
TL;DR
- Focus on practical problems, not just theory. The best machine learning engineer interview questions simulate real-world challenges like building recommendation systems or handling imbalanced data.
- Assess end-to-end skills. A top candidate must demonstrate proficiency across the entire ML lifecycle, from data processing and feature engineering to model deployment and monitoring.
- Use a structured evaluation. Implement a scorecard to assess coding, system design, theory, and business acumen consistently across all candidates. This removes bias and improves hiring accuracy.
- What to do next: Define a hiring scorecard, standardize your interview loop with these questions, and book a call with us to see pre-vetted senior ML engineer profiles.
Who This Guide Is For
This guide is for technical leaders responsible for hiring and building high-performing AI/ML teams.
- CTO / Head of Engineering: You need a reliable framework to vet senior ML engineers who can own projects from concept to production and deliver business impact.
- Hiring Manager / Staff Engineer: You are conducting interviews and need high-signal questions that distinguish between candidates who know theory and those who can build and ship robust ML systems.
- Founder / Product Lead: You are defining the ML engineer role and need to understand the key skills and practical challenges that define a top-tier candidate.
Quick Framework: The ML Engineer Interview Scorecard
A successful interview process is not a pop quiz; it's a structured assessment that simulates real-world challenges. We use a scorecard to evaluate candidates across four core dimensions.
The Top 10 Interview Questions
1. Explain the Bias-Variance Tradeoff
This is one of the most fundamental machine learning engineer interview questions. It tests a candidate's core understanding of model performance, generalization, and the root causes of error. A strong answer shows they grasp how model complexity impacts prediction accuracy on unseen data—essential for building reliable systems.
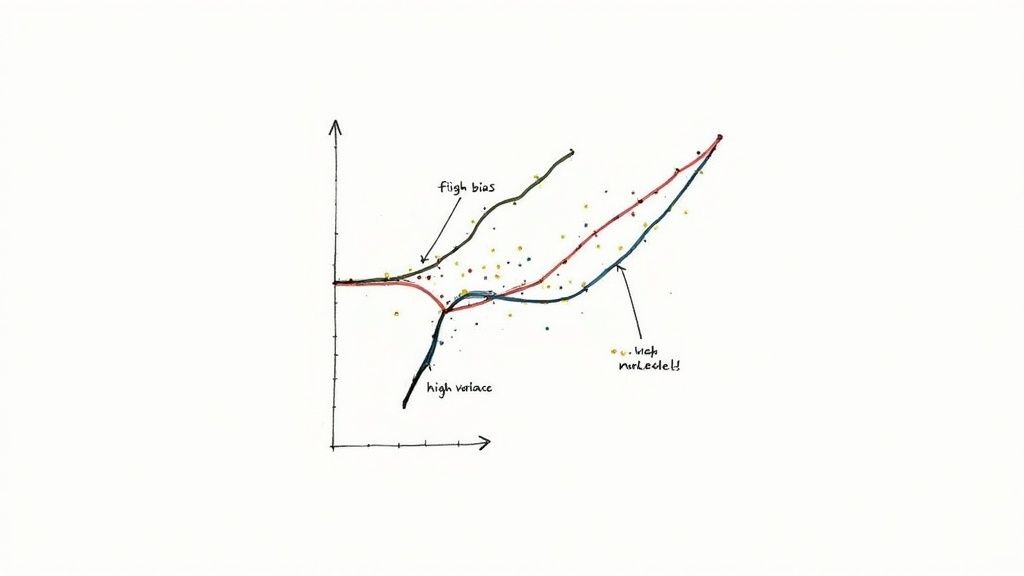
Bias is the error from approximating a complex real-world problem with an overly simple model. High-bias models (like Linear Regression) often underfit.
Variance is the error from sensitivity to small fluctuations in the training set. High-variance models (like a deep Decision Tree) often overfit, capturing noise instead of the underlying signal.
The goal is to find a balance. A model with optimal complexity will have low bias and low variance, generalizing well to new data. Understanding these implications is key, as it forces engineers to make better decisions about algorithm choice and hyperparameter tuning.
What a Good Answer Looks Like
- Diagnose with Learning Curves: Plots training and validation error against training set size. A large gap between curves indicates high variance (overfitting); both curves plateauing at a high error suggests high bias (underfitting).
- Provide Concrete Examples: Contrasts a high-bias model like Logistic Regression with a high-variance model like a Support Vector Machine with an RBF kernel, explaining scenarios where each is preferable.
- Discuss Mitigation Strategies: To fix high bias, try a more complex model or add features. To fix high variance, use more data, apply regularization (L1/L2), or use a simpler model. You can learn more about these foundational AI concepts and interview approaches.
2. Implement Linear Regression from Scratch
This classic coding question separates candidates who only call libraries from those who understand a model's mechanics. It assesses their grasp of cost functions, gradient descent, and numerical optimization. A strong answer showcases both mathematical intuition and practical coding skills.
At its core, linear regression models the relationship between variables by fitting a linear equation to data. The implementation involves defining a cost function (like Mean Squared Error) and using gradient descent to iteratively adjust the model's parameters to minimize this cost.
The process reveals a candidate's ability to translate a mathematical formula into efficient, working code. It also serves as a gateway to discussing more complex implementations, like regularization.
What a Good Answer Looks Like
- Start with Pseudocode: Outlines the steps: initialize parameters, define the cost function, calculate gradients, and update parameters in a loop. This demonstrates structured thinking.
- Use Vectorization: Uses NumPy for efficient matrix operations instead of slow loops. Explains how vectorization speeds up computation.
- Discuss Convergence and Debugging: Explains how to monitor the cost function to ensure the model is learning and how to choose a learning rate.
- Analyze Complexity: Discusses the time and space complexity of their implementation. For batch gradient descent, time complexity is O(n * f * i), where n is samples, f is features, and i is iterations.
3. Design a Recommendation System at Scale
This system design question moves beyond algorithms to assess a candidate's ability to architect and deploy complex ML systems. A strong answer demonstrates practical knowledge of the entire lifecycle, from data ingestion to low-latency serving and performance monitoring.
The core task involves designing a system that can generate personalized suggestions for users in real-time, requiring a thoughtful approach to data pipelines, model architecture, and scalability. It reveals if you can connect business goals with technical trade-offs.
A complete answer typically involves a multi-stage architecture: candidate generation to quickly filter a vast item space, followed by a more expensive ranking model to score and order the shortlisted candidates. This hybrid approach is critical for meeting strict latency requirements. This is a key consideration for companies evaluating global talent sourcing models.
What a Good Answer Looks Like
- Ask Clarifying Questions First: Scopes the problem by asking about business objectives (e.g., increase engagement), scale (users, items), and latency constraints.
- Outline a Multi-Stage Architecture: Proposes a two-stage design: 1) Candidate Generation (collaborative filtering, embeddings) and 2) Ranking (XGBoost, DNN). Explains the trade-offs.
- Address the Cold-Start Problem: Discusses strategies for new users (fall back to popularity) and new items (use content features).
- Discuss Evaluation and A/B Testing: Explains how to evaluate the system offline (precision@k, nDCG) and online with an A/B testing framework to measure business impact.
4. Explain Cross-Validation and Why It's Important
This question probes a candidate’s practical knowledge of model evaluation. Answering well shows you understand how to generate reliable performance metrics, prevent overly optimistic results, and build models that generalize to unseen data.
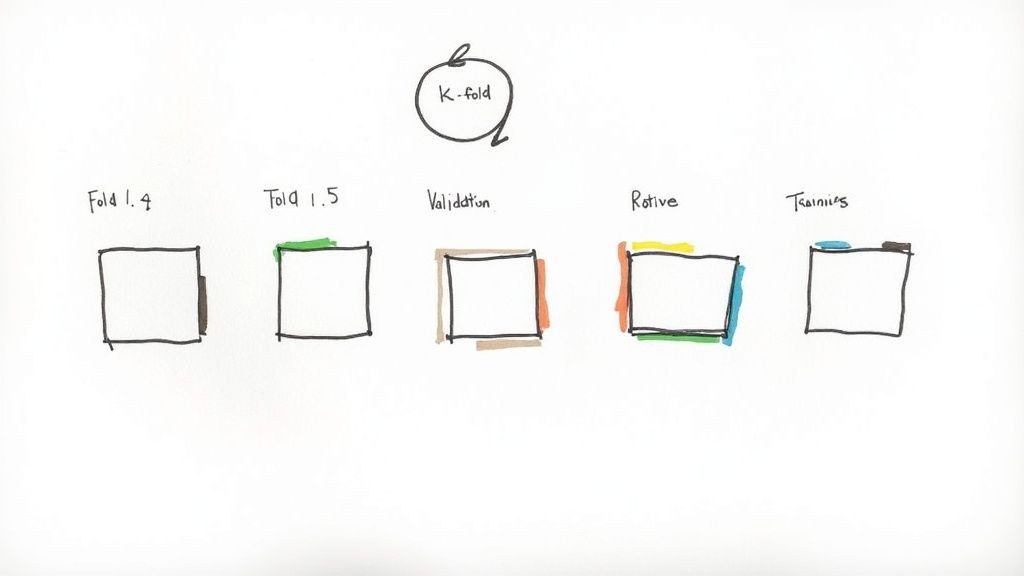
Cross-validation is a resampling procedure used to evaluate models on limited data. The most common method is k-fold cross-validation, where the data is split into k folds. The model is trained k times, with each fold getting a turn as the test set.
The final performance metric is the average of the metrics from each of the k runs, providing a more stable and robust estimate of the model's true performance. This is critical for making informed decisions about which model to deploy.
What a Good Answer Looks Like
- Mention Key Variants: Discusses different types of CV. Explains that Stratified K-Fold is essential for imbalanced classification problems. For temporal data, a Time Series Split is necessary to prevent training on future data to predict the past.
- Discuss Hyperparameter Tuning: Explains nested cross-validation, using an inner loop for hyperparameter tuning and an outer loop for final model evaluation to prevent information leakage.
- Quantify the Output: Emphasizes reporting both the mean and the standard deviation of the performance metric across folds. A high standard deviation signals an unstable model.
5. Tell Me About a Time You Failed and What You Learned
This behavioral question assesses a candidate's resilience, humility, and ability to learn from mistakes. For an ML engineer, where experimentation is constant, failure is inevitable. A strong answer reveals self-awareness, problem-solving skills, and accountability.
The interviewer is looking for a mature, growth-oriented mindset. They want to see that you can navigate the inherent uncertainty of ML projects, from a flawed hypothesis to a production model that degrades unexpectedly.
The goal is to frame a genuine failure as a powerful learning experience that made you a better engineer. A well-structured story shows you can analyze root causes, take corrective action, and institutionalize the learnings.
What a Good Answer Looks Like
- Use the STAR Method: Structures the response using the Situation, Task, Action, and Result (STAR) framework. Clearly describes the context, your responsibility, the actions taken (and why they failed), and what you learned.
- Choose a Relevant, Technical Failure: Selects a real failure with technical depth, like a model deployment that failed due to data drift or an overlooked bug in a data pipeline.
- Emphasize Ownership and Learning: Takes clear ownership. Details specific changes made to their process. For instance, "After that incident, I implemented a robust data validation step in our CI/CD pipeline to catch such issues before production."
6. Implement Binary Classification Model Evaluation Metrics
This technical question tests practical implementation skills. It assesses whether an engineer can translate model predictions into business-relevant performance measures. A strong answer shows you can code metrics like precision and recall from scratch and articulate when one is more critical than the other.
Production models are rarely judged on accuracy alone. Business goals, like minimizing false negatives in medical diagnosis or reducing false positives in a spam filter, dictate the choice of evaluation metric. Understanding these tradeoffs is a non-negotiable skill.
What a Good Answer Looks Like
- Implement From Scratch First: Demonstrates foundational knowledge by implementing metrics using NumPy. Starts with the confusion matrix components: True Positives (TP), True Negatives (TN), False Positives (FP), and False Negatives (FN). Then builds precision (TP / (TP + FP)) and recall (TP / (TP + FN)).
- Connect Metrics to Business Impact: Provides concrete scenarios. For fraud detection, high recall is crucial. For a spam filter, high precision is vital.
- Discuss Threshold-Independent Metrics: Explains that precision and recall depend on a classification threshold. Introduces metrics like ROC-AUC as a way to evaluate a model's performance across all possible thresholds.
7. How Would You Handle Class Imbalance in Your Dataset?
This is a critical, real-world question that tests a candidate's ability to solve a common data problem that can derail model performance. Answering well shows you understand that raw accuracy is often misleading.
Class imbalance occurs when one class is heavily overrepresented. For instance, in fraud detection, legitimate transactions might outnumber fraudulent ones 999 to 1. A naive model could achieve 99.9% accuracy by always predicting "not fraud," making it useless.
Successfully navigating this problem requires a multi-faceted approach, combining data-level techniques, algorithmic adjustments, and a focus on appropriate evaluation metrics.
What a Good Answer Looks Like
- Prioritize Metrics: Starts by explaining why accuracy is poor. Proposes metrics like Precision, Recall, F1-Score, and AUPRC. Discusses how the business context (cost of a false negative vs. false positive) determines which metric to optimize.
- Discuss Data-Level Techniques: Mentions resampling methods. Oversampling (e.g., SMOTE) creates synthetic data for the minority class. Undersampling removes instances from the majority class. Crucially, explains that resampling must only be applied to the training set.
- Explain Algorithmic Solutions: Discusses using models with built-in
class_weightparameters, which penalize misclassifications of the minority class more heavily. Also, mentions cost-sensitive learning or adjusting the decision threshold.
8. Describe Your Experience with End-to-End Machine Learning Projects
This question gauges a candidate's practical, hands-on experience. It evaluates their ability to navigate the entire machine learning lifecycle, from problem framing to deploying and maintaining a production system.
Interviewers use this question to understand if you can own a project and deliver tangible business value. They want to see that you've grappled with real-world complexities like messy data, shifting requirements, and production constraints.
An end-to-end project showcases a holistic understanding of the ML system, including data collection, feature engineering, model selection, deployment, and post-deployment monitoring.
What a Good Answer Looks Like
- Structure with the STAR Method: Frames the story using Situation (the business problem), Task (your objective), Action (the specific steps you took), and Result (the measurable business impact).
- Discuss Challenges and Trade-offs: Talks about a technical challenge faced, like data drift or high latency, and explains the trade-offs considered to solve it.
- Quantify Your Impact: Instead of "the model improved accuracy," says "the new model reduced false positives by 20%, saving the operations team 15 hours per week." This is a key differentiator when companies hire remote AI developers.
- Mention Collaboration: Describes working with stakeholders like product managers, data engineers, and business analysts to highlight communication skills.
9. Design a Feature Engineering Pipeline for High-Dimensional Data
This question evaluates a candidate's ability to build scalable, production-ready data processing systems. Interviewers use it to assess how you handle the complexity of real-world data with thousands of potential features.
Handling high-dimensional data is a common challenge in domains like genomics or e-commerce. The goal of a feature engineering pipeline is to systematically transform raw data into a curated set of informative features that improve model performance and reduce training time.
What a Good Answer Looks Like
- Outline a Phased Approach: Describes a structured process: 1) Exploration & Selection (correlation analysis, SHAP), 2) Dimensionality Reduction (PCA, Autoencoders), 3) Transformation & Scaling, and 4) Pipeline Automation (scikit-learn Pipelines, Spark).
- Discuss Tradeoffs: Explains the pros and cons of different techniques. For example, PCA is efficient but results in features that lose their original interpretability, while feature selection preserves meaning.
- Incorporate MLOps Best Practices: Addresses operational concerns. Mentions feature stores (Tecton, Feast) for consistency between training and serving. Discusses monitoring for feature drift and implementing automated retraining triggers.
10. Explain Regularization Techniques and When to Use Each
This question assesses a candidate's ability to prevent overfitting. A strong answer demonstrates a nuanced understanding of how to control model complexity, which is critical for building robust systems that generalize well to unseen data.
Regularization adds a penalty for complexity to the model's loss function.
L1 Regularization (Lasso) adds a penalty equal to the absolute value of coefficients. It can shrink some coefficients to zero, performing automatic feature selection.
L2 Regularization (Ridge) adds a penalty equal to the square of the magnitude of coefficients. It forces weights to be small but rarely zero, making it effective for preventing multicollinearity.
What a Good Answer Looks Like
- Connect to Bias-Variance: Frames regularization as a tool to manage the bias-variance tradeoff. By adding a penalty (bias), you reduce the model's variance and improve generalization.
- Detail Specific Use Cases: Explains when to use each. Use L1 (Lasso) when you suspect many features are useless and want a sparse, interpretable model. Use L2 (Ridge) when you believe all features contribute.
- Discuss Neural Network Techniques: Mentions Dropout (randomly deactivates neurons during training) and Early Stopping (monitors validation error and stops training when it begins to increase).
- Explain Hyperparameter Tuning: Emphasizes that the strength of regularization is a hyperparameter and that cross-validation is used to find its optimal value.
Checklist: From Questions to a High-Signal Hiring Process
Simply having a list of strong questions is not enough. The real goal is to build a repeatable, high-signal hiring framework that consistently identifies top-tier talent.
Define Your Scorecard: Adapt the 4-part framework (Fundamentals, Coding, System Design, Business Impact) to your specific role. Weight categories based on the job's primary responsibilities. An MLOps role weighs system design higher; a research role prioritizes theory.
Standardize the Interview Loop: Ensure every candidate for a given role gets the same core questions. This removes bias and allows for fair, apples-to-apples comparisons. Train interviewers on the scorecard and what a "good" vs. "great" answer looks like.
Conduct a Retrospective: After each hiring round, review your process. Did the candidates who scored highest on these questions perform best in their roles 90 days later? Use this feedback to continuously refine your interview questions and evaluation criteria.
Integrate a Broader Framework: Mastering these questions is part of a larger skill set. For candidates and hiring managers, a strategic framework for how to prepare for interviews enhances overall readiness and turns a Q&A into a strategic talent assessment.
What to Do Next
- Download our Interview Scorecard Template: Use our pre-built template to customize your evaluation process for ML engineer roles.
- Schedule a Tech Deep Dive: Book a free 30-minute session with our AI/ML practice lead to refine your interview questions and hiring process.
- Start a Pilot: See pre-vetted, senior ML engineer profiles from our network. Launch a pilot project in under two weeks and build with confidence.
Finding, vetting, and onboarding elite remote AI and ML engineers is a full-time job. At ThirstySprout, we've built the specialized sourcing and vetting engine so you don't have to. Start a pilot with pre-vetted, senior ML talent in under two weeks.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.