dashboards can pull from Prometheus, Grafana, Datadog, Splunk, New Relic, OpenTelemetry, or a mix of tools. Ownership cannot be fragmented. If platform engineers own pods, data engineers own pipelines, and data scientists own model metrics without a shared escalation path, incidents last longer than they should.
Alert on business risk, not only on outages
ML incidents rarely start as hard downtime. A ranking model can keep serving while an upstream feature defaults to zero. A fraud model can respond on time while feature freshness slips far enough to increase false negatives. The API stays green. The business does not.
Set alerts in layers:
- Platform alerts: error rate, tail latency, resource saturation, failed jobs, GPU starvation
- Data alerts: schema drift, missing columns, delayed features, unexpected null rates, training-serving skew
- Model alerts: prediction drift, confidence collapse, output distribution changes, policy threshold breaches
- Business alerts: conversion drop, approval rate swing, abnormal escalation volume, cost per prediction spike
That last layer matters more than many teams expect. If a larger model version doubles GPU cost with no gain in decision quality, observability should catch it. MLOps is not only about uptime. It is also about controlling inference cost and proving that model behavior still supports the business case.
A practical operating model
Use traces and logs to debug serving paths. Use metrics to detect drift and degradation trends. Use sampled prediction records and feature snapshots for root cause analysis, with the right privacy controls in place.
Teams also need disciplined ownership around model releases, rollback criteria, and audit trails. Strong source code management practices for ML platforms make observability more useful because alerts are easier to tie back to a specific model version, feature definition, or pipeline change.
One rule keeps this section grounded. If an on-call engineer cannot answer what changed, which models are affected, and whether the issue is infra, data, or model logic within a few minutes, the monitoring stack is producing noise instead of operational control.
5. Version control for data, models, and code
Git alone is not enough for machine learning. It solves code history well. It does almost nothing for datasets, large model artifacts, training configurations, or experiment lineage.
That gap explains a lot of AI team friction. Someone asks, “Which model is in production?” Then the answers start with “I think.”
Version the full lineage
For AI systems, the release unit is bigger than a commit hash. You need to know which code version trained which model on which dataset with which parameters, and what evaluation result justified promotion.
A practical stack often looks like this:
- Git: Source code, pipeline definitions, metadata files.
- DVC or similar: Dataset references, large artifact tracking, reproducible data stages.
- MLflow or similar: Experiment runs, parameters, metrics, model registry.
Teams that need stronger engineering foundations for repositories and workflows should also tighten their source code management practices, because MLOps versioning breaks down quickly when branching, ownership, and review standards are loose.
Mini-case for reproducibility
A remote team trains a model in one region using an updated dataset bucket. Another team member later reruns the experiment in staging and gets different results because the preprocessing step pulled newer data and a different feature config. No outage occurs immediately, but trust in the entire workflow drops.
The fix is boring and powerful. Store references to the dataset snapshot, preprocessing version, environment image, and model artifact in the same release record. Then promotion becomes traceable instead of conversational.
A naming convention helps more than teams expect:
project/model-namedataset-snapshotfeature-set-versiontraining-configcandidateorproduction
This isn't process for process’s sake. It’s what lets you answer auditors, debug regressions, and roll back a model safely without guessing which artifact was serving traffic.
6. Infrastructure scaling and resource management
Cloud costs in AI don’t usually explode because teams chose the wrong vendor. They explode because nobody put workload boundaries around training, batch processing, and online inference.
The expensive mistake is letting every workload compete for the same pool without scheduling rules.
Split workloads by behavior
Training jobs are bursty and often fault tolerant. Inference workloads need predictable latency. Feature pipelines may be time-sensitive but not user-facing. Treating all three the same creates waste.
Use different node pools, queue policies, and autoscaling behavior for each class of work. In Kubernetes, that often means dedicated node groups, taints and tolerations, and explicit resource classes. Outside Kubernetes, the same principle still applies. Separate capacity by workload behavior.
One practical example. Put notebook experimentation and ad hoc research on a lower-priority pool with strict idle shutdown rules. Keep production inference isolated from that pool entirely. Your engineers still get flexibility, but not at the cost of customer-facing stability.
Right-size first, then optimize
Many teams chase “GPU optimization” too early. Start with visibility.
Track:
- Utilization by workload type
- Queue time for jobs
- Idle time on expensive nodes
- Resource requests versus actual use
Once you have that, make policy decisions:
- Batch training: Good candidate for preemptible or spot-style capacity when retries are acceptable.
- Online inference: Reserve predictable capacity and scale conservatively.
- Backfills and feature recompute: Schedule outside peak serving windows when possible.
A useful operating habit is requiring cost allocation tags or labels on all AI infrastructure. If a team can’t identify the owner of a cluster, job, or dataset store, nobody will clean it up.
The business outcome is straightforward. Better resource management lowers waste and reduces “urgent” procurement or cloud escalations that are really scheduling problems in disguise.
7. Automated testing and validation for ML models
Traditional test suites catch syntax errors, API breaks, and obvious regressions. They don’t tell you whether a model still behaves acceptably after a feature change or data refresh.
That’s why AI pipelines need a broader definition of test coverage.
Expand the test pyramid for ML
You still need unit and integration tests. But they’re only the base layer.
Add ML-specific checks such as:
- Data validation: Required columns, types, null thresholds, cardinality checks.
- Training validation: Sanity checks on label distribution, convergence behavior, and artifact creation.
- Model evaluation gates: Compare against a known baseline before promotion.
- Serving validation: Smoke tests against the actual inference path, not a notebook-only path.
A good release question is not “Did the pipeline pass?” It’s “What evidence says this model is safe enough to deploy?”
Operator note: A model that matches offline metrics but fails online feature assumptions is not a test success. It’s a missing test.
A practical release gate
For a recommendation or classification service, define a small release contract:
- the incoming schema matches expected features
- the model artifact can load in the serving container
- predictions return in a valid range
- latency stays within the service budget
- comparison against the previous production model shows no unacceptable regression by your chosen business criteria
This doesn’t need a giant governance process. It needs clear pass-fail logic.
A strong pattern is to keep “fast tests” on every commit and “expensive tests” on merge or scheduled release candidates. That protects developer speed while still creating confidence before promotion.
What doesn’t work is relying on one final manual review. Humans are useful for edge-case judgment. They are bad at acting as your primary quality gate for repetitive release checks.
8. Feature stores and data pipeline management
A lot of model failures come from one boring source. The features used during training are not the same features used during serving.
That mismatch is expensive because it’s hard to spot. The pipeline runs. The service returns predictions. Only later do teams realize the offline transformation logic drifted from the online path.
Start with consistency, not platform ambition
Feature stores can help, but many teams adopt them too early and turn a solvable data contract issue into a platform project.
The right progression is usually:
- Standardize feature definitions.
- Document ownership and lineage.
- Make training and serving read from the same logic or governed outputs.
- Add feature store capabilities when reuse and online serving justify them.
For some teams, a clean warehouse model plus reliable batch orchestration is enough for a long time. For others, especially low-latency inference teams, an online feature layer becomes necessary earlier.
What teams should document
Every production feature should have:
- Owner
- Source system
- Transformation logic
- Refresh expectation
- Consumers
- Fallback behavior
A simple mini-case. A growth model uses “recent_user_activity” during training from a warehouse snapshot. At serving time, the API reads a similarly named field from a caching layer with different freshness and null handling. The names match. The values don’t. A documented contract would have exposed the mismatch before release.
Airflow, Prefect, Dagster, and managed workflow services all work if the contracts are clear. Tool choice matters less than consistency between training and serving.
If you only take one action here, make feature ownership explicit. Unowned data pipelines become everyone’s hidden dependency and no one’s priority during incidents.
9. Security, compliance, and access control
Security failures in AI systems are usually boring first and catastrophic later. An over-permissioned service account. A secret in a notebook. A model artifact bucket open wider than it should be. A CI job that can deploy to production from the wrong branch.
For AI teams, the blast radius is often larger because sensitive data, proprietary prompts, models, and training artifacts all sit in the same operating environment.
Teams handling regulated or high-sensitivity workloads should tighten their approach to securing big data, especially where feature pipelines and training datasets cross security boundaries.
Build security into delivery, not after it
The strongest pattern is DevSecOps discipline inside the normal pipeline:
- dependency and image scanning
- secrets management
- least-privilege IAM
- encrypted storage paths
- audit logs for data and model access
- policy checks on infrastructure and deployment changes
The earlier cited DORA summary notes that top teams keep change failure rates low by integrating testing and security checks early in delivery. That principle matters even more in AI, where a rushed release might expose both application risk and data risk.
Practical controls that pay off quickly
- Secrets: Keep credentials in Vault, AWS Secrets Manager, or your cloud equivalent. Never in notebooks or repo files.
- IAM: Separate permissions for training, inference, and platform administration. Don’t hand broad production access to every ML engineer.
- Artifacts: Restrict who can push, promote, and load production models.
- Auditability: Record who changed datasets, deployment configs, and model versions.
A realistic trade-off is speed versus friction. If security reviews happen only as ticket-based approval at the end, engineering will route around them. Put the controls in CI, IaC policy, and runtime access patterns instead.
That’s the version teams can sustain.
10. Incident response and disaster recovery for ML systems
At 2 a.m., the API is up, latency looks normal, and customers are still getting bad answers. That is a standard ML incident. The service is healthy. The system is failing.
Generic incident playbooks break down here because ML failures often sit in the gap between software, data, and infrastructure. A model can drift without throwing errors. A feature pipeline can keep running while serving stale values. A training job can miss its window because GPU capacity disappeared under a higher-priority workload. If the response plan only covers app outages, the team loses hours proving the web tier is fine while the business keeps absorbing bad predictions.
Write runbooks around ML failure modes and assign clear owners for each one. Include cases such as bad model promotion, upstream schema drift, stale online features, failed retraining on a scheduled refresh, vector index corruption, and GPU pool loss for production training or batch inference. For every scenario, define the trigger, the first diagnostic checks, the rollback target, the approval path, and the customer communication channel.
Recovery in ML systems depends on three separate rollback decisions:
- which application version to restore
- which model artifact to restore
- which data, feature set, or index snapshot to restore or isolate
That separation matters. In a traditional service incident, rolling back the app often fixes the issue. In an ML incident, the code may be fine while the promoted model is wrong, the feature values are stale, or the embedding index is out of sync with the current corpus. Teams that do not track lineage across code, model, and data turn incident response into manual forensics.
A runbook template should stay short enough to use under pressure:
- Detection signal
- Customer and business impact
- Recent changes across code, model, data, and infrastructure
- Rollback or containment target
- Validation checks after recovery
- Owner, escalation path, and decision-maker
- Post-incident actions
I recommend treating rollback as a product capability, not an operator trick. That means keeping previous model versions deployable, preserving feature and dataset snapshots for a defined recovery window, and making index rebuilds scripted instead of tribal knowledge. The trade-off is storage cost and some pipeline overhead. The payoff is lower downtime, lower incident labor, and less revenue risk when a model release goes bad.
Disaster recovery for ML also needs a broader scope than infrastructure failover. A secondary region helps if the cluster is down. It does not help if you replicate corrupted features, promote a biased model globally, or lose the metadata that maps a prediction service to the exact training set and hyperparameters behind it. Back up the control plane for ML operations: experiment metadata, model registry state, feature definitions, pipeline configs, secrets references, and deployment history.
Test the plan with simulations. Include scenarios where the infrastructure stays healthy but the outputs are wrong. That is the failure pattern AI teams see often, and it is the one generic DevOps playbooks usually miss.
10-Point Comparison of DevOps Best Practices for ML Systems
| Solution | 🔄 Implementation Complexity | ⚡ Resource Requirements | 📊 Expected Outcomes | Ideal Use Cases | ⭐ Key Advantages & 💡 Tips |
|---|---|---|---|---|---|
| Infrastructure as Code (IaC) for AI/ML Environments | High (declarative setup, state management and locking) | Moderate (IaC tooling plus access to cloud/GPU provisioning) | Consistent, reproducible environments; faster deployments; audit trail | Provisioning GPU clusters, multi-env parity, disaster recovery | ⭐ Eliminates drift; 💡 use reusable modules, separate state per env, enforce code reviews |
| CI/CD Pipelines for Model and Code Deployment | High (multi-stage automation and integrations) | High (CI runners, artifact stores, test compute (can be heavy for training)) | Frequent low-risk deployments; faster time-to-market; automated validation | Model rollout, staging→production, automated testing and canaries | ⭐ Catches regressions early; 💡 favor fast feedback suites, use artifacts/feature stores, implement canary rollouts |
| Containerization & Orchestration (Docker & Kubernetes) | High (container lifecycle and K8s operational complexity) | High (registries, cluster management, GPUs, networking) | Portable, scalable serving and training; reproducible runtimes; autoscaling | Production model serving, multi-component ML systems, scalable training | ⭐ Solves "works on my machine"; 💡 build slim images, set resource requests and limits, use private registries |
| Monitoring, Observability & Alerting for ML Systems | Medium–High (metrics, traces, and model-specific telemetry setup) | High (metrics/log storage and observability stack) | Faster detection and diagnosis; lower MTTR; model drift detection | Production inference, SLA-driven services, compliance-sensitive apps | ⭐ Visibility into model behavior; 💡 track model metrics, tune alerts to avoid fatigue, prepare runbooks |
| Version Control for Data, Models, and Code | Medium (workflow changes and tool adoption) | Moderate (artifact storage (S3/GCS), metadata in Git) | Reproducible experiments; auditability; easy rollback and comparison | Experiment tracking, regulated environments, reproducible research | ⭐ Enables lineage and reproducibility; 💡 store artifacts in cloud, track metadata in Git, standardize naming |
| Infrastructure Scaling & Resource Management | Medium–High (autoscaling policies and scheduling logic) | Variable (autoscalers, spot integrations, schedulers, monitoring) | Cost-optimized resource usage; predictable training conditions; reduced contention | Burst training, multi-tenant clusters, cost-sensitive workloads | ⭐ Optimizes cost and utilization; 💡 use spot for batch jobs, monitor GPU utilization, implement quotas |
| Automated Testing & Validation for ML Models | Medium–High (defining meaningful baselines and tests) | Moderate–High (compute for validation and regression suites) | Prevents regressions; detects bias and data issues before deploy | Model release pipelines, compliance-focused deployments, QA gating | ⭐ Reduces production surprises; 💡 define baselines, add fairness tests, use mutation testing |
| Feature Stores & Data Pipeline Management | High (building catalog, online/offline stores and pipelines) | High (storage, low-latency serving, orchestration systems) | Consistent train/serve features; faster feature reuse and iteration | Organizations with many models, shared feature requirements | ⭐ Eliminates duplication, ensures consistency; 💡 start with offline store, enforce producer/consumer contracts |
| Security, Compliance & Access Control | Medium–High (RBAC, secrets, encryption, and auditing) | Moderate (secrets managers, scanning tools, encrypted storage) | Reduced risk and regulatory compliance; protected IP and data | Fintech, healthcare, regulated enterprise AI deployments | ⭐ Essential for trust and regs; 💡 use least-privilege, manage secrets centrally, scan images in CI |
| Incident Response & Disaster Recovery for ML Systems | Medium (runbooks, alerting, failover planning and testing) | Moderate (on-call tools, backup/replication, DR infrastructure) | Faster incident resolution; business continuity; post-incident learning | Mission-critical AI features, high-availability services | ⭐ Minimizes downtime impact; 💡 create ML-specific runbooks, automate rollback, run DR simulations quarterly |
What to Do Next: Implementing DevOps Best Practices
A familiar pattern plays out in AI teams. The model shows promise in a notebook, leadership wants it in production, and the team spends the next month fighting environment drift, unclear ownership, GPU shortages, and releases that are hard to roll back. The problem usually is not model quality alone. It is the absence of an operating system for shipping AI reliably.
Start by sequencing the work. AI teams get more value from a stable foundation than from adding every MLOps tool at once. In practice, the first layer is Infrastructure as Code, CI/CD, and version control across code, data, and model artifacts. Once those controls are in place, you can add observability, security, scaling policies, and disaster recovery without building on guesswork.
That matters because ML systems are harder to run than standard web services. You are not only deploying code. You are managing training jobs, batch and real-time pipelines, expensive GPU capacity, model lineage, and prediction quality in production. Traditional DevOps gives you the baseline. MLOps extends it to handle the parts that break when data changes, models drift, or training and serving environments diverge.
For many CTOs, a primary bottleneck is ownership.
If nobody owns AI platform reliability, the work lands on the nearest ML engineer or backend lead. That creates inconsistent standards, undocumented infrastructure, and expensive delays in product delivery. It also raises risk. A team that cannot trace which data trained a model or reproduce the environment that served it will struggle during incidents, audits, and customer escalations.
A dedicated MLOps or platform function fixes that, but the shape should match your stage:
- Early-stage startup: One platform-minded engineer can standardize environments, build CI/CD, manage cloud foundations, and set rules for model promotion.
- Growing AI product team: Add explicit MLOps ownership for training pipelines, model registry, observability, and GPU scheduling.
- Multi-team organization: Build a platform team that offers self-service tooling, shared Kubernetes patterns, access controls, and guardrails while product teams keep responsibility for their own services and models.
The hiring profile should be blended. Pure infrastructure talent often misses model lifecycle risks. Pure ML talent often underestimates release engineering, security, and production support. Strong candidates can discuss trade-offs clearly: when to separate training and inference clusters, how to version large datasets, what to monitor beyond latency, and how to roll back a bad model when the service is healthy but prediction quality is not.
Ask questions that expose operating judgment:
- How have you versioned datasets, features, and model artifacts in production?
- What do you monitor for an inference service besides uptime, latency, and CPU?
- How would you detect and contain a bad model release caused by data drift?
- How would you split Kubernetes capacity between bursty training jobs and latency-sensitive inference workloads?
- Where would you enforce approval gates for regulated models?
Good answers include design choices, constraints, and failure modes. They should mention cost, reproducibility, and risk, not only tooling.
The next three steps are practical.
- Assess current maturity. Use the 10 practices in this guide as an operating checklist. Mark each one as manual, partially automated, or production-ready. If the team is still firefighting, start with IaC, CI/CD, and artifact versioning.
- Set ownership and scope. Decide whether you need one senior MLOps engineer, a platform lead, or a small team. Tie that role to outcomes the business cares about: shorter release cycles, lower cloud waste, better auditability, fewer production incidents.
- Add experienced builders. AI infrastructure takes longer to learn through trial and error than many teams expect. Engineers who have already run model training, deployment, observability, and incident response in production reduce that learning curve.
If you need a broader engineering lens alongside this guide, this reference on software development lifecycle best practices is a useful companion for process design around planning, delivery, and quality.
Ready to build a platform your AI team can trust? ThirstySprout helps companies hire vetted remote MLOps, platform, and AI engineers who have shipped production systems and understand the operational realities behind training pipelines, Kubernetes, model delivery, and cloud cost control.
If you need senior MLOps or platform engineers who can build CI/CD, Kubernetes, observability, and model delivery systems without months of ramp-up, ThirstySprout can help you start a pilot quickly and meet vetted AI infrastructure talent who’ve done this in production.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.