
TL;DR: Your Quick Guide to High-Value AI Roles
- Highest Impact Roles: LLM Engineer, MLOps Engineer, and AI Infrastructure Engineer command the highest salaries due to their direct impact on building and scaling production AI systems.
- Key Skills: Mastery of Kubernetes, cloud infrastructure (AWS/GCP), vector databases (Pinecone, Milvus), and low-level programming (C++/CUDA) are non-negotiable for top-tier roles.
- Action for Leaders: Stop hiring generic "AI engineers." Define roles with precision (e.g., AI Product Engineer for user features vs. MLOps for infrastructure) to match your company's stage and immediate goals.
- Action for Engineers: Specialize in a high-demand niche like computer vision or reinforcement learning and build a portfolio of end-to-end, deployed projects. Your GitHub is your resume.
- Start a Pilot: The fastest way to de-risk hiring is to start a 2–4 week pilot with a pre-vetted AI engineer.
Who This Guide Is For
- CTO / Head of Engineering: You need to budget for, attract, and retain elite AI talent to build your product roadmap.
- Founder / Product Lead: You are scoping new AI features and need to understand the specific roles required to build them reliably and cost-effectively.
- Senior Engineers: You are planning your next career move and want to specialize in a high-growth, high-compensation domain.
Quick Answer: The 3 Tiers of Top-Paying AI Jobs
The most valuable engineering roles today are those that build, deploy, and scale production AI systems. We can group the top-paying jobs into three tiers based on their function within the AI lifecycle.
Tier 1: Foundation & Scale (Infrastructure Focused)
- Roles: MLOps Engineer, AI/ML Infrastructure Engineer, Data Engineer.
- Why they're top-tier: They build the reliable, scalable platforms that make all other AI work possible. They are force multipliers for the entire organization.
- Hire them when: You need to move from successful prototypes to production-grade, reliable AI services that can handle real-world traffic and data volume.
Tier 2: Model & Application (Product Focused)
- Roles: LLM Engineer, Machine Learning Engineer, AI Product Engineer.
- Why they're top-tier: They build the core AI models and user-facing features that directly create business value and competitive advantage.
- Hire them when: You have a clear product goal and need specialists to build the core intelligence, whether it's a recommendation engine or a generative AI assistant.
Tier 3: Advanced Specialization (Niche Focused)
- Roles: Computer Vision Engineer, Reinforcement Learning Engineer.
- Why they're top-tier: They possess rare, deep expertise required for transformative but specialized applications like autonomous systems or medical imaging.
- Hire them when: Your core business model relies on solving a specific, hard problem in a niche domain that requires PhD-level expertise.
- Business Acumen: They ask about the business impact of the 5% accuracy gain versus the cost of breaching the SLO.
- Technical Depth: They discuss canary deployments, A/B testing, and latency-optimized inference (e.g., using ONNX Runtime, TensorRT).
- Monitoring Focus: They mention specific metrics to watch: not just latency but also model drift and data quality.
- Mastery of Cloud-Native Tooling: Expertise in Kubernetes, Docker, and Terraform is non-negotiable.
- Observability for ML: Assess their ability to implement systems that track model-specific metrics like prediction latency and concept drift.
- Cost Optimization Focus: Ask how they would design a training pipeline to minimize GPU costs or an inference service to scale to zero.
- Indexing: Documents are chunked, converted to embeddings via an API (e.g., OpenAI), and stored in a vector database (e.g., Pinecone).
- Retrieval: A user query is embedded, and the vector DB returns the most similar document chunks.
- Generation: The query and retrieved chunks are passed as context to an LLM, which generates the final answer.
- Measure Everything: "First, I'd instrument each step: embedding latency, vector search latency, and LLM generation latency."
- Identify Bottlenecks: "The LLM generation is often the slowest. I'd check if we're using a slow model or if the context window is too large."
- Propose Solutions: "We could switch to a faster model (e.g., GPT-3.5-Turbo), use a smaller context, or stream the response tokens back to the user to improve perceived latency."
- Mastery of the LLM Stack: Test their ability to implement RAG systems using vector databases like Pinecone, Weaviate, or Milvus.
- Advanced Prompt Engineering: Ask candidates to design complex prompt strategies like chain-of-thought or few-shot learning.
- Focus on Production Realities: Ask how they would handle prompt injection, mitigate model "hallucinations," or monitor rising inference costs.
- Usage Velocity: Change in daily active sessions week-over-week.
- Feature Adoption: Boolean flags for whether a user has tried key features (e.g., "used_collaboration_tool").
- Support Interactions: Number of support tickets filed in the last 30 days.
- Billing Events: Number of failed payments in the last 90 days.
[ ]Is the user split truly random and consistent?[ ]Are the control and variant groups of sufficient size for statistical significance?[ ]Are we logging all necessary metrics correctly for both groups?[ ]Does the experiment have a clear success metric (e.g., conversion rate) and guardrail metrics (e.g., latency, error rate)?- Prioritize Feature Engineering: Ask candidates to whiteboard the features they would create for a core business problem, like predicting customer churn.
- Assess Experimental Rigor: Pose a scenario where a new model fails in an online test and ask them to diagnose potential causes like data drift.
- Look for Production-Focused Thinking: Probe their understanding of the trade-offs between complex models (neural networks) and simpler ones (gradient-boosted trees).
- Use Batch for: Model training data, daily/hourly reporting, non-time-sensitive analytics. It's cheaper and simpler.
- Use Streaming for: Real-time fraud detection, live recommendations, dynamic pricing. Use it when data freshness of seconds-to-minutes directly impacts business value.
- Batch and Streaming Mastery: Test for proficiency in both processing paradigms using tools like Apache Flink or Spark.
- Modern Lakehouse Architecture: Assess their knowledge of lakehouse formats like Apache Iceberg and how they enable ACID transactions on data lakes.
- "Data as a Product" Mindset: Evaluate their approach to data contracts, quality monitoring, and Service Level Objectives (SLOs).
- Bad UX: "I don't know."
- Good UX: "I couldn't find a direct answer for that. Would you like me to search our help docs for related topics or connect you with a human support agent?"
- Naive Approach: Send the entire document to GPT-4. (Expensive)
- Use a smaller, cheaper model (e.g., GPT-3.5-Turbo) for documents under 2,000 words.
- For longer documents, use a Map-Reduce approach: summarize smaller chunks first, then combine the summaries.
- Cache summaries for popular documents to avoid re-generating them.
- Product and UX Instincts: Ask candidates to critique an existing AI product or whiteboard how they would design a feature to handle ambiguous AI outputs.
- Focus on Measurable Impact: Ask them to describe a project where they measurably improved engagement or retention with an AI-powered feature.
- Cost-Aware Design: Ask how they would implement a feature while managing token costs, using techniques like caching or smaller, specialized models.
- Cloud Model (e.g., ResNet-50): High accuracy, but too slow and large for an embedded device.
- Edge-Optimized Model (e.g., MobileNetV3): Slightly lower accuracy, but designed to run fast with low memory.
- Optimization Techniques: An expert engineer would apply quantization (using 8-bit integers instead of 32-bit floats) and pruning (removing unnecessary model weights) using tools like TensorFlow Lite to make it even faster.
- Randomly rotate and flip images of defects.
- Adjust brightness and contrast to simulate different lighting conditions.
- Add random noise or blur to make the model more resilient to camera imperfections.
- Edge Deployment Expertise: Assess their experience with optimizing models for resource-constrained devices using frameworks like TensorFlow Lite or NVIDIA TensorRT.
- Data-Centric Mindset: Ask how they would design a data collection and annotation pipeline to handle edge cases and mitigate bias.
- Foundation in Classical Vision: A strong understanding of classical image processing is crucial for preprocessing, debugging, and hybrid approaches.
- Sparse Reward (Bad): +1 only when the task is complete. The agent may never succeed by random chance.
- +0.1 for moving the arm closer to the box.
- +0.2 for touching the box.
- +0.5 for successfully grasping the box.
- +1.0 for lifting the box.
This guides the agent toward the correct solution. - Domain Randomization: During training, randomly vary physical parameters in the simulation (e.g., friction, lighting, object mass). This forces the model to learn a policy that is robust to real-world variations.
- Strong Mathematical and Algorithmic Foundation: Candidates must be fluent in probability, optimization, and control theory. Ask them to explain the trade-offs between on-policy (SARSA) and off-policy (Q-learning) algorithms.
- Simulation and Environment Design: Assess their experience with tools like OpenAI Gym, MuJoCo, or Isaac Sim.
- Bridging the Sim-to-Real Gap: Probe their knowledge of techniques like domain randomization and system identification.
- Data Parallelism: Replicate the model on each GPU, but feed each one a different slice of the data.
- Tensor Parallelism: Split a single layer of the model (e.g., a large weight matrix) across multiple GPUs.
- Pipeline Parallelism: Place different layers of the model on different GPUs, creating a pipeline.
- Low-Level Systems Mastery: Proficiency in languages like C++ and CUDA is paramount. Ask how they would optimize a matrix multiplication kernel.
- Deep Framework Internals: Ask them to explain the journey of a model from Python to execution on a GPU in PyTorch or JAX.
- Performance and Hardware Acumen: Look for experience with profiling tools like NVIDIA's Nsight and a deep understanding of modern GPUs and TPUs.
- Standard Prompt (Bad): "What is the answer to this word problem? [problem]"
- Chain-of-Thought Prompt (Good): "Solve this word problem. Think step by step and show your work before giving the final answer. [problem]"
This simple instruction dramatically improves accuracy on complex reasoning tasks. - Create an Evaluation Dataset: A list of 50-100 challenging user queries.
- Define a Metric: For a summarization task, this could be a ROUGE score or a simple human rating (1-5 scale) for coherence and accuracy.
- Test Systematically: Run multiple prompt variations against the dataset and compare scores to find the optimal wording.
- Systematic Prompting Frameworks: Candidates should understand concepts like chain-of-thought, few-shot prompting, and retrieval-augmented generation (RAG).
- Deep Model-Specific Knowledge: Ask how they would adapt a prompt strategy when migrating between different foundational models (e.g., GPT-4 vs. Claude 3).
- Robust Evaluation and Testing: Assess their ability to create evaluation datasets and metrics to quantitatively score prompt performance.
- Data: Write a Python script to export and clean chat logs.
- Model: Fine-tune a small, open-source model (e.g., a DistilBERT variant) on the cleaned data.
- Backend: Wrap the model in a simple FastAPI endpoint.
- Frontend: Add a button to the chat UI that calls the API and displays the suggestions.
They can do all four steps, enabling rapid prototyping. - Instead of: Building a complex Kubernetes cluster.
- They use: A managed service like AWS SageMaker or a simple Docker container on a single virtual machine to get the first version deployed.
- Instead of: A large, expensive model.
- They use: A smaller, faster open-source model or a cheaper API that is "good enough" for the initial product launch.
- Portfolio Over Pedigree: Prioritize candidates with a history of shipping end-to-end AI products. Look for personal projects or startup experience.
- System Design for Pragmatism: Frame interview questions around building a feature with tight constraints on time and budget.
- Assess Product Acumen: Ask how they would measure the success of an AI feature beyond model metrics, focusing on business KPIs like user engagement.
- Define Your Needs Precisely: Stop using the generic "AI Engineer" title. Use the roles above to create a specific job description that matches your immediate business goals. Download our AI Role Definition Checklist to help.
- Rethink Your Interviews: Shift from algorithmic trivia to practical, domain-specific problems. Ask candidates to design a small system, critique an existing AI product, or debug a production scenario.
- Start a Pilot Project: The best way to vet top AI talent is to work with them. Engage a pre-vetted engineer for a 2–4 week pilot project focused on a real business problem. This de-risks the hiring decision and delivers immediate value.
- MLOps Best Practices - ThirstySprout
- What is a Machine Learning Engineer? - ThirstySprout
- Nvidia's RL for Chip Floorplanning - reruption.com
- Top AI Startups and Innovators - founderconnects.com
1. ML Systems Engineer / MLOps Engineer
ML Systems Engineers, or MLOps Engineers, build the automated infrastructure that turns experimental models into reliable, business-critical applications. They solve the "it works on my laptop" problem by architecting scalable training pipelines, automated deployments, and robust monitoring systems.
Their work is foundational to realizing the value of AI investments. This direct link to ROI makes it one of the top paying software engineering jobs.
Example 1: Interview Question to Vet MLOps Talent
A simple, effective question to identify top-tier MLOps talent is:
"Your team's new fraud detection model performs 5% better in offline tests but causes a 20ms increase in p99 latency. Your service level objective (SLO) for latency is 150ms, and you're currently at 140ms. Do you ship it? Explain your reasoning and the monitoring you'd need."
A great answer reveals:
Example 2: Sample MLOps Scorecard
Use this simple scorecard to evaluate candidates or internal projects:
Actionable Insights for Hiring
For a deeper look into structuring these systems, explore these MLOps best practices.
2. Large Language Model (LLM) Engineer / Prompt Engineer
LLM Engineers build applications on top of models like GPT-4 or Llama. They bridge the gap between a powerful foundation model and a reliable, production-ready feature by designing systems for prompt engineering and Retrieval-Augmented Generation (RAG).
Their work is critical for companies racing to integrate generative AI, making it one of the top paying software engineering jobs in the current market.
Example 1: Basic RAG Architecture Diagram
A typical RAG system for a Q&A bot involves these steps:
This architecture grounds the LLM in your private data, reducing hallucinations.
Example 2: Interview Question for LLM Engineers
"You've built a RAG-based chatbot for customer support. Users complain it's slow. Your p99 latency is 8 seconds. Walk me through your process for diagnosing and fixing this, starting with the most likely culprits."
A great answer includes a structured approach:
Actionable Insights for Hiring
3. Machine Learning Engineer (Feature Engineering & Model Development)
Machine Learning Engineers translate raw data into predictive power. They design, train, and fine-tune the models that drive core business outcomes, from personalization to fraud detection. This direct link to business value makes it one of the top paying software engineering jobs.
Example 1: Feature Engineering for Churn Prediction
For a subscription service, an ML engineer would create features to predict customer churn:
This creativity in feature design often has more impact than complex model architectures.
Example 2: A/B Test Sanity Checklist
Before launching a new recommendation model, a skilled ML engineer verifies the A/B test setup:
Actionable Insights for Hiring
To understand their full scope, explore what a Machine Learning Engineer does.
4. Data Engineer (ML-Focused / Data Pipeline Engineer)
A Data Engineer focused on machine learning builds the data pipelines that feed clean, reliable data to training algorithms and production models. This role is the bedrock of any serious ML initiative.
Their work ensures that the massive datasets required for training are high-quality, discoverable, and optimized for performance and cost. This foundational importance makes it one of the top paying software engineering jobs.
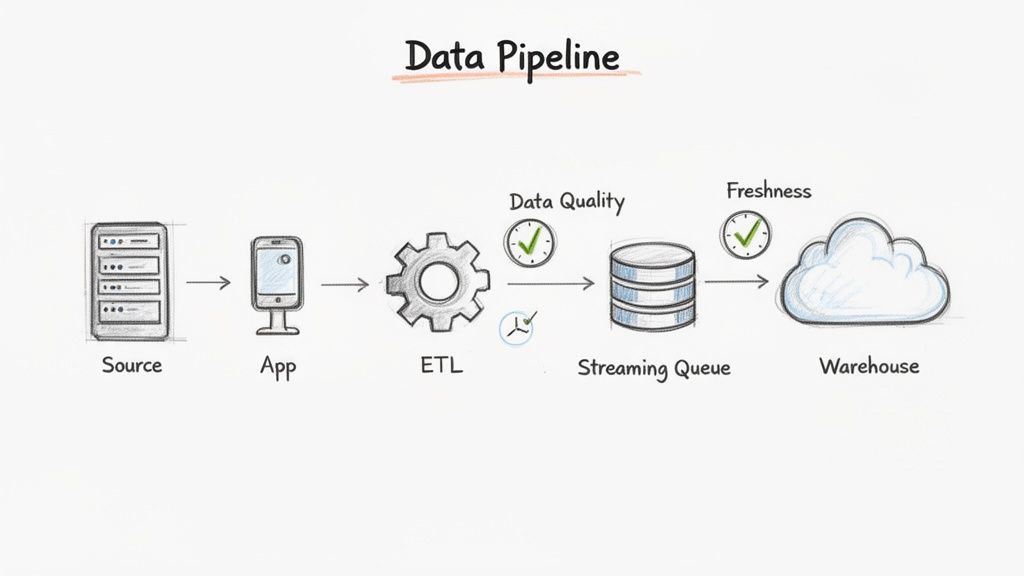
Example 1: Data Quality Check as Code
A top data engineer doesn't just move data; they validate it. Here’s a simple check using a tool like dbt:
# models/schema.ymlmodels:- name: fct_user_sessionscolumns:- name: session_idtests:- unique- not_null- name: session_duration_secondstests:- dbt_expectations.expect_column_values_to_be_between:min_value: 0max_value: 86400 # 1 dayThis simple config automatically creates tests to ensure every session_id is unique and durations are plausible.
Example 2: Batch vs. Streaming Decision Framework
When should you use batch (e.g., Spark Batch) vs. streaming (e.g., Flink)?
Actionable Insights for Hiring
5. AI Product Engineer / AI Integrations Engineer
AI Product Engineers bridge the gap between AI capabilities and tangible product features. They are experts at productizing AI, managing everything from feature flags to the user experience around AI's inherent uncertainty.
This role's high valuation comes from its direct impact on user adoption and revenue. Their expertise places them among the top paying software engineering jobs.
Example 1: Designing a Graceful AI Failure UX
A user asks an AI chatbot a question it can't answer.
An AI Product Engineer designs these fallback paths.
Example 2: Cost-Aware Feature Design
An AI Product Engineer wants to build a "summarize this document" feature.
Actionable Insights for Hiring
6. Computer Vision / AI Vision Engineer
Computer Vision Engineers teach machines to see and interpret the world. They develop the algorithms that power autonomous vehicles, medical diagnostics, and automated retail.
The combination of deep specialized knowledge and robust software engineering skills makes these professionals rare and valuable, commanding some of the top paying software engineering jobs.
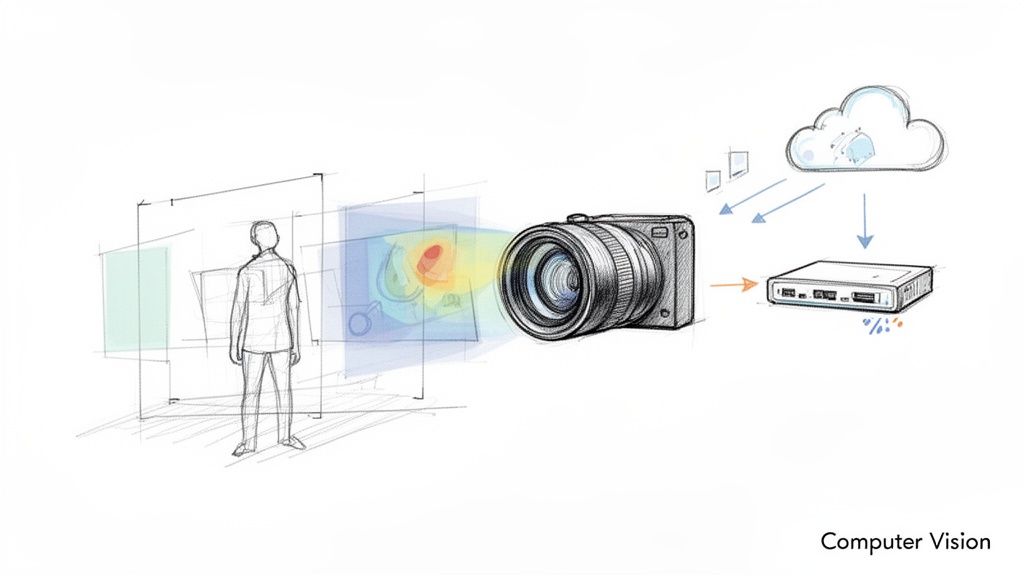
Example 1: Model Optimization for Edge Deployment
A computer vision model for a smart camera needs to run on-device.
Example 2: Data Augmentation for Robustness
To train a model that detects defects on a manufacturing line, a vision engineer would augment the training data to simulate real-world conditions:
Actionable Insights for Hiring
7. Reinforcement Learning / Multi-Agent Systems Engineer
Reinforcement Learning (RL) Engineers build agents that learn optimal behaviors through trial and error. They design simulation environments and reward functions to solve complex sequential decision-making problems.
This role’s scarcity and high specialization make it one of the top paying software engineering jobs, essential for robotics, gaming AI, and supply chain optimization. Their skills are applied to complex problems, as shown by Nvidia's Reinforcement Learning in chip floorplanning.
Example 1: Reward Function Design
To train a robot to pick up a box, the reward function is critical:
Example 2: The Sim-to-Real Gap
An RL policy trained perfectly in a simulator often fails on a real robot. Top RL engineers bridge this "sim-to-real" gap using techniques like:
Actionable Insights for Hiring
8. AI/ML Infrastructure & Research Engineer
AI/ML Infrastructure Engineers build the foundational systems that power cutting-edge AI. They operate at the intersection of low-level systems engineering and advanced AI, developing frameworks and high-performance computing clusters. This critical function makes it one of the top paying software engineering jobs.
Example 1: CUDA Kernel for Optimized Operations
A standard Python library might perform an operation slowly. An infrastructure engineer would write a custom kernel in CUDA C++ to run directly on the GPU, parallelizing the computation and achieving a 10-100x speedup for a critical part of a model's training loop.
Example 2: Distributed Training Strategy
To train a model too large for a single GPU, an infrastructure engineer would implement a distributed strategy:
Knowing when to use each strategy is a key skill.
Actionable Insights for Hiring
9. Prompt Engineer / AI UX Specialist
A Prompt Engineer architects the conversation between humans and LLMs. They systematically develop, test, and refine prompts to ensure AI models produce accurate, relevant, and safe responses.
Their work translates an AI's raw capability into a predictable and valuable user experience, making it one of the most in-demand and top paying software engineering jobs in the generative AI space.
Example 1: Chain-of-Thought Prompting
To improve an LLM's reasoning on a math problem:
Example 2: Prompt Evaluation Framework
A prompt engineer doesn't just write prompts; they test them.
Actionable Insights for Hiring
10. Full-Stack AI/ML Engineer (Generalist with Production Focus)
The Full-Stack AI/ML Engineer is a versatile generalist who handles the entire ML lifecycle, from data pipelines to front-end integration. They are the startup world's "AI swiss-army knife," capable of shipping a complete AI-powered feature single-handedly.
Their end-to-end ownership accelerates development, which is why they are among the top paying software engineering jobs, especially in early-stage companies.
Example 1: Building a Minimum Viable AI Feature
Task: Build a "smart reply" feature for a chat app.
A full-stack AI engineer would:
Example 2: Pragmatic Tool Selection
A full-stack AI engineer makes practical choices to move fast:
Actionable Insights for Hiring
What To Do Next
Finding and vetting elite AI engineers is a significant challenge. ThirstySprout specializes in connecting you with the top 3% of remote AI and MLOps talent, pre-vetted for technical excellence and practical experience.
Start a Pilot | See Sample Profiles
References
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.