
You’re probably here because your team already has some security coverage, but it no longer matches your risk.
Maybe you have cloud firewall rules, endpoint protection, and vendor alerts. Maybe an engineer built a packet sniffer script during a sprint. But now your product is handling more customer traffic, more APIs, more internal services, and more ways for something abnormal to hide in plain sight. At that point, a python intrusion detection system stops being a side project and becomes an engineering program.
That’s where practical implementation often falters. The internet is full of Python IDS demos, but many are built for learning, not operations. The University of Florida Career Connections Center notes that existing Python IDS tutorials often focus on basic prototype implementations such as short projects for detecting SYN floods or port scans, while leaving out production concerns like scale and MLOps integration for startup technical leaders (University of Florida overview of simple Python IDS projects).
Your Python IDS Plan in 3 Bullets
If you’re a CTO, Head of Engineering, or founder making a build decision in the next few weeks, keep the plan simple.
- Start with a narrow detection scope: Begin with one traffic boundary that matters, such as public API ingress or east-west traffic around sensitive services. Pair a few explicit rules with lightweight anomaly detection instead of trying to model your whole network on day one.
- Treat the first release as an operational pilot: Your first milestone isn’t “build a model.” It’s “generate alerts the team can review without losing trust in the system.” That means logging, triage workflow, ownership, and escalation path matter as much as model choice.
- Optimize for false positive control, not leaderboard accuracy: A prototype that looks great on a benchmark but floods Slack or PagerDuty is a failed deployment.
- Staff for operations early: A production Python IDS needs application knowledge, ML judgment, and deployment discipline. If those sit in different people’s heads, you need a clear owner.
- Use outside material selectively: If you’re mapping broader detection posture before you commit architecture, this overview of advanced threat detection is useful for framing where IDS fits relative to other controls.
Who should use this approach
This is for teams that need to decide quickly whether to build, extend, or pilot a Python-based IDS.
It fits best when you have:
- A growing SaaS or fintech stack with enough traffic that manual log review isn’t workable
- An engineering team that can ship infrastructure but not a dedicated in-house detection engineering function yet
- A need for incremental rollout instead of a multi-quarter security transformation
What usually works
A practical first version of a python intrusion detection system usually combines three layers:
- Packet or flow capture
- A small set of deterministic checks
- A reviewable anomaly pipeline
That combination gives you early signal, fast debugging, and a path to improve over time.
Practical rule: If your team can’t explain why an alert fired, your IDS isn’t ready for production, no matter how strong the model metrics look.
What usually doesn’t
Teams lose time when they start with the hardest part first.
Common mistakes:
- Training before baselining: If you don’t understand normal traffic by service, environment, and time pattern, your model will learn noise.
- Overbuilding deep learning too early: Complex models can help later, but they slow debugging when the team is still deciding what should count as suspicious.
- Ignoring alert consumers: Security signal without triage ownership turns into ignored notifications.
A 4-Phase Framework for Building Your IDS
A production Python IDS is easier to manage when you break it into four phases with clear outputs.
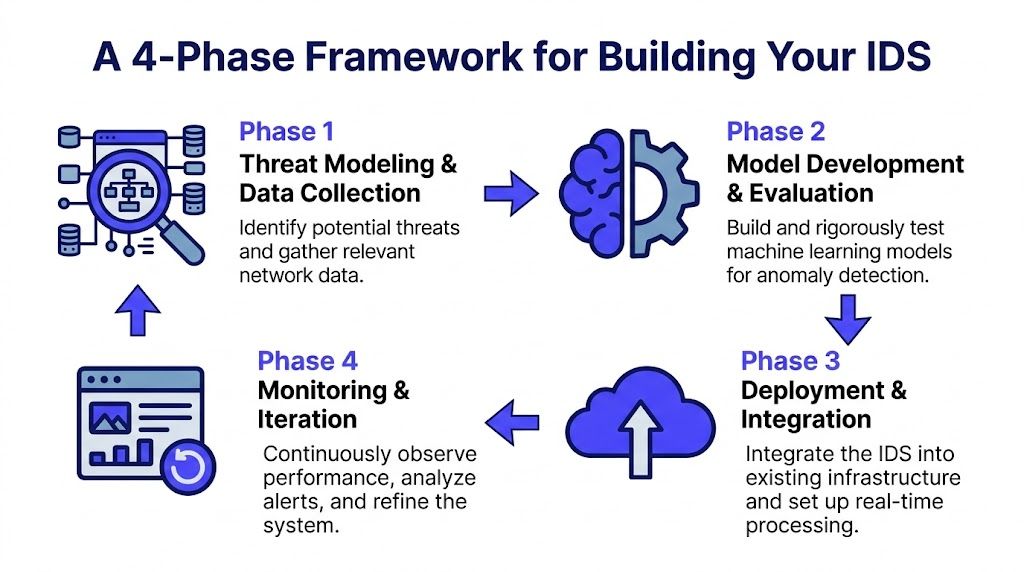
Phase 1 Threat modeling and scoping
Don’t start with code. Start with exposure.
Ask which traffic matters most to the business:
- Public ingress: API gateways, login flows, checkout paths, admin routes
- Sensitive internal paths: service-to-service calls around payments, auth, and data stores
- Operational surfaces: CI runners, bastions, observability agents, and batch workers
The goal is to decide where the IDS can create business value fastest. Typically, that means choosing a boundary where bad behavior is costly and normal behavior is relatively stable.
A simple scoping worksheet should answer:
- What are we protecting
- What attack patterns matter first
- What telemetry already exists
- Who reviews alerts
- What action is allowed automatically
This is also where you decide whether you’re building a packet-focused system, a flow-focused system, or a hybrid. Packet-level visibility gives more detail. Flow-level summaries are easier to store, reason about, and operationalize.
Pick one boundary, one owner, and one alert destination for the pilot. Broad coverage can come later.
Deliverables for Phase 1
| Output | Why it matters |
|---|---|
| Threat model | Keeps the project tied to actual risk |
| Telemetry inventory | Prevents surprises during implementation |
| Pilot boundary | Limits scope so the team can ship |
| Triage owner | Avoids orphaned alerts |
Phase 2 Data collection and feature engineering
Once scope is set, you need clean, consistent telemetry.
That usually means collecting packet or flow data, enriching it, and producing features your rules or models can use. Typical features include duration, protocol behavior, service patterns, byte counts, flags, connection frequency, and timing characteristics.
This phase decides whether your system becomes useful or noisy.
A sound data pipeline should do the following:
- Normalize categorical values: protocol and service labels must be consistent
- Align timestamps: delayed or skewed events will break sequence logic
- Separate training and evaluation windows: otherwise you’ll leak patterns and overestimate performance
- Label what you can, baseline what you can’t: most real environments have incomplete labels, so operational baselines matter
If you’re using benchmark datasets at all, use them to test implementation mechanics, not to prove readiness for your environment. The benchmark may help you verify feature pipelines and model APIs. It won’t replace your own traffic history.
A minimal feature set that’s actually useful
Start small. For many teams, a first pass includes:
- Connection metadata
- Request rate by source or service
- Byte and packet distribution
- Protocol flags
- Burstiness over short windows
- Repeated access patterns
That’s enough to support both heuristics and baseline ML without creating a giant feature store project.
Phase 3 Model development and evaluation
Leaders often ask the wrong first question. They ask which algorithm is best.
The better question is which model family your team can debug, deploy, and maintain.
For a first production pass, you usually have three choices:
Rules and heuristics
These are best when you already know specific suspicious behaviors and want fast deployment.
Pros:
- Easy to explain
- Fast to test
- Simple to tune with operations feedback
Limits:
- Weak on novel patterns
- Can become brittle as traffic changes
Classical machine learning
This is often the strongest starting point for a Python IDS team that wants better generalization without deep infrastructure overhead.
A GeeksforGeeks implementation using Logistic Regression on the KDD Cup 1999 intrusion dataset reported 99.36% train accuracy and 99.36% test accuracy (GeeksforGeeks Python IDS example). That result shows how quickly Python tools like pandas and scikit-learn can produce a capable baseline. It does not remove the need for production tuning.
Why this path works:
- Good iteration speed
- Clearer feature attribution
- Lower operational burden than deep sequence models
Hybrid models
When you need better coverage across known and less obvious behavior, hybrid architectures become attractive.
Research summarized in a St. Cloud State University thesis describes a hybrid methodology that stacks Random Forest, XGBoost, and LSTM with stratified cross-validation. It reports 99.5% to 99.95% accuracy on KDD Cup’99, compared with 96% for SVM, and notes false positives reduced from 2% to 5% to under 0.5%. The same summary notes CNN-LSTM hybrids hit 98.80% accuracy on benchmark data (St. Cloud State hybrid IDS thesis).
Those numbers are useful for one decision only. They justify testing hybrid models when your threat surface and traffic complexity are high enough to warrant the extra engineering.
They do not mean you should start there automatically.
Phase 4 Deployment and in-life monitoring
A real Python IDS isn’t a notebook. It’s a service.
The deployment shape that works for most product teams looks like this:
- Capture layer for packets or flows
- Transport layer for buffering and stream handling
- Inference service for rules and model scoring
- Alerting layer tied to incident workflows
- Observability and retraining path for ongoing tuning
A University College London dissertation outlines a 7-step methodology for ML-based anomaly detection IDS, including real-time deployment with Kafka/ELK for streaming and PyShark for parsing (UCL dissertation on ML-based IDS deployment). That’s the right mental model. Deployment skill matters as much as model skill.
What to monitor after launch
Once live, review more than detections.
Track:
- Alert usefulness: do operators close alerts as real issues, harmless anomalies, or unclear events
- Feature stability: did traffic shape change after product releases
- Latency and backpressure: is inference keeping up with traffic
- Threshold drift: are old cutoffs now producing junk
A Python IDS that never gets retrained, retuned, or re-baselined will slowly turn into a confidence problem for the whole team.
Exit criteria for the pilot
Before broadening rollout, confirm:
- The alert stream is understandable
- The team knows who owns tuning
- Model and rules can be updated safely
- The pipeline survives real traffic bursts
- The system produces evidence useful for investigation
If those aren’t true yet, expanding coverage just multiplies the pain.
Practical Examples Architecture and Model Scorecard
A CTO usually asks the wrong first question here. The question is rarely which model has the best benchmark result. The useful question is which design your team can operate at 2 a.m. without dragging security, platform, and data engineering into a weekly tuning war.
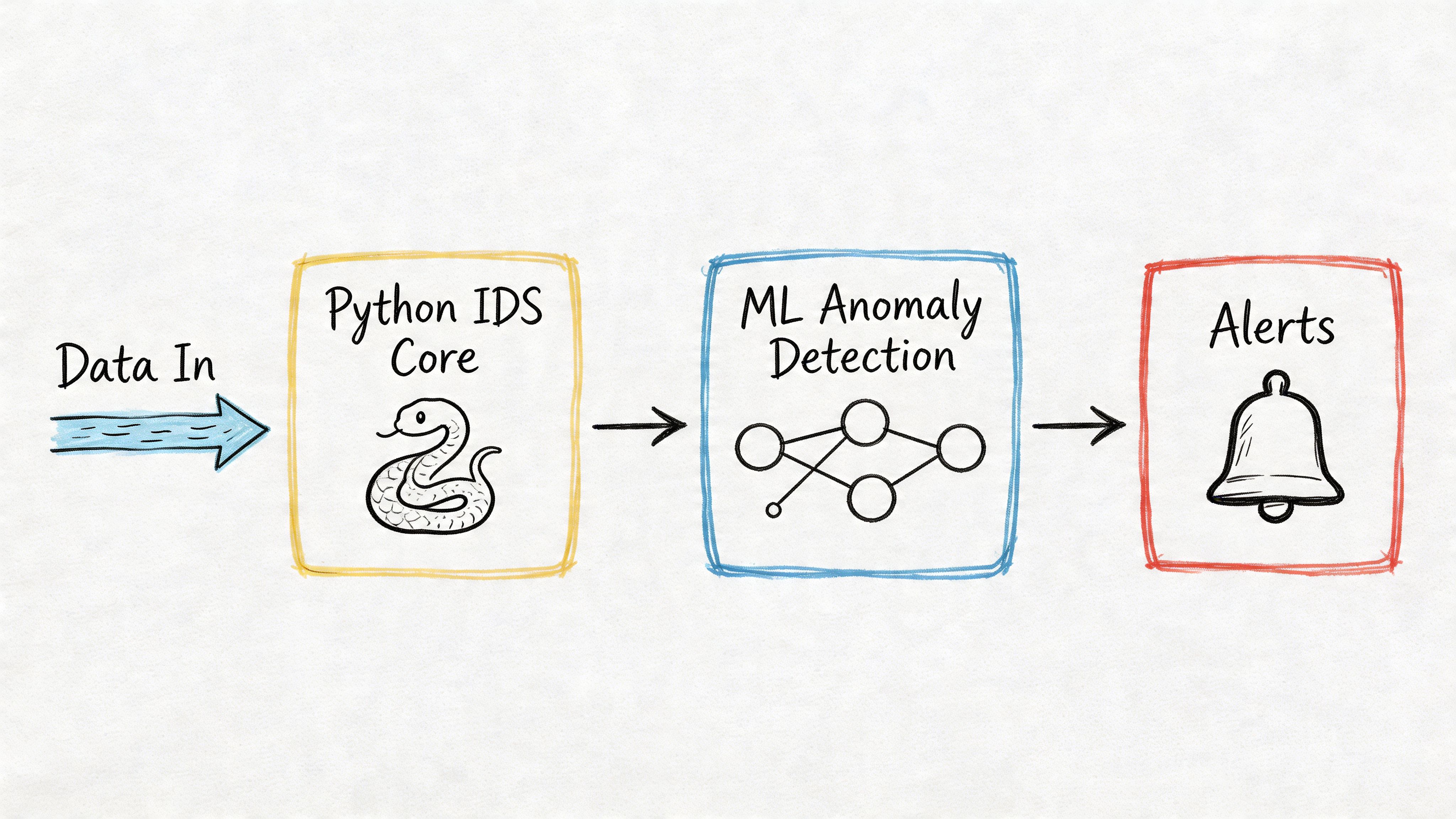
Example 1 A real-time streaming architecture
A practical first architecture is usually a hybrid. Rules handle obvious abuse patterns. A model scores the gray area where static thresholds break down. That split keeps the first release explainable while giving the team room to improve detection quality later.
A common setup looks like this:
- Capture: Scapy or PyShark collectors observe selected interfaces or mirror ports
- Buffering: Kafka absorbs traffic spikes and separates packet capture from downstream scoring
- Scoring service: a Python API, often built with FastAPI, applies deterministic rules before model scoring
- Storage: alerts and supporting context flow into Elasticsearch or another searchable store
- Notification: Slack, PagerDuty, or ticketing receives filtered alerts with severity and reason codes
- Feedback loop: analysts, SREs, or incident responders tag alerts so thresholds and features can be adjusted
The feedback loop is the expensive part. It needs owner time, triage discipline, and enough context in each alert for a human to judge whether the system was right. Without that, teams collect detections but do not improve them.
If you already run anomaly pipelines in adjacent systems, the same habits apply here. Baseline normal behavior, watch for drift, and keep feature generation reproducible. The MLOps practices that keep detection pipelines maintainable matter as much as the model choice because IDS work fails operationally long before it fails mathematically.
If the IDS cannot preserve packet metadata, decision reason, and investigation breadcrumbs, the alert will slow the responder down instead of helping. This guide from CloudOrbis on event logging strategy is a useful companion for designing retention, traceability, and audit context.
Example 2 Heuristic-first versus ML-first scorecard
A small Scapy-based Python IDS project shows the appeal of heuristics clearly. It flags suspicious traffic using simple thresholds such as oversized packets and repeated packet-size patterns associated with flood behavior or scans (LakshayD02 Scapy IDS project). That approach is blunt, but operations teams can inspect it, challenge it, and tune it quickly.
The better choice depends less on data science ambition and more on staffing reality.
| Option | Best fit | Strengths | Weaknesses | Good first milestone |
|---|---|---|---|---|
| Heuristic-first IDS | Teams with limited labeled data and an immediate visibility gap | Fast to ship, easy to explain, low debugging overhead | Misses subtle behavioral changes, requires ongoing threshold maintenance | Alert on a narrow set of obvious suspicious patterns |
| ML-first IDS | Teams that already have stable telemetry, feature pipelines, and review capacity | Better at surfacing weaker signals and non-obvious deviations | Harder to interpret, heavier data pipeline work, more analyst review load | Run scored alerts in parallel and compare operator feedback |
| Hybrid rollout | Teams that need early coverage without locking themselves into static rules | Rules catch known bad behavior, ML helps prioritize uncertain cases | More components to own, clearer team boundaries required | Put rules in production and keep ML in shadow mode until alert quality is proven |
For leadership, the hybrid path is usually the safest first investment. It gives security a usable alert stream, gives platform teams a bounded service to run, and gives data teams time to prove that model output improves triage instead of adding noise.
A config sketch for a first release
Use this as a planning artifact, not copy-paste production code.
- Collector: PyShark on monitored interfaces
- Rules: oversized packet checks, repetitive-size burst checks, protocol flag anomalies
- Inference API: FastAPI endpoint for batch scoring
- Queue: Kafka topic per traffic boundary
- Alert routing: Slack for medium severity, incident platform for high severity
- Storage: searchable event log with packet metadata and decision reason
A first release should answer one operator question clearly: why did this alert fire?
If your team cannot answer that in one screen, hold the model work, tighten the evidence trail, and reduce scope. That choice usually saves a quarter of avoidable rework.
Production Pitfalls and Performance Trade-offs
At 2:00 a.m., the question is rarely whether the classifier looked good in a notebook. The question is whether the security lead trusts the alert, whether the platform team can trace why it fired, and whether anyone can tune it without breaking the pipeline.
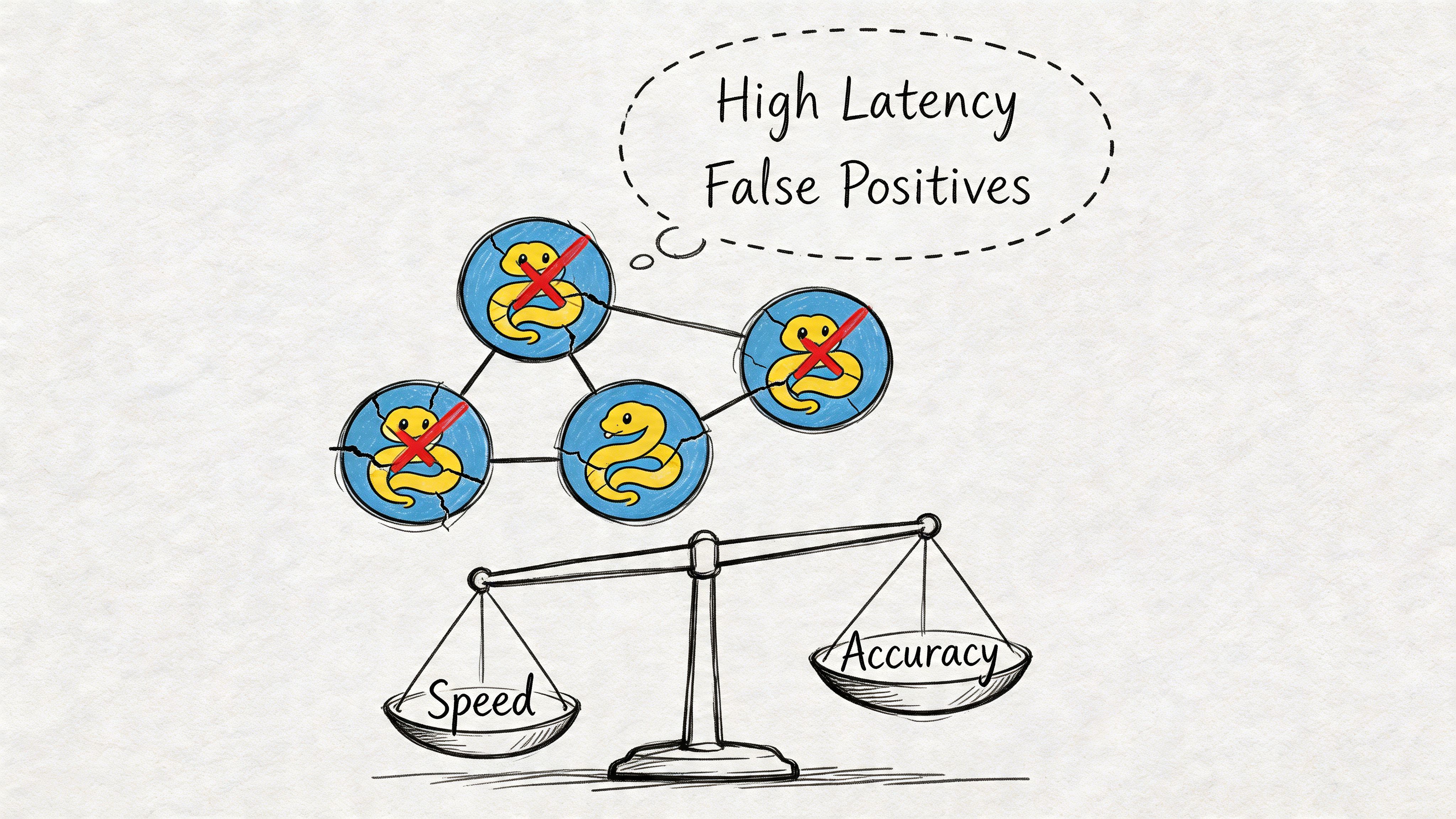
High test accuracy does not mean low operational cost
Many first-time IDS projects stall because leadership approves the model based on evaluation metrics, then discovers the actual bill arrives in analyst time, paging noise, and exception handling.
A model with strong offline performance can still create an unusable queue if it flags too many benign events, produces weak evidence, or routes alerts without clear severity boundaries. For a CTO, that changes the business case fast. The system stops looking like a security multiplier and starts looking like a staffing problem.
Teams that run IDS well usually judge it on four production measures:
- False positive rate at real traffic volume
- Alert explainability for analysts and incident leads
- Escalation quality across severity levels
- Review capacity for the people who own triage
A model that looks good in validation and creates noisy on-call rotations is still a failed release.
Drift is a delivery problem, not only a data science problem
Traffic changes every time the company ships something meaningful. New customer integrations, service mesh changes, pricing launches, mobile app releases, and cloud migrations all alter the baseline. Attack patterns change too, but internal product work often causes just as much model decay.
Standard MLOps discipline is required here. Version feature definitions. Keep threshold history. Log model inputs and decisions in a form analysts can inspect. Track changes in score distribution after releases. If your team needs a concrete operating model, these MLOps best practices for production ML systems map cleanly to IDS pipelines.
The practical trade-off is simple. The more adaptive the detector, the more disciplined the release process has to be.
Better detection depth usually costs speed, clarity, or team time
Executive teams often ask for real-time response and advanced detection in the same first release. That combination is expensive.
A common trade-off made is:
- Simple rules are fast to run, cheap to explain, and easier to support during incidents
- Classical ML models add flexibility without creating heavy serving requirements
- Sequence models or hybrid stacks can catch more nuanced behavior, but they raise debugging time, infrastructure cost, and rollback complexity
Those are not just model choices. They are operating model choices.
I usually recommend that teams budget for the human cost of sophistication before they budget for GPUs. A detector that is slower but understandable can still work. A detector nobody can debug under pressure usually does not last.
Real production environments break tutorial assumptions
Many Python IDS examples assume full packet visibility and stable network boundaries. Enterprise environments rarely give you either.
Common constraints show up quickly:
- Encrypted payloads limit payload inspection
- Cloud, SaaS, and on-prem boundaries create blind spots
- Sampling and aggregation distort event patterns
- Load balancers, NAT, and service proxies change observable behavior
Security and platform teams often respond by centering detection on flow metadata, endpoint context, identity signals, and correlation across systems instead of raw packet content alone.
If the design depends on perfect packet capture, expect redesign work after the first architecture review.
The hardest scaling problem is ownership
Code is not usually the long-term bottleneck. Decision ownership is.
Someone has to review alerts, label misses, approve threshold changes, coordinate with incident response, and decide when a model update is safe to release. In early pilots, that work often gets spread across a security engineer, a data scientist, and an SRE who already have full-time jobs. That arrangement works for a demo. It usually fails in production within a quarter.
The failure pattern is predictable. Review queues grow. Thresholds stop getting tuned. Analysts lose trust in the alerts. Then alerts get muted or ignored, and leadership concludes the IDS was the wrong investment.
The fix is not more model experimentation. The fix is a clear operating owner, a release cadence, and a feedback loop the team can sustain.
Assembling Your IDS A-Team Skill and Role Guide
A production Python IDS isn’t a one-person build for long.
Even if one strong engineer can create the pilot, keeping it reliable usually takes a small cross-functional unit. The build succeeds when roles are clear and handoffs are minimal.
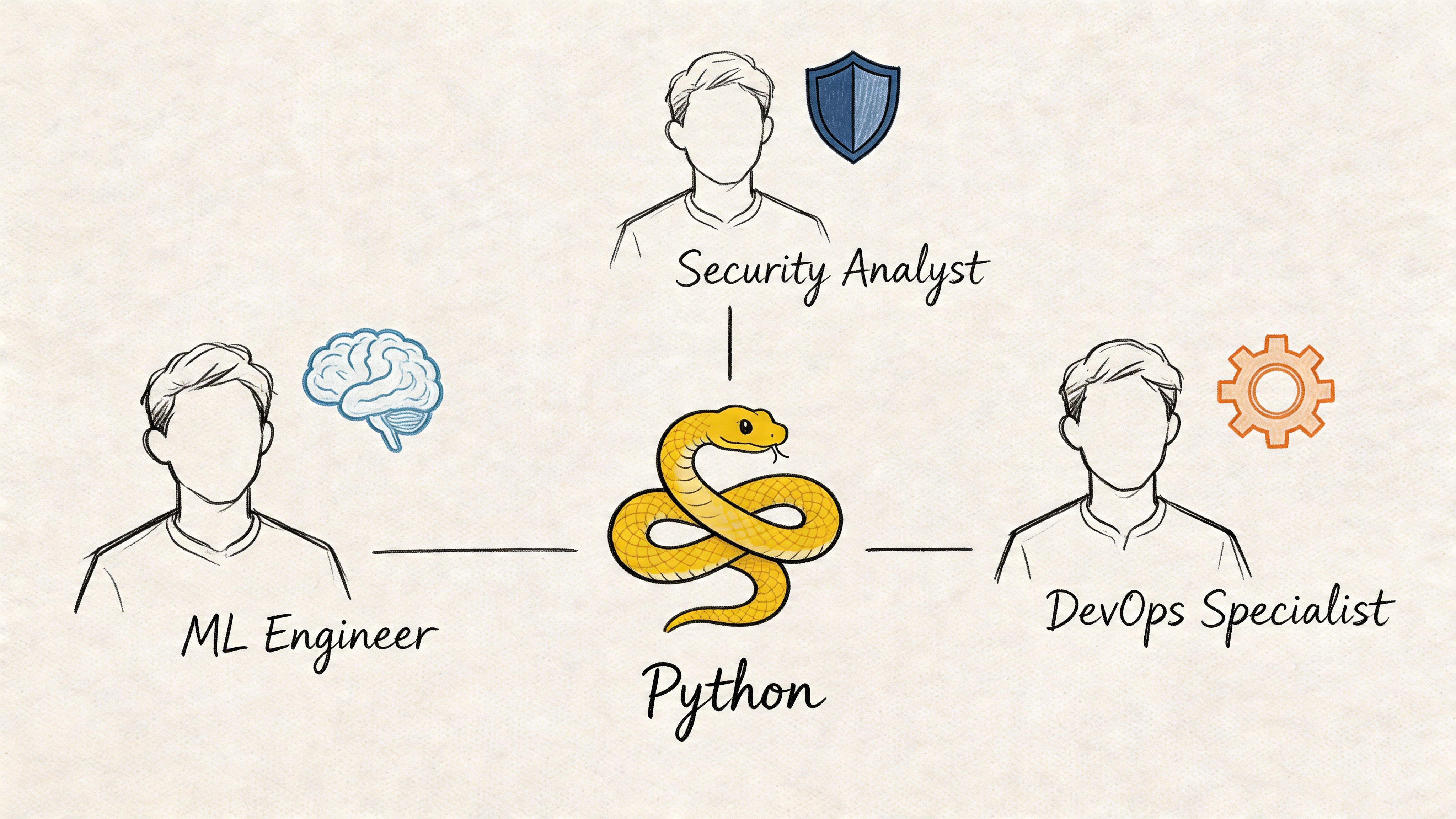
The core roles
A UCL dissertation on ML-based anomaly detection IDS highlights deployment into real-time environments with Kafka/ELK and PyShark, which makes one thing clear. You need MLOps capability beyond model building (UCL dissertation on streaming deployment requirements).
Here’s the practical staffing map.
| Role | What they own | Must-have skills | What to watch for |
|---|---|---|---|
| Machine Learning Engineer | Feature pipelines, training, evaluation, inference logic | Python, scikit-learn, TensorFlow or PyTorch, feature engineering, model evaluation | Great notebook work but weak production judgment |
| MLOps or Platform Engineer | Deployment, streaming, CI/CD, observability, rollback paths | Docker, Kubernetes, Kafka, logging stacks, API deployment | Strong infra skills but no feel for model behavior |
| Security Analyst or Detection Engineer | Threat mapping, alert review, rule quality, triage logic | Network telemetry, incident analysis, detection tuning | Deep security knowledge but low collaboration with product teams |
Hiring order that usually makes sense
If you’re starting from scratch, don’t try to hire every specialist at once.
A common sequence:
- One senior ML engineer with production instincts
- One platform or MLOps engineer who can own deployment
- Fractional or embedded security expertise for validation and tuning
If you’re actively hiring, this guide on how to hire machine learning engineers is useful because IDS work punishes weak systems thinking fast.
Interview questions that reveal real capability
Skip generic Python trivia. Ask questions that expose trade-off judgment.
Use prompts like:
- How would you design a Python IDS for one high-value traffic boundary before expanding coverage?
- What would you log for every alert so an on-call engineer can investigate it later?
- When would you choose rules over anomaly detection for the first release?
- How would you handle threshold tuning after a major product release changes normal traffic?
- How would you separate shadow-mode model evaluation from production blocking logic?
Good candidates talk about data quality, rollback plans, and alert consumers. Weak candidates jump straight to model choice.
Soft skills matter more than most teams expect
The best IDS hires share a few traits:
- Adversarial thinking: they ask how the detector can be bypassed
- Restraint: they don’t oversell what the model knows
- Cross-functional communication: they can explain an alert to security, infra, and product engineers
- Operational discipline: they care about ownership, incident flow, and safe rollout
That combination is rarer than pure Python skill. Hire for it deliberately.
Download Your IDS Project and Hiring Checklist
If you were turning this into an internal project brief today, the fastest move is to use a checklist.
A good IDS checklist saves time because it forces decisions that teams usually postpone until they become blockers. It also helps you separate “interesting ML work” from “something we can put into production.”
What your checklist should include
Use a one-page planning document with these sections:
Scope the pilot
- Choose one boundary: public ingress, internal service edge, or sensitive admin path
- Define target threats: scans, floods, unusual access patterns, or protocol abuse
- Set pilot success criteria: useful alerts, operator trust, and review workflow
Confirm telemetry
- List capture sources: packet, flow, gateway, proxy, and application logs
- Check data quality: timestamps, missing fields, schema consistency
- Decide retention: enough history for baselining and post-alert investigation
Choose detection approach
- Pick your starting mode: heuristics, ML, or hybrid
- Define explainability needs: what evidence must every alert include
- Document safe actions: observe only, notify, or automated response
Plan the team
- Name an owner: one engineering lead for delivery
- Define review roles: who triages, tunes, and signs off changes
- Draft hiring needs: ML engineering, platform, and security coverage
Set an operating rhythm
- Weekly alert review
- Model or threshold change log
- Post-pilot decision date
Download format
The best version is a simple PDF or Notion page your engineering lead, security contact, and hiring manager can all use in the same meeting.
Keep it short. If the checklist takes longer to read than your pilot brief, it won’t be used.
What to Do Next
A python intrusion detection system becomes manageable when you reduce it to three immediate decisions.
1. Scope a narrow pilot
Choose one monitored boundary and one alert consumer.
Don’t start across every environment. Start where suspicious traffic would hurt the business and where the team can effectively validate alerts. That gives you a faster learning loop and less political friction.
2. Decide your initial detection style
If your team needs visibility fast, start with deterministic rules plus reviewable logging.
If you already have stable telemetry and ML support, run anomaly detection in shadow mode before you let it drive noisy operational alerts. That preserves trust while you learn what the model is really seeing.
3. Staff the operating loop, not just the build
Before writing the full roadmap, answer three ownership questions:
- Who ships the first version
- Who reviews detections every week
- Who updates thresholds or models safely
If any of those are unclear, fix the team plan first. The technology can wait a few days. Bad ownership is harder to undo than bad code.
The teams that get value from IDS aren’t always the ones with the fanciest model. They’re the ones that ship a narrow version, learn from real traffic, and keep improving the operating loop.
If you want help turning this into a staffed pilot, ThirstySprout can connect you with senior ML engineers, MLOps specialists, and AI platform talent who’ve shipped production systems, not just prototypes. You can start a pilot, validate the architecture, and build your IDS team without waiting through a long hiring cycle.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.