
TL;DR
- When to finetune? To teach an LLM a new skill (like adopting a brand voice or generating specific JSON), not new knowledge. For knowledge, use Retrieval-Augmented Generation (RAG).
- What's the best method? Start with Parameter-Efficient Finetuning (PEFT), specifically QLoRA. It trains a model using <1% of its parameters on a single GPU, saving ~90% on cost and time compared to full finetuning.
- What do you need? A high-quality dataset of 500–2,000 clean, instruction-following examples is more effective than 50,000 messy ones. Data quality is everything.
- Next step: Define your business metric (e.g., improve JSON adherence to 95%) and start with a small data audit. If you don't have at least 100 high-quality examples, your first task is data collection.
Who This Is For
- CTOs & Heads of Engineering: Deciding on the architecture and budget for a custom AI model versus using a generic API.
- Founders & Product Leads: Scoping the ROI, timeline, and team needed to build an AI feature with specific behavioral requirements.
- Staff & ML Engineers: Looking for a practical, step-by-step workflow to finetune an open-source model like Llama 3 or Mistral.
The Quick Answer: Your LLM Fine-Tuning Framework
Figuring out the right path isn't just a technical choice—it sets the direction for your project, from budget and timeline to the team you'll need. The core decision always comes back to one question: are you teaching a new skill or providing new knowledge?
Choose fine-tuning for new skills: When you need the model to change its core behavior, fine-tuning is the way to go. This is your tool for adopting a unique personality, learning a complex output format, or summarizing text with a specific, stylized flair. You're altering how the model operates.
Choose RAG for new knowledge: When your goal is to feed the model up-to-date information, RAG is the clear winner. It's built for Q&A over internal documents, customer support articles, or legal archives. You're not changing the model's brain, just giving it a bigger library to read from.
This decision also impacts bigger strategic questions, like the decision to build your own LLM models versus relying on third-party APIs.
A Simple Decision Tree: Skill vs. Knowledge
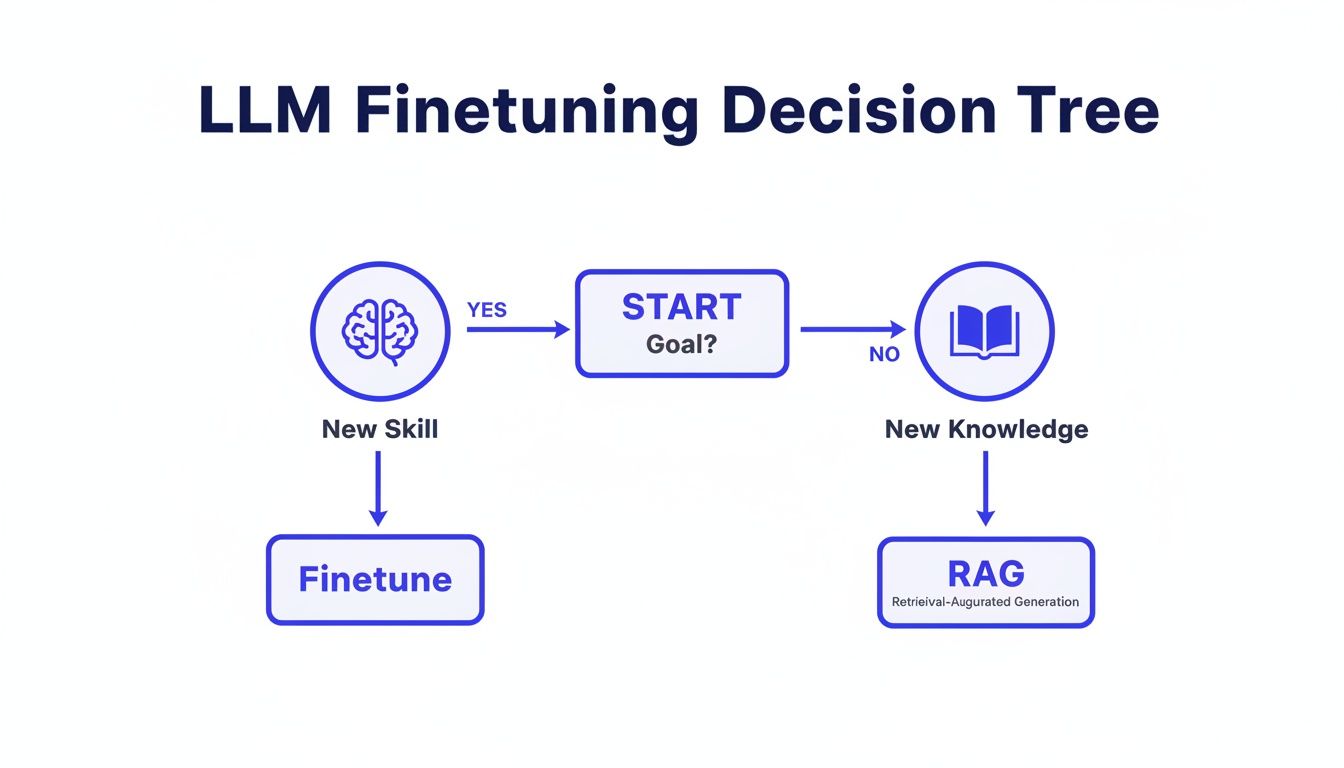
alt text: Flowchart for LLM finetuning, deciding between finetuning for new skills or RAG for new knowledge.
As the flowchart shows, your primary goal is the key driver. If you're trying to bake in a new capability, you finetune. If you just need it to know more, you use RAG.
Practical Examples of Fine-Tuning in Action
Here are two common scenarios where fine-tuning is the correct technical and business decision.
Example 1: Creating a Brand-Voice Chatbot
A B2B SaaS company wants a chatbot that sounds like its senior solutions architects: professional, concise, and slightly formal. Generic model responses are too conversational and don't reflect the brand's expert positioning.
- Problem: The base model's skill (its tone and style) is wrong.
- Action: They create a dataset of 500 "gold-standard" Q&A pairs curated from their best support tickets and documentation, ensuring each answer mirrors the target voice.
- Method: They use QLoRA to finetune a Mistral-7B model. The process takes ~3 hours on a single cloud GPU.
- Business Impact: The new chatbot achieves a 9/10 score on internal brand voice evaluations, improving customer trust and reducing the need for human hand-offs for simple queries by 30%.
Example 2: Generating Structured SQL Queries
A data analytics platform wants to allow users to ask questions in plain English ("show me last month's user signups by region") and have the LLM generate a valid SQL query for their specific database schema.
- Problem: The base model lacks the skill of generating SQL that works with their unique table names and column structures.
- Action: An engineer generates a dataset of 1,000 natural language questions mapped to correct, hand-verified SQL queries.
- Method: They use LoRA to finetune Llama 3 8B. The LoRA adapter file is only ~40MB, making it easy to version and deploy.
- Business Impact: The feature achieves 92% query success rate in testing, reducing the time for non-technical users to get data insights from hours to seconds. This becomes a key product differentiator.
Deep Dive: Preparing Data, Choosing a Method, and Deploying
Step 1: Prepare Your Dataset for Finetuning
Your finetuned model will only ever be as good as its data. Success hinges on data quality, not quantity. A small, meticulously cleaned, and highly relevant dataset will beat a giant, messy one every time.
Your goal is to build an instruction-following dataset of prompt-and-completion pairs. Each pair is a tiny lesson: "When you see an input like this (the prompt), produce an output exactly like this (the completion)."

alt text: A hand-drawn illustration showing a data audit checklist, a dataset file, and warning signs, representing the importance of a data audit for finetuning an LLM.
The standard format is a JSONL file, where each line is a JSON object. For example:
{"prompt": "Summarize this review in a friendly tone: 'The app is okay but crashes sometimes.'", "completion": "Thanks for the feedback! We're sorry to hear about the crashes and are working on a fix to improve your experience."}
This clean structure is non-negotiable. Building reliable pipelines to create these files is critical; if you need help, our guide on the best data pipeline tools can point you in the right direction.
We can't stress this enough: careful data selection is everything. The winning teams in the NeurIPS 2023 LLM Fine-tuning Competition won by curating smaller, higher-quality datasets, not by using the biggest ones. Their fine-tuning competition findings proved that a well-curated dataset of 500 examples teaches a model far more effectively than 50,000 messy ones.
Step 2: Choose Your Finetuning Strategy (PEFT vs. Full)
For almost every business use case, Parameter-Efficient Finetuning (PEFT) is the right answer. Full finetuning is a resource hog—incredibly expensive and demanding. PEFT gets you comparable results for a fraction of the cost.

alt text: A sketch of a balance scale comparing full finetuning with PEFT/LoRA, showing that PEFT has significantly lower resource costs.
The most popular PEFT method is LoRA (Low-Rank Adaptation), which freezes the base model and trains tiny "adapter" layers. An even more efficient version is QLoRA (Quantized LoRA), which uses 4-bit precision to fit larger models on the same hardware. Meta AI has some great insights on these modern techniques.
Getting started is simple with the Hugging Face peft library. This snippet shows how you're only training a tiny fraction of the model:
from peft import LoraConfig, get_peft_modelfrom transformers import AutoModelForCausalLM# Load your base model (e.g., Llama 3 8B)model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B")# Define the LoRA configurationpeft_config = LoraConfig(r=16,lora_alpha=32,target_modules=["q_proj", "v_proj"],lora_dropout=0.05,task_type="CAUSAL_LM")# Wrap the base model with the PEFT configpeft_model = get_peft_model(model, peft_config)peft_model.print_trainable_parameters()# trainable params: 4,718,592 || all params: 8,034,963,456 || trainable%: 0.0587You're training less than 0.1% of the total parameters. That is the magic of LoRA.
Step 3: Run the Finetuning Workflow
Here is a 5-step workflow using the Hugging Face ecosystem, which has become the standard for open-source LLM development. For a deeper walkthrough, see A Practical Guide on How to Fine-Tune LLMs.
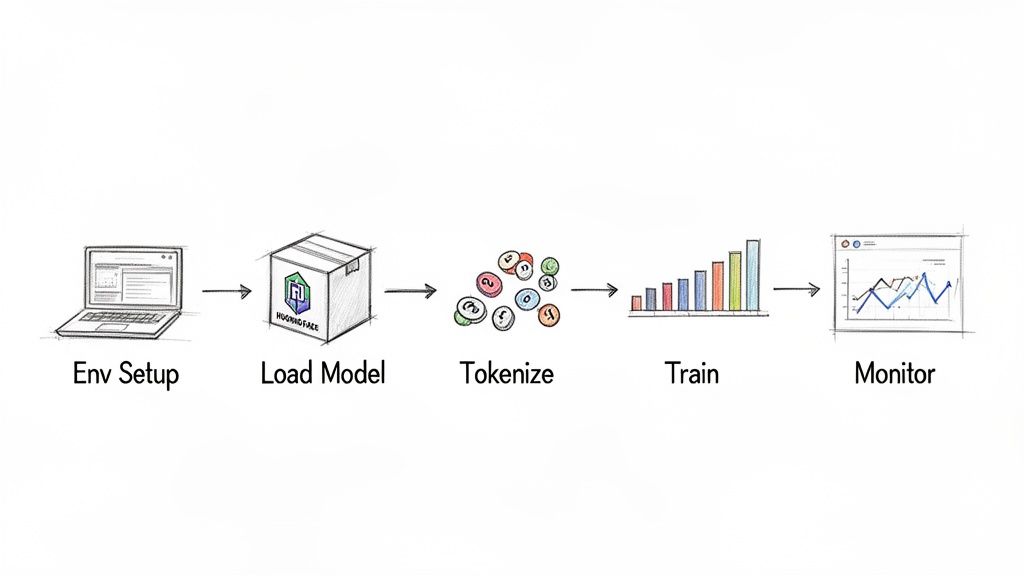
alt text: A diagram illustrates the five steps of fine-tuning a language model: setup, load model, tokenize, train, and monitor.
- Setup Environment: Install
transformers,datasets,peft,torch, andbitsandbytes. Ensure your GPU and CUDA drivers are configured correctly. - Load Model & Tokenizer: Load your base model (e.g., Mistral-7B) with 4-bit quantization and its corresponding tokenizer. Pro-tip: Always set the tokenizer's
pad_tokenif it's undefined to avoid crashes. - Tokenize Dataset: Load your JSONL dataset and apply a prompt template to each example before tokenizing the text into numerical tensors.
- Configure Trainer: Use the Hugging Face
TrainerwithTrainingArgumentsto define your learning rate, batch size, and epochs. A single call totrainer.train()starts the process. - Monitor Training: Use tools like Weights & Biases or TensorBoard to watch your training loss. A smooth, downward-sloping curve is what you want to see.
Step 4: Evaluate and Deploy Your Model
A good-looking loss curve doesn't guarantee business value. You need both quantitative metrics and human judgment to confirm the model works as intended.
Automated metrics like ROUGE or BLEU are useful, but they can't tell you if a response is factually wrong or off-brand. That requires human review.
Create a simple scorecard for human evaluation. Here’s an example we use:
Human Evaluation Scorecard
A "Factual Accuracy" score of 2 is a showstopper that an automated metric would miss. This is why you keep humans in the loop.
For deployment, you can use the Hugging Face Hub for demos, managed platforms like AWS SageMaker or Google's Vertex AI for production, or self-host with tools like Text Generation Inference (TGI) for full control. Following MLOps best practices for AI teams is key to a reliable deployment.
Step 5: Address Pitfalls like Overfitting and Forgetting
- Catastrophic Forgetting: This happens when your model becomes a one-trick pony, forgetting its general skills. To prevent this, mix 5–10% of general-purpose instruction data into your specialized dataset.
- Overfitting: This is when the model memorizes your training data instead of learning patterns. Use a separate, unseen test set to check for a performance drop, which is a red flag.
- Sample Size: You rarely need massive datasets. Research shows diminishing returns after a certain point; you can read the full research about these sample size findings. Focus on 500 to 2,000 high-quality examples.
Your Production Readiness Checklist
Before you deploy, run through this final checklist to ensure your model is a reliable business asset, not just a clever experiment.
- [ ] Data Quality Verified: Have you manually spot-checked your training data for errors, formatting issues, and biases?
- [ ] Robust Evaluation in Place: Do you have both automated metrics and a human evaluation scorecard?
- [ ] Catastrophic Forgetting Mitigated: Have you tested the model on basic, off-topic prompts to ensure it's still coherent?
- [ ] Overfitting Checked: Is performance on your held-out test set similar to your validation set?
- [ ] Cost and Latency Measured: Do you know the exact cost per inference and the average response time under expected load?
- [ ] Monitoring and Logging Configured: Are you logging inputs and outputs to watch for model drift and error spikes?
- [ ] Rollback Plan Ready: Do you have a tested, one-click way to revert to the previous model version if something goes wrong?
What to Do Next
- Audit Your Data: Identify your best source of 100-500 high-quality examples for the skill you want to teach.
- Scope a Pilot Project: Define a clear business metric and a 2-week plan to finetune a 7B model using QLoRA.
- Talk to an Expert: A 20-minute call can validate your approach and clarify your budget and timeline.
Ready to build and deploy your own production-grade AI models? ThirstySprout connects you with the world's top remote AI and MLOps engineers who can accelerate your roadmap.
Hire from the Top 1% Talent Network
Ready to accelerate your hiring or scale your company with our top-tier technical talent? Let's chat.