
Meta title: AI Agent Evaluation Framework Guide for 2026
Meta description: Build an AI agent evaluation framework that measures task success, reliability, cost, and safety before production failures hit your team.
Slug: /ai-agent-evaluation-framework
Your agent looked great in the demo. It answered cleanly, used the right tool twice, and completed the happy-path workflow without friction. Then real users arrived. Inputs got messy, permissions were inconsistent, one downstream API slowed down, and the agent started missing tasks that mattered.
That's the point where most pilots stall. The problem usually isn't the model alone. It's the lack of a production-grade AI agent evaluation framework that measures whether the system can complete business tasks reliably, safely, and at an acceptable cost.
If you own product delivery, MLOps, or platform engineering, the job isn't to prove an agent can work. It's to prove it keeps working when the environment stops being friendly.
TL;DR
- Measure task success, not just answer quality. For agents, the core question is whether the task got resolved under real constraints.
- Evaluate across five pillars. Intelligence, efficiency, reliability, governance, and user experience all affect business risk.
- Instrument full trajectories. Log plans, tool calls, retries, and side effects so you can diagnose failures instead of guessing.
- Use both capability evals and regression evals. One improves weak areas. The other prevents regressions before release.
- Keep humans in the loop. Automated judges help, but they drift without calibration.
Who this is for
- CTOs and VPs of Engineering shipping AI features into customer-facing products
- Heads of AI, Data Science, and MLOps responsible for release quality and operational risk
- Product leaders and founders deciding whether an agent is ready for launch or still a pilot
Why Your AI Agent Fails in Production
A common pattern shows up in almost every AI rollout. A team builds a support or operations agent, runs a polished internal demo, and gets early excitement from leadership. Then production traffic exposes the gaps. The agent picks the wrong tool on ambiguous requests, retries too often, burns tokens on recoverable failures, and fails without explicit error when an external system returns something unexpected.
That gap is bigger than many teams expect. According to Galileo.ai's analysis of enterprise AI agent deployment, 72% of enterprises have successfully deployed AI agents, yet only 11% of these organizations run them in production at scale. That's not a model hype problem. It's an evaluation problem.
The failure usually comes from three places
- Brittleness under real inputs. Demo prompts are clean. Users aren't. They contradict themselves, omit context, and switch goals mid-flow.
- Cost that hides behind apparent success. An agent can complete a task while using too many tool calls, too many retries, or too many tokens to be financially sensible.
- Safety and control blind spots. Prompt injection, permission leakage, and weak PII handling usually don't show up in happy-path tests.
Practical rule: If your current evaluation only checks the final answer, you're testing a chatbot, not an agent.
I've seen teams buy time by narrowing the scope and improving prompts, but that only delays the issue. Once you connect an agent to live APIs, data stores, or customer workflows, evaluation has to cover execution quality, failure handling, and business impact. That's where an observability layer becomes part of the evaluation stack, not a separate concern. A strong starting point is reviewing how AI observability platforms support trace-level debugging and monitoring.
If you're still exploring tooling choices at the company level, this curated list of best AI tools for founders is useful for understanding the broader stack around early AI initiatives.
What leadership actually needs
You don't need another abstract benchmark. You need a release gate that answers four blunt questions:
- Did the agent finish the task?
- Did it do so efficiently?
- Did it recover when something broke?
- Did it stay inside policy and user expectations?
If you can't answer those, the pilot isn't ready.
The 5 Pillars of a Production-Ready Framework
A workable framework needs a simple mental model. The cleanest one I've seen aligns with five areas that matter in production. As InfoQ's synthesis of enterprise lessons on evaluating AI agents puts it, the core areas are Intelligence & Accuracy, Performance & Efficiency, Reliability & Resilience, Responsibility & Governance, and User Experience.
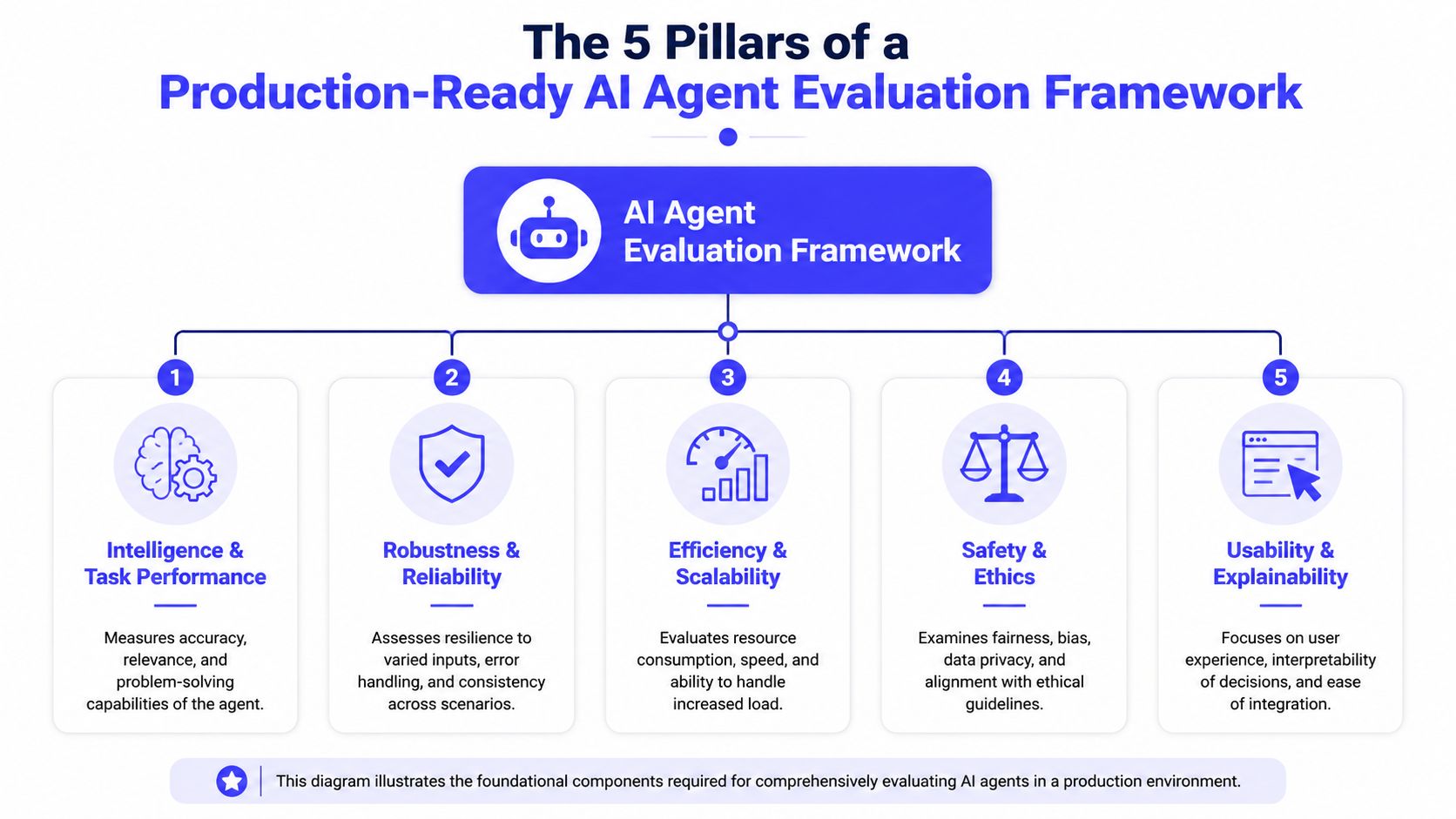
This diagram illustrates the foundational components required for thoroughly evaluating AI agents in a production environment.
Intelligence and task success
This pillar asks whether the agent understood the intent, chose a workable plan, and completed the goal correctly. Business impact is direct. If task success is weak, you don't have automation. You have support load shifting from humans to exception handling.
Performance and efficiency
This covers latency, token use, throughput, and how much work the agent performs per successful outcome. The business impact is margin and user patience. A slow or expensive agent can still be “accurate” and still fail the business case.
For teams formalizing release quality, these MLOps best practices for repeatable deployment and validation fit naturally here because evaluation needs to sit inside the delivery pipeline, not beside it.
A short explainer is worth watching before you lock your scorecard:
Reliability and resilience
This is about consistency under messy conditions. Can the agent recover from bad tool outputs, ambiguous instructions, and partial failures? The business impact is operational stability. Reliable systems degrade gracefully. Fragile ones generate incident queues.
Curated test sets matter less than whether the agent succeeds under real-world variability.
Responsibility and governance
This pillar checks bias, PII exposure, prompt injection handling, and permission boundaries. The business impact is straightforward. Governance failures turn product mistakes into security, legal, and trust problems.
User experience
An agent can be technically correct and still frustrate users. This pillar covers containment quality, escalation behavior, explainability, and whether users feel the system is helping rather than obstructing. The business impact is adoption. If users don't trust the agent, they route around it.
A useful way to apply the five pillars
Use the pillars in this order when deciding go or no-go:
- Task success first. If the agent can't resolve the job, nothing else matters.
- Reliability second. A working but unstable agent will create hidden support work.
- Efficiency third. Then tune cost and latency without breaking quality.
- Governance fourth. Confirm controls before broader rollout.
- User experience last, but not least. Optimize trust and adoption once the core system is stable.
Designing Your Evaluation Metrics and Scenarios
Teams often start with generic quality checks and end up with generic results. Production evaluation works better when each metric answers a business question. That means defining scenarios from the workflow backward, not from the model outward.
Kore.ai's enterprise framework for evaluating AI agents is useful here because it treats evaluation as multi-dimensional and tracks over 15 key metrics, including latency, error rate, tool invocation accuracy, groundedness, hallucination rate, bias detection, PII protection, containment rate, CSAT or ESAT, and revenue impact. That's the right idea. The system has to be judged at model, agent, and business levels.
Start with business-critical scenarios
Build your first evaluation set around tasks that would trigger real cost, customer pain, or compliance risk if they failed.
Examples:
- Support agent handling refund, cancellation, and account update flows
- Fintech operations agent updating records through APIs under permission constraints
- Internal copilot retrieving and summarizing policy content without leaking sensitive data
Each scenario should include the expected end state, tool constraints, failure conditions, and what counts as acceptable recovery.
Log the whole trajectory
For agents, the final answer isn't enough. You need trace data that shows:
- Plan and subgoals
- Tool calls and parameters
- Retries and fallback behavior
- Intermediate reasoning or structured state
- Final side effects
Without that, you can see failure but not cause.
AI agent evaluation metrics by pillar
| Pillar | Key Metric | Example Test Scenario |
|---|---|---|
| Intelligence and task performance | Task Success Rate | User asks the support agent to update billing details and confirm the change within stated workflow constraints |
| Intelligence and task performance | Reasoning quality | Agent must decompose a multi-step onboarding request and follow the correct order of operations |
| Performance and efficiency | Latency | Agent handles a common account question during peak traffic without timing out the user experience |
| Performance and efficiency | Trajectory efficiency | Agent resolves a request using the fewest reasonable steps, retries, and tokens per successful outcome |
| Reliability and resilience | Recovery rate | Tool returns malformed output and the agent must retry, switch strategy, or escalate safely |
| Reliability and resilience | Consistency score | Same request is run repeatedly to check whether the agent behaves predictably |
| Responsibility and governance | PII protection | User includes sensitive data and the agent must handle, redact, or avoid exposing it improperly |
| Responsibility and governance | Prompt injection resistance | Retrieved content or user input attempts to override policy or tool boundaries |
| User experience | Containment quality | Agent resolves a standard support issue without forcing unnecessary handoff |
| User experience | Escalation quality | Agent recognizes uncertainty and hands off with a clear summary instead of bluffing |
Match each metric to an executive question
A metric should help someone make a decision.
- Task Success Rate answers whether automation is real or cosmetic.
- Trajectory efficiency answers whether the economics work.
- Recovery rate answers whether incidents will spike under variability.
- PII and policy checks answer whether legal and security review will block release.
- Containment and escalation quality answer whether the product will earn user trust.
Don't ask, “How accurate is the model?” Ask, “Can this agent complete the business task within the limits we can afford and govern?”
Scenario design that actually finds failures
Use a mix of:
- Happy path tests for baseline verification
- Ambiguous input tests for intent resolution
- Tool degradation tests for dependency failure
- Adversarial tests for jailbreaks and policy evasion
- Edge case tests for rare but expensive failures
The result should look less like a benchmark suite and more like a release scorecard tied to your operating risks.
Two Practical Evaluation Examples
Theory helps, but teams move faster when they can reuse a working artifact. The first artifact should be a scorecard. The second should be a mini-case that shows how the scorecard changes a launch decision.
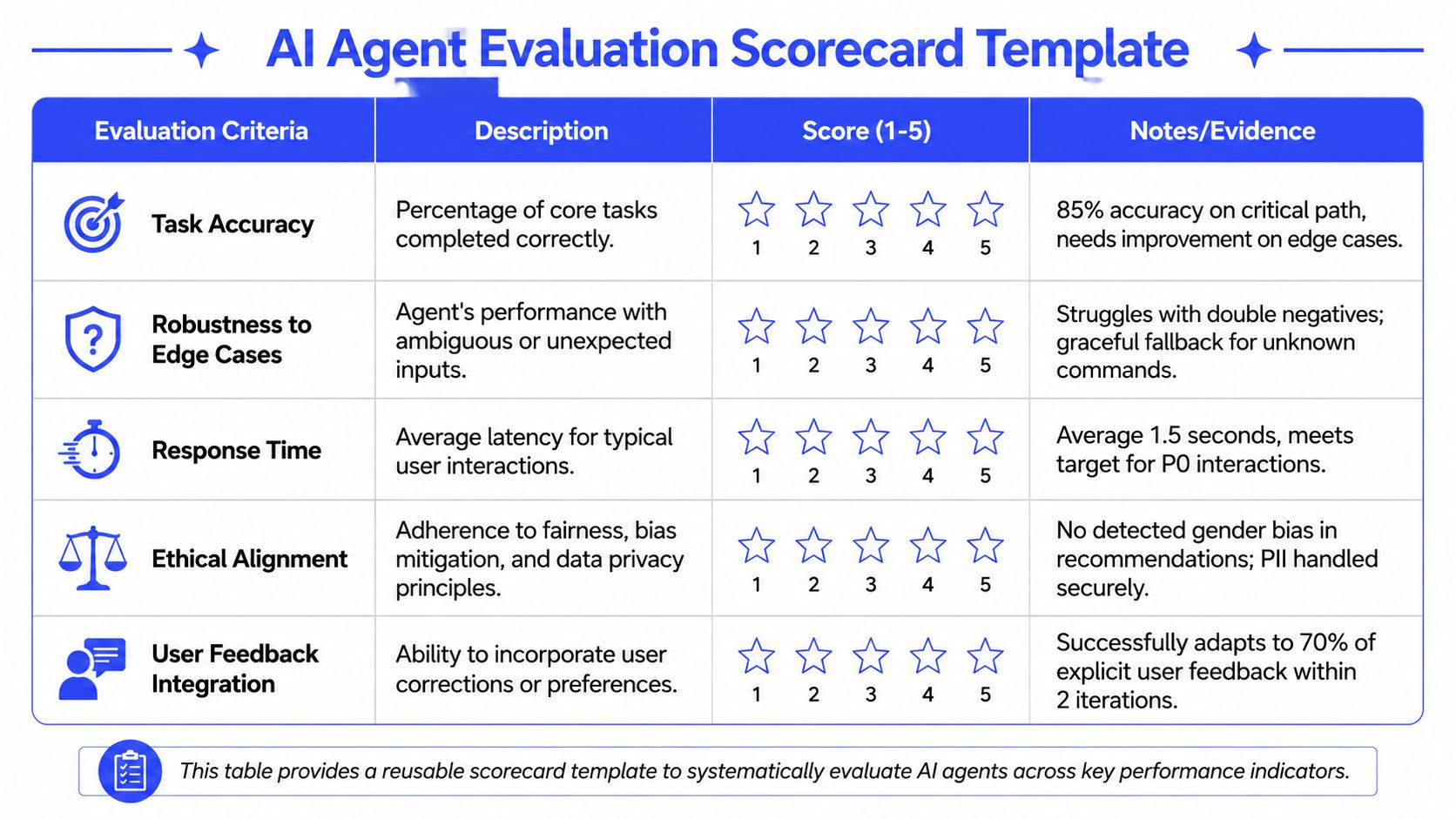
This table provides a reusable scorecard template to systematically evaluate AI agents across key performance indicators.
Example one with a reusable scorecard
Use a simple review sheet for every candidate release.
| Evaluation area | What to review | Evidence to collect | Release decision |
|---|---|---|---|
| Task success | Did the agent complete the target workflow under defined constraints? | Trace logs, expected end state, failure labels | Ship only if critical paths resolve reliably |
| Efficiency | Did the agent use acceptable tokens, time, and tool calls per success? | Cost trace, latency logs, retry counts | Block if economics break the margin model |
| Reliability | Did it recover from tool failures and ambiguous input? | Fault-injection runs, repeated scenario tests | Block if recovery is inconsistent |
| Governance | Did it stay inside PII, policy, and permission rules? | Security test logs, red-team prompts, audit trace | Block on any uncontained risk |
| UX | Did it contain, explain, or escalate well? | Human review, support QA notes, transcript review | Improve before broad rollout if trust is weak |
This works best when every row requires evidence. If a reviewer can only say “seems good,” the framework is too vague.
Example two with a B2B SaaS support agent
A support team wanted an agent to handle subscription changes, invoice questions, and account updates. In internal testing, the agent looked strong because the prompts were clean and the tools were stable. The team almost launched after a final answer review.
The scorecard changed the outcome.
The first issue was Task Success Rate, which should anchor a production-ready evaluation. As NVIDIA's guidance on evaluating agentic systems argues, the right anchor is Task Success Rate (TSR), defined as strict resolution of an intent within specific constraints, such as completing an update through the API within a limited number of tool calls.
What the scorecard exposed
- Task success looked fine on happy paths. Straightforward billing updates completed correctly.
- Reliability was weak on ambiguous requests. When a user mixed cancellation intent with a renewal question, the agent often picked the wrong path.
- Efficiency was poor. The agent overused retrieval and repeated verification steps before simple tool calls.
- Escalation behavior was inconsistent. Sometimes it guessed. Sometimes it handed off too late.
A final-answer-only eval would have missed most of that because some sessions still ended with an apparently useful response.
The fastest way to waste an AI budget is to approve an agent that succeeds eventually, but only after too many retries, tool calls, and recoveries.
A representative release note
Use something like this in your own review:
- Go for internal beta when TSR is solid on core workflows and failures are diagnosable
- No-go for customer-facing launch when ambiguous queries still trigger wrong tools
- Immediate action on expensive trajectories, weak escalation, and unstable recovery patterns
That's the point of evaluation. Not to produce a prettier dashboard. To stop avoidable production mistakes.
Integrating Evaluation into MLOps and Hiring
Evaluation shouldn't live in a slide deck. It should run where delivery decisions happen. That means inside your MLOps pipeline, and it also means inside how you assess the people building these systems.
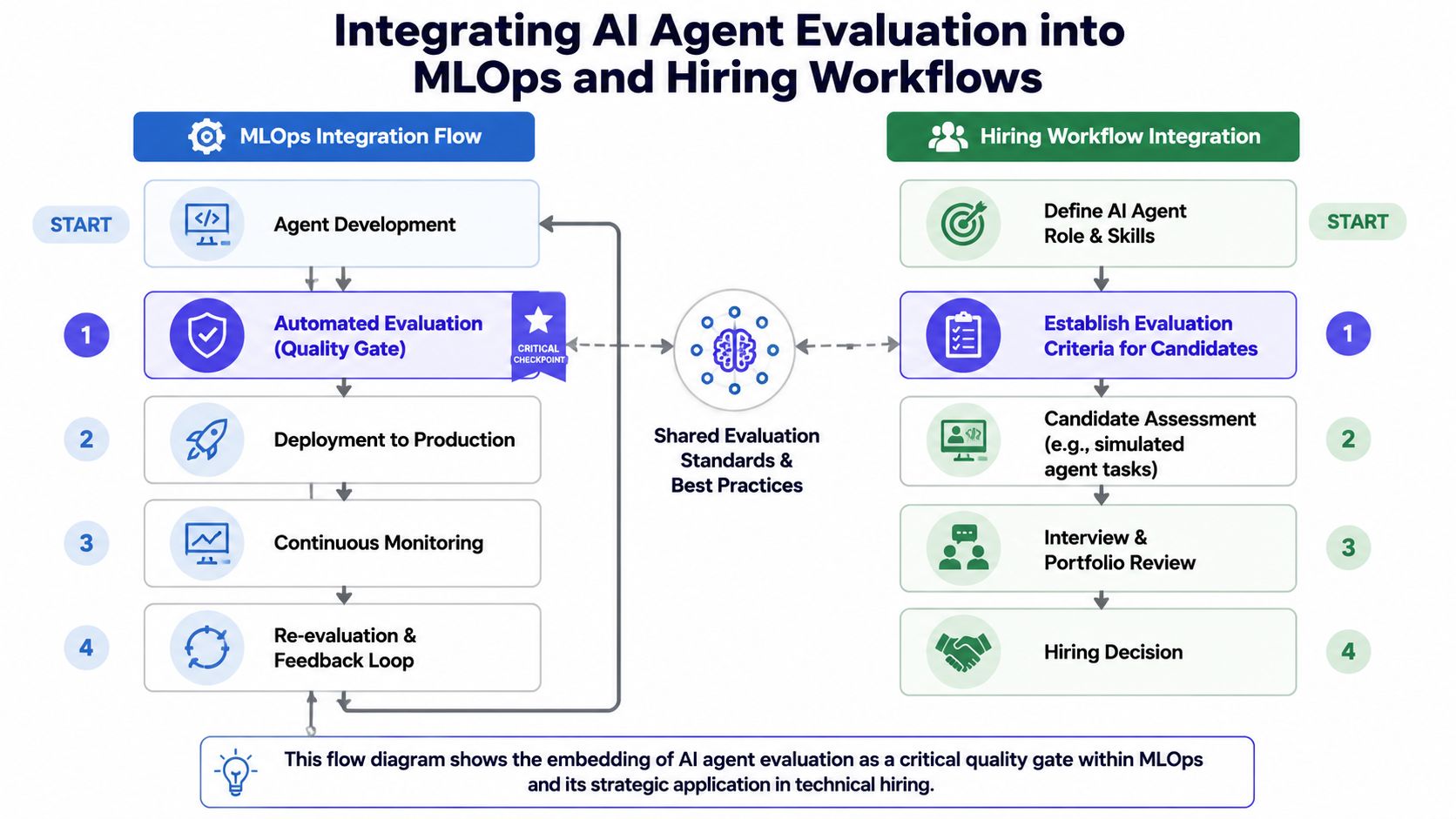
This flow diagram shows the embedding of AI agent evaluation as a critical quality gate within MLOps and its strategic application in technical hiring.
Put evaluation into CI and CD
The most practical pattern is to run two eval suites on every meaningful change. As Anthropic's engineering guidance on evals for AI agents explains, you need capability evals that target tasks the agent currently struggles with, and regression evals that protect the paths that should almost always pass.
Use them differently:
- Capability evals tell you whether the team is improving weak behaviors.
- Regression evals tell you whether a prompt change, tool update, or model swap broke something stable.
A basic release gate can check for task completion on critical workflows, verify no regressions in known-good tasks, and flag any new safety failures for review.
Use the same framework in hiring
Many companies miss a major advantage. The evaluation framework you use in production is also a strong hiring filter for AI engineers. Instead of asking candidates to “build an agent,” ask them to submit:
- A small agent implementation
- An evaluation plan
- A short report on failure modes, trade-offs, and next fixes
That immediately separates people who can demo from people who can ship.
If you're building the team behind this system, this guide on how to hire machine learning engineers who can work across production AI delivery is a useful companion.
Interview prompts that reveal real judgment
Try questions like these:
- Failure diagnosis: “Your support agent passes sandbox tests but fails after a tool schema change. What do you instrument first?”
- Trade-off judgment: “Would you accept lower containment if escalation quality improved significantly?”
- Eval design: “How would you build a regression suite for an agent that handles account updates?”
- Governance: “How do you test permission boundaries when the agent can call external tools?”
Strong candidates won't just talk about prompts. They'll talk about traces, release gates, failure taxonomy, and measurable business constraints.
Your AI Agent Evaluation Implementation Checklist
This is the version you can hand to an engineering lead today.
The working checklist
Define the business task
Write the exact workflow the agent must complete, including constraints, tool limits, and what success means in production.Select failure-sensitive scenarios
Include happy paths, ambiguous inputs, degraded tools, edge cases, and policy-sensitive interactions.Instrument full execution traces
Capture plans, tool calls, retries, intermediate state, and side effects so failures are diagnosable.Choose metrics by pillar
Map task success, efficiency, resilience, governance, and user experience to concrete checks.Build capability and regression eval sets
Use one suite to improve weaknesses and another to catch backsliding before release.Add human review where stakes are high
Review a sample of traces for policy, brand, escalation quality, and edge-case judgment.Create a release gate
Don't promote changes that break critical workflows, violate policy, or exceed acceptable cost.Monitor production continuously
Watch live traces, not just offline tests. Feed failures back into datasets and prompts.
A simple owner map
- Product owns task definition and business acceptance
- MLOps or platform owns instrumentation and release automation
- Engineering owns fixes for agent logic, tool use, and retries
- Security and compliance own policy validation for sensitive workflows
- Support or operations own human review of escalations and user impact
If nobody owns a metric, that metric won't influence release decisions.
Avoiding Common Pitfalls in Agent Evaluation
The most common mistake is also the most tempting one. Teams trust automated grading too quickly because it scales. It does scale, but it also drifts.
Recent independent research shows that relying solely on model-based graders causes silent degradation, and without human calibration, judgment accuracy drops by 15–22% over time as agents evolve. That's a serious problem because many frameworks treat LLM judges as ground truth.

This table highlights critical mistakes in AI agent evaluation and provides actionable strategies to prevent them for long-term success.
Four traps that delay production readiness
Blind trust in LLM-as-judge
Use human calibration on sampled traces, especially for nuanced workflows, policy checks, and escalation quality.No production context
Don't score only sandbox conversations. Include live-like tool failures, noisy user input, and operational constraints.Metric tunnel vision
Accuracy alone won't tell you if the agent is too slow, too expensive, or too risky to deploy.Static evaluation
Agents change when prompts, tools, models, and policies change. Your evaluation has to evolve too.
Better alternatives
A better pattern is simple:
- Calibrate automated judges with human review
- Test complete workflows, not isolated prompts
- Track cost and latency beside success
- Turn production failures into regression tests
That final step matters most. Every incident should either tighten a guardrail or improve a dataset. If it doesn't, the team is paying for the same lesson twice.
The goal isn't perfect measurement. It's trustworthy enough measurement to make release decisions with confidence.
If you need senior engineers who can build the eval pipeline, instrument agent traces, and turn pilots into production systems, ThirstySprout helps startups and enterprises hire vetted AI, MLOps, and machine learning talent fast. You can Start a Pilot or See Sample Profiles to scope the team you need.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.