
Your team already has models in production. They predict churn, rank leads, flag fraud, or forecast demand. The problem is simpler and more painful than most AI blog posts admit. The model gives an answer, but your business still doesn't know how much to trust it.
That's where probabilistic programming becomes worth a serious look. Not because it's academically elegant. Because some decisions are expensive when confidence is hidden.
If you're a CTO, founder, or product lead deciding whether to fund this capability, focus on two questions. Can it help you make better decisions under uncertainty? And can your team ship and operate it without turning research code into a permanent science project?
What Is Probabilistic Programming and Why Should You Care
TL;DR for technical leaders
- Use probabilistic programming when uncertainty is part of the product decision. If your team needs to reason about risk, confidence, and tradeoffs, this approach is often more useful than a point prediction alone.
- Don't treat it as a replacement for your ML stack. It's a strong fit for selected problems, especially where explanation and structured uncertainty matter.
- Your real decision is organizational, not theoretical. Success depends less on model novelty and more on whether you have engineers who can operationalize inference, monitoring, and debugging.
A practical example. Your pricing model recommends a change, but sales wants to know how confident the system is. Your demand forecast shifts after a supply disruption, and finance needs a range, not one number. Your experimentation platform says variant B wins, but product asks whether the improvement is meaningful enough to ship.
That's the business case. Probabilistic programming lets teams model uncertainty directly instead of bolting confidence estimates onto a system after the fact.
The field was formally established as distinct in 2009, when statistical inference became a built-in, first-class operation in programming languages. By 2016, universal probabilistic programming languages such as Pyro could represent any computable probability distribution, moving the discipline from manual model specification toward automated statistical modeling with built-in inference such as Markov Chain Monte Carlo, according to Carnegie Mellon lecture notes on probabilistic programming.
Bottom line: If a wrong decision is costly and uncertainty is central to the workflow, probabilistic programming deserves evaluation. If you just need a fast classifier, it probably doesn't.
This matters most for leaders who are tired of black-box outputs and want systems that support judgment, not just automation.
Core Concepts Explained for Technical Leaders
Probabilistic programming sounds more exotic than it is. Strip away the notation and you get a disciplined way to answer one business question: what's the most plausible explanation for the data we're seeing, and how uncertain are we about it?
Think in stories, not equations
A probabilistic model is a story about how your data gets produced.
For a subscription business, that story might include traffic quality, pricing, seasonality, campaign mix, and user intent. Instead of saying “conversion rate is 4.2,” the model says “conversion is shaped by several uncertain factors, and here's the range of outcomes that fit what we know.”
A prior is an explicit version of what your business already believes. Maybe you know enterprise buyers convert more slowly. Maybe you know seasonality affects renewal behavior. In probabilistic programming, you don't leave that knowledge in a slide deck. You encode it.
A likelihood is how well your story matches observed data.
Inference is the update step. It works backward from outcomes to the most likely causes. The model starts with assumptions, sees new evidence, and revises its beliefs.
If your stakeholders get lost in AI jargon, a plain-language reference like AI terminology for founders helps align product, engineering, and leadership before architecture debates start.
What changed in practice
The important architectural shift is that random variables and distributions became first-class parts of the programming language. That let engineers express uncertainty directly inside code, rather than treating statistics as a disconnected toolchain.
For leaders, the key implication isn't academic elegance. It's a multiplier. Your team can define a model and let the system handle much of the inference machinery.
That's why these systems are useful in areas such as simulation, forecasting, and decision support. If you want a concrete business-friendly example, this overview of Monte Carlo simulation in finance shows the kind of reasoning probabilistic systems support well.
Framework choice is really a hiring choice
Here's the practical view of the ecosystem.
| Framework | Best fit | Hiring implication |
|---|---|---|
| Pyro | Teams already working in PyTorch and modern Python ML workflows | Easier fit if your ML engineers already live in Python |
| Stan | Teams that value mature Bayesian modeling workflows and disciplined model specification | Strong fit for statisticians and research-heavy modeling teams |
| Turing.jl | Teams comfortable with Julia and interested in performance-oriented technical stacks | Harder hiring market unless you already use Julia |
Don't start by asking which framework is most powerful. Ask which one your team can debug at 2 a.m., extend in six months, and staff without rebuilding your org chart.
A solid probabilistic programming hire doesn't just know priors and posteriors. They know how those choices affect latency, tests, and business decisions.
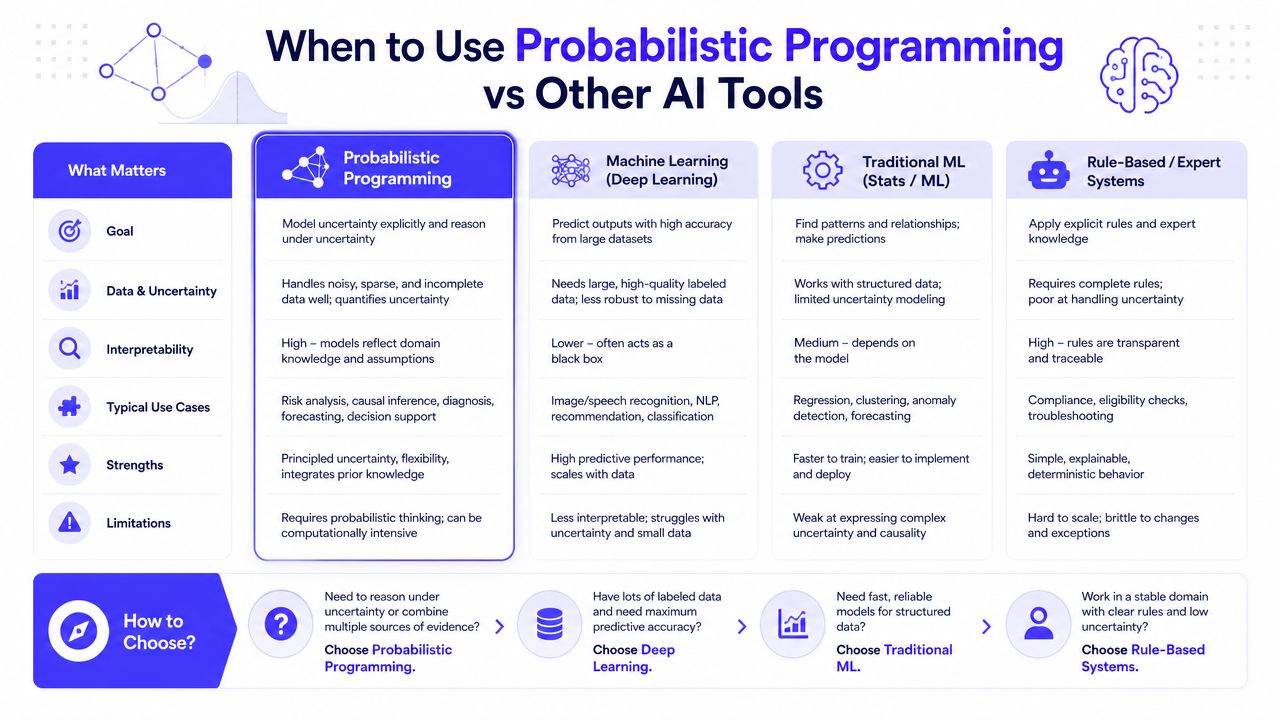
When to Use Probabilistic Programming vs Other AI Tools
The easiest way to waste time with probabilistic programming is to use it where a simpler tool already wins. The right way to evaluate it is against alternatives your team could deploy this quarter.
The short decision rule
Use probabilistic programming when you need to model structured uncertainty and make decisions from it.
Don't use it when the core job is perception, retrieval, or generic prediction and uncertainty is secondary.
A useful market reality check comes from WorldQuant's discussion of probabilistic programming in modern AI. Their framing is the right one for CTOs: the trend isn't replacing foundation models, but building hybrid systems where probabilistic layers handle calibration, causal reasoning, and decision support while neural components handle perception or text generation.
A practical comparison
| Problem type | Best default tool | Why |
|---|---|---|
| Fraud or credit decisions with confidence requirements | Probabilistic programming | You need calibrated uncertainty and explanation, not just a score |
| Image classification or speech recognition | Deep learning | Perception tasks reward scale and representation learning |
| Support chatbot or internal knowledge assistant | LLM stack | Language generation and retrieval matter more than explicit uncertainty modeling |
| Eligibility or policy enforcement | Rule-based system | Clear deterministic logic often beats statistical complexity |
| Demand forecasting with many interacting uncertainties | Probabilistic programming or hybrid stack | Ranges and scenario analysis matter as much as prediction |
| Lead scoring from stable historical data | Traditional ML | Simpler models are often easier to train, deploy, and maintain |
When it's a strong fit
Probabilistic programming earns its keep when the answer needs context.
Consider dynamic pricing. A point forecast may tell you expected demand. A probabilistic model can help you reason about plausible demand ranges, uncertainty by segment, and how much risk sits behind a pricing move.
Consider marketing spend and experimentation. If your team needs to reason about uncertain effects, prior beliefs, and decision thresholds, Bayesian approaches are often a better fit than one-off significance tests. For readers making that shift, this primer on how to compare Bayesian and Frequentist testing is a useful way to frame the tradeoff with your product and data teams.
Consider supply chain forecasting. If stockouts, supplier delays, and demand volatility all matter at once, structured uncertainty is the problem. That's where probabilistic programming is more than a research curiosity.
Later in this section, it helps to see the framing in spoken form.
When to avoid it
Be blunt here. Don't choose probabilistic programming if your team mainly needs:
- Fast perception systems such as image moderation or ASR
- Simple ranking problems where gradient boosting already performs well
- Low-latency features where every millisecond matters and uncertainty won't change the user decision
- LLM product workflows where the bottleneck is prompt design, retrieval quality, or workflow orchestration
If your stakeholders won't act differently based on uncertainty, don't pay the implementation tax for modeling it.
The best adoption path for most companies is hybrid. Let your neural or classical ML models do pattern recognition. Add probabilistic components where decision quality improves because confidence is explicit.
Example Architecture for a Smarter A/B Testing Platform
A/B testing is one of the cleanest places to justify probabilistic programming because the business question is already probabilistic. Not “is there a winner by a fixed threshold,” but “how likely is variant B to be better, and is that difference large enough to matter?”
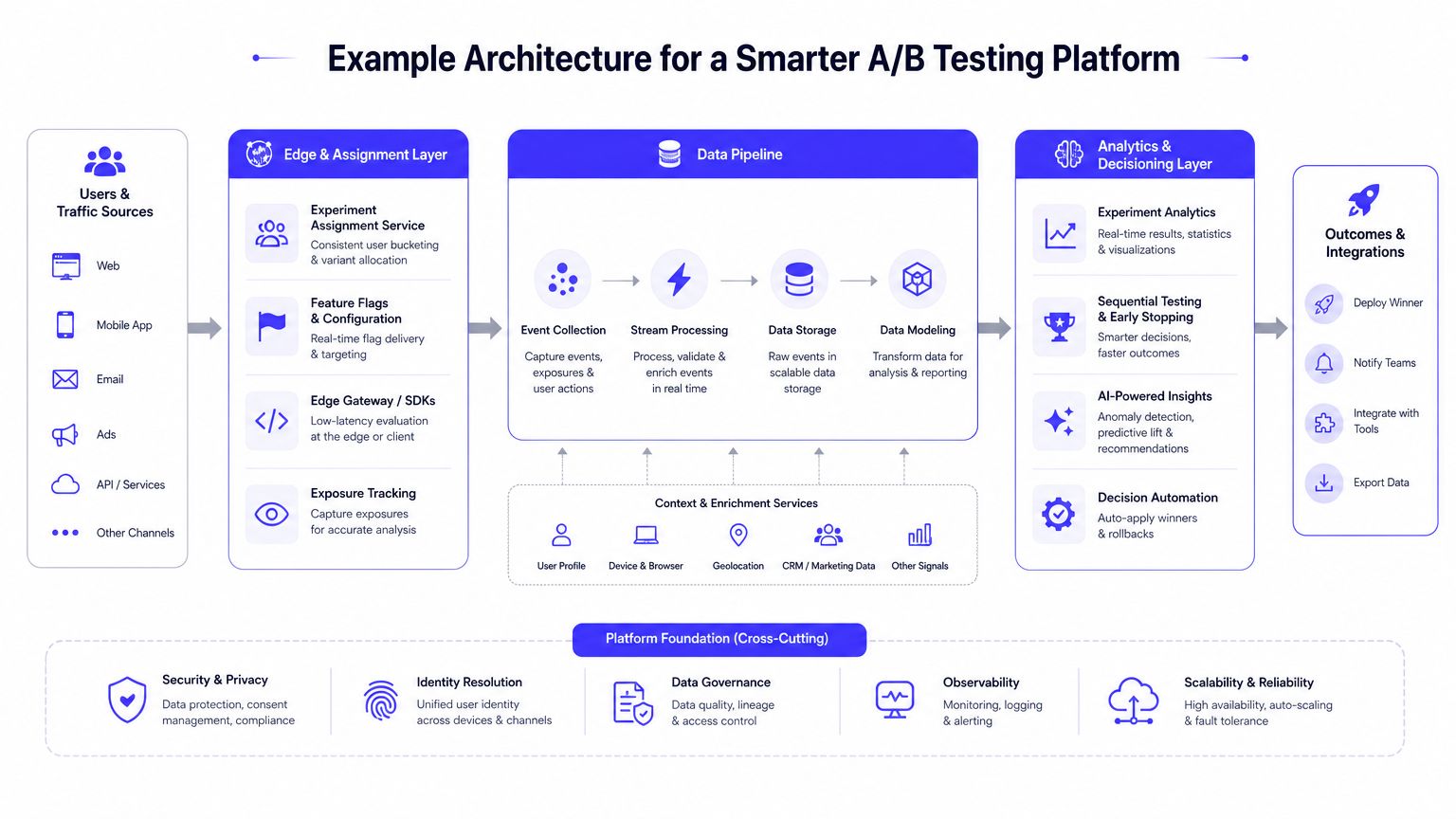
What the production flow looks like
A practical setup looks like this:
- Event collection sends user exposures, clicks, conversions, and segment attributes into your analytics stream.
- Feature and aggregation jobs prepare experiment-level summaries on a regular cadence.
- Inference service runs a Bayesian model over conversion or revenue outcomes.
- Decision API exposes business-friendly outputs, such as probability that B beats A or probability the uplift clears an internal threshold.
- Experiment dashboard shows product managers ranges and confidence, not just a binary winner label.
This architecture changes the conversation in product reviews. Teams stop asking whether they “hit significance” and start asking whether the expected upside justifies rollout risk.
Why this beats a thin statistics layer
The main benefit isn't that the math is newer. It's that the output matches the decision.
A PM can ask, “What's the probability this change is better for high-intent users?” A growth lead can ask, “Should we keep running this test, or do we already know enough?” Those are decision questions. Classical workflows often force teams to translate from a statistical artifact into a product action.
Practical rule: If your experimentation platform needs to support early stopping, segment-level uncertainty, or expected business impact, probabilistic modeling is often a better foundation than a one-size-fits-all t-test workflow.
A representative model snippet
Below is a simple sketch in Python-like pseudocode using a Pyro-style structure. It's illustrative, not a drop-in production file.
import pyroimport pyro.distributions as distdef ab_model(conversions_a, trials_a, conversions_b, trials_b):rate_a = pyro.sample("rate_a", dist.Beta(1.0, 1.0))rate_b = pyro.sample("rate_b", dist.Beta(1.0, 1.0))pyro.sample("obs_a", dist.Binomial(total_count=trials_a, probs=rate_a), obs=conversions_a)pyro.sample("obs_b", dist.Binomial(total_count=trials_b, probs=rate_b), obs=conversions_b)What matters isn't the syntax. It's the operating model around it. The service should return outputs your business can use directly:
- Probability B beats A
- Probability uplift clears your internal launch bar
- Credible range for expected conversion impact
- Segment breakdowns where uncertainty is still too high
That's a platform feature, not a stats exercise.
From Prototype to Production MLOps and Scaling Challenges
Most probabilistic programming content stops at model definition. That's the easy part. The hard part starts when someone asks for a service-level objective, monitoring plan, rollback path, and on-call ownership.
The main bottleneck is often not model expressiveness but inference efficiency and debugging. The DARPA view is useful here: literature on paradoxes of probabilistic programming shows that natural-looking models can behave in counterintuitive ways, making correctness and interpretability harder than tutorials imply. It also highlights the hiring need, which is engineers who can turn a prototype into a low-latency, testable service, as described in DARPA's probabilistic programming for advancing machine learning program overview.
What breaks after the demo
Here's what usually goes wrong in production:
- Inference gets too slow. The model that felt acceptable in a notebook becomes painful in an API path.
- Monitoring is underspecified. Teams track a single prediction metric even though the system emits distributions.
- Debugging is foreign to the org. Product bugs, data bugs, and inference pathologies look similar at first.
- Ownership is muddy. Data science writes the model, platform owns deployment, and nobody owns posterior quality.
This is why standard MLOps advice isn't enough on its own. Day 2 operations for AI systems become even more critical when your outputs are uncertain by design. For a strong operational framing, this piece on addressing Day 2 AI operations maps closely to the kind of failure modes leaders should expect.
A production pattern that actually works
Use a staged deployment path.
| Stage | What to optimize | CTO checkpoint |
|---|---|---|
| Prototype | Model validity and business relevance | Does uncertainty change a real decision? |
| Pilot service | Inference speed and API shape | Can downstream systems consume the outputs? |
| Operational rollout | Monitoring, testing, and incident ownership | Do we know when the model is wrong or unstable? |
For many teams, that means making deliberate tradeoffs between inference methods. If precision is the priority, methods such as Markov Chain Monte Carlo can be attractive. If latency is tighter, approximate approaches may be more practical. The right answer depends on product constraints, not ideology.
What to monitor
A probabilistic service needs a different checklist than a standard classifier.
- Track posterior drift, not just feature drift.
- Validate convergence signals in scheduled jobs and block promotion when they fail.
- Test priors explicitly so business assumptions don't change unnoticed.
- Log decision-facing summaries such as probability thresholds and confidence intervals, not just raw model artifacts.
A mature team will also run the same kind of deployment discipline used elsewhere in ML. Versioned data contracts, reproducible builds, canary releases, and rollback paths still matter. This guide to MLOps best practices is a helpful baseline, but probabilistic systems need one more layer of rigor around inference diagnostics and uncertainty monitoring.
Natural-looking probabilistic models can still fail in unnatural ways. If your team can't explain a weird posterior, they aren't ready to expose it to customers.
Hiring Framework for Your Probabilistic Programming Team
Don't hire a “probabilistic programming expert” as a vanity title. Hire for the work that has to get done.
Organizations often need a blend of modeling depth and production discipline. The mistake is loading up on academic fluency and underinvesting in software engineering.
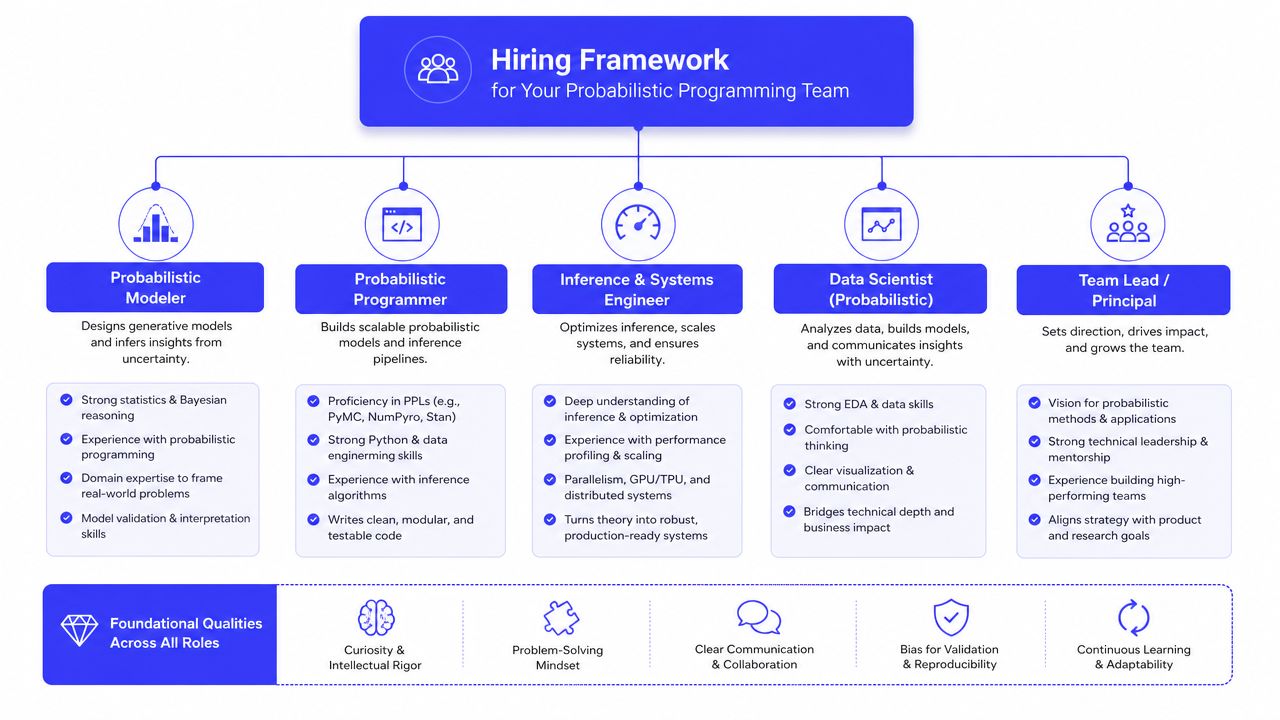
The three roles that matter most
The modeler translates business assumptions into priors, likelihoods, and decision outputs. This person needs Bayesian judgment and enough product sense to avoid elegant but useless models.
The machine learning engineer turns prototypes into maintainable services. They should understand API design, testing, batching, latency tradeoffs, and the cost of inference choices.
The MLOps or platform engineer owns deployment, observability, and lifecycle management. In smaller companies, this may be the same person as the ML engineer.
If you're already building your core AI team, this guide on how to hire machine learning engineers is a practical starting point for defining the production side of the role.
A simple scorecard
| Skill area | What good looks like | Red flag |
|---|---|---|
| Bayesian reasoning | Can explain priors as business assumptions and defend modeling choices | Talks in jargon, can't connect model design to decisions |
| PPL experience | Has built models in tools such as Pyro or Stan and can discuss tradeoffs | Knows syntax but not failure modes |
| Inference strategy | Can explain when exactness matters and when approximation is acceptable | Treats one inference method as universally right |
| Production engineering | Designs testable services, monitors outputs, and handles rollback | Only shows notebook work |
| Debugging | Has concrete examples of surprising model behavior and resolution steps | Blames data quality for every issue |
Interview questions that expose real capability
Ask questions that force candidates to bridge theory and operations.
- A debugging prompt: “Describe a time a probabilistic model produced a surprising result. How did you isolate whether the issue was data, model structure, or inference?”
- A product tradeoff question: “How would you choose between a slower, higher-fidelity inference path and a faster approximation for a user-facing feature?”
- A systems question: “What would you monitor in a probabilistic API beyond uptime and latency?”
- A collaboration question: “How would you explain a prior to a product manager who thinks it sounds subjective?”
The best candidates answer in terms of failure handling, business decisions, and maintainability. The weaker ones retreat into math.
Your 5-Step Adoption Checklist and Next Steps
Use this checklist before you approve a pilot.
- Pick a decision, not a technology. Start with a business problem where uncertainty changes the action.
- Define the decision output. Specify what stakeholders need to see, such as a probability, range, or threshold-based recommendation.
- Choose the narrowest useful pilot. A/B testing, forecasting, or risk scoring are usually better starts than a company-wide platform bet.
- Pressure-test your operating model. Decide who owns inference performance, monitoring, and production incidents.
- Assess hiring gaps early. If nobody on the team can debug posterior behavior or productionize the service, don't pretend that gap will solve itself.
My recommendation is simple. Invest in probabilistic programming when uncertainty is core to the product or decision process. Skip it when you mainly need speed, pattern recognition, or commodity prediction. Most companies should start with one hybrid use case and one accountable owner.
Next steps:
- Score one candidate use case from your roadmap using the checklist above.
- Review the A/B testing architecture with your engineering lead and ask whether the outputs would change how your team ships.
- Decide whether to hire, upskill, or bring in outside help before the pilot starts.
If you want to move fast without building this capability from scratch, ThirstySprout can help you find senior AI and ML engineers who've shipped production systems, handled MLOps realities, and can lead a focused probabilistic programming pilot. Start a Pilot, or see sample profiles to evaluate the skill mix before you commit.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.