
TL;DR
- Security is a system, not a single tool. Effective big data security requires integrating secure architecture, scalable governance, and a specialized team. A failure in one area compromises the entire system.
- Focus on three pillars. Build your strategy around (1) a secure, layered architecture (encryption, network isolation), (2) automated governance (policy-as-code, data lineage), and (3) a team with deep data security skills.
- Prioritize architecture and access control. Start with a Zero Trust mindset from day one. Use VPCs, end-to-end encryption, and granular IAM/RBAC to minimize your attack surface. A common failure is leaving security as an afterthought.
- Automate compliance and monitoring. Use tools to automatically classify sensitive data, track lineage, and detect anomalies. Manual processes cannot scale to handle petabyte-level data volumes and sophisticated threats.
- Hire for security from the start. Embed security expertise within your data and MLOps teams. A Data Engineer with a security focus is non-negotiable once your data operations mature.
Who this is for
This guide is for technical leaders responsible for data strategy and risk management:
- CTO / Head of Engineering: You need to build a scalable, secure data platform without slowing down product innovation. You are accountable for the architecture and the team that runs it.
- Founder / Product Lead: You are building an AI- or data-driven product and need to understand the security risks and costs involved. You need to ensure customer data is protected to maintain trust and business viability.
- Talent Ops / Procurement: You are tasked with hiring the specialized engineers needed to build and secure these complex systems. You need to know what skills to look for.
The Big Data Security Framework
Protecting petabytes of data from breaches, insider threats, and compliance missteps isn’t an IT problem; it’s a core business function. A single breach can lead to multi-million dollar fines under regulations like GDPR or CCPA, erode customer trust, and hand your competitive advantage to rivals.
A modern framework for big data security stands on three pillars:
- Secure Architecture: Your technical blueprint. This includes end-to-end encryption, strict network segmentation, and granular Identity and Access Management (IAM) to control who can access data.
- Scalable Governance: The rules of the road. This covers data classification, privacy compliance, and automated data lineage to trace information from source to use.
- Specialized Team: The human element. You need engineers with expertise in data security, MLOps, and secure pipeline development to implement and manage controls.
alt text: A diagram of the Big Data Security Framework, illustrating framework components: Architecture, Governance, and Team.
These pillars work together. Technology alone is never enough; it requires sound policies and skilled people to be effective.
Practical Examples of Secure Architectures
Abstract theory is useless. Here are two common, battle-tested architectural patterns you can use as a blueprint for your own stack.
Example 1: Secure Data Lake for Analytics on AWS
Data lakes are powerful but can become security nightmares if not properly configured. This architecture focuses on creating a secure perimeter and enforcing granular controls from the start.
Key Components and Their Security Roles:
- Network Isolation with VPC: All components, including Amazon S3 buckets and compute clusters, reside within a Virtual Private Cloud (VPC). VPC Endpoints ensure traffic between services never traverses the public internet, shrinking the attack surface.
- Encrypted Storage with S3: Data at rest must be encrypted. Enable server-side encryption (SSE-S3 or SSE-KMS) by default on all S3 buckets. Bucket policies should be configured to deny unencrypted uploads.
- Granular Access with AWS Lake Formation: AWS Lake Formation provides a central console to manage permissions at the database, table, or column level. This ensures a data scientist working on product analytics cannot access sensitive PII in the same data lake.
- Identity and Access Management (IAM): Use IAM roles with temporary, least-privilege credentials for all services and users. Enforce Multi-Factor Authentication (MFA) for all human access to the AWS console.
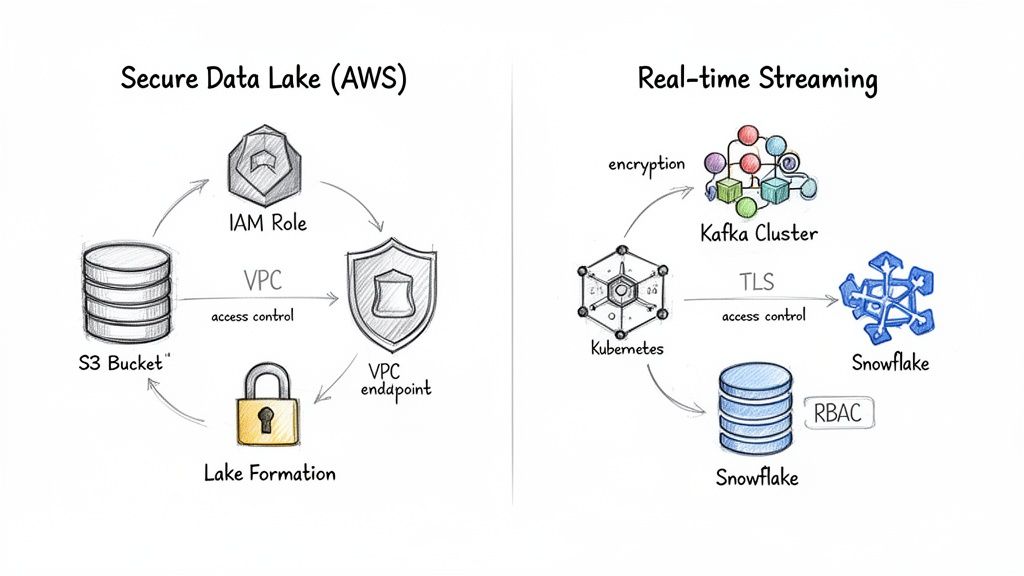
alt text: Diagram illustrating secure data lake architecture on AWS and real-time streaming with Kafka, Kubernetes, and Snowflake, highlighting security measures.
Example 2: Secure Real-Time Streaming with Kafka and Snowflake
For real-time use cases like fraud detection, securing the data stream is as critical as protecting the destination warehouse.
Key Components and Their Security Roles:
- Encrypted Transport with TLS: All data moving through your Apache Kafka cluster must be encrypted in transit using Transport Layer Security (TLS). This prevents eavesdropping on the data stream itself.
- Container Isolation with Kubernetes: Run the Kafka cluster on a platform like Kubernetes. Use Kubernetes Network Policies as an internal firewall to restrict communication, allowing only specific services (e.g., the ingestion API) to talk to Kafka brokers on designated ports.
- Secure Ingestion with Snowflake: Use key-pair authentication for the Snowflake Kafka Connector. Create a dedicated Snowflake user and role for the connector that has only
INSERTpermissions on target tables, adhering to the principle of least privilege. - Role-Based Access Control (RBAC) in Snowflake: Once data is in Snowflake, a robust RBAC model takes over. Create distinct roles for different user groups (data engineers, analysts). Analysts might only have access to sanitized or aggregated views, while a privileged role is required to see raw PII.
For a deeper dive, read our guide on designing secure pipelines for big data.
Deep Dive: Risks, Trade-offs, and Pitfalls
As data grows, so do risks. You must understand how threats operate to build an effective defense.
1. Data Privacy and Compliance Violations
Regulations like GDPR and CCPA have operational teeth. A "right to be forgotten" request requires you to surgically remove a user's data from immutable logs, analytics tables, and even trained ML models. This is impossible without impeccable data lineage tracking. Failure results in fines that can reach millions of dollars.
2. Expanded Cloud Attack Surface
A typical big data stack has dozens of interconnected cloud services—each a potential entry point. A single misconfigured S3 bucket, an overly permissive IAM role, or a public-facing API endpoint can compromise the entire pipeline. The global average cost of a data breach is now $4.45 million, according to the 2023 Cybersecurity Almanac. For data-intensive companies, that figure is much higher. Adopting a Zero Trust Architecture is no longer optional.
3. Insider Threats (Malicious and Accidental)
A disgruntled employee can cause deliberate damage, but an accidental leak is just as dangerous.
Mini-Case: The Accidental Credential Leak
- Situation: A junior data engineer hardcodes a database credential with write access into a script and commits it to a private GitHub repo.
- Mistake: Months later, the project is open-sourced, making the repository public. The old commit history is not scrubbed.
- Outcome: Automated scanners find the credential within minutes. An attacker gains access, exfiltrates customer data, and deploys ransomware. The breach goes undetected for weeks because logs show activity from a "valid" user.
This scenario highlights the need for the principle of least privilege. Grant every user and service the absolute minimum access required.
4. Data and Model Poisoning in AI Systems
Data poisoning occurs when an attacker subtly corrupts your training data to cause a model to misbehave. For example, slightly altering thousands of images could train a quality control model to approve defective products. The business impact is severe: financial loss from a compromised fraud detection model, brand damage from a biased recommendation engine, or safety risks from a faulty autonomous vehicle model.
Big Data Security Checklist
Use this checklist to audit your current security posture and identify immediate gaps. This helps connect risks to actionable controls and required team expertise.
This checklist isn't exhaustive but provides a solid starting point for aligning technical controls with your hiring strategy. An in-depth threat intelligence report can provide further context on emerging threats.
What to do next
- Conduct a 1-Hour Risk Audit. Use the checklist above with your engineering leads to identify your top three vulnerabilities. Focus on immediate, high-impact gaps.
- Map a 90-Day Security Roadmap. Based on the audit, define a realistic plan for the next quarter. Prioritize fixes that deliver the most risk reduction for the effort, like enforcing MFA or implementing default encryption.
- Perform a Skills Gap Analysis. Compare your roadmap against your current team's capabilities. If you lack in-house expertise in areas like cloud security, IAM, or secure MLOps, make a plan to hire or upskill. A strategic approach to information security recruitment is crucial.
Ready to build a more secure foundation for your data? ThirstySprout connects you with vetted data security and MLOps engineers who can join your team in days, not months. Find your expert today.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.