
TL;DR: Your Quick Guide to the Naive Bayes Algorithm
- What it is: A fast, simple probabilistic classifier used for tasks like spam filtering and text categorization.
- Why you should care: It’s excellent for creating a quick, low-cost baseline model to test an idea. For engineering leaders, this means faster time-to-value and lower initial cloud spend.
- When to use it: For text classification (spam, sentiment), real-time predictions, and any project with limited data or compute resources.
- Key limitation: Its "naive" assumption that all features are independent can limit its accuracy on complex problems where feature interactions are critical.
- Recommended Action: Use Naive Bayes as your first model for text classification pilots. If you prove business value but need higher accuracy, then invest in more complex models like BERT or XGBoost.
Who This Guide Is For
- CTOs / Heads of Engineering: Deciding which algorithm to use for a new classification feature or a proof-of-concept. You need a fast, low-risk way to get a baseline.
- Founders / Product Leads: Scoping an AI feature and need to understand the trade-offs between speed, cost, and accuracy to build a realistic roadmap.
- Hiring Managers / Talent Ops: You need to vet machine learning engineers and understand what practical skills to look for beyond just knowing the theory.
This guide is for operators who need to make a decision and start building within days, not months.
A Quick Framework: When to Use the Naive Bayes Algorithm
Use this simple decision tree to determine if Naive Bayes is the right starting point for your project.
- Yes: Proceed to step 2.
- No (e.g., predicting a number like revenue): Naive Bayes is not the right tool. Consider Linear Regression or a tree-based model.
- Yes: Naive Bayes is a strong candidate, especially for setting a baseline. Proceed to step 3.
- No (e.g., image recognition, complex tabular data with many interacting features): You’ll likely get better results from a different model like a CNN for images or XGBoost for tabular data.
- Yes: Use Naive Bayes. It provides a fast, cheap, and surprisingly effective baseline.
- No (e.g., accuracy is paramount, and you have significant time/budget): Use Naive Bayes to set a benchmark, but plan to move to a more powerful model like BERT for text or LightGBM for structured data.
- Data Ingestion: User-submitted messages flow into a processing queue. A separate pipeline collects user-reported "spam" and "not spam" examples for retraining.
- Preprocessing: A worker cleans the text (lowercase, removes punctuation) and uses TF-IDF (Term Frequency-Inverse Document Frequency) to convert words into numerical feature vectors.
- Classification: The pre-trained Multinomial Naive Bayes model receives the vector and calculates the probability of the message being "spam."
- Action & Monitoring: If the probability exceeds a set threshold, the message is quarantined. The key metric to monitor is precision—you must minimize false positives to avoid blocking legitimate messages.
- Time-to-Value: A pilot spam filter can be built and deployed in 3–5 days.
- Cost: The model is lightweight and runs on a single CPU, keeping infrastructure costs low.
- Risk: The primary risk is blocking legitimate user messages (false positives), so precision must be tuned carefully.
- Model Choice: They should justify using Multinomial or Bernoulli Naive Bayes, explaining that ticket classification is a text problem.
- Feature Engineering: They mention creating a vocabulary of "urgent" words (e.g., "down," "outage," "cannot log in") and converting tickets into numerical vectors.
- Trade-offs: A strong candidate will immediately flag the "naive" assumption as a risk. They'll state that while fast, the model might miss nuanced urgency cues where words are only urgent in combination.
- Business Impact: The best answers connect to business outcomes. They'll talk about the cost of a false negative (missing an urgent ticket) and suggest monitoring recall to ensure critical issues are caught. They might also propose Naive Bayes as a fast V1, with a plan to upgrade to a more complex model like BERT if the business case is proven.
- Prior Probability: How likely is an outcome initially? (e.g., What percentage of all support tickets are 'Urgent'?)
- Likelihood: If the outcome happened, how often would we see this evidence? (e.g., If a ticket is 'Urgent,' what's the chance it contains the word "outage"?)
- Evidence: How common is the evidence on its own? (e.g., What percentage of all tickets contain "outage"?)
- Data type: Continuous values like temperature, height, or financial transaction amounts.
- Use case: Customer churn prediction based on features like 'average monthly bill' or 'total data usage.'
- Data type: Discrete counts, like how many times a word appears in a document.
- Use case: Topic modeling for support tickets, where features are the frequency of each word. This is a core tool in natural language processing.
- Data type: Binary flags (e.g., 'does this email contain the word "lottery"?').
- Use case: Spam filtering or sentiment analysis where the mere presence of a word (e.g., "crashed") is the signal, not its frequency. This often requires good feature engineering.
- Confirm your problem is a classification task.
- Validate that speed and low cost are key drivers.
- Gather and label a sample dataset (at least 1,000 examples per class is a good start).
- Choose the right Naive Bayes variant (Gaussian, Multinomial, or Bernoulli) based on your feature type.
- Set up a Python environment with
scikit-learn. - Write a script for data preprocessing (e.g., text cleaning, tokenization).
- Implement feature extraction (e.g., TF-IDF for Multinomial, binary flags for Bernoulli).
- Train the model on your dataset.
- Implement Laplace smoothing (
alphahyperparameter) to handle words not seen in training. - Evaluate the model using a held-out test set.
- Focus on the right metric: precision for spam filtering (avoid false positives), recall for urgent ticket routing (avoid false negatives).
- Wrap the trained model in a simple API (e.g., using Flask or FastAPI).
- Deploy the API to a staging environment.
- Document the model's limitations, especially the "naive" assumption.
- Speed: Trains 10–100x faster than complex models on many text tasks.
- Efficiency: Has a tiny memory footprint, making it ideal for resource-constrained environments or edge devices.
- Good with Small Data: It can perform surprisingly well even with a limited training dataset.
- The "Naive" Assumption: Its biggest weakness. If your features are highly correlated (e.g., in fraud detection, 'large purchase amount' and 'new shipping address' are related), its accuracy will suffer.
- Poorly Calibrated Probabilities: Never trust the raw probability scores. They are useful for ranking classes (e.g., 'spam' is more likely than 'not spam') but are not accurate confidence levels due to the independence assumption.
- For Correlated Features: Use Gradient Boosting models like XGBoost or LightGBM. They are designed to find complex interactions between features, making them ideal for fraud detection or churn prediction on tabular data.
- For Complex Text/Image Data: For nuanced text understanding, a Transformer model like BERT will outperform Naive Bayes. For images, use a Convolutional Neural Network (CNN).
- When You Need Reliable Probabilities: In finance or medicine, where the confidence score is critical, Logistic Regression is a better choice as it produces well-calibrated probabilities.
- Identify a Pilot Project: Find a simple classification problem in your business, like routing support tickets or analyzing customer feedback for sentiment.
- Scope a 5-Day Sprint: Use the checklist above to plan a rapid pilot. The goal is to get a working baseline model, not perfection.
- Hire the Right Talent: You need an engineer who understands these practical trade-offs. To find them, check our guide on how to hire top machine learning engineers or let us connect you with our pre-vetted network.
- Naive Bayes classifier - Wikipedia. (2024). Wikipedia. Link
- Naive Bayes algorithm origins, real-world applications and case studies. (2022). DEV Community. Link
- Naive Bayes background information. (2023). IBM. Link
- ThirstySprout. What is Feature Engineering in Machine Learning? Link
- ThirstySprout. What is Natural Language Processing? Link
- ThirstySprout. How to Hire Top Machine Learning Engineers. Link
What Is the Naive Bayes Algorithm?
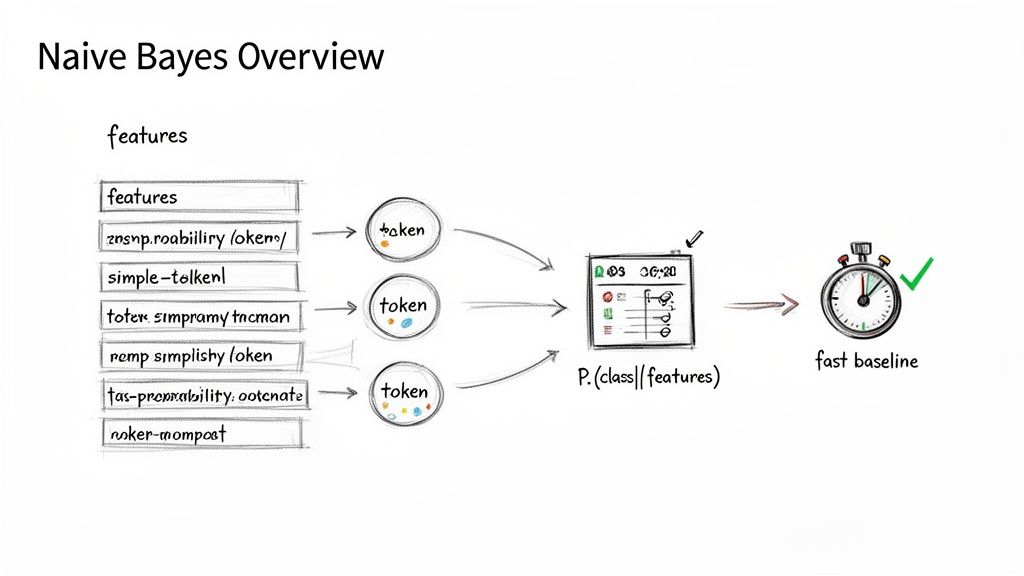
Alt text: A diagram illustrates the Naive Bayes algorithm workflow, from input features and tokenization to calculating class probability for a fast baseline.
The Naive Bayes algorithm is a probabilistic classifier built on Bayes' Theorem. It calculates the probability that a piece of data belongs to a specific category based on its features. For a product lead, that means you can stand up a model to sort information with solid results, and do it quickly.
The algorithm gets its name from its "naive" assumption: that every feature it's looking at is completely independent of the others. When deciding if an email is spam, it assumes the word "free" has no relationship to the word "money."
This is almost never true in the real world, but this simplification is its superpower. By ignoring complex relationships, the model can be trained incredibly fast, giving you a functional baseline in hours, not weeks.
Practical Example 1: Spam Filter for a SaaS App
A common use case for the Naive Bayes algorithm is building a spam filter. If your SaaS product has a messaging feature, you need a fast, reliable filter to maintain user trust.
The Architecture:
Business Impact:
Practical Example 2: Interview Question for an ML Engineer
When hiring, you need to test for practical application, not just theory. This question helps you find engineers who think about business impact.
The Scenario: "You're tasked with building a system to classify incoming customer support tickets into 'Urgent' and 'Not Urgent.' Walk me through how you'd use the Naive Bayes algorithm, from data to deployment. What are the biggest risks?"
What to Look for in a Great Answer:
The Deep Dive: How the Naive Bayes Algorithm Works
The algorithm is a straightforward application of Bayes' Theorem, which is just a formal way of updating your beliefs based on new evidence.
Think of it like a recipe:
The algorithm combines these to produce the posterior probability—the updated guess about the outcome.
The "Naive" Assumption: A Powerful Trade-Off
The "naive" part is its conditional independence assumption. It assumes every feature is independent. For example, it assumes a ticket containing "outage" has no bearing on whether it also contains "down."
Alt text: A diagram showing a class variable C influencing features F1 to Fn. Crucially, there are no lines connecting the features, visualizing the 'naive' independence assumption.
This assumption is what makes the Naive Bayes algorithm so fast. It doesn't waste compute power on the tangled relationships between features. For a CTO, this means training a baseline model on thousands of features in minutes, not hours.
Its mathematical roots go back centuries, but it truly took off in the 1990s for real-time jobs like email spam filtering. Studies showed it could even outperform more complex algorithms in certain text-based tasks. You can dive deeper into its rich history and surprisingly competitive performance.
Choosing the Right Naive Bayes Variant
Picking the right variant is critical and depends entirely on your data's structure.
Gaussian Naive Bayes
Use this when your features are continuous numbers that follow a "bell curve" (a Gaussian distribution).
Multinomial Naive Bayes
This is the classic choice for text classification where features are word counts.
Bernoulli Naive Bayes
Use this for binary features—things that are either present (1) or absent (0).
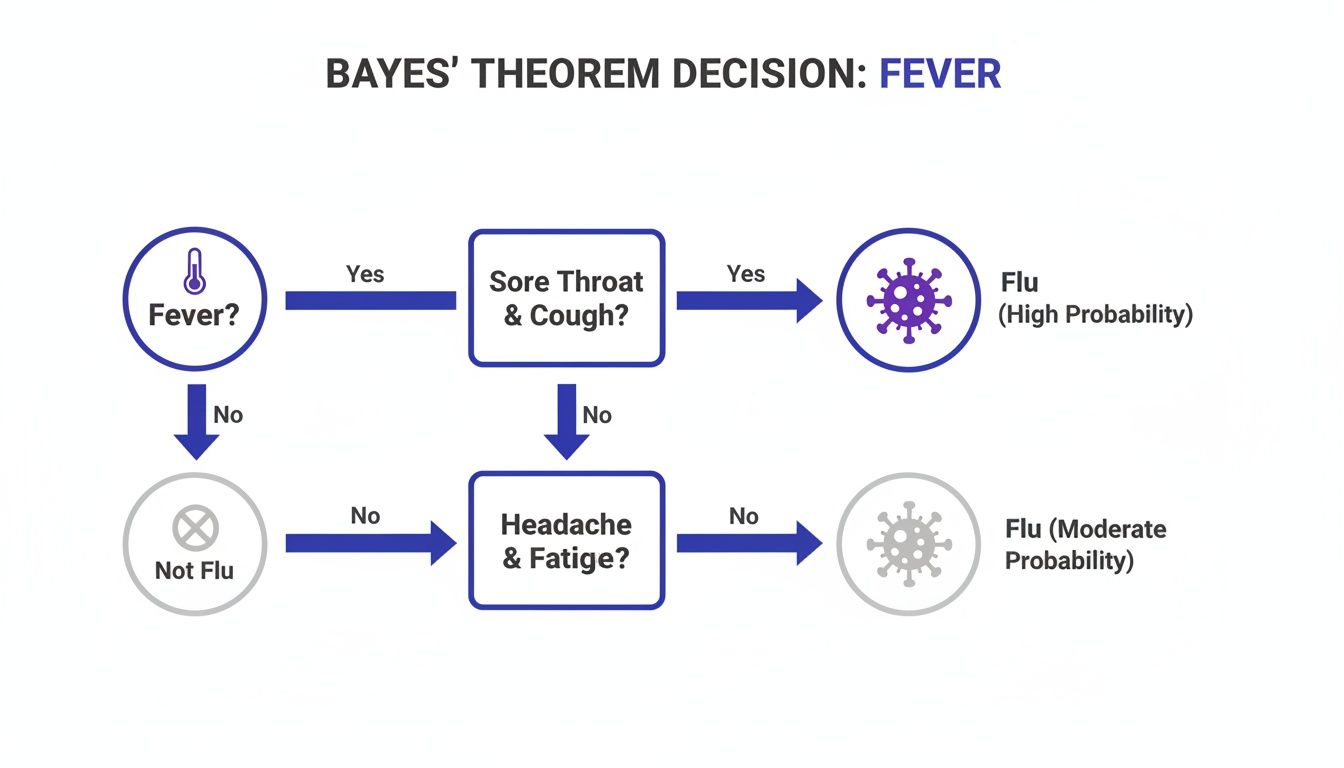
Alt text: A Bayes' Theorem decision tree for flu diagnosis, where each symptom like 'fever' updates the probability of having the flu, illustrating probabilistic reasoning.
Checklist: Your Naive Bayes Project Plan
Use this checklist to guide your Naive Bayes implementation from idea to production.
Phase 1: Scoping & Setup (1–2 Days)
Phase 2: Development & Training (2–3 Days)
Phase 3: Evaluation & Deployment (1–2 Days)
Trade-Offs, Limits, and Alternatives
No algorithm is perfect. Knowing the limits of the Naive Bayes algorithm is key to using it effectively.
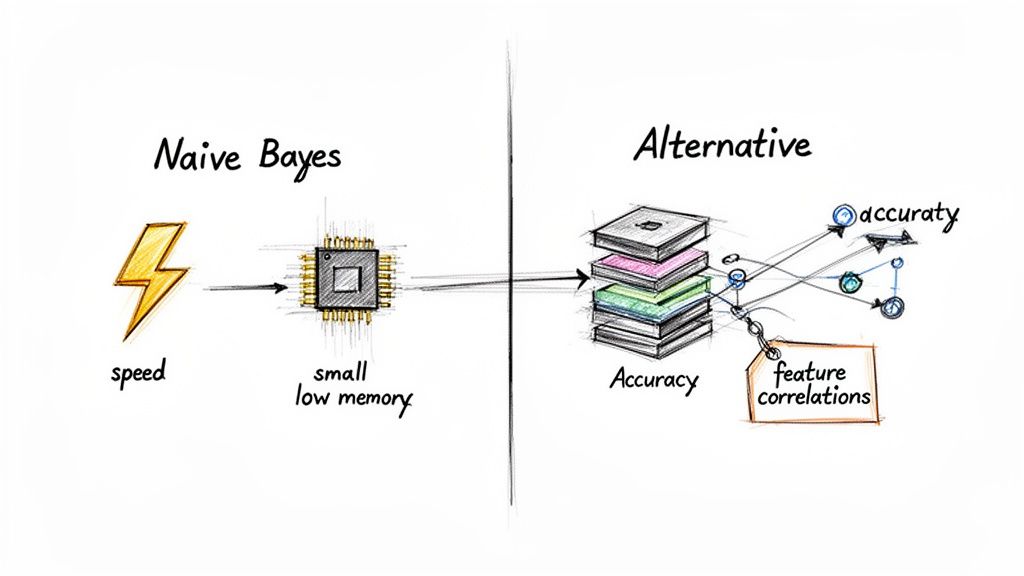
Alt text: Infographic showing the trade-offs: Naive Bayes offers high speed and low memory, while alternatives offer higher accuracy by handling feature correlations.
Strengths: Why You Use It
Weaknesses: When to Be Cautious
When to Use an Alternative
Use Naive Bayes to get a fast baseline. Upgrade when you hit its limits and have a clear business case for higher accuracy.
IBM's documentation offers a great overview of its performance history, confirming its value for high-throughput, low-latency systems.
What to Do Next
Ready to build a team with the expertise to choose and deploy the right algorithm for the job? ThirstySprout connects you with senior AI and ML engineers who ship production models.
Start a Pilot with pre-vetted AI talent today.
References
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.