
You're probably in one of two situations right now. Either a product team keeps asking for “AI” and you've translated that into “we need a data scientist,” or your company already has dashboards, SQL, and a warehouse, but nobody owns forecasting, experimentation, or predictive work end to end.
Most hiring advice fails because it starts with interview questions. That's too late. If you want to hire a data scientist who creates business value, you need an operating system. Start with role diagnosis, write a job spec that matches the actual work, run a process that tests real performance, and onboard them into a problem they can influence quickly.
TL;DR
- Don't hire a data scientist by default. If your real blocker is broken pipelines, poor data access, or missing production support, hire a different role first.
- Write the role around decisions, not tools. Python and SQL matter, but the job is turning messy data into decision-ready recommendations.
- Use a structured funnel. A practical sequence is pre-screen, take-home, sales pitch, data day, then a fast decision, as outlined by First Round Review's hiring framework.
- Test with real data and business context. The strongest signal is whether a candidate can analyze realistic data, explain patterns, and recommend next steps, as argued in CoderPad's guidance on hiring data scientists.
- Plan Day 1 before you open the role. Retention and time-to-impact depend on clear problems, supporting engineering capacity, and working conditions that good candidates want, according to Robert Half's hiring guidance.
Who this is for: CTOs, founders, heads of engineering, and hiring leaders who need a data scientist in the next hiring cycle and want the person to ship useful work, not just present clever notebooks.
First Question Is This the Right Hire
The most expensive mistake isn't choosing the wrong candidate. It's choosing the wrong role.
A lot of teams say they need a data scientist when they really need one of three things: a better analytics layer, a data engineer, or an machine learning engineer who can productionize models. CIO makes the point clearly that data scientists are most effective when they're supported by data engineers and machine learning engineers. When they're forced to clean data, productionize models, and handle repetitive platform work, output drops fast, as noted in CIO's guide to hiring and retaining data scientists.
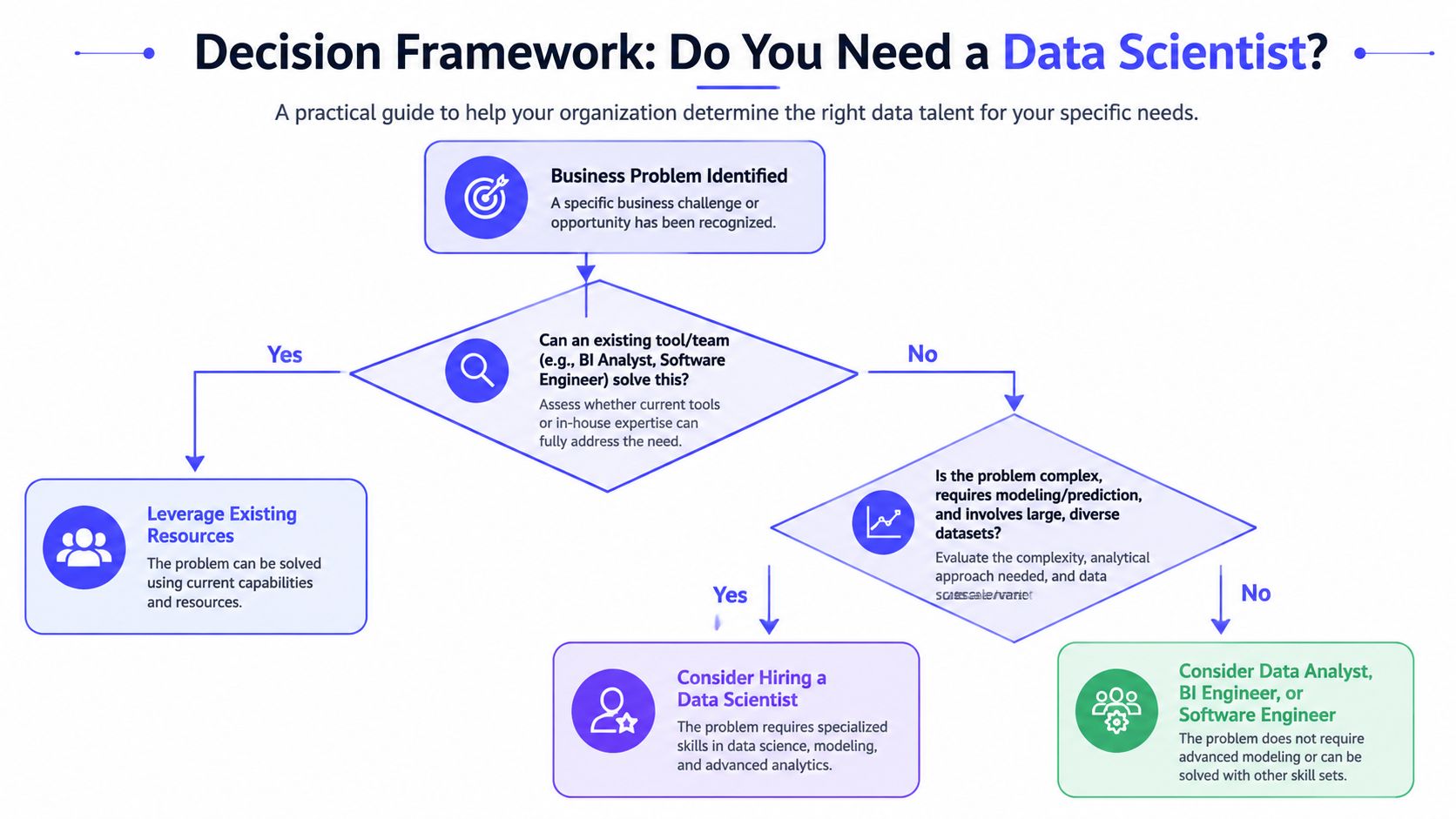
Use a simple decision tree
Ask these questions in order:
Can your existing team solve this?
If a BI analyst can answer it with SQL and dashboards, don't create a new role.Does the problem require modeling or prediction?
If you need churn prediction, demand forecasting, anomaly detection, or experimentation design, the case for a data scientist gets stronger.Is the data usable already?
If data lives in five systems, definitions change weekly, and nobody trusts the warehouse, hire data engineering help first.Who will own deployment?
If the output needs to run in production, you likely need machine learning engineering support. We break that distinction down in this comparison of machine learning engineer vs data scientist.
Quick role split
| Need | Better first hire |
|---|---|
| Clean pipelines, warehouse modeling, reliable ingestion | Data Engineer |
| Dashboards, KPI definitions, business reporting | Analytics Engineer or BI Analyst |
| Predictive modeling, experimentation, decision support | Data Scientist |
| Production inference, model serving, deployment workflows | Machine Learning Engineer |
Practical rule: If your first six months of “data science” work would mostly involve fixing tables, joining broken sources, and making dashboards trustworthy, you don't need a data scientist first.
Mini-case example
A Series A SaaS company wants lead scoring. The founder asks for a data scientist. After one discovery session, the actual problem is obvious: CRM data is inconsistent, product events aren't standardized, and nobody agrees on what counts as a qualified lead. A data scientist in that setup spends their time cleaning and negotiating definitions. The better move is to stabilize the data model first.
A different company has clean product analytics, a clear conversion funnel, and a pricing team making manual forecast calls every month. That's a good environment for a data scientist. The work is already framed as decisions, not plumbing.
If your use case is workforce planning, attrition risk, or hiring forecasts, it's worth reviewing Synopsix's guide to predictive HR. Not because you need HR analytics specifically, but because it shows the kind of business framing a useful data science role should support.
Define the Role and Write a High-Signal Job Spec
A weak job spec creates an expensive hiring loop. You attract candidates who can talk about models, but not candidates who can improve a decision your company makes.
The fix is simple. Define the operating context before you write a single bullet point.
Start with the decision, not the toolkit
The role should exist to improve a recurring business decision. Churn risk. Pricing. Forecasting. Experiment design. Fraud review. Demand planning. If you cannot name the decision, you are not ready to hire.
That decision determines the profile. A product data scientist who designs experiments and influences roadmap tradeoffs is a different hire from a forecasting specialist or an applied scientist building recommendation models. Treating them as one generic "data scientist" role is how teams end up with six interviews, no alignment, and a bad hire.
Write down four things first:
- The decision this person will improve
- The datasets they will rely on
- The stakeholders who will act on the work
- The boundaries of the role
The boundary matters more than hiring teams admit. Strong candidates read a spec to spot hidden cleanup work, vague ownership, and politics disguised as "cross-functional collaboration." If the actual job is half analyst, quarter data engineer, and quarter scientist, say so or fix the scope.
Braintrust gets this part right in its guide to hiring data scientists. The useful profile is not "good at machine learning." It is someone who can apply statistics, modeling, and business communication to a specific operating problem.
Build the scorecard before the job post
Do this internally first. It forces discipline and stops the usual habit of dumping every desirable skill into the public spec.
| Skill area | Must have | Nice to have | Not needed |
|---|---|---|---|
| SQL and data manipulation | Complex joins, validation, exploration | Query optimization | BI dashboard ownership |
| Statistics | Hypothesis testing, regression, experimental thinking | Bayesian methods | Academic depth without a business use |
| Programming | Python for analysis and modeling | TensorFlow or Java if your stack requires it | Broad language lists with no clear reason |
| Machine learning | Model selection, evaluation, trade-offs | Clustering or optimization depth | Production platform ownership |
| Communication | Clear recommendations for product and business teams | Executive presentation polish | Sales-style storytelling |
This matrix does two jobs. It sharpens the post, and it gives interviewers a common standard. Without it, one interviewer screens for research depth, another screens for stakeholder polish, and a third screens for infrastructure work nobody asked for.
If your team is hiring across adjacent roles, use a neighboring spec as a boundary check. This AI engineer job description guide is useful for separating model development from application and deployment work.
Pay follows scope
Compensation confusion usually starts with role confusion.
Indeed's current market pages show a large active market for statistical data scientist roles, including a Statistical Data Scientist job search on Indeed, and compensation on posted roles varies widely by scope and level. The lesson is not the exact number. The lesson is that broad, poorly defined roles get priced inconsistently and attract the wrong mix of applicants.
The same pattern shows up in salary benchmarks. The University of Texas at Dallas cites average pay of about $100,000 for data scientists versus $70,000 for data analysts in its comparison of the two paths. If you want analyst-grade reporting work with scientist-grade credentials, expect friction. You will either overpay for work that does not need the title, or lose serious candidates once they understand the actual scope.
Set the boundary first. Then set the range.
Write responsibilities that describe outputs
Bad specs describe activities. Good specs describe outcomes, interfaces, and constraints.
Skip this:
- Build machine learning models
- Work with stakeholders
- Extract insights from data
Use this:
- Own churn analysis and prediction for the self-serve product
- Design and evaluate experiments with product and growth leaders
- Deliver decision memos with recommended actions, assumptions, and trade-offs
- Hand off deployable logic to engineering with clear documentation
- Exclude warehouse rebuilds and model serving infrastructure from the role
That last line matters. Good candidates want to know where the job stops.
For a starting point, Talantrix's Data Scientist job resource is useful. Do not paste it into your ATS and call it done. Adapt it to your data maturity, decision cadence, and team design. A high-signal spec feels specific enough that the right candidate can picture their first 90 days, and the wrong candidate can tell they are not a fit.
Source Candidates from High-Signal Channels
Posting on a general job board and waiting is fine if you want volume. It's weak if you want fit.
The best data scientists rarely respond to generic recruiter copy because generic outreach signals a generic role. If your note says “your background looks interesting, we're building something exciting in AI,” you've already told them you didn't read their work and probably don't know what you need.
What high-signal sourcing actually looks like
Good sourcing starts with role-specific filters. Don't search only for “Data Scientist.” Look for people whose work matches your problem. Depending on the role, that may include titles like decision scientist, applied scientist, senior analytics engineer, experimentation lead, or product data scientist.
Prioritize channels that reveal actual work:
- Referrals from engineers, PMs, and analysts who've worked with strong data talent
- Portfolio and GitHub review when the role requires code quality and reproducible analysis
- Kaggle, conference talks, technical writing, or open-source contributions when modeling depth matters
- Specialized talent partners when speed and vetting matter more than candidate volume
Platforms are also compressing the early sourcing cycle. Uplers says it can provide 3 to 5 relevant candidates in 48 hours in its hiring workflow claims referenced in the verified data. Whether you use a platform, internal recruiting, or a partner, the point is the same. Speed now matters because strong technical candidates won't sit in a slow funnel.
Mini-case outreach example
Weak outreach:
Hi, we're hiring a data scientist for an exciting AI startup. You seem like a strong fit. Open to chatting?
Better outreach:
You built experimentation workflows for subscription conversion and wrote about trade-offs in retention modeling. We have a clean events pipeline, a pricing team making manual forecast calls, and a product org that needs a scientist who can challenge assumptions, not just build dashboards. The first project is demand forecasting tied to a real planning process. If that's close to the work you want, I'll send the scorecard and interview steps.
That second message works because it shows three things:
- you know what they've done
- you know what your company needs
- you can describe the first problem clearly
A sourcing checklist for hiring managers
- Define one search thesis: what kind of problems has this person solved before?
- Use artifact-based sourcing: prioritize public work, portfolios, notebooks, talks, or references to shipped analysis
- Show the first project in outreach: candidates want to know what they'll own
- Mention operating context: data quality, stakeholder maturity, and deployment support
- Avoid keyword laundry lists: they make the role sound unfocused
The strongest outreach reads like a peer inviting another peer to solve a hard problem.
One practical option is using a vetted network such as ThirstySprout when you need pre-qualified AI and data talent across full-time, contract, or fractional models. That doesn't replace your own role definition. It reduces the time wasted on candidates who were never aligned in the first place.
Run a Structured Interview Process
A candidate clears four friendly conversations, joins your team, and then spends three months polishing models nobody uses. That failure usually starts in the interview loop. The process tested charisma, polish, and résumé brand names. It did not test whether the person can frame a business problem, work with messy data, and influence decisions.
Run interviews like an operating system. Each step should answer one hiring question, and no two steps should test the same thing twice.
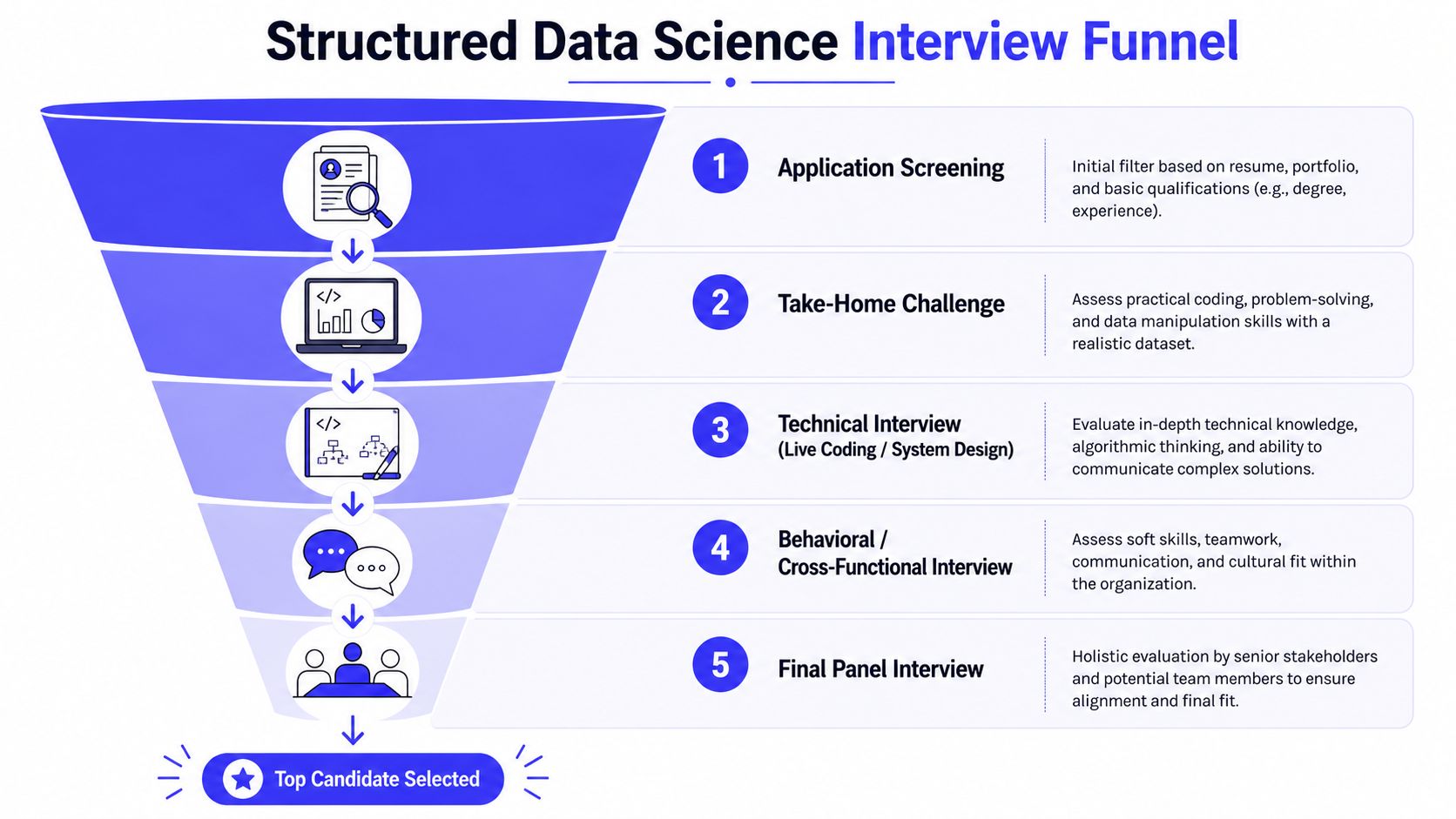
Stage-by-stage interview design
Pre-screen
Use the pre-screen to confirm the basics and protect everyone's time.
Check for:
- direct relevance to the problems you need solved
- clear communication
- motivation that matches the role you defined
- compensation and working model alignment
Keep this short. Thirty minutes is enough. If the candidate cannot explain a past project in plain English, that is a useful signal.
Hiring manager interview
This is the highest-value conversation in the loop. Use it to test judgment.
Ask the candidate to walk through one project from start to finish:
- what the business decision was
- what data was available and what was missing
- what trade-offs they made
- what shipped
- what changed because of their work
Press on the messy parts. Good candidates talk clearly about bad data, stakeholder conflict, weak proxies, and decisions made under uncertainty. Weak candidates hide behind model names.
If your role sits close to production ML, align this round with the standards you would use to hire machine learning engineers for applied production work. The split between analytics, experimentation, and ML engineering should be explicit in the panel design, not discovered after the offer is signed.
Live analytical interview
Give the candidate a small set of tables, a chart, or a short case. Then ask:
- what would you inspect first
- what looks suspicious
- what would you ignore for now
- what decision should the business make with incomplete information
This round predicts on-the-job performance better than abstract brainteasers. You are testing prioritization, skepticism, and communication under time pressure.
Stakeholder communication interview
A data scientist who cannot persuade product, finance, or operations will create nice notebooks and little else.
Run a scenario-based discussion. Ask the candidate to explain a recommendation to a skeptical executive, or to defend why a result is directionally useful even when the data is imperfect. Listen for clarity, restraint, and whether they can separate confidence from certainty.
Here's a useful explainer if your team wants a quick visual overview before designing the panel:
Cross-functional interview
Do not turn this into a vague “culture fit” chat.
Use structured behavioral questions tied to the job:
- Tell me about a time product wanted an answer faster than the data justified.
- Tell me about a time you were wrong and had to change your recommendation.
- Tell me about a disagreement over an experiment, forecast, or KPI definition.
- Tell me how you handled a stakeholder who wanted certainty you could not provide.
A practical framework helps here. The OKR Hub's hiring insights are useful for evaluating collaboration and working style without drifting into personality judgments.
Final decision
Hold the debrief the same day.
Require every interviewer to submit written scores before discussion starts. Score against the same rubric. If you let the first opinion set the tone, the rest of the panel will follow it.
Example scorecard
| Dimension | What good looks like | Red flag |
|---|---|---|
| Problem framing | Defines the business decision before choosing a method | Starts with tools or algorithms |
| Data judgment | Questions source quality, bias, leakage, and missing context | Treats inputs as clean and complete |
| Technical execution | Chooses methods that fit the constraint and explains why | Reaches for complexity without a reason |
| Communication | Explains findings clearly to non-technical partners | Uses jargon to avoid clarity |
| Ownership | Connects analysis to action, rollout, and follow-up | Stops at a notebook or slide |
Good data scientists improve decision quality. Hire for that standard.
Design a Take-Home Task That Predicts Performance
Most take-homes are badly designed. They reward free time, not judgment.
If you want a useful signal, the task should look like the job. That means a small but realistic dataset, a clear business question, and enough ambiguity that the candidate has to make choices. It should not feel like a graduate statistics exam or a puzzle set from a coding platform.
What a strong take-home includes
Use a prompt like this:
You're supporting a subscription product team. We've provided event data, account metadata, and recent plan changes. Identify the drivers of conversion or churn risk, explain what patterns matter, and recommend the next actions the product team should take. Show your assumptions.
That works because it tests the whole loop:
- data inspection
- method choice
- analytical reasoning
- communication to stakeholders
CoderPad's guidance is directionally right here. The strongest signal is whether a candidate can work with actual data and explain what they'd do next in business terms, not just model terms.
A practical rubric your team can use
Score submissions across five areas:
Problem framing
Did they restate the business problem clearly? Did they define success?Data handling
Did they inspect data quality, missing values, outliers, or odd joins? Did they challenge the input where needed?Analytical depth
Did they choose methods that fit the question? Did they explain trade-offs instead of showing off?Code and reproducibility
Is the work readable, organized, and rerunnable?Recommendation quality
Could a PM or operator act on the result?
You don't need a numeric scale in the article to make this useful. Internally, you can rate each category with a simple weak, acceptable, strong rubric and require written notes for every decision.
Mini-case example
Candidate A submits polished code, multiple models, and dense charts. The final recommendation is vague. You still don't know what the company should do next.
Candidate B submits simpler analysis, calls out a data quality issue, explains why one segment behaves differently, and recommends one product test plus one data fix. Candidate B is often the stronger hire.
That's especially true if your organization needs someone who can influence product and engineering, not just build notebooks. If your roadmap leans more toward deployment-heavy work, use this as a handoff point and consider whether you should hire machine learning engineers alongside or instead of a data scientist.
A good take-home answers one question: would I trust this person with a live business problem next month?
Make the Offer and Onboard for Rapid Impact
A bad close creates a bad start.
You pick the candidate, everyone celebrates, and then the new data scientist spends ten days waiting for access, gets three conflicting priorities, and hears “just find something useful.” That is not onboarding. That is organizational confusion, and it turns strong hires into slow hires.
The offer stage is part of the hiring system, not paperwork at the end. If you want Day 1 impact, decide the working model, define the first problem, line up the manager and stakeholders, and remove the access blockers before the person signs.
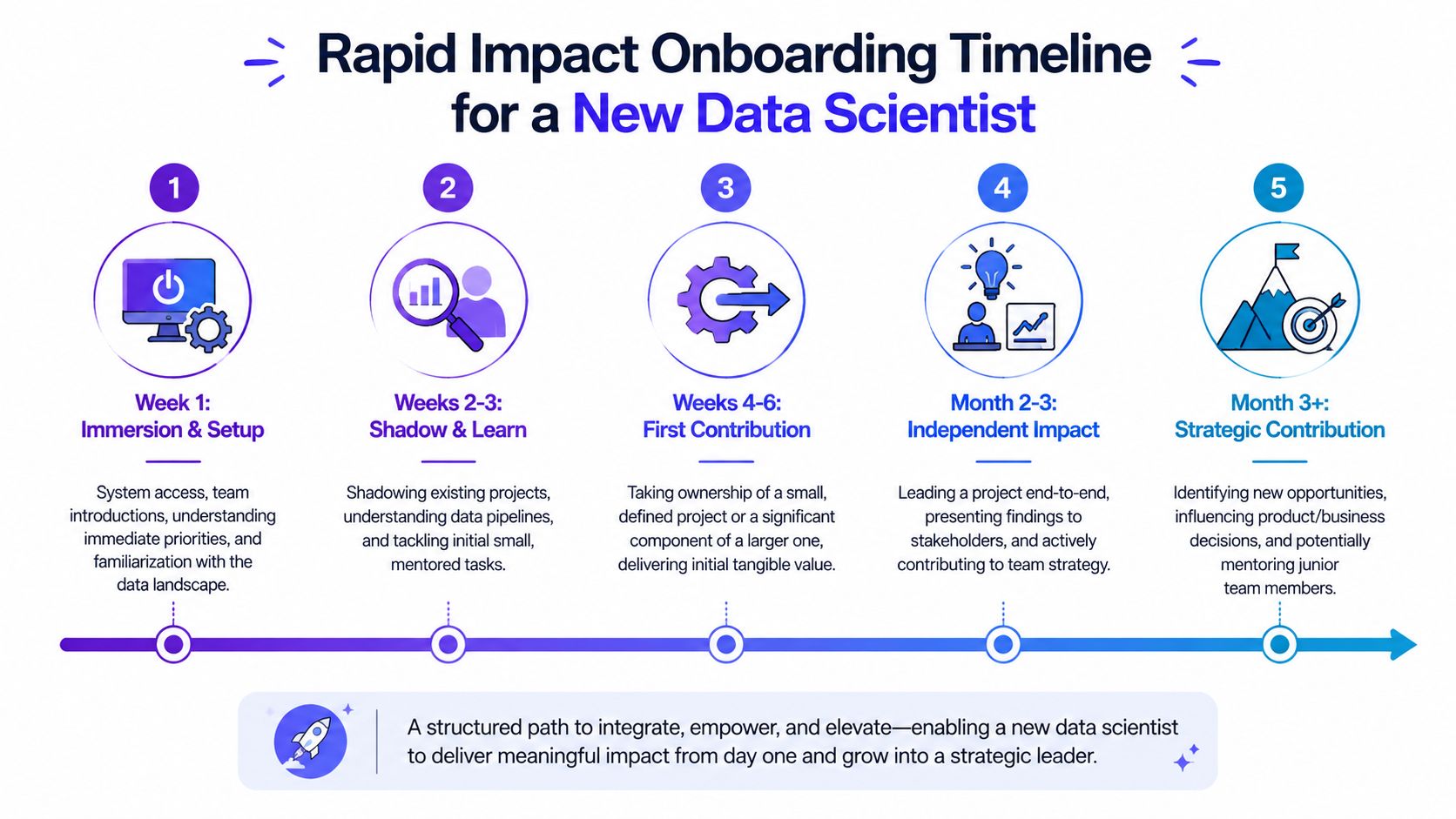
Choose the right engagement model
Pick the model that fits the uncertainty in the role.
| Model | Best when | Risk |
|---|---|---|
| Full-time hire | Ongoing roadmap, clear ownership, long-term business need | Expensive mistake if the scope is still vague |
| Contract | Urgent project, defined deliverable, unclear long-term demand | Project stalls if nobody inside owns the outcome |
| Fractional | You need senior judgment to shape the function before adding headcount | Limited execution capacity |
Use full-time only when you can name the first few decisions this person will support and who will act on the work. Use contract when the need is narrow and time-bound. Use fractional when the primary problem is setup, not production capacity.
Teams get this wrong all the time. They hire a full-time data scientist to compensate for unclear priorities, weak instrumentation, or missing data engineering support. That hire struggles because the system is broken, not because the person is weak.
What the offer should make clear
A strong candidate evaluates your operating discipline as much as your compensation.
Your offer should answer five questions:
- What problem do I own first?
- Who is my manager, and who are my core stakeholders?
- What support exists from engineering, analytics, or machine learning teams?
- What systems and data will I have access to in the first week?
- What does success look like by 30, 60, and 90 days?
Clarity wins good candidates. Vague promises repel them.
If you cannot answer those questions in plain language, do not rush the offer. Fix the role design first.
Build onboarding around one business problem
New data scientists do not need a tour of every dashboard in the company. They need one concrete problem, one decision-maker, and the data required to make progress.
Use a simple 90-day plan.
Week 1
- Complete access setup: warehouse, notebooks, repos, dashboards, tracking docs
- Assign one manager and one primary cross-functional partner
- Review the business context: goals, current metrics, known data issues, existing constraints
- Define the first deliverable: decision memo, analysis, experiment review, or model recommendation
First month
- Ship one useful output: something a stakeholder can review and act on
- Audit metric definitions and instrumentation gaps
- Document role boundaries: what belongs to data science, analytics, engineering, and product
- Establish a review cadence: weekly manager check-in and regular stakeholder readout
First quarter
- Deliver one project that matters to the roadmap
- Present the recommendation to the people who own the decision
- Set up a repeatable workflow: validation steps, documentation, handoff, and follow-up measurement
This is the operating system most hiring guides miss. Interview quality matters, but the hire succeeds or fails based on role clarity, decision ownership, and how fast the company turns analysis into action.
Mini-case onboarding example
Bad onboarding looks familiar. The new hire gets access late, inherits a vague charter, meets a dozen stakeholders, and spends the first month trying to decode politics instead of solving a problem.
Good onboarding is tighter. By the end of week one, the new hire has the data, knows the first question to answer, understands who will use the output, and has a review on the calendar. That setup produces useful work fast because the company did the hard management work before asking for results.
Avoid Common Red Flags and Take Your Next Step
A bad data science hire rarely fails in the interview. They fail three weeks later, when the problem is messy, the data is worse than expected, and nobody can tell whether the work will change a decision.
That is the standard you should use now. Stop asking who sounded smart. Ask who is likely to produce useful work inside your company, with your constraints, on your timeline.
Red flags that matter
- Tool-first answers: they jump to Python, TensorFlow, or model choice before defining the decision, user, or business constraint
- No trade-off thinking: they describe methods but cannot explain what they would give up for speed, simplicity, interpretability, or deployment reality
- Weak stakeholder judgment: they never ask who will act on the output, how often, or what happens if the recommendation is wrong
- Blind trust in data: they do not probe for missing fields, broken instrumentation, sampling bias, or inconsistent metric definitions
- Analysis without ownership: they can produce notebooks and charts, but they do not think through rollout, handoff, monitoring, or follow-up measurement
One more red flag deserves extra weight. Candidates who make every project sound like a solo effort usually create problems later. Strong data scientists can explain where they led, where they depended on engineering or product, and how decisions got made.
If a candidate never asks how a recommendation gets used inside your company, they probably have not owned outcomes before.
Your next three steps are simple:
- Write the first six months of work in plain language.
- Build the scorecard before you talk to candidates.
- Decide whether you need a full-time hire, contract support, or a broader AI and data team around the role.
Do those three things before you open another req. A confused role attracts polished candidates, wastes interview time, and produces slow hires who need constant translation once they start.
If you want help turning this into a live hiring process, ThirstySprout helps teams hire vetted AI and data talent across full-time, contract, and fractional models. Start with a scoped pilot, review sample profiles, and make sure the role is right before you commit to the wrong hire.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.