
TL;DR
- Go Beyond Theory: Ask practical system design questions like "Design a real-time recommendation system" or "Design a data drift detection system" to test production experience.
- Focus on the Full Lifecycle: Include questions on debugging, MLOps, model evaluation, and feature engineering. A great AI engineer builds, deploys, and maintains systems.
- Use Behavioral Questions for Depth: A question like "Tell me about a time you debugged a complex model" reveals more about a candidate's problem-solving process than a dozen definition questions.
- Actionable Next Step: Use the rubric and checklist provided below to standardize your interview process and reduce bias. This helps you identify top talent faster.
Who this is for
- CTO / Head of Engineering: You need to hire senior AI talent who can own features from architecture to deployment and connect their work to business impact.
- Hiring Manager / Tech Lead: You are responsible for vetting candidates' technical depth and ensuring they can contribute to your production ML systems from day one.
- Founder / Product Lead: You are building an AI feature and need to hire the foundational engineers who have the pragmatic skills to ship and iterate quickly.
This guide provides a battle-tested set of AI engineer interview questions to help you identify candidates with true engineering depth, not just theoretical knowledge.
The Interview Framework: 4 Critical Skill Domains
Generic coding challenges miss the point. To hire an effective AI engineer, your interview process must assess practical competence across four critical domains. Use these categories to structure your interviews and scorecards.
- Deep Technical Fundamentals: Can they explain core concepts like the Transformer architecture from first principles?
- Scalable System Design: Can they architect an end-to-end MLOps pipeline or a real-time recommendation system, considering trade-offs?
- MLOps and Production Readiness: How do they handle real-world challenges like data drift, model evaluation, and complex debugging?
- Pragmatic Problem-Solving: Do they connect technical decisions to business outcomes, cost, and user experience?
1. Explain the Transformer Architecture and the Self-Attention Mechanism
This is a foundational technical question. A candidate's ability to explain the Transformer architecture, introduced in "Attention is All You Need," reveals their depth beyond just using APIs. It’s the core technology behind models like GPT and BERT.
The key innovation was replacing the sequential processing of Recurrent Neural Networks (RNNs) with a parallelizable architecture built on self-attention. This allows the model to weigh the importance of all tokens in a sequence simultaneously, capturing complex, long-range dependencies more effectively.
Alt text: Diagram showing the self-attention mechanism in a Transformer model, a key part of AI engineer interview questions on architecture.
What a Strong Answer Looks Like
A strong response moves from high-level intuition to specific mechanisms.
- High-Level Concept: The candidate first explains why attention is needed, contrasting it with the bottlenecks of RNNs in handling long-distance relationships.
- Core Mechanism (Self-Attention): They must clearly define the roles of Queries (Q), Keys (K), and Values (V). A great explanation uses an analogy, like a database lookup.
- Key Components: A comprehensive answer also mentions Multi-Head Attention (letting the model focus on different parts of the input), Positional Encodings (to provide sequence order), and the Encoder-Decoder structure.
Practical Example: Interview Scorecard
Use this simple rubric to standardize your team's evaluation.
For more details on applications, explore our guide to the core concepts of natural language processing.
2. Design a Real-Time Recommendation System at Scale
This system design question tests a candidate's ability to architect a complete, production-ready ML system. It evaluates their thinking on data pipelines, model serving, latency, and the trade-offs between accuracy and speed for millions of users.
The goal is an end-to-end architecture that ingests user data, trains recommendation models, and serves personalized suggestions in real-time. A successful design balances sophisticated modeling with the engineering reality of high-throughput performance.
Alt text: Workflow diagram detailing steps from a funnel through candidate list and data storage to low hornet.
What a Strong Answer Looks Like
A great answer is a structured conversation that clarifies requirements before drawing blueprints.
- Clarifying Requirements: They start by asking about scale (users, items), latency requirements (<100ms), and business goals (e.g., increase engagement vs. clicks).
- High-Level Architecture: They propose a multi-stage architecture, typically involving candidate generation (retrieval) and ranking. This shows they know how to make large-scale recommendations tractable.
- Key Components: They discuss data flow, including real-time event streams (e.g., Kafka) and batch processing for training. They mention specific model types, like matrix factorization (retrieval) and gradient-boosted trees (ranking).
- Operational Concerns: Strong candidates address practical challenges like the cold-start problem (new users/items), monitoring for model drift, and designing an A/B testing framework.
Practical Example: Mini Case Study
- Scenario: A news site wants to recommend articles.
- Candidate Generation: Use a simple model like Collaborative Filtering (via matrix factorization) or content-based filtering (e.g., TF-IDF on article text) to quickly select a few hundred relevant articles from millions.
- Ranking: Use a more complex model like XGBoost to rank the 200 candidates. The ranking model uses richer features (user history, article popularity, time of day) to predict the click-through rate.
- Serving: Serve the top 10 ranked articles to the user. The entire process must complete in under 150ms.
- Problem Context (Situation & Task): The candidate concisely sets the scene. What was the model? What was its business purpose? What was the unexpected behavior (e.g., performance drop, bizarre predictions)?
- Systematic Debugging (Action): This is the core of the answer. They should describe their step-by-step process. Did they form a hypothesis? Did they check data integrity first, then model configuration, then the pipeline? Look for a structured approach, not random trial and error.
- Resolution and Impact (Result): What was the root cause? How did they fix it? Crucially, they should quantify the business impact (e.g., "accuracy recovered from 75% to 92%"). They should also discuss what they learned and what processes they implemented to prevent recurrence.
- Strong Answer (5/5): Articulates a complex problem. Describes a systematic, hypothesis-driven debugging process. Quantifies the impact and discusses preventative measures.
- Medium Answer (3/5): Describes a real problem but provides a fuzzy account of their debugging steps. The process feels more like luck than a repeatable methodology.
- Weak Answer (1/5): Cites a simple bug (e.g., a syntax error) or cannot recall a significant debugging experience. This suggests a lack of hands-on experience.
- Clear Definitions: The candidate must first define underfitting and overfitting by describing their impact on training versus validation performance.
- Mitigation for Overfitting: Look for specific techniques like L1/L2 regularization (explaining they add a penalty for large weights), dropout, early stopping, and data augmentation.
- Mitigation for Underfitting: The candidate should also cover the other side, suggesting solutions like using a more complex model, feature engineering, or training for longer.
- Strong Answer (5/5): Clearly explains the bias-variance tradeoff. Lists at least three distinct strategies for mitigating overfitting and at least two for underfitting. Can explain why these techniques work.
- Medium Answer (3/5): Correctly defines overfitting and underfitting. Can name one or two common solutions but struggles to explain the mechanisms behind them.
- Weak Answer (1/5): Confuses the definitions or provides vague advice. Indicates a critical gap in fundamental ML knowledge.
- Scoping and Requirements: They start by asking clarifying questions about the use case, scale, latency requirements, and data characteristics.
- Component Breakdown: They walk through each key stage: Data Ingestion, Data Validation & Processing, Model Training (with retraining triggers), Model Validation & Versioning, Deployment Strategy (e.g., Canary, Blue/Green), and Monitoring.
- Reliability and Operations: A production-ready mindset is crucial. The candidate should address logging, alerting for data drift, and system resilience. For resilient deployments, candidates should understand concepts like multi-provider failover strategies.
- Tooling vs. Concepts: While mentioning tools (e.g., Kubeflow, MLflow) is good, the focus should be on the function of each component and the reasoning behind their choices.
- Distinction Between Evaluation Types: The candidate must differentiate between automatic evaluation (using metrics like ROUGE or BERTScore) and human evaluation (using human raters to assess helpfulness and factual accuracy).
- Task-Specific Metrics: They should explain that while general benchmarks (e.g., MMLU) are useful, production success requires custom evaluation sets tailored to the specific task (e.g., measuring factual consistency for a RAG system).
- Beyond Accuracy: A senior candidate will proactively discuss evaluating for safety, bias, and fairness. They should also consider operational metrics like latency and cost per inference.
- Go Beyond the Obvious: They should explain why they chose a specific framework for a project. For example, "We chose PyTorch for its dynamic computational graph, which was essential for our research, while we used Scikit-learn for baselines due to its simplicity."
- Acknowledge Trade-offs: A great candidate will discuss the challenges they faced, like TensorFlow's initial steep learning curve or the production complexities of a research-focused library.
- Ecosystem Awareness: The answer should extend beyond model-building libraries to include tools for data processing (Pandas, Dask), experiment tracking (Weights & Biases, MLflow), and deployment (Docker, Kubernetes).
- High-Level Concept: They start by defining data drift (changes in input data) and concept drift (changes in the input-output relationship).
- Drift Detection: They should discuss specific statistical methods like the Kolmogorov-Smirnov (KS) test for numerical features or Chi-Squared tests for categorical features to compare distributions between training and live data.
- System Architecture: An excellent answer details a full architecture: logging inputs/outputs, a monitoring dashboard, automated alerting (e.g., PagerDuty, Slack), and a clear action plan (e.g., manual analysis vs. automated retraining triggers).
- Systematic Approach: The candidate should describe a repeatable process: start with brainstorming based on domain knowledge, move to data exploration (EDA), generate features, and then use validation techniques to select the best ones.
- Domain Knowledge Application: They should emphasize understanding the business problem to hypothesize useful features. For a customer churn model, they might suggest creating features like
days_since_last_purchase. - Iterative Validation: A great answer will highlight that feature engineering is not a one-shot task. They should mention using feature importance scores or permutation importance to empirically validate which features add value.
- Production Awareness: Top candidates will also consider the computational cost of generating a feature and data availability at inference time.
- Establish a Baseline: The first step should always be creating a simple model (e.g., Logistic Regression) to establish a performance floor and benchmark.
- Systematic Approach: They should describe an incremental process, moving from simpler models to more complex ones (e.g., XGBoost to a neural network) only when justified by performance gains.
- Tuning Strategy: A key differentiator is discussing hyperparameter tuning. They should explain the inefficiency of Grid Search and advocate for methods like Random Search or Bayesian Optimization, mentioning the trade-off with the computational budget.
- Rigorous Validation: The candidate must emphasize using robust validation, such as k-fold cross-validation, to get reliable performance estimates.
- Define a Scorecard: For each question, create a simple 1-5 rubric defining what a weak, medium, and strong answer looks like.
- Calibrate Interviewers: Before interviews, have your team score a mock candidate's answers together to ensure everyone uses the same evaluation bar.
- Use a Practical Take-Home: Replace abstract algorithm puzzles with a small, scoped project that mirrors a real problem your team faces (e.g., build a simple API for a model, including data validation and a README).
- Test for Product Mindset: Ask candidates to critique a recent AI product launch or discuss the trade-offs between model accuracy and user experience. The best engineers think like owners.
- Share this guide with your hiring team. Use the questions and scorecards to standardize your interview process this week.
- Identify 1-2 system design questions that are most relevant to your upcoming projects and make them a core part of your interview loop.
- Book a scoping call with ThirstySprout. If you need to hire elite, pre-vetted remote AI engineers in weeks, not months, we can help you build your team faster.
3. Tell Me About a Time You Debugged a Complex ML Model Issue
This behavioral question reveals real-world problem-solving skills and intellectual honesty. Great AI engineers are systematic detectives who can diagnose issues ranging from silent data drift and training bugs to unexpected inference behavior.
Unlike a coding challenge, this question assesses the candidate's methodology. Their response demonstrates their practical experience and technical maturity.
What a Strong Answer Looks Like
A strong response follows a clear narrative, like the STAR (Situation, Task, Action, Result) method.
Scoring Rubric
4. Explain Overfitting vs. Underfitting and Mitigation Strategies
This foundational question tests a candidate's grasp of the bias-variance tradeoff. The ability to diagnose and solve these issues is non-negotiable for anyone building reliable machine learning systems.
Underfitting (high bias) occurs when a model is too simple to capture underlying patterns. Overfitting (high variance) happens when a model is too complex and learns the training data's noise, failing to generalize to new data.
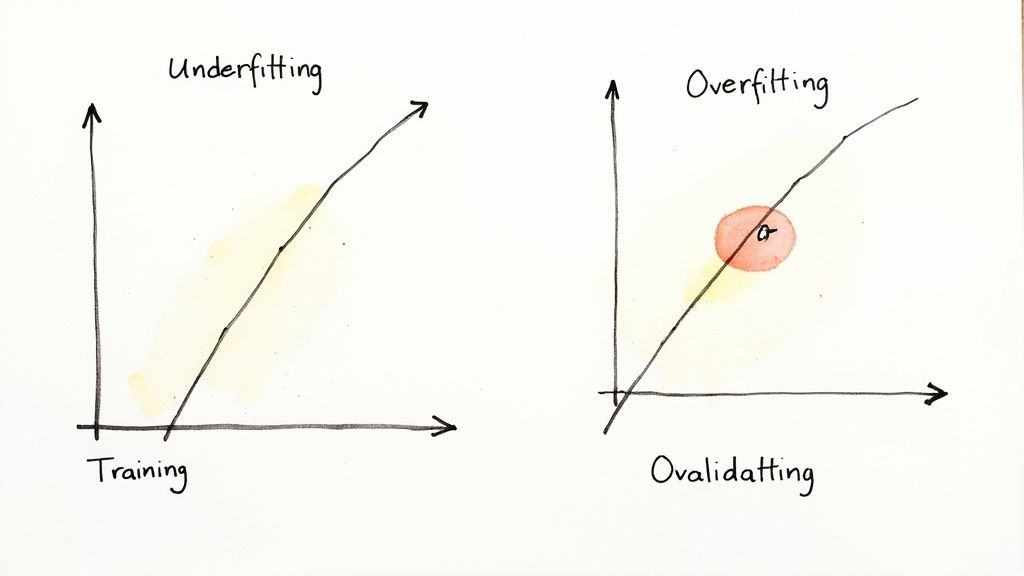
Alt text: Two hand-drawn graphs illustrate underfitting and overfitting machine learning concepts with data points.
What a Strong Answer Looks Like
A strong response clearly defines both concepts and pivots to practical, actionable mitigation strategies.
Scoring Rubric
5. Design an End-to-End MLOps Pipeline for Production
This system design question reveals a candidate's ability to architect robust, automated systems that deliver business value. It tests their practical knowledge of the entire machine learning lifecycle, from raw data to a live, monitored product.
The goal is to assess if the engineer can connect data engineering, model development, deployment, and operations into a cohesive workflow. It’s a direct indicator of their ability to ship and maintain real-world AI applications.
What a Strong Answer Looks Like
A great response is structured, moving logically through each stage of the pipeline.
To dive deeper into operationalizing these pipelines, see this guide on MLOps best practices.
6. How Would You Evaluate a Large Language Model (LLM)?
This practical question separates candidates who can build models from those who can deploy and maintain them. An LLM's performance is not a single number; it's a multi-faceted profile of capabilities, risks, and costs.
Evaluating an LLM requires a nuanced approach combining automated benchmarks with human evaluation to assess quality, tone, and safety. A strong candidate understands that the "best" model depends entirely on the specific use case.
What a Strong Answer Looks Like
A great response demonstrates a structured, multi-layered evaluation strategy.
To better understand how model inputs are crafted, see our guide on the fundamentals of prompt engineering.
7. Walk Me Through Your Experience with ML Frameworks and Tools
This question moves beyond theory to gauge a candidate's practical, hands-on experience. It’s not about listing frameworks; it’s about the why and how behind their choices.
An engineer’s fluency with frameworks like PyTorch and TensorFlow, alongside MLOps tools like MLflow or Kubeflow, is a direct indicator of their ability to build and maintain real-world AI systems.
What a Strong Answer Looks Like
A strong answer demonstrates T-shaped knowledge: deep expertise in one core framework and broad awareness of alternatives.
8. Design a System to Detect and Handle Data Drift
This is a classic MLOps question that separates theoretical knowledge from production experience. A model’s accuracy degrades when live data differs from its training data. This phenomenon, known as data drift, requires a robust system to detect and mitigate.
Answering this well requires a candidate to think about monitoring, statistical analysis, and automated workflows needed to maintain model performance over time.
Alt text: Diagram showing a data drift monitoring system, including data collection, statistical testing, alerting, and retraining triggers, a common topic in AI engineer interview questions.
What a Strong Answer Looks Like
A strong candidate will propose a comprehensive system addressing detection, alerting, and resolution.
9. Describe Your Approach to Feature Engineering for a New ML Problem
This question reveals a candidate's systematic thinking and creativity. Great AI engineers know that even the most advanced model will fail with poor features, making this a core competency.
Feature engineering is the process of transforming raw data into features that better represent the underlying problem to the predictive models. It is often the most time-consuming yet impactful step in building an ML system.
What a Strong Answer Looks Like
A strong response will outline a structured, iterative process.
10. How Do You Approach Model Selection and Hyperparameter Tuning?
This question assesses a candidate's systematic methodology and their grasp of the trade-offs between performance, complexity, and computational cost. It reveals their balance of scientific rigor and practical, business-aware decision-making.
A great response demonstrates a structured, incremental approach that starts with a simple baseline and methodically explores more complex solutions. Understanding various model selection strategies is key to ensuring the chosen model is both robust and efficient.
What a Strong Answer Looks Like
A strong candidate will outline a clear, repeatable workflow.
Checklist for Your AI Engineer Interview Process
Hiring great AI engineers requires a systematic process, not just good questions. Use this checklist to build a repeatable engine for identifying top talent.
What to Do Next
Ready to connect with world-class, pre-vetted AI talent? ThirstySprout matches high-growth companies with the top 3% of remote AI and MLOps engineers who have already built and shipped production systems. Start a pilot with your ideal candidate in 2-4 weeks.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.