
- Fine-Tune for Skills, Not Facts: Use fine-tuning to teach a large language model (LLM) a new skill, behavior, or style—like matching your brand voice or generating specific code. For answering questions from documents, start with Retrieval-Augmented Generation (RAG).
- PEFT is the Standard: Use Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA. They cut compute costs and training time by up to 90% compared to full fine-tuning and avoid "catastrophic forgetting."
- Data Quality Over Quantity: A small, clean dataset of 1,000 high-quality, instruction-formatted examples will outperform a massive, noisy dataset. Focus on curating data that mirrors your production use case.
- Deploy Smartly: Use an optimized inference server (like vLLM) and quantization (4-bit) to reduce latency and Total Cost of Ownership (TCO). For most teams, a serverless GPU platform like Modal offers the best balance of cost and performance.
- Recommended Action: Start with a pilot project. Define a clear business metric, create a small, high-quality dataset of 500-1,000 examples, and run a LoRA fine-tuning experiment on a model like Llama-3-8B. The training cost is often less than $20.
Who this is for
- CTO / Head of Engineering: Deciding on the architecture for an AI feature and whether to build a custom model or rely on off-the-shelf APIs.
- Founder / Product Lead: Scoping the budget, timeline, and team needed to ship a specialized AI capability that creates a competitive advantage.
- AI/ML Engineer: Looking for a step-by-step, production-focused playbook for fine-tuning, evaluating, and deploying a custom LLM.
A 5-Step Framework for Production Fine-Tuning
This guide provides a step-by-step framework for connecting fine-tuning directly to business outcomes. The process is more straightforward than you might think.
- Define the Goal & Baseline: Identify a specific business Key Performance Indicator (KPI) you want to move (e.g., reduce support ticket resolution time by 30%). Test a powerful base model like GPT-4o or Llama 3 to set a performance benchmark. If you can't beat the baseline, don't fine-tune.
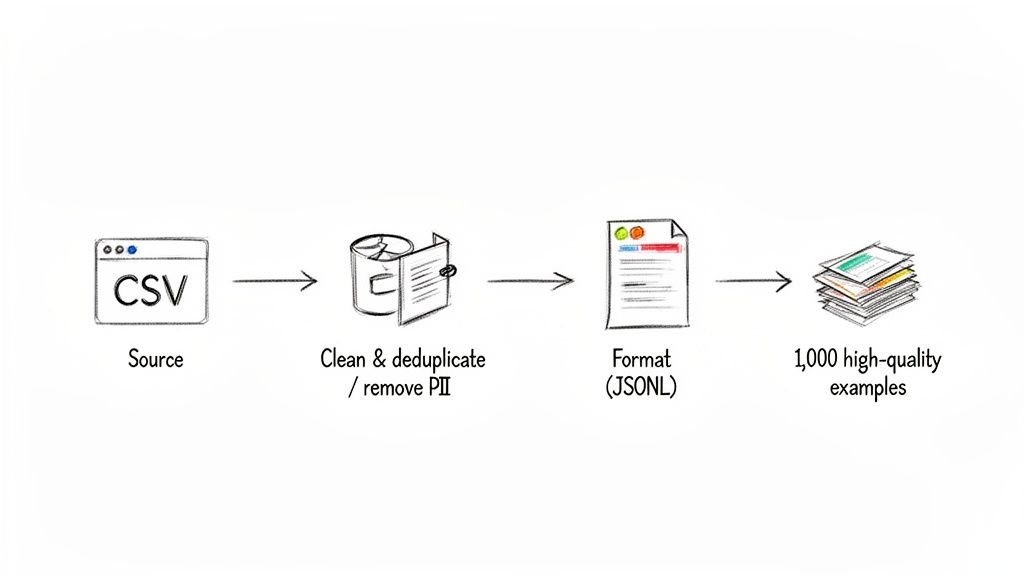
- Curate a High-Quality Dataset: Assemble 1,000 perfect, real-world examples. Clean the data aggressively, scrub all Personally Identifiable Information (PII), and format each entry as a clear instruction-response pair (e.g., using the Alpaca prompt template).
- Choose a Base Model & PEFT Strategy: Select an appropriate open-source model (e.g., Llama-3-8B, Mistral-7B). Use a PEFT method like LoRA (Low-Rank Adaptation) to train efficiently on a single GPU.
- Train & Evaluate Rigorously: Run the training job, tracking hyperparameters meticulously. Evaluate the resulting model with both automated metrics and a structured human review process using a scorecard.
- Deploy, Monitor & Optimize: Deploy the model using an optimized inference server. Implement monitoring for latency, cost, and model quality. Create a feedback loop to collect production data for future improvements.
Practical Example 1: Fintech Transaction Classifier
A common use case we see is classifying financial data into custom categories that are specific to a business, which general models fail at.
- The Business Problem: A fintech startup needed to classify user transactions into 50+ highly specific, custom categories (e.g., "Subscription-Software" vs. "Subscription-Media"). A general model like GPT-4 struggled with the nuance, leading to manual re-categorization and a poor user experience.
- Dataset: 2,000 labeled transactions sourced directly from their production database.
- Hardware: A single NVIDIA V100 GPU on a cloud provider.
- Training Time: Under 4 hours.
- Business Impact: The fine-tuned model achieved 95% classification accuracy, reducing manual correction work by over 80%. This directly improved the product's value and scalability for a one-time training cost of less than $50.
Practical Example 2: Data Prep & Training Snippet
Your data quality is a direct proxy for your final model's quality. Here’s an actionable code snippet for transforming a messy CSV of support tickets into a clean JSONL file ready for training. The prompt template is the most critical part—it teaches the model its role and expected output format.
import pandas as pdfrom datasets import Dataset# 1. Load raw data from a CSVdf = pd.read_csv("support_tickets.csv")# 2. Define a prompt template for instruction tuningdef create_prompt(row):# This template is crucial. It teaches the model the exact format you expect.template = f"""### Instruction:You are a helpful customer support agent. Read the following ticket and provide a clear, concise resolution.### Ticket:{row['ticket_text']}### Resolution:{row['resolution_text']}"""return {"text": template}# 3. Apply the template and create a Hugging Face Dataset object# This assumes your CSV has 'ticket_text' and 'resolution_text' columnsdataset = Dataset.from_pandas(df)formatted_dataset = dataset.map(create_prompt)# 4. Save the prepared data to a JSONL file, ready for trainingformatted_dataset.to_json("training_data.jsonl", orient="records")print("Dataset successfully transformed to training_data.jsonl")This structured data is then fed into a training script. This script shows how to configure a LoRA fine-tuning job using standard libraries like transformers and peft.
import torchfrom transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArgumentsfrom peft import LoraConfigfrom trl import SFTTrainer# Configurationmodel_name = "meta-llama/Meta-Llama-3-8B"dataset_path = "training_data.jsonl" # Your formatted data# 1. Load Model and Tokenizer with 4-bit quantization for memory savingsmodel = AutoModelForCausalLM.from_pretrained(model_name,load_in_4bit=True,torch_dtype=torch.float16,device_map="auto")tokenizer = AutoTokenizer.from_pretrained(model_name)tokenizer.pad_token = tokenizer.eos_token# 2. Configure LoRAlora_config = LoraConfig(r=16,lora_alpha=32,lora_dropout=0.05,bias="none",task_type="CAUSAL_LM",target_modules=["q_proj", "k_proj", "v_proj", "o_proj"])# 3. Define Training Argumentstraining_args = TrainingArguments(output_dir="./results",per_device_train_batch_size=4,gradient_accumulation_steps=4,learning_rate=2e-4,num_train_epochs=3,logging_steps=10,fp16=True,)# 4. Initialize Trainer (assuming you've loaded 'formatted_dataset')trainer = SFTTrainer(model=model,train_dataset=formatted_dataset, # Your dataset objectargs=training_args,peft_config=lora_config,max_seq_length=1024,tokenizer=tokenizer,)# 5. Start trainingtrainer.train()This setup strikes a balance between performance and resource use, making it a reliable blueprint for fine-tuning on a single GPU.
Deep Dive: Trade-offs, Alternatives, and Pitfalls
Full Fine-Tuning vs. PEFT: The Only Choice That Matters
Your first major decision is choosing a tuning method.
- Full Fine-Tuning: Retrains every single weight in the model. This requires massive datasets and multiple high-end GPUs (e.g., A100s). The high cost and risk of "catastrophic forgetting"—where the model forgets its general knowledge—make it impractical for most teams.
- Parameter-Efficient Fine-Tuning (PEFT): Freezes the model’s original weights and trains a small set of new "adapter" layers on top. This is the default choice for nearly all production use cases.

The Business Impact: Adopting PEFT slashes compute costs and memory needs by up to 90%. A job that might require >24GB of VRAM with full tuning can often run with <16GB using LoRA. This unlocks faster experiments, lower cloud bills, and empowers smaller teams to build custom models without a large infrastructure budget. Understanding the difference between supervised and unsupervised machine learning helps in preparing the supervised dataset needed for this process.
Pitfall 1: Using a Huge, Noisy Dataset
The idea that you need tens of thousands of examples is an outdated myth from the early days of LLMs. Quality crushes quantity. Meta's 2023 LIMA experiment proved that a model fine-tuned on just 1,000 curated examples outperformed models trained on over 50,000 noisy ones.
How to Avoid It: Focus your engineering time on curating a small, pristine dataset. Time spent cleaning, structuring, and reviewing your data has a higher ROI than any other step. This also drastically cuts down the time-to-value for shipping a custom model. For more details on this, see this guide on how to train ChatGPT on your own data. You can manage this process with the best data pipeline tools.
Pitfall 2: Relying Only on Automated Evaluation Metrics
Relying on automated metrics like ROUGE or BLEU is a classic mistake. They provide a quick signal but fail to measure nuance, style, or factual accuracy.
How to Avoid It: Human review is non-negotiable if your model will interact with users. Use a simple evaluation scorecard to have reviewers rate outputs on a 1-5 scale across key criteria. This forces a structured, objective review process and ensures the model you ship is a genuine improvement. For more on building robust evaluation systems, see our guide on automating regression testing.
Simple Evaluation Scorecard
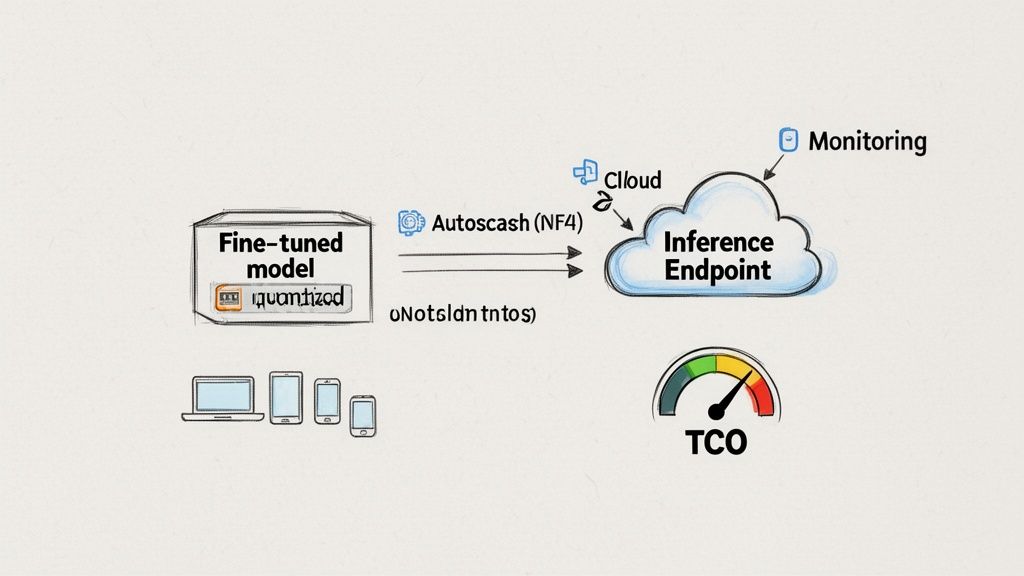
Pitfall 3: Ignoring Deployment Costs (TCO)
A fine-tuned model sitting on a hard drive provides no value. The final step is pushing it to production reliably and cost-effectively, which requires a smart Machine Learning Operations (MLOps) strategy.
How to Avoid It: Plan your deployment architecture from the start.
- Managed Endpoints: Services like Hugging Face Inference Endpoints or Amazon SageMaker offer a fast path to production.
- Optimized Inference Servers: High-throughput servers like vLLM or NVIDIA's TensorRT-LLM maximize performance.
- Cost-Saving Techniques: Use quantization to shrink the model's memory footprint by up to 75% and run on cheaper GPUs.
- Our Recommendation: For most teams, serverless GPU platforms like Modal or Anyscale offer the best trade-off. They combine the simplicity of a managed service with the performance of an optimized engine like vLLM, allowing you to scale to zero and only pay for what you use.
Your Total Cost of Ownership (TCO) breaks down into three parts:
- Data Prep Cost: Primarily engineering hours.
- Training Cost: GPU hours for experiments (often <$20 per run for PEFT).
- Inference Cost: The ongoing operational expense, which is the largest component.
For a deeper dive into building this infrastructure, check out our guide on MLOps best practices.
Checklist: From Idea to Production-Ready Model
Use this checklist to de-risk your project and ensure every technical decision is tied to a business goal.
Phase 1: Scoping & Justification (1-2 days)
- Define the Problem: Confirm fine-tuning is necessary over prompt engineering or Retrieval-Augmented Generation (RAG).
- Set a Measurable Goal: Define a specific KPI to improve (e.g., "achieve 95% accuracy on ticket classification").
- Establish a Baseline: Test an off-the-shelf model like GPT-4o or Llama 3 to define your performance target.
Phase 2: Data Preparation (3-5 days)
- Source Representative Data: Collect 500-2,000 examples from the production environment.
- Clean & Sanitize: Deduplicate, remove low-quality examples, and scrub all PII.
- Format for Instruction-Tuning: Structure every example into a consistent JSONL format with a clear prompt template.
Phase 3: Training & Experimentation (2-4 days)
- Select a Base Model: Choose a suitable model like Mistral-7B or Llama-3-8B.
- Run a Smoke Test: Train on 100 examples first to catch configuration errors quickly.
- Track Experiments: Log all hyperparameters (learning rate, LoRA rank, etc.) and evaluation results for each run.
Phase 4: Evaluation & Safety (2-3 days)
- Automated Metrics: Measure performance against your baseline using relevant metrics (e.g., accuracy, ROUGE).
- Human Review: Use a scorecard to have at least two reviewers evaluate outputs for helpfulness, tone, and accuracy.
- Red Teaming: Actively test for failure modes, biases, and harmful content before deployment.
Phase 5: Deployment & Monitoring (Ongoing)
- Optimize for Inference: Quantize the model and deploy it with an optimized engine like vLLM.
- Set Up Monitoring: Create a dashboard to track latency, error rates, and cloud costs.
- Implement a Feedback Loop: Build a simple mechanism for users to flag bad responses, providing data for the next training cycle.
What to Do Next
- Scope a Pilot Project: Identify a high-impact, low-risk use case in your organization that can be tested in 2-4 weeks.
- Assemble Your Dataset: Follow the checklist to curate a small, high-quality dataset of at least 500 examples.
- Talk to an Expert: Schedule a call with us to validate your approach, estimate the TCO, and define the engineering skills you'll need to succeed.
Ready to build a world-class AI team? ThirstySprout helps you hire vetted, senior AI and ML engineers who can ship production-ready models. Start a pilot in under a week.
References
- Low-Rank Adaptation of Large Language Models (LoRA), arXiv:2106.09685, Microsoft Research.
- LIMA: Less Is More for Alignment, arXiv:2305.11206, Meta AI Research.
- Hugging Face
transformers,peft, andtrllibrary documentation. - LLM Fine-Tuning Services Market Projections, Verified Market Research, 2024.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.