
TL;DR: Your Quick Guide to Hiring Data Scientists
- Define by Problem, Not Tools: Start with the business problem you need solved (e.g., "reduce churn by 15%"). This dictates the exact skills you need, like survival analysis and XGBoost, preventing generic "unicorn" job posts.
- Use a Practical Take-Home Test: Ditch abstract whiteboard puzzles. Assign a 2–4 hour take-home project using a real (but sanitized) dataset. Evaluate it with a clear rubric focused on code quality, modeling approach, and business interpretation.
- Source Beyond LinkedIn: Find top talent where they work. Look for active contributors on GitHub, high-ranking competitors on Kaggle, and authors at conferences like NeurIPS. Your outreach must reference their specific work.
- Onboard for a Fast Win: Structure a 90-day plan focused on a small, achievable "starter project." This helps new hires learn the ropes, build confidence, and deliver tangible value quickly, accelerating their impact.
- Think Globally and Remotely: Don't limit your search to a single city. The best person for the job probably doesn't live within commuting distance. Embracing a remote-first approach gives you access to a far larger, higher-quality talent pool.
Who this is for
This guide is for you if you are a:
- CTO, Head of Engineering, or Staff Engineer responsible for hiring data scientists who can ship production-ready models and directly impact business metrics.
- Founder or Product Lead trying to scope a data science role, set a realistic budget, and build a team to power new AI features.
- Talent Ops or Technical Recruiter tasked with finding, vetting, and closing elite data science candidates in a competitive market.
This is a playbook for operators who need to hire the right data scientist in weeks, not months.
A 4-Step Framework for Recruiting Top Data Scientists
Hiring a data scientist today is a world away from what it was just a few years back. The role has fundamentally shifted from a research-heavy, academic position to a product-focused engineering discipline. The problem is, most companies are still using outdated recruiting strategies, chasing PhDs and publication lists while completely missing the practical skills that actually create business value.
This mismatch leads to a hiring cycle that’s painful, slow, and often goes nowhere.
Alt text: Illustration of a hiring bottleneck funnel reducing many candidates to slow output and delayed time-to-market.
Every week that critical data science role sits empty is another week a competitor is shipping new AI features. The costs add up fast: delayed time-to-value, mounting opportunity cost, and team burnout. To break this cycle, you need a precise, repeatable process.
Here is the 4-step framework we use at ThirstySprout:
- Define the Role by Business Problem: Translate a specific business need into a technical skills matrix.
- Source Talent Based on Demonstrated Work: Find candidates on platforms like GitHub and Kaggle, not just LinkedIn.
- Vet with a Practical Take-Home Assignment: Test for real-world problem-solving skills, not abstract theory.
- Onboard for a Quick Win: Structure the first 90 days around a tangible starter project to accelerate impact.
Practical Examples of the Framework in Action
Theory is great, but execution is what matters. Here are two real-world examples of how to apply this framework to find the exact data scientist you need.
Example 1: Creating a Job Spec for a Churn Prediction Role
- Business Problem: "We need to cut customer churn by 15% in the next six months."
- Required Skills: This requires expertise in time-series and survival analysis, plus a solid background in building classification models like XGBoost. They’ll need strong SQL to shape user activity data and Python to build the model.
- Resulting Skills Matrix: This becomes your scorecard for every candidate, ensuring objectivity.
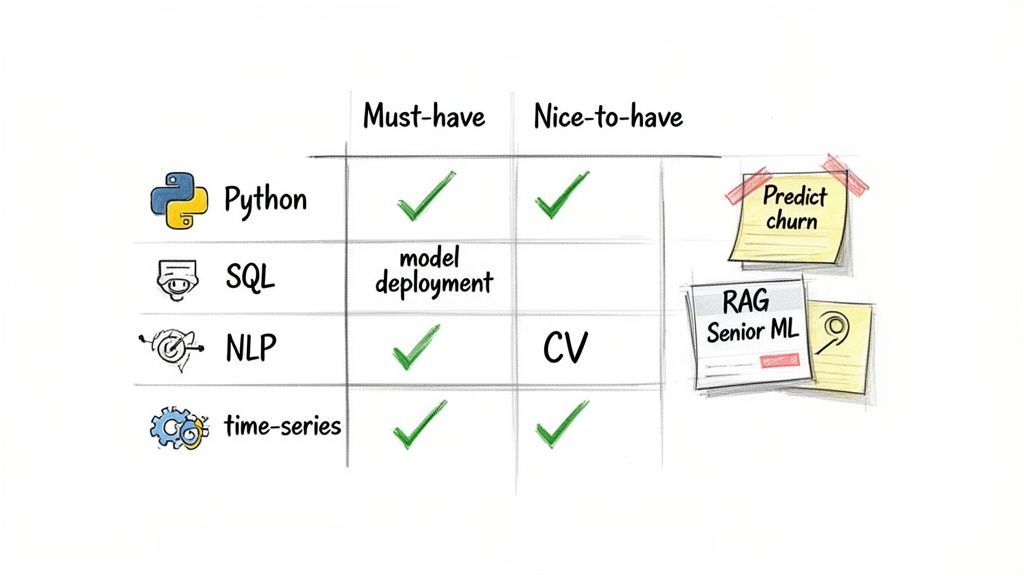
Alt text: Data scientist skills matrix outlining must-have and nice-to-have proficiencies like Python, SQL, and NLP for a churn prediction role.
Why this works: It connects every technical requirement back to its business impact, forcing you to ask why you need a certain tool. This stops you from just adding trendy-but-irrelevant tech to the job description.
Example 2: Designing a Take-Home Test for a Sentiment Analysis Role
- Business Problem: "We need to understand the sentiment of customer reviews to prioritize product fixes."
- The Prompt: Build a baseline sentiment analysis model for customer reviews.
- Dataset: Provide a simple, clean CSV file with two columns:
review_textandrating(1-5 stars). - Instructions: "Your goal is to build a simple model that classifies reviews as positive, negative, or neutral. Please submit a Jupyter Notebook that includes your data exploration, model training, and a brief evaluation. We're looking for a clear, well-documented approach and are more interested in your thought process than a perfectly tuned model. Please spend no more than 3-4 hours on this assignment."
Why this works: This assignment tests what truly matters: Can they clean data? Can they choose a reasonable baseline model? Can they interpret the results and explain their choices? It directly assesses the skills that deliver day-to-day impact.
Deep Dive: Sourcing, Vetting, and Onboarding
With a clear role definition and practical examples, let's dive into the trade-offs and details for each step of the hiring process.
Step 1: Source Where Top Talent Lives
The best data scientists aren't scrolling through job boards. To hire them, you must go find them based on their demonstrated work.
- GitHub Repositories: Look for contributors to well-known open-source libraries like Scikit-learn or Hugging Face Transformers. A well-maintained personal project that solves a unique problem is one of the strongest signals you can find.
- Kaggle Competitions: Top-ranked users on Kaggle have proven they can build high-performing models under pressure.
- Academic Conferences: Authors presenting at premier conferences like NeurIPS are defining the future of the field.
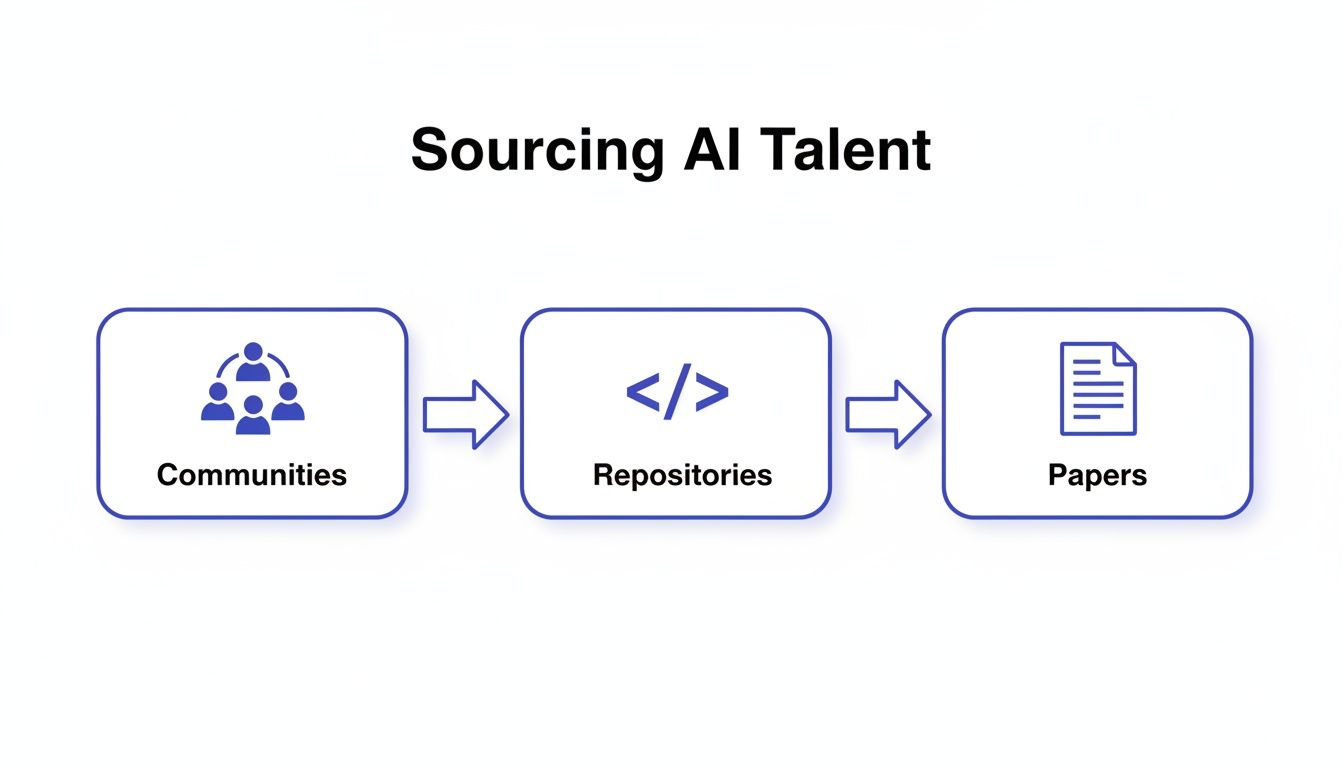
Alt text: Flowchart illustrating the process of sourcing AI talent through communities, repositories, and academic papers.
Your outreach must be hyper-personalized. A great message feels less like a pitch and more like a conversation starter between two experts. It should reference their specific work and connect it to a compelling problem you're solving.
Step 2: Vet for Practical Skills, Not Theory
Generic brain teasers and abstract whiteboard problems are awful predictors of on-the-job success. Your vetting process must mirror the actual work they’ll be doing.
A well-designed interview process acts as a series of increasingly fine filters:
- Brief Technical Screen (30–45 mins): A sanity check on core competencies like Python, SQL, and basic probability. It's a filter, not the main event.
- Practical Take-Home Assignment (2–4 hours): The heart of the assessment. Give them a small version of a real problem.
- Systems Design & Results Review (60–90 mins): The candidate walks you through their take-home project, followed by a collaborative discussion about how they'd scale their solution.
To keep evaluations fair, you need a scorecard. A rubric removes subjectivity and forces you to focus on the criteria you defined upfront.
Take-Home Assignment Evaluation Rubric
Step 3: Craft an Offer and Onboard for Impact
In this market, assume your top candidate has multiple offers. A compelling offer is more than just a salary number.
- Competitive Compensation: This is table stakes. Be transparent about your philosophy (e.g., location-based bands).
- Meaningful Equity: Frame it in terms of potential value and genuine ownership.
- A Real Growth and Learning Budget: A dedicated budget of $2,000–$5,000 for conferences like PyCon and specialized courses shows you're serious about their development.
- The Right Tools: Access to powerful GPUs and a solid MLOps platform like Kubeflow or MLflow can be a huge selling point.
Getting the offer signed isn't the finish line. The first 90 days are make-or-break. A structured onboarding plan helps new hires score a tangible win quickly.
Checklist: 90-Day Onboarding Plan for Data Scientists
This plan is all about quick integration and empowering your new hire to deliver something meaningful, fast.
Phase 1: Foundation (Days 1–30)
- Day One Access: All system, data, and code repository access is ready before they start.
- Meet Stakeholders: Schedule 1-on-1s with key people in product, engineering, and the business.
- Define the "Starter Project": Assign a small, well-scoped project (e.g., "Analyze feature adoption data from our last product launch").
- Assign a Buddy: Pair them with a senior team member for guidance.
Phase 2: Execution (Days 31–60)
- Deep Dive on Project: The new hire is now heads-down on their starter project.
- Set a Weekly Cadence: Establish regular, focused check-ins to unblock them and provide feedback.
- Present Early Findings: Have them share progress with a small, friendly group to build confidence.
Phase 3: Impact (Days 61–90)
- Deliver the First Win: The starter project is formally presented to stakeholders. Celebrate it.
- Hold a 90-Day Review: Discuss progress, the early win, and set goals for the next quarter.
- Graduate to a Core Project: They are now ready to tackle a more complex, business-critical initiative.
What to Do Next
- Define Your Next Hire's Business Problem: Before you write a single line of a job description, write one sentence defining the exact business problem they will solve in their first six months.
- Create a Skills Matrix: Use our template to build a practical scorecard that maps technical skills directly to business impact.
- Start a Pilot with ThirstySprout: Skip the noise and connect directly with top-tier, vetted AI talent. We match you with senior data scientists and ML engineers who have a proven track record of shipping production systems.
Ready to start your pilot in as little as two weeks?
Learn more and see sample profiles at ThirstySprout
References
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.