
TL;DR
- Zero-Trust is Mandatory: Assume your network is already compromised. Authenticate and authorize every single request to access data, regardless of its origin.
- Encrypt Everything: Data must be encrypted at rest (in S3, Snowflake), in transit (using TLS 1.3), and, where possible, in use. This is your last line of defense.
- Automate Access Control: Use Role-Based Access Control (RBAC) and Infrastructure as Code (IaC) like Terraform to enforce the principle of least privilege. Manual permissioning at scale is a recipe for disaster.
- Monitor & Alert in Real-Time: You can't stop threats you can't see. Pipe all access and system logs into a SIEM (like Splunk or Datadog) to detect and respond to anomalies instantly.
- Hire Security-Minded Engineers: The best tools are useless without the right people. Prioritize hiring data and MLOps engineers who treat security as a core part of their job, not an afterthought.
Who This Is For
- CTO / Head of Engineering: You're responsible for the architecture and risk posture of your company's data platform and need a practical framework to implement.
- Founder / Product Lead: You're scoping new AI features and need to understand the security requirements and budget implications to avoid costly rework.
- Engineering Manager: You're building a remote data team and need to define roles, skills, and best practices for secure data handling from day one.
The 5-Pillar Big Data Security Framework
For any engineering leader, building a resilient data platform comes down to five fundamental pillars. This isn't about buying a single tool; it's a multi-layered defense that addresses the complex realities of distributed data systems. This is your immediate action plan.
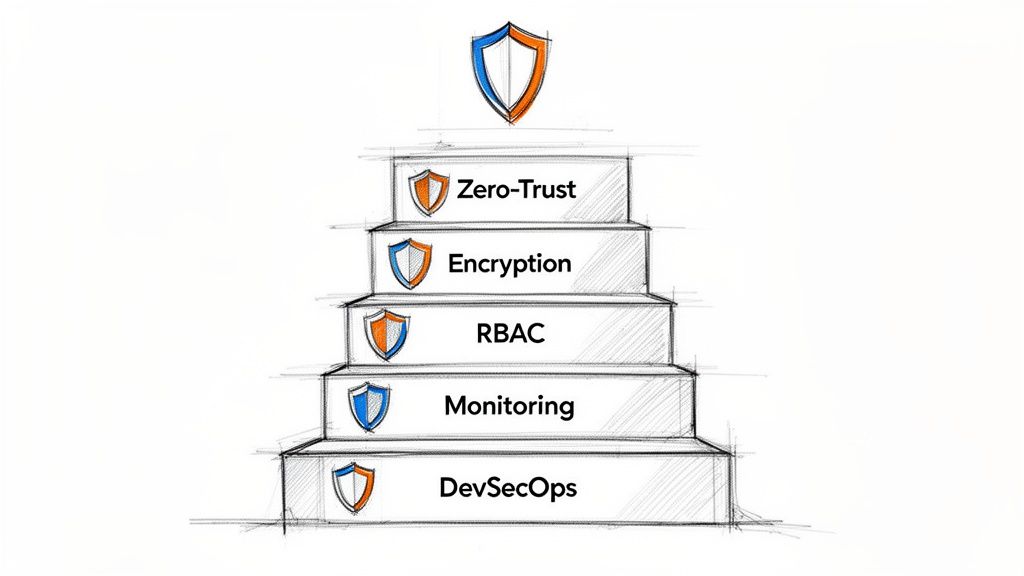
Here's the step-by-step framework for making smart, quick decisions on securing your data:
- Adopt a Zero-Trust Architecture: The mantra is simple: never trust, always verify. Every single request to access data must be aggressively authenticated and authorized. It doesn't matter if it's from inside or outside your network.
- Implement End-to-End Encryption: Your data must be locked down everywhere. That means it must be encrypted while sitting in your data lake (at rest), moving across the network (in transit), and even while being actively processed (in use).
- Establish Granular Access Control: Stick to the principle of least privilege. Use Role-Based Access Control (RBAC) to grant users and services the absolute minimum access they need. You can dive deeper into how to secure big data in our detailed guide.
- Integrate Automated Monitoring: You can't stop a threat you can't see. Setting up real-time monitoring and anomaly detection is non-negotiable for spotting suspicious activity and shutting down threats the moment they appear.
- Embed Security into CI/CD (DevSecOps): Stop treating security as an afterthought. Build security checks, vulnerability scanning, and automated policy enforcement directly into your development and deployment pipelines from day one.
Practical Examples of Big Data Security
Theory is good, but execution is better. Let's look at two practical examples of how these security pillars are implemented in real-world data architectures.
Example 1: Securing a Serverless AWS Data Lake
A common pattern for startups is a cost-effective, scalable data lake on AWS. But its flexibility can create security nightmares if not architected correctly.
First, all data enters through an API Gateway, which validates every request. Raw data lands in a dedicated Amazon S3 bucket where server-side encryption via AWS Key Management Service (KMS) is enforced. This ensures that even if the storage is compromised, the data remains unreadable.
Next, an AWS Lambda function processes new data. This function runs with a strict IAM (Identity and Access Management) role. It has just enough permission to read from the raw bucket and write to a processed bucket—nothing more.
With data processed, AWS Glue builds a data catalog. When analysts query this data using Amazon Athena, access is managed by AWS Lake Formation. This allows for column-level security. An analyst might see a customer’s state, but their name and address fields are completely masked. All API calls are logged in AWS CloudTrail, providing a complete audit trail.
Example 2: Sample Terraform for a Least-Privilege IAM Role
Infrastructure as Code (IaC) is crucial for enforcing security policies consistently. Here is a simple Terraform snippet defining an IAM role for a data processing Lambda function. It adheres to the principle of least privilege.
# IAM Role for our data processing Lambdaresource "aws_iam_role" "data_processor_lambda_role" {name = "DataProcessorLambdaRole"assume_role_policy = jsonencode({Version = "2012-10-17",Statement = [{Action = "sts:AssumeRole",Effect = "Allow",Principal = {Service = "lambda.amazonaws.com"}}]})}# IAM Policy granting specific, minimal S3 permissionsresource "aws_iam_policy" "data_processor_lambda_policy" {name = "DataProcessorLambdaPolicy"description = "Minimal S3 permissions for the data processing Lambda"policy = jsonencode({Version = "2012-10-17",Statement = [{Action = ["s3:GetObject"],Effect = "Allow",Resource = "arn:aws:s3:::my-raw-data-bucket/*"},{Action = ["s3:PutObject"],Effect = "Allow",Resource = "arn:aws:s3:::my-processed-data-bucket/*"},{Action = ["logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents"],Effect = "Allow",Resource = "arn:aws:logs:*:*:*"}]})}# Attach the policy to the roleresource "aws_iam_role_policy_attachment" "lambda_policy_attach" {role = aws_iam_role.data_processor_lambda_role.namepolicy_arn = aws_iam_policy.data_processor_lambda_policy.arn}What this shows: This configuration gives the Lambda permission only to read from the my-raw-data-bucket and write to the my-processed-data-bucket. It cannot delete objects, change bucket policies, or access any other AWS service, dramatically reducing the potential blast radius of a compromise.
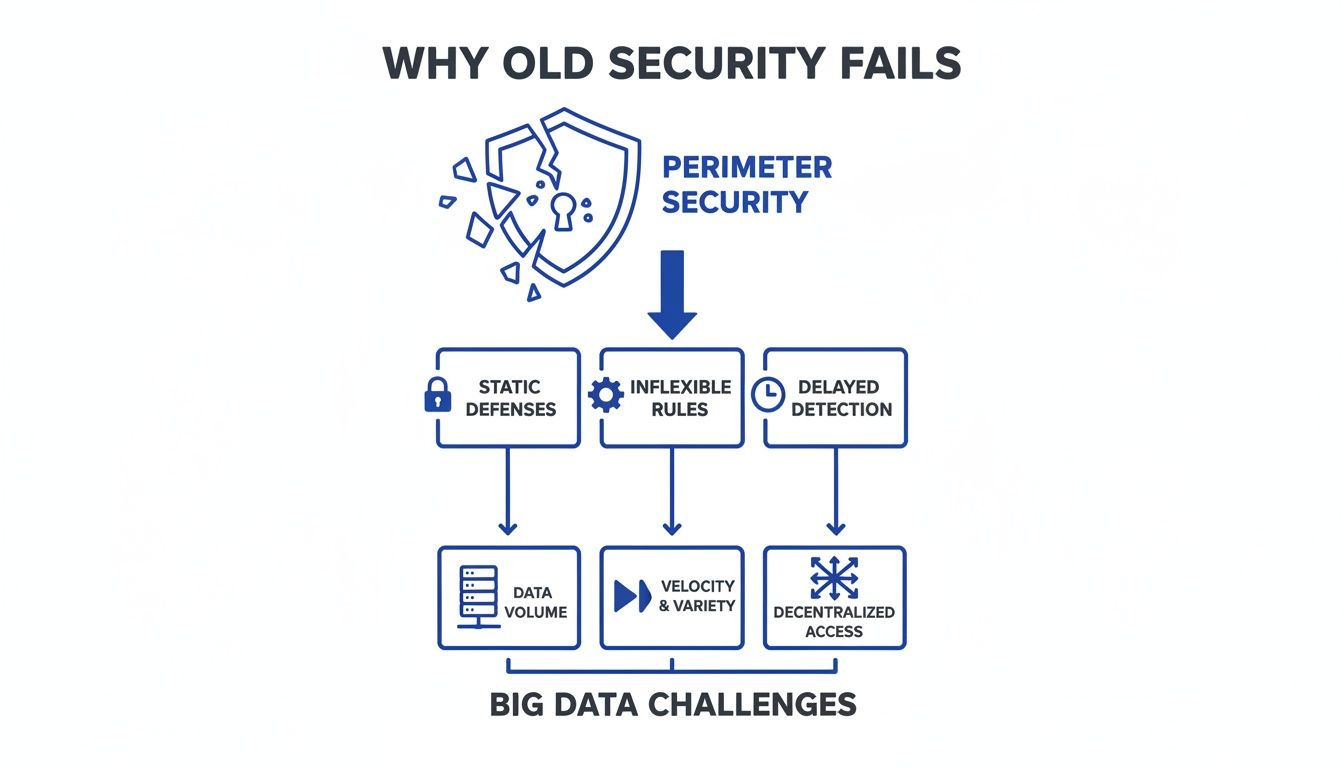
Why Traditional Security Fails with Big Data
Old-school security was like a castle with a moat. The goal was to keep bad actors out. This "perimeter security" model worked when all data lived inside a single, well-defined network.
But your data "castle" is now more like a sprawling city. It’s a distributed system—think Hadoop or Spark—with data scattered across countless servers and cloud services. The old moat-and-wall strategy falls apart.
The three V's of big data—volume, velocity, and variety—shatter traditional security models. You can't manually inspect petabytes of information streaming in every second. This creates a massive attack surface where every component is a potential weak point.
The Business Impact of Getting It Wrong
Ignoring these realities is a direct threat to your business. A single breach can trigger catastrophic financial losses and vaporize customer trust. When disposing of data, understanding the crucial concept of data sanitization is also essential to ensure information is unrecoverable.
The big data security market is projected to reach USD 87.9 billion by 2035, up from USD 26.3 billion in 2025. This growth is driven by the 181 zettabytes of data expected by 2025 and an average breach cost of $4.45 million in 2023. This is a fundamental business risk that demands a new, data-centric approach to security.
Trade-offs and Deep Dive into Security Pillars
A secure big data strategy isn't a one-size-fits-all solution. Each of the five pillars involves trade-offs between security, cost, and performance.
1. Secure Architecture and Data Lifecycle
Trade-off: Strong network isolation vs. ease of access.Running compute clusters like Spark in isolated network environments with strict firewall rules enhances security but can complicate access for developers and analysts. The alternative—flatter networks—is simpler to manage but riskier.Our take: Start with strict isolation. It's easier to relax rules for specific use cases than to lock down a permissive environment later.
2. Identity and Access Management at Scale
Trade-off: Granularity vs. complexity.Highly granular, attribute-based access control offers the best security but can become complex to manage. Simpler role-based models are easier to implement but may grant overly broad permissions.Our take: Use Role-Based Access Control (RBAC) as your baseline. For highly sensitive data, layer on attribute-based controls (e.g., access based on user location or time of day).
- Data Analyst Role:
read-onlyaccess to curated datasets in a warehouse like Snowflake. - ML Training Service Role:
readaccess to a specific S3 bucket with training data andwriteaccess to a model registry.
3. Data Protection and Encryption
Trade-off: Performance overhead vs. data protection.Encrypting data, especially in transit, adds a small performance overhead due to CPU usage for cryptographic operations. For ultra-low-latency applications, this can be a factor.Our take: The performance impact of modern encryption (like AES-256) on modern hardware is negligible for most use cases. Always encrypt. Use managed services like AWS Key Management Service (KMS) to handle key management securely.
4. Threat Detection and Monitoring
Trade-off: Alert fatigue vs. missed threats.Setting up a Security Information and Event Management (SIEM) system like Splunk or Datadog is critical. However, overly sensitive alerts can lead to "alert fatigue," where your team starts ignoring them.Our take: Focus on high-fidelity alerts for clear indicators of compromise, such as:
- A user account accessing terabytes of data from an unusual location.
- A service account trying to access data it has never touched before.
- A flood of failed login attempts on a critical database.
5. Governance and Compliance
Trade-off: Rigidity vs. developer velocity.Automating security policies with Infrastructure as Code (IaC) tools like Terraform ensures consistency but can slow down developers who want to experiment.Our take: Provide sandboxed development environments with looser controls, but enforce strict, automated security policies for all staging and production environments through your CI/CD pipeline. Also, implement immutable backup solutions for ransomware defense as a non-negotiable governance control.
Your Big Data Security Checklist
Use this checklist to audit your current platform or guide a new implementation. This asset helps ensure you cover all critical security domains.
Foundational Security (Do these first)
- Implement a Zero-Trust architecture (verify every request).
- Enforce MFA (Multi-Factor Authentication) for all user access.
- Block all public access to data storage buckets (e.g., S3) at the account level.
- Centralize identity management with an IdP (e.g., Okta).
Data Protection
- Encrypt all data at rest (AES-256) using a managed service (e.g., AWS KMS).
- Enforce TLS 1.2+ for all data in transit.
- Implement data masking or tokenization for all PII in non-production environments.
- Establish a data classification policy (e.g., Public, Internal, Confidential, Restricted).
Access Control
- Define and implement Role-Based Access Control (RBAC) policies.
- Enforce the principle of least privilege for all user and service accounts.
- Regularly review and audit all IAM roles and permissions.
- Use a secrets management solution (e.g., HashiCorp Vault)—no hardcoded credentials.
Monitoring & Response
- Enable and centralize access logs for all data stores and services.
- Configure automated alerts for high-risk anomalies (e.g., unusual data access patterns).
- Have a documented incident response plan.
- Perform regular security audits and penetration tests.
DevSecOps & Governance
- Manage all security configurations as code (e.g., Terraform).
- Integrate static analysis security testing (SAST) into your CI/CD pipeline.
- Scan all container images for known vulnerabilities before deployment.
- Maintain immutable backups for critical data stores.
How to Choose Your Big Data Security Stack
Picking your security stack is a classic build-vs-buy dilemma. The right tools should integrate smoothly with your environment—whether it's Databricks, Snowflake, or a custom setup.
Big Data Security Tool Evaluation Matrix
Use this matrix to score potential tools across the dimensions that actually matter. Rate each option on a scale of 1 to 5.
An open-source tool like Apache Ranger might seem "free," but if it requires two full-time engineers to maintain, it could be more expensive than a managed service like Immuta. Remember, your security tools are part of a larger ecosystem. The best data pipeline tools can also reduce the security burden on other parts of your stack.
Building Your Big Data Security Team
Technology enforces rules, but skilled engineers design, build, and maintain the secure ecosystem. Assembling a team with genuine security expertise is the most important investment you can make.
Core Roles for Your Data Security Squad
- Data Engineers with Security Expertise: They build secure pipelines using data masking, encryption, and fine-grained access controls in warehouses like Snowflake or Google BigQuery.
- MLOps Engineers Focused on DevSecOps: They automate security into the CI/CD process using secrets management tools like Vault, container security, and IaC tools like Terraform.
- Dedicated Cloud Security Engineers: They are masters of your cloud provider’s (AWS, GCP) security tools, including IAM policies, network segmentation, and threat monitoring.
Our guide on information security recruitment offers a deeper look into sourcing this specialized talent. According to recent trends in big data security, stolen credentials are a factor in 51% of big data incidents, highlighting the need for security-first engineers from day one.
What to Do Next
- Run an Audit: Use the checklist above to conduct a 1-week audit of your current data platform against these security principles. Identify your top 3 biggest gaps.
- Prioritize Your Roadmap: Translate your findings into your next engineering sprint. Focus on high-impact, low-effort fixes first, like enforcing MFA or blocking public S3 access.
- Scope a Pilot Project: If you lack the in-house expertise, don't wait. A data breach costs far more than proactive investment.
Ready to build a secure, high-performing AI team without the operational overhead? ThirstySprout connects you with the world's top remote AI and data engineers who have proven experience shipping secure, production-grade systems.
References
- IBM Cost of a Data Breach Report 2023
- Technavio Big Data Security Market Analysis
- HashiCorp Vault Documentation
- AWS Well-Architected Framework - Security Pillar
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.